Obsługa wartości NULL jest jednym z trudniejszych aspektów modelowania danych i manipulacji danymi za pomocą SQL. Zacznijmy od tego, że próba wyjaśnienia dokładnie, czym jest NULL samo w sobie nie jest trywialne. Nawet wśród ludzi, którzy dobrze znają teorię relacyjną i SQL, usłyszysz bardzo silne opinie zarówno za, jak i przeciw używaniu wartości NULL w swojej bazie danych. Czy to im się podoba, czy nie, jako praktyk zajmujący się bazami danych często masz do czynienia z nimi, a biorąc pod uwagę, że wartości NULL dodają złożoności do pisania kodu SQL, dobrym pomysłem jest uczynienie priorytetem dobrego ich zrozumienia. W ten sposób unikniesz niepotrzebnych błędów i pułapek.
Ten artykuł jest pierwszym z serii o NULL złożoności. Zacznę od omówienia czym są wartości NULL i jak zachowują się w porównaniach. Następnie opisuję NULL niespójności w leczeniu w różnych elementach językowych. Na koniec omówię brakujące standardowe funkcje związane z obsługą NULL w T-SQL i zasugeruję alternatywy, które są dostępne w T-SQL.
Większość omówienia dotyczy każdej platformy, która implementuje dialekt SQL, ale w niektórych przypadkach wspominam o aspektach specyficznych dla T-SQL.
W moich przykładach użyję przykładowej bazy danych o nazwie TSQLV5. Skrypt, który tworzy i wypełnia tę bazę danych, oraz jego diagram ER można znaleźć tutaj.
NULL jako znacznik brakującej wartości
Zacznijmy od zrozumienia, czym są wartości NULL. W SQL NULL jest znacznikiem lub symbolem zastępczym dla brakującej wartości. Jest to próba SQL przedstawienia w Twojej bazie danych rzeczywistości, w której czasami występuje pewna wartość atrybutu, a czasami jej brakuje. Załóżmy na przykład, że musisz przechowywać dane pracowników w tabeli Pracownicy. Masz atrybuty dla imienia, drugiego imienia i nazwiska. Atrybuty name i lastname są obowiązkowe, dlatego definiujesz je jako nie zezwalające na wartości NULL. Atrybut middlename jest opcjonalny i dlatego definiujesz go jako zezwalający na wartości NULL.
Jeśli zastanawiasz się, co model relacyjny ma do powiedzenia na temat brakujących wartości, wierzył w nie twórca modelu, Edgar F. Codd. W rzeczywistości rozróżnił nawet dwa rodzaje brakujących wartości:Brakujące, ale mające zastosowanie (znacznik wartości A) i Brakujące, ale nie mające zastosowania (znacznik wartości I). Jeśli jako przykład weźmiemy atrybut drugie imię, w przypadku, gdy pracownik ma drugie imię, ale ze względu na prywatność zdecyduje się nie udostępniać informacji, użyjesz znacznika A-Values. W przypadku, gdy pracownik w ogóle nie ma drugiego imienia, użyjesz znacznika I-Values. W tym przypadku ten sam atrybut może czasami być istotny i obecny, czasami brakujący, ale mający zastosowanie, a czasem brakujący, ale niemożliwy do zastosowania. Inne przypadki mogłyby być jaśniejsze, obsługując tylko jeden rodzaj brakujących wartości. Załóżmy na przykład, że masz tabelę Zamówienia z atrybutem o nazwie senddate, który zawiera datę wysyłki zamówienia. Wysłane zamówienie zawsze będzie miało obecną i odpowiednią datę wysyłki. Jedynym przypadkiem braku znanej daty wysyłki będą zamówienia, które nie zostały jeszcze wysłane. Dlatego tutaj albo odpowiednia wartość daty wysyłki musi być obecna, albo należy użyć znacznika I-Values.
Projektanci SQL postanowili nie wchodzić w rozróżnienie między wartościami dającymi się zastosować i niemożliwymi do zastosowania, i dostarczyli nam NULL jako znacznik wszelkiego rodzaju braków danych. W większości przypadków SQL został zaprojektowany tak, aby zakładać, że wartości NULL reprezentują rodzaj brakującej wartości typu Missing But Applicable. W konsekwencji, zwłaszcza gdy używasz NULL jako symbolu zastępczego dla nieodpowiedniej wartości, domyślna obsługa SQL NULL może nie być tą, którą postrzegasz jako poprawną. Czasami będziesz musiał dodać wyraźną logikę obsługi NULL, aby uzyskać leczenie, które uważasz za właściwe dla Ciebie.
W ramach najlepszej praktyki, jeśli wiesz, że atrybut nie powinien zezwalać na wartości NULL, upewnij się, że wymuszasz go za pomocą ograniczenia NOT NULL jako części definicji kolumny. Jest kilka ważnych powodów. Jednym z powodów jest to, że jeśli tego nie wymusisz, w takim czy innym momencie, dotrą tam wartości NULL. Może to być wynikiem błędu w aplikacji lub importowania złych danych. Korzystając z ograniczenia, wiesz, że wartości NULL nigdy nie dotrą do tabeli. Innym powodem jest to, że optymalizator ocenia ograniczenia, takie jak NOT NULL, w celu lepszej optymalizacji, unikania niepotrzebnej pracy w poszukiwaniu wartości NULL i włączania pewnych reguł przekształceń.
Porównania z wartościami NULL
Istnieje pewna trudność w ocenie predykatów przez SQL, gdy zaangażowane są wartości NULL. Najpierw omówię porównania dotyczące stałych. Później omówię porównania dotyczące zmiennych, parametrów i kolumn.
W przypadku używania predykatów porównujących operandy w elementach zapytania, takich jak WHERE, ON i HAVING, możliwe wyniki porównania zależą od tego, czy którykolwiek z operandów może mieć wartość NULL. Jeśli wiesz z całą pewnością, że żaden z operandów nie może być NULL, wynikiem predykatu zawsze będzie TRUE lub FALSE. Jest to tak zwana dwuwartościowa logika predykatów lub w skrócie po prostu dwuwartościowa logika. Dzieje się tak na przykład, gdy porównujesz kolumnę, która jest zdefiniowana jako nie zezwalająca na wartości NULL z jakimś innym operandem innym niż NULL.
Jeśli którykolwiek z operandów w porównaniu może być wartością NULL, powiedzmy, kolumną, która zezwala na wartości NULL, używając zarówno operatorów równości (=), jak i nierówności (<>,>, <,>=, <=itd.), jesteś teraz na łasce trójwartościowej logiki predykatów. Jeśli w danym porównaniu te dwa operandy nie są wartościami NULL, nadal otrzymujesz jako wynik TRUE lub FALSE. Jeśli jednak któryś z operandów ma wartość NULL, otrzymasz trzecią wartość logiczną o nazwie UNKNOWN. Zauważ, że tak jest nawet przy porównywaniu dwóch wartości NULL. Traktowanie TRUE i FALSE przez większość elementów SQL jest dość intuicyjne. Traktowanie UNKNOWN nie zawsze jest tak intuicyjne. Co więcej, różne elementy SQL w różny sposób radzą sobie z przypadkiem UNKNOWN, co wyjaśnię szczegółowo w dalszej części artykułu pod hasłem „Niespójności w traktowaniu NULL”.
Załóżmy na przykład, że musisz wykonać zapytanie do tabeli Sales.Orders w przykładowej bazie danych TSQLV5 i zwrócić zamówienia, które zostały wysłane 2 stycznia 2019 r. Używasz następującego zapytania:
UŻYJ TSQLV5; SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż.ZamówieniaWHERE data wysyłki ='20190102';
Oczywiste jest, że predykat filtra ma wartość TRUE dla wierszy, w których data wysłania to 2 stycznia 2019 r., i że te wiersze powinny zostać zwrócone. Jasne jest również, że predykat ma wartość FAŁSZ dla wierszy, w których występuje data wysłania, ale nie jest to data 2 stycznia 2019 r., i że te wiersze należy odrzucić. Ale co z wierszami z datą wysłania NULL? Pamiętaj, że zarówno predykaty oparte na równości, jak i predykaty oparte na nierównościach zwracają UNKNOWN, jeśli którykolwiek z operandów ma wartość NULL. Filtr WHERE jest przeznaczony do odrzucania takich wierszy. Należy pamiętać, że filtr GDZIE zwraca wiersze, dla których predykat filtra ma wartość TRUE i odrzuca wiersze, dla których predykat ma wartość FALSE lub UNKNOWN.
To zapytanie generuje następujące dane wyjściowe:
identyfikator zamówienia data wysyłki----------- -----------10771 2019-01-0210794 2019-01-0210802 2019-01-02
Załóżmy, że musisz zwrócić zamówienia, które nie zostały wysłane 2 stycznia 2019 r. Jeśli chodzi o Ciebie, zamówienia, które nie zostały jeszcze wysłane, powinny zostać uwzględnione w wynikach. Używasz zapytania podobnego do poprzedniego, tylko negującego predykat, na przykład:
SELECT identyfikator zamówienia, senddateFROM Sales.OrdersWHERE NOT (data wysyłki =„20190102”);
To zapytanie zwraca następujące dane wyjściowe:
identyfikator zamówienia data wysyłki----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (806 wierszy dotyczy)
Dane wyjściowe naturalnie wykluczają wiersze z datą wysłania 2 stycznia 2019 r., ale także wiersze z datą wysłania NULL. To, co może być tutaj sprzeczne z intuicją, to to, co dzieje się, gdy używasz operatora NIE do zanegowania predykatu, którego wynikiem jest NIEZNANE. Oczywiście NIEPRAWDA to FAŁSZ, a NIE FAŁSZ to PRAWDA. Jednak NIE NIEZNANE pozostaje NIEZNANE. Logika SQL stojąca za tym projektem polega na tym, że jeśli nie wiesz, czy zdanie jest prawdziwe, nie wiesz również, czy to zdanie nie jest prawdziwe. Oznacza to, że podczas używania operatorów równości i nierówności w predykacie filtra, ani dodatnie, ani ujemne formy predykatu nie zwracają wierszy z wartościami NULL.
Ten przykład jest dość prosty. Istnieją trudniejsze przypadki dotyczące podzapytań. Istnieje powszechny błąd, gdy używasz predykatu NOT IN z podzapytaniem, gdy podzapytanie zwraca NULL wśród zwróconych wartości. Zapytanie zawsze zwraca pusty wynik. Powodem jest to, że dodatnia forma predykatu (część IN) zwraca TRUE, gdy zostanie znaleziona wartość zewnętrzna, i UNKNOWN, gdy nie zostanie znaleziona z powodu porównania z NULL. Wtedy negacja predykatu z operatorem NOT zawsze zwraca odpowiednio FALSE lub UNKNOWN — nigdy TRUE. Szczegółowo opisuję ten błąd w błędach, pułapkach i najlepszych praktykach T-SQL — podzapytaniach, w tym sugerowanych rozwiązaniach, rozważaniach dotyczących optymalizacji i najlepszych praktykach. Jeśli nie znasz jeszcze tego klasycznego błędu, koniecznie zapoznaj się z tym artykułem, ponieważ błąd jest dość powszechny i istnieją proste środki, które możesz podjąć, aby go uniknąć.
Wracając do naszych potrzeb, co z próbą zwrotu zamówień z datą wysyłki inną niż 2 stycznia 2019 r., przy użyciu innego operatora niż (<>):
SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE data wysyłki <> „20190102”;
Niestety, zarówno operatory równości, jak i nierówności dają wartość UNKNOWN, gdy którykolwiek z operandów ma wartość NULL, więc to zapytanie generuje następujące dane wyjściowe, takie jak poprzednie, z wyłączeniem wartości NULL:
identyfikator zamówienia data wysyłki----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (806 wierszy dotyczy)
Aby wyizolować kwestię porównań z wartościami NULL dającymi wartość UNKNOWN przy użyciu równości, nierówności i negacji dwóch rodzajów operatorów, wszystkie poniższe zapytania zwracają pusty zbiór wyników:
SELECT identyfikator zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaWHERE datawysyłki =NULL; SELECT identyfikator zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaWHERE NOT (datawysyłki =NULL); SELECT identyfikator zamówienia, datawysyłkiFROM Sprzedaż.ZamówieniaWHERE datawysyłki <> NULL; SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE NOT (data wysyłki <> NULL);
Zgodnie z SQL, nie powinieneś sprawdzać, czy coś jest równe NULL lub inne niż NULL, ale czy coś jest NULL lub nie jest NULL, używając odpowiednio operatorów specjalnych IS NULL i IS NOT NULL. Operatory te używają logiki dwuwartościowej, zawsze zwracając PRAWDA lub FAŁSZ. Na przykład użyj operatora IS NULL, aby zwrócić niewysłane zamówienia, jak na przykład:
SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż. ZamówieniaWHERE data wysyłki JEST NULL;
To zapytanie generuje następujące dane wyjściowe:
identyfikator zamówienia data wysyłki----------- -----------11008 NULL11019 NULL11039 NULL... (dotyczy 21 wierszy)
Użyj operatora IS NOT NULL, aby zwrócić wysłane zamówienia, na przykład:
SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż. ZamówieniaWHERE data wysyłki NIE JEST NULL;
To zapytanie generuje następujące dane wyjściowe:
identyfikator zamówienia data wysyłki----------- -----------10249 2017-07-1010252 2017-07-1110250 2017-07-12...11050 2019-05 -0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06 (809 wierszy dotyczy)
Użyj poniższego kodu, aby zwrócić zamówienia, które zostały wysłane w dniu innym niż 2 stycznia 2019 r., a także zamówienia niewysłane:
SELECT identyfikator zamówienia, data wysyłkiFROM Sales. OrdersWHERE data wysyłki <> „20190102” LUB data wysyłki JEST NULL;
To zapytanie generuje następujące dane wyjściowe:
W dalszej części serii omówię standardowe funkcje dla traktowania NULL, których obecnie brakuje w T-SQL, w tym predykat DISTINCT , które mogą znacznie uprościć obsługę NULL.
Porównania ze zmiennymi, parametrami i kolumnami
W poprzedniej sekcji skupiono się na predykatach, które porównują kolumnę ze stałą. W rzeczywistości jednak najczęściej będziesz porównywać kolumnę ze zmiennymi/parametrami lub z innymi kolumnami. Takie porównania pociągają za sobą dalsze komplikacje.
Z punktu widzenia obsługi NULL zmienne i parametry są traktowane tak samo. Będę używał zmiennych w moich przykładach, ale uwagi, które robię na temat ich obsługi, są tak samo istotne dla parametrów.
Rozważ następujące podstawowe zapytanie (nazwę je Zapytanie 1), które filtruje zamówienia wysłane w określonym dniu:
DECLARE @dt JAKO DATA ='20190212'; SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż.ZamówieniaWHERE data wysyłki =@dt;
Używam zmiennej w tym przykładzie i inicjuję ją z pewną przykładową datą, ale równie dobrze może to być sparametryzowane zapytanie w procedurze składowanej lub funkcji zdefiniowanej przez użytkownika.
To wykonanie zapytania generuje następujące dane wyjściowe:
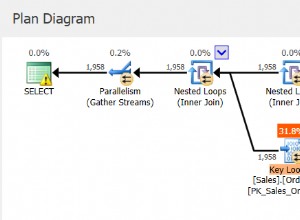
Plan dla zapytania 1 pokazano na rysunku 1.
 Rysunek 1:Plan dla zapytania 1
Rysunek 1:Plan dla zapytania 1
Tabela zawiera indeks pokrywający, który obsługuje to zapytanie. Indeks nazywa się idx_nc_shippeddate i jest zdefiniowany za pomocą listy kluczy (shippeddate, orderid). Predykat filtra zapytania jest wyrażony jako argument wyszukiwania (SARG) , co oznacza, że umożliwia optymalizatorowi rozważenie zastosowania operacji wyszukiwania w indeksie pomocniczym, przechodząc bezpośrednio do zakresu kwalifikujących się wierszy. To, co sprawia, że predykat filtru SARG jest możliwy do zrealizowania, polega na tym, że używa operatora, który reprezentuje kolejny zakres kwalifikujących się wierszy w indeksie, i że nie stosuje manipulacji do filtrowanej kolumny. Otrzymany plan jest optymalnym planem dla tego zapytania.
Ale co, jeśli chcesz, aby użytkownicy mogli prosić o niewysłane zamówienia? Takie zamówienia mają NULL datę wysyłki. Oto próba przekazania NULL jako daty wejściowej:
DECLARE @dt AS DATE =NULL; SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż.ZamówieniaWHERE data wysyłki =@dt;
Jak już wiesz, predykat używający operatora równości tworzy UNKNOWN, gdy którykolwiek z operandów ma wartość NULL. W konsekwencji to zapytanie zwraca pusty wynik:
identyfikator zamówienia data wysyłki----------- -----------(0 wierszy dotyczy)
Mimo że T-SQL obsługuje operator IS NULL, nie obsługuje jawnego operatora IS
DECLARE @dt AS DATE =NULL; SELECT identyfikator zamówienia, senddateFROM Sales.OrdersWHERE ISNULL(shippeddate, '99991231') =ISNULL(@dt, '99991231');
To zapytanie generuje poprawne dane wyjściowe:
identyfikator zamówienia data wysyłki----------- -----------11008 NULL11019 NULL11039 NULL...11075 NULL11076 NULL11077 NULL (dotyczy 21 wierszy)
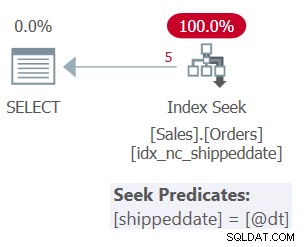
Ale plan dla tego zapytania, jak pokazano na rysunku 2, nie jest optymalny.
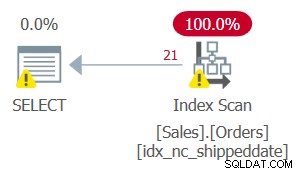 Rysunek 2:Plan dla zapytania 2
Rysunek 2:Plan dla zapytania 2
Ponieważ zastosowano manipulację do filtrowanej kolumny, predykat filtru nie jest już uważany za SARG. Indeks nadal obejmuje, więc można go używać; ale zamiast stosowania wyszukiwania w indeksie przechodzącego bezpośrednio do zakresu kwalifikujących się wierszy, skanowany jest cały liść indeksu. Załóżmy, że tabela zawiera 50 000 000 zamówień, a tylko 1000 to zamówienia niewysłane. Ten plan skanowałby wszystkie 50 000 000 wierszy zamiast wyszukiwania, które przechodzi bezpośrednio do kwalifikującego się 1000 wierszy.
Jedną z form predykatu filtru, w której oba mają poprawne znaczenie, którego szukamy i która jest uważana za argument wyszukiwania, jest (datawysyłki =@dt LUB (datawysyłki JEST NULL I @dt JEST NULL)). Oto zapytanie używające predykatu SARGable (nazwiemy je Zapytanie 3):
DECLARE @dt AS DATE =NULL; SELECT identyfikator zamówienia, senddateFROM Sales.OrdersWHERE (data wysyłki =@dt OR (data wysyłki JEST NULL ORAZ @dt JEST NULL));
Plan dla tego zapytania pokazano na rysunku 3.
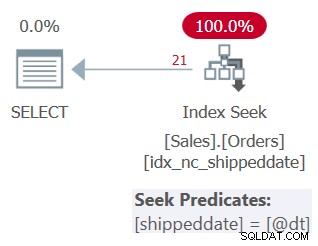 Rysunek 3:Plan dla zapytania 3
Rysunek 3:Plan dla zapytania 3
Jak widać, plan stosuje wyszukiwanie w indeksie pomocniczym. Predykat seek mówi senddate =@dt, ale jest wewnętrznie zaprojektowany do obsługi wartości NULL, tak jak wartości inne niż NULL, ze względu na porównanie.
To rozwiązanie jest powszechnie uważane za rozsądne. Jest standardowy, optymalny i poprawny. Jego główną wadą jest to, że jest gadatliwy. Co by było, gdybyś miał wiele predykatów filtrujących opartych na kolumnach dopuszczających NULL? Szybko otrzymasz długą i kłopotliwą klauzulę WHERE. A jest znacznie gorzej, gdy trzeba napisać predykat filtrujący obejmujący kolumnę dopuszczalną NULL, która szuka wierszy, w których kolumna jest inna niż parametr wejściowy. Predykat staje się wtedy:(shippeddate <> @dt AND ((shippeddate JEST NULL ORAZ @dt IS NOT NULL) LUB (shippeddate JEST NULL i @dt JEST NULL))).
Widać wyraźnie potrzebę bardziej eleganckiego rozwiązania, które byłoby jednocześnie zwięzłe i optymalne. Niestety niektórzy uciekają się do niestandardowego rozwiązania, w którym wyłącza się opcję sesji ANSI_NULLS. Ta opcja powoduje, że SQL Server używa niestandardowej obsługi równości (=) i operatorów różnych niż (<>) z logiką dwuwartościową zamiast trójwartościowej, traktując wartości NULL tak samo jak wartości inne niż NULL do celów porównawczych. Tak jest przynajmniej, o ile jeden z operandów jest parametrem/zmienną lub literałem.
Uruchom następujący kod, aby wyłączyć opcję ANSI_NULLS w sesji:
WYŁĄCZ ANSI_NULLS;
Uruchom następujące zapytanie, używając prostego predykatu opartego na równości:
DECLARE @dt AS DATE =NULL; SELECT identyfikator zamówienia, data wysyłkiFROM Sprzedaż.ZamówieniaWHERE data wysyłki =@dt;
To zapytanie zwraca 21 niewysłanych zamówień. Otrzymujesz ten sam plan, który pokazano wcześniej na rysunku 3, pokazując wyszukiwanie w indeksie.
Uruchom następujący kod, aby przełączyć się z powrotem do standardowego zachowania, gdy ANSI_NULLS jest włączone:
WŁĄCZ ANSI_NULLS;
Zdecydowanie odradza się poleganie na takim niestandardowym zachowaniu. Dokumentacja stwierdza również, że obsługa tej opcji zostanie usunięta w niektórych przyszłych wersjach programu SQL Server. Co więcej, wielu nie zdaje sobie sprawy, że ta opcja ma zastosowanie tylko wtedy, gdy przynajmniej jeden z operandów jest parametrem/zmienną lub stałą, mimo że dokumentacja jest na ten temat dość jasna. Nie ma to zastosowania przy porównywaniu dwóch kolumn, na przykład w łączeniu.
Jak więc poradzić sobie ze złączeniami obejmującymi kolumny złączeń dopuszczające NULL, jeśli chcesz uzyskać dopasowanie, gdy obie strony mają wartości NULL? Jako przykład użyj następującego kodu, aby utworzyć i wypełnić tabele T1 i T2:
DROP TABLE IF EXISTS dbo.T1, dbo.T2;GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2 , k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) WARTOŚCI (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C') ,(1, 1, 0, 'D'),(0, NULL, 1, 'F'); WSTAW W dbo.T2(k1, k2, k3, val2) WARTOŚCI (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I') ,(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Kod tworzy indeksy pokrywające w obu tabelach, aby obsługiwać łączenie oparte na kluczach łączenia (k1, k2, k3) po obu stronach.
Użyj poniższego kodu, aby zaktualizować statystyki kardynalności, zwiększając liczby tak, aby optymalizator pomyślał, że masz do czynienia z większymi tabelami:
ZAKTUALIZUJ STATYSTYKI dbo.T1(UNQ_T1) Z ROWCOUNT =1000000; AKTUALIZUJ STATYSTYKI dbo.T2(UNQ_T2) Z ROWCOUNT =1000000;
Użyj następującego kodu, aby połączyć dwie tabele za pomocą prostych predykatów opartych na równości:
WYBIERZ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 SPRZECZENIE WEWNĘTRZNE dbo.T2 ON T1.k1 =T2.k1 AND T1.k2 =T2.k2 AND T1. k3 =T2.k3;
Podobnie jak we wcześniejszych przykładach filtrowania, również tutaj porównania między wartościami NULL przy użyciu operatora równości dają UNKNOWN, co skutkuje niedopasowaniami. To zapytanie generuje puste dane wyjściowe:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------(0 wpływa na wiersze)
Użycie ISNULL lub COALESCE, tak jak we wcześniejszym przykładzie filtrowania, zastąpienie wartości NULL wartością, która normalnie nie może pojawić się w danych po obu stronach, daje w wyniku poprawne zapytanie (nazywam to zapytanie zapytaniem 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON ISNULL(T1.k1, -2147483648) =ISNULL(T2.k1, -2147483648 ) AND ISNULL(T1.k2, -2147483648) =ISNULL(T2.k2, -2147483648) AND ISNULL(T1.k3, -2147483648) =ISNULL(T2.k3, -2147483648);
To zapytanie generuje następujące dane wyjściowe:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------0 NULL NULL C I0 NULL 1 F K
Jednak podobnie jak manipulowanie filtrowaną kolumną łamie zdolność SARG predykatu filtra, manipulowanie kolumną sprzężenia uniemożliwia poleganie na kolejności indeksu. Można to zobaczyć w planie dla tego zapytania, jak pokazano na rysunku 4.
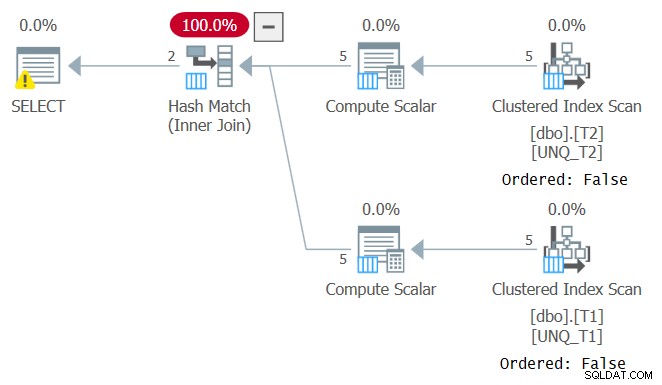 Rysunek 4:Plan dla zapytania 4
Rysunek 4:Plan dla zapytania 4
Optymalny plan dla tego zapytania to taki, który stosuje uporządkowane skany dwóch indeksów obejmujących, po których następuje algorytm Merge Join, bez jawnego sortowania. Optymalizator wybrał inny plan, ponieważ nie mógł polegać na kolejności indeksowania. Jeśli spróbujesz wymusić algorytm Merge Join przy użyciu INNER MERGE JOIN, plan nadal będzie polegał na nieuporządkowanych skanach indeksów, po których nastąpi jawne sortowanie. Spróbuj!
Oczywiście możesz użyć długich predykatów podobnych do predykatów SARGable pokazanych wcześniej do zadań filtrowania:
WYBIERZ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 SPRZECZENIE WEWNĘTRZNE dbo.T2 ON (T1.k1 =T2.k1 LUB (T1.k1 JEST NULL AND T2) K1 JEST NULL)) AND (T1.k2 =T2.k2 LUB (T1.k2 JEST NULL I T2.K2 JEST NULL)) AND (T1.k3 =T2.k3 OR (T1.k3 JEST NULL I T2.K3 JEST NULL)) NULL));
To zapytanie daje pożądany wynik i umożliwia optymalizatorowi poleganie na kolejności indeksów. Jednak naszą nadzieją jest znalezienie rozwiązania, które będzie zarówno optymalne, jak i zwięzłe.
Istnieje mało znana, elegancka i zwięzła technika, której można używać zarówno w sprzężeniach, jak i filtrach, zarówno w celu identyfikacji dopasowań, jak i identyfikacji niedopasowań. Ta technika została odkryta i udokumentowana już wiele lat temu, tak jak we wspaniałym artykule Paula White'a Plany nieudokumentowanych zapytań:Porównania równości z 2011 roku. Ale z jakiegoś powodu wydaje się, że wiele osób wciąż o tym nie wie i niestety kończą używanie nieoptymalnych, długich i niestandardowe rozwiązania. Z pewnością zasługuje na większą ekspozycję i miłość.
Technika ta opiera się na fakcie, że operatory zbiorów, takie jak INTERSECT i EXCEPT, używają podejścia opartego na odrębności podczas porównywania wartości, a nie podejścia opartego na równości lub nierówności.
Rozważ nasze wspólne zadanie jako przykład. Gdybyśmy nie musieli zwracać kolumn innych niż klucze złączenia, użylibyśmy prostego zapytania (nazwę go Query 5) z operatorem INTERSECT, na przykład:
SELECT k1, k2, k3 FROM dbo.T1INTERSECTSELECT k1, k2, k3 FROM dbo.T2;
To zapytanie generuje następujące dane wyjściowe:
k1 k2 k3----------- ----------- -----------0 NULL NULL0 NULL 1
Plan dla tego zapytania pokazano na rysunku 5, który potwierdza, że optymalizator mógł polegać na kolejności indeksów i używać algorytmu łączenia łączenia.
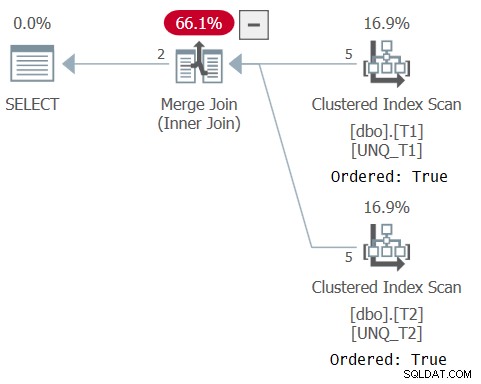 Rysunek 5:Plan dla zapytania 5
Rysunek 5:Plan dla zapytania 5
Jak zauważa Paul w swoim artykule, plan XML dla operatora zbioru używa niejawnego operatora porównania IS (CompareOp="IS" ) w przeciwieństwie do operatora porównania EQ używanego w normalnym złączeniu (CompareOp="EQ" ). Problem z rozwiązaniem, które opiera się wyłącznie na operatorze zbioru, polega na tym, że ogranicza ono do zwracania tylko kolumn, które porównujesz. To, czego naprawdę potrzebujemy, to rodzaj hybrydy między złączeniem a operatorem mnogościowym, pozwalającej na porównywanie podzbioru elementów przy jednoczesnym zwróceniu dodatkowych elementów, tak jak robi to złącze, i używając porównania opartego na odrębności (IS), tak jak robi to operator mnogościowy. Jest to osiągalne przez użycie sprzężenia jako konstrukcji zewnętrznej i predykatu EXISTS w klauzuli ON sprzężenia opartego na zapytaniu z operatorem INTERSECT porównującym klucze sprzężenia z dwóch stron, tak jak to (będę nazywał to Query 6):
WYBIERZ T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(WYBIERZ T1.k1, T1.k2, T1.k3 PRZECIĘCIE WYBIERZ T2. k1, T2.k2, T2.k3);
Operator INTERSECT operuje na dwóch zapytaniach, z których każde tworzy zestaw jednego wiersza na podstawie kluczy sprzężenia z obu stron. Gdy dwa wiersze są takie same, zapytanie INTERSECT zwraca jeden wiersz; predykat EXISTS zwraca TRUE, co skutkuje dopasowaniem. Gdy te dwa wiersze nie są takie same, zapytanie INTERSECT zwraca pusty zestaw; predykat EXISTS zwraca FALSE, co skutkuje niedopasowaniem.
To rozwiązanie generuje pożądany wynik:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------0 NULL NULL C I0 NULL 1 F K
Plan dla tego zapytania pokazano na rysunku 6, potwierdzając, że optymalizator mógł polegać na kolejności indeksów.
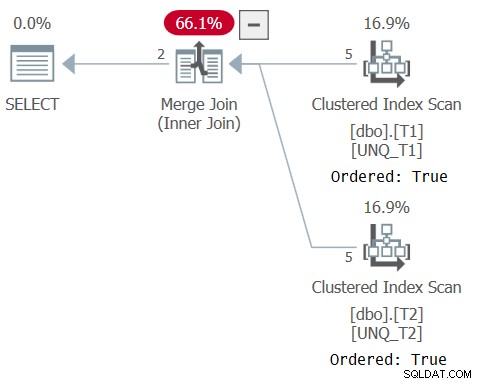 Rysunek 6:Plan dla zapytania 6
Rysunek 6:Plan dla zapytania 6
Możesz użyć podobnej konstrukcji jako predykatu filtra obejmującego kolumnę i parametr/zmienną do wyszukiwania dopasowań na podstawie odrębności, na przykład:
DECLARE @dt AS DATE =NULL; SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE EXISTS (SELECT data wysyłki INTERSECT SELECT @dt);
Plan jest taki sam, jak ten pokazany wcześniej na rysunku 3.
Możesz także zanegować predykat, aby wyszukać niedopasowania, na przykład:
DECLARE @dt JAKO DATA ='20190212'; SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE NOT EXISTS (SELECT data wysyłki INTERSECT SELECT @dt);
To zapytanie generuje następujące dane wyjściowe:
Alternatywnie możesz użyć predykatu dodatniego, ale zamień INTERSECT na EXCEPT, na przykład:
DECLARE @dt JAKO DATA ='20190212'; SELECT identyfikator zamówienia, data wysyłkiFROM Sales.OrdersWHERE EXISTS (SELECT data wysyłki EXCEPT SELECT @dt);
Pamiętaj, że plany w obu przypadkach mogą się różnić, więc upewnij się, że eksperymentujesz w obie strony z dużymi ilościami danych.
Wniosek
Wartości NULL dodają swój udział złożoności do pisania kodu SQL. Zawsze chcesz pomyśleć o potencjale obecności wartości NULL w danych i upewnić się, że używasz odpowiednich konstrukcji zapytań i dodajesz odpowiednią logikę do swoich rozwiązań, aby poprawnie obsługiwać wartości NULL. Ignorowanie ich to pewny sposób na pojawienie się błędów w kodzie. W tym miesiącu skupiłem się na tym, czym są wartości NULL i jak są obsługiwane w porównaniach obejmujących stałe, zmienne, parametry i kolumny. W przyszłym miesiącu będę kontynuować relację, omawiając niespójności w traktowaniu NULL w różnych elementach językowych oraz brakujące standardowe funkcje obsługi NULL.