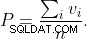Druga instrukcja zajmuje dużo czasu, ponieważ musi przeskanować całą tabelę, aby policzyć wiersze.
Jedyne, co możesz zrobić, to użyć indeksu:
CREATE INDEX ON tbl_oplog (deleted) INCLUDE (id);
VACUUM tbl_oplog; -- so you get an index only scan
Zakładając, że id jest kluczem podstawowym, znacznie lepiej byłoby użyć count(*) i pomiń INCLUDE klauzula z indeksu.
Ale najlepiej jest prawdopodobnie użyć oszacowania:
SELECT t.reltuples * freq.f AS estimated_rows
FROM pg_stats AS s
JOIN pg_namespace AS n
ON s.schemaname = n.nspname
JOIN pg_class AS t
ON s.tablename = t.relname
AND n.oid = t.relnamespace
CROSS JOIN LATERAL
unnest(s.most_common_vals::text::boolean[]) WITH ORDINALITY AS val(v,id)
JOIN LATERAL
unnest(s.most_common_freqs) WITH ORDINALITY AS freq(f,id)
USING (id)
WHERE s.tablename = 'tbl_oplog'
AND s.attname = 'deleted'
AND val.v = ?;
Wykorzystuje statystyki dystrybucji do oszacowania żądanej liczby.
Jeśli chodzi tylko o paginację, nie potrzebujesz dokładnych obliczeń.
Przeczytaj mojego bloga aby dowiedzieć się więcej na temat liczenia w PostgreSQL.