Wysoka dostępność jest obecnie koniecznością, ponieważ większość organizacji nie może sobie pozwolić na utratę danych. Jednak wysoka dostępność zawsze wiąże się z ceną (która może się znacznie różnić). Wszelkie konfiguracje, które wymagają niemal natychmiastowego działania, zwykle wymagają drogiego środowiska, które dokładnie odzwierciedla konfigurację produkcyjną. Ale są też inne opcje, które mogą być tańsze. Mogą one nie pozwolić na natychmiastowe przejście do klastra odzyskiwania po awarii, ale nadal zapewniają ciągłość biznesową (i nie obciążają budżetu).
Przykładem tego typu konfiguracji jest środowisko DR w trybie „zimnego czuwania”. Pozwala to na zmniejszenie wydatków, a jednocześnie na rozkręcenie nowego środowiska w zewnętrznej lokalizacji w przypadku katastrofy. W tym poście na blogu zademonstrujemy, jak stworzyć taką konfigurację.
Wstępna konfiguracja
Załóżmy, że mamy dość standardową konfigurację replikacji MySQL Master/Slave w naszym własnym centrum danych. Jest to wysoce dostępna konfiguracja z ProxySQL i Keepalived do obsługi wirtualnego adresu IP. Główne ryzyko polega na tym, że centrum danych stanie się niedostępne. Jest to mały DC, może to tylko jeden dostawca usług internetowych bez BGP. W tej sytuacji założymy, że jeśli przywrócenie bazy danych zajmie kilka godzin, to jest w porządku, o ile jest to możliwe.
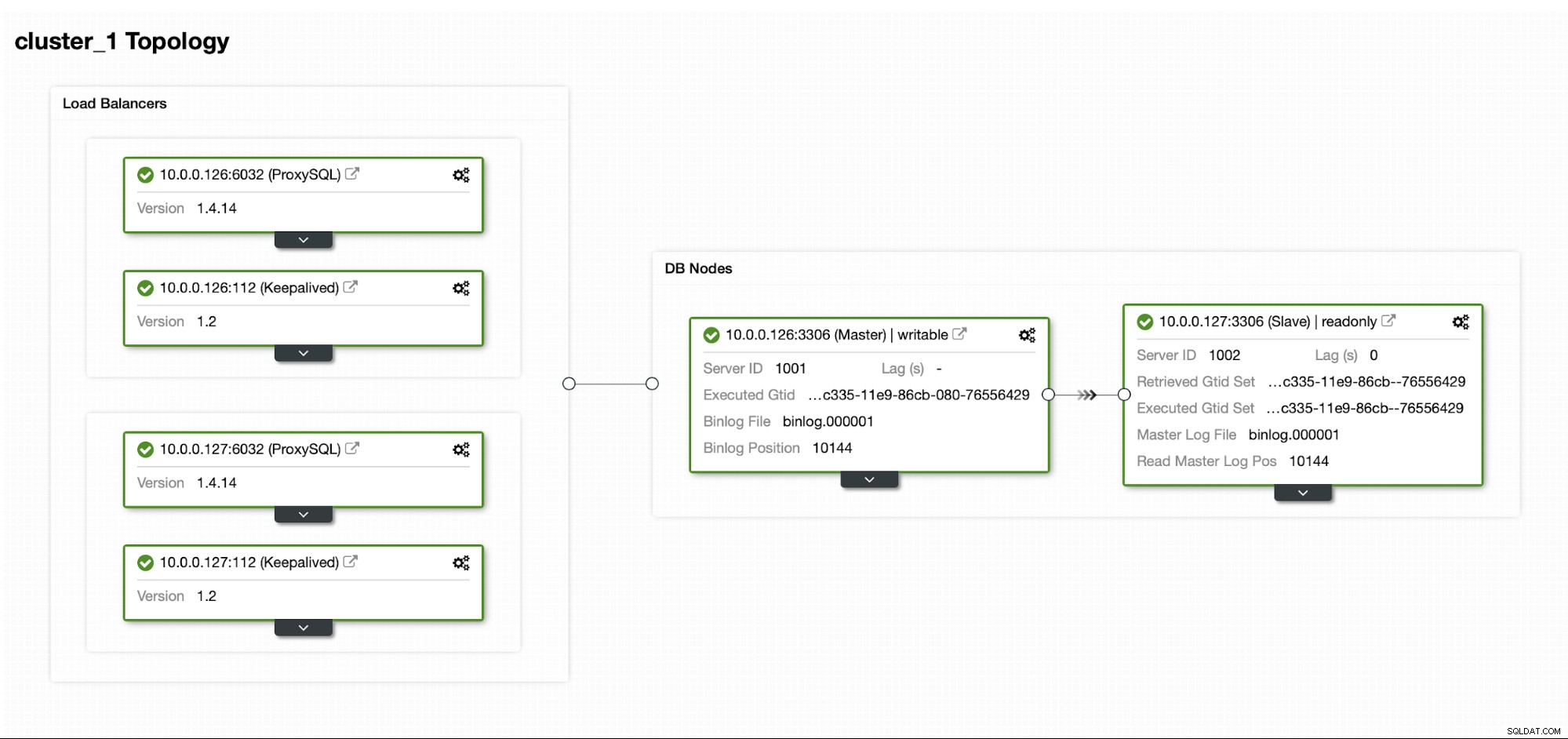
Do wdrożenia tego klastra użyliśmy programu ClusterControl, który można pobrać bezpłatnie. W naszym środowisku DR użyjemy EC2 (ale może to być również dowolny inny dostawca chmury).
Wyzwanie
Głównym problemem, z którym musimy się zmierzyć, jest to, w jaki sposób powinniśmy zapewnić, że mamy świeże dane, aby przywrócić naszą bazę danych w środowisku odzyskiwania po awarii? Oczywiście idealnie byłoby, gdybyśmy mieli działającego niewolnika replikacji w EC2... ale potem musimy za to zapłacić. Jeśli mamy napięty budżet, możemy spróbować obejść to za pomocą kopii zapasowych. Nie jest to idealne rozwiązanie, ponieważ w najgorszym przypadku nigdy nie będziemy w stanie odzyskać wszystkich danych.
Przez „najgorszy scenariusz” rozumiemy sytuację, w której nie będziemy mieć dostępu do oryginalnych serwerów baz danych. Jeśli będziemy mogli do nich dotrzeć, dane nie zostałyby utracone.
Rozwiązanie
Zamierzamy użyć ClusterControl do ustawienia harmonogramu tworzenia kopii zapasowych, aby zmniejszyć ryzyko utraty danych. Wykorzystamy również funkcję ClusterControl do przesyłania kopii zapasowych do chmury. Jeśli centrum danych nie będzie dostępne, możemy mieć nadzieję, że wybrany przez nas dostawca chmury będzie osiągalny.
Konfigurowanie harmonogramu tworzenia kopii zapasowych w ClusterControl
Najpierw będziemy musieli skonfigurować ClusterControl przy użyciu naszych danych logowania do chmury.
Możemy to zrobić za pomocą opcji „Integracje” z menu po lewej stronie.
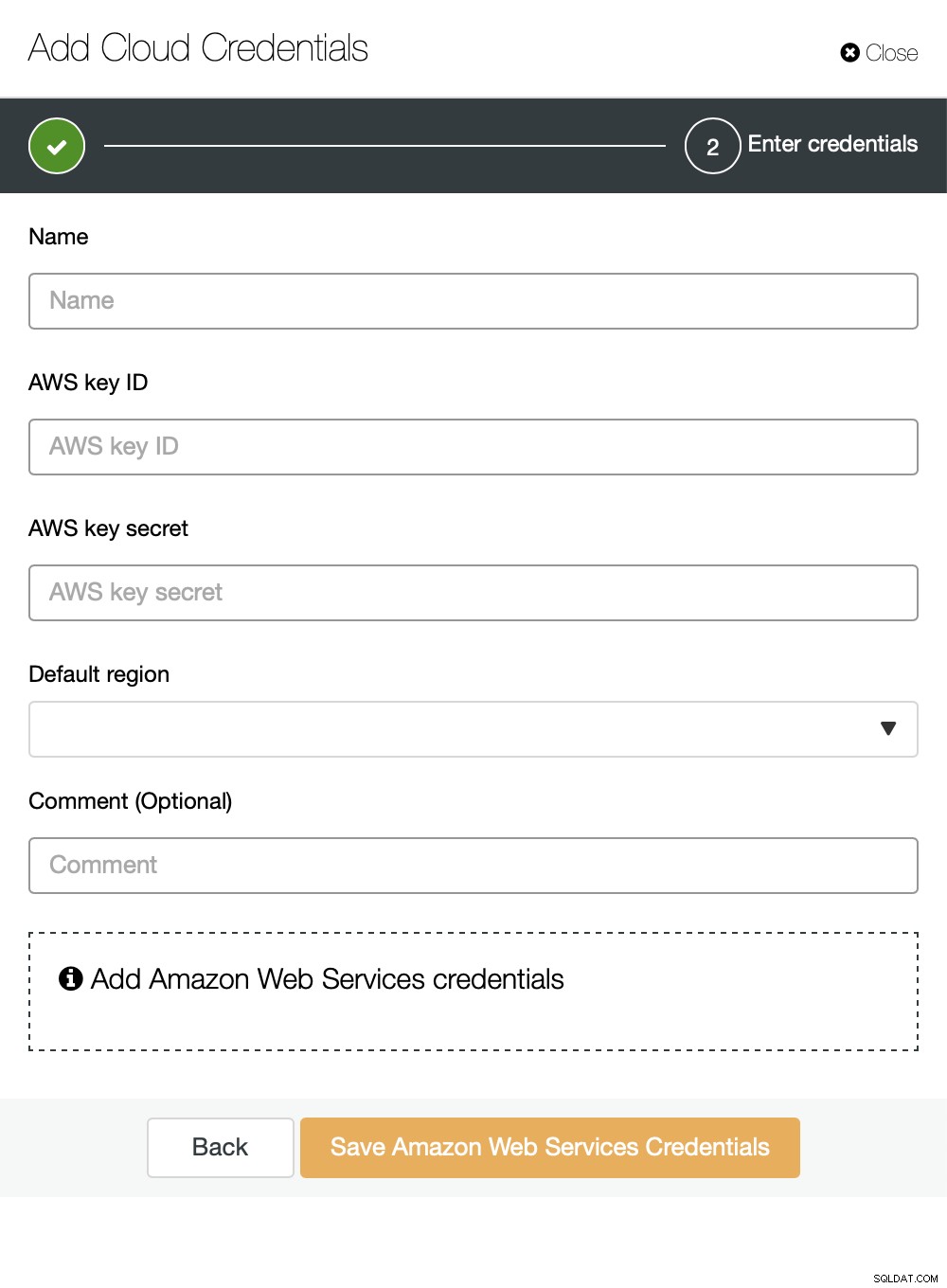
Możesz wybrać Amazon Web Services, Google Cloud lub Microsoft Azure jako chmurę chcesz, aby ClusterControl przesyłał kopie zapasowe. Będziemy kontynuować z AWS, w którym ClusterControl będzie używać S3 do przechowywania kopii zapasowych.
Następnie musimy przekazać identyfikator klucza i klucz tajny, wybierz region domyślny i wybierz nazwę dla tego zestawu danych uwierzytelniających.
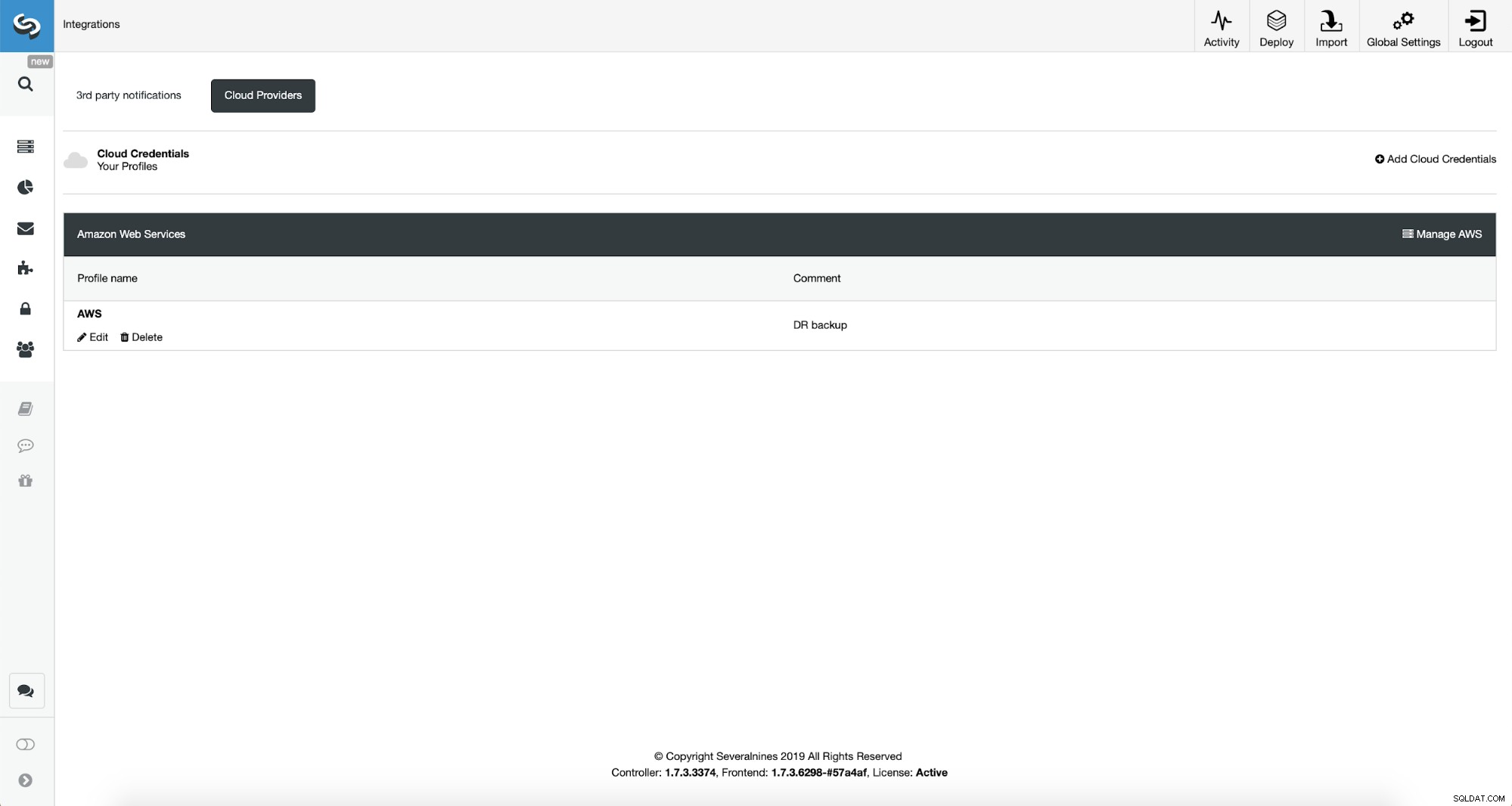
Po wykonaniu tej czynności możemy zobaczyć dodane przed chwilą poświadczenia wymienione w ClusterControl.
Teraz przystąpimy do konfigurowania harmonogramu tworzenia kopii zapasowych.
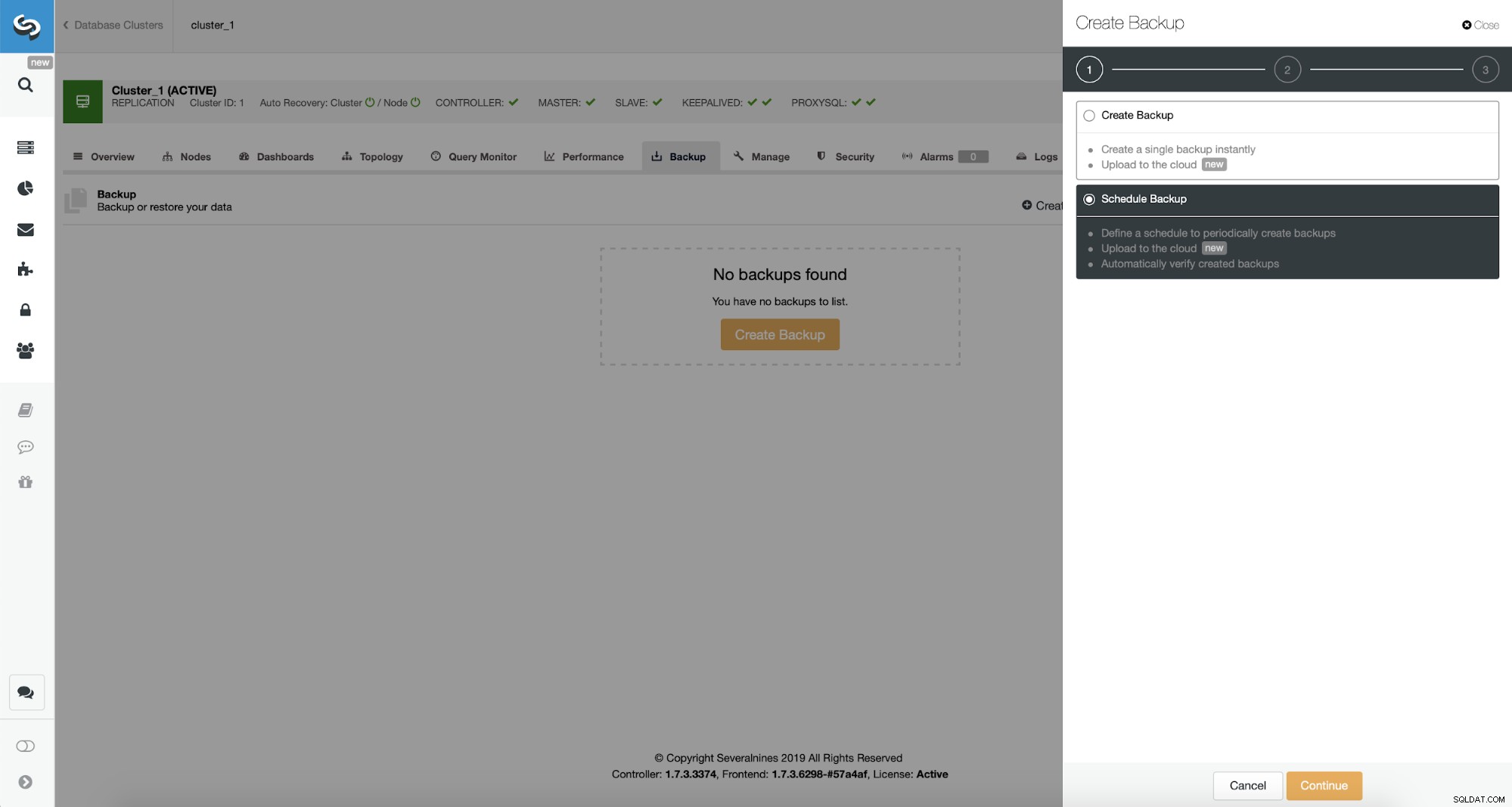
ClusterControl umożliwia natychmiastowe utworzenie kopii zapasowej lub jej zaplanowanie. Pójdziemy z drugą opcją. Chcemy stworzyć następujący harmonogram:
- Pełna kopia zapasowa tworzona raz dziennie
- Przyrostowe kopie zapasowe tworzone co 10 minut.
Pomysł jest następujący. W najgorszym przypadku stracimy tylko 10 minut ruchu. Jeśli centrum danych stanie się niedostępne z zewnątrz, ale będzie działać wewnętrznie, możemy spróbować uniknąć utraty danych, odczekując 10 minut, kopiując najnowszą przyrostową kopię zapasową na jakimś laptopie, a następnie ręcznie wysłać ją do naszej bazy danych DR, korzystając nawet z tetheringu przez telefon i połączenie komórkowe, aby obejść awarię usługodawcy internetowego. Jeśli przez jakiś czas nie będziemy w stanie wydobyć danych ze starego centrum danych, ma to na celu zminimalizowanie liczby transakcji, które będziemy musieli ręcznie połączyć z bazą danych DR.
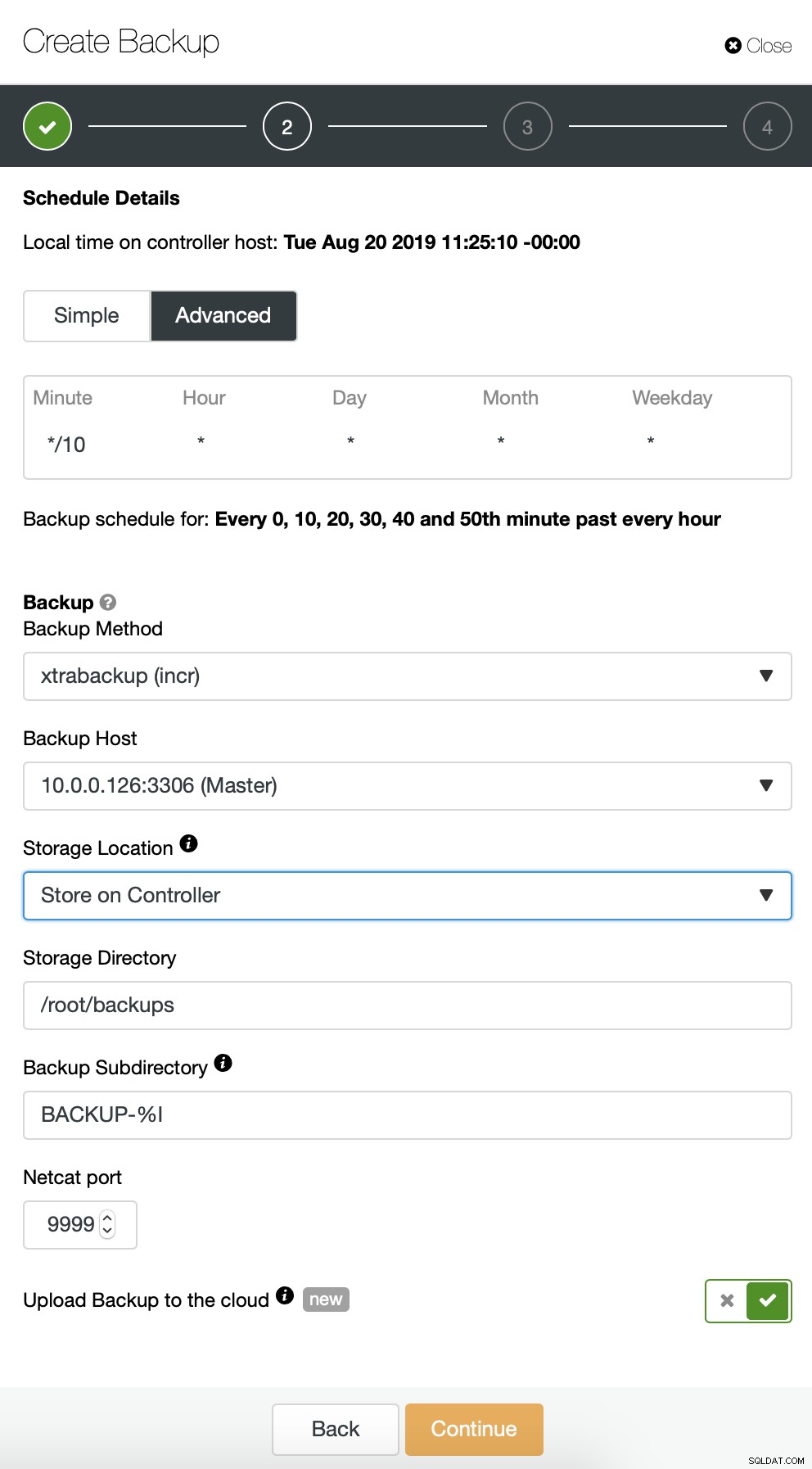
Zaczynamy od pełnej kopii zapasowej, która będzie wykonywana codziennie o 2:00. Użyjemy mastera do pobrania kopii zapasowej, przechowamy ją na kontrolerze w katalogu /root/backups/. Włączymy również opcję „Prześlij kopię zapasową do chmury”.
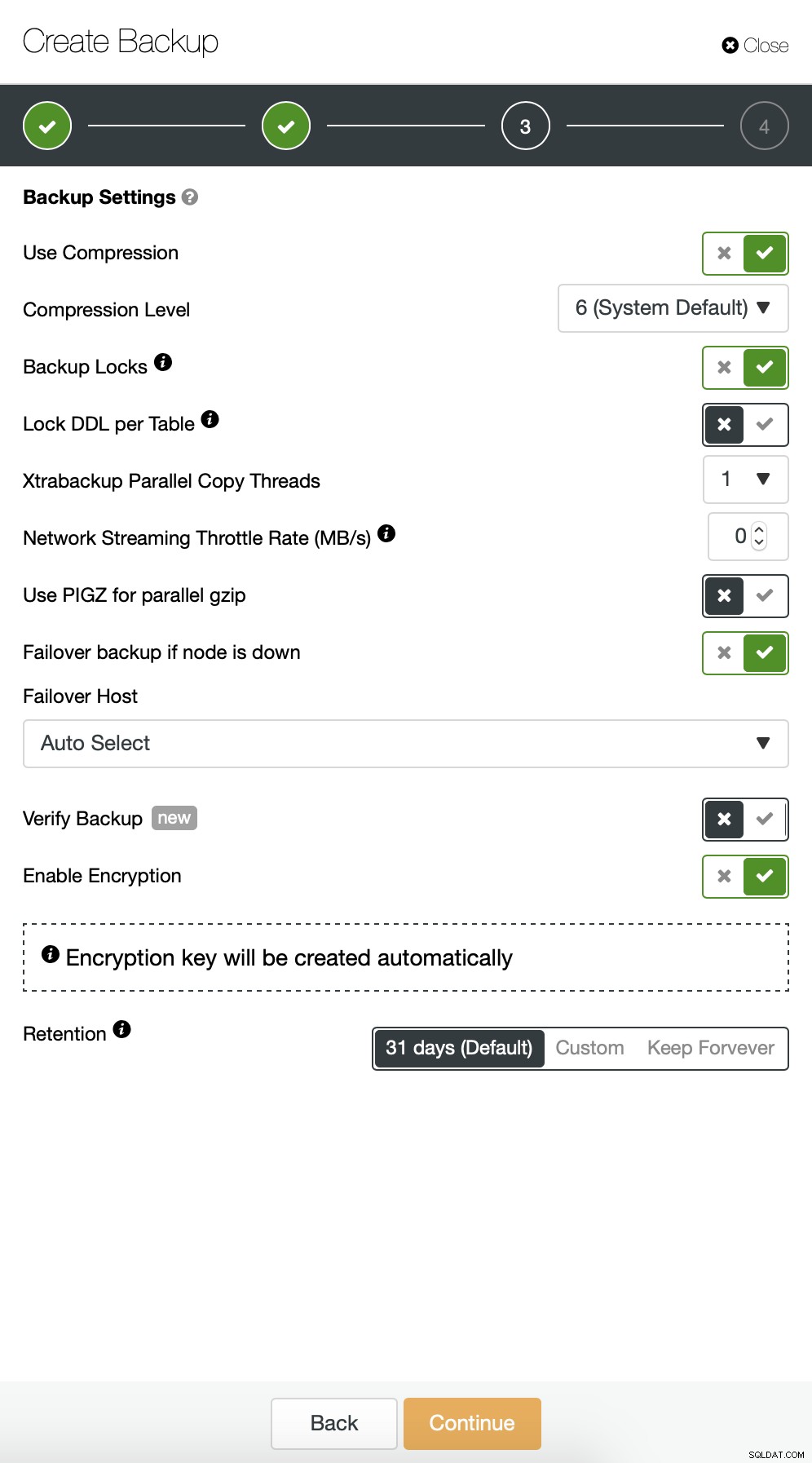
Następnie chcemy wprowadzić kilka zmian w domyślnej konfiguracji. Zdecydowaliśmy się na wybór automatycznie wybranego hosta awaryjnego (na wypadek gdyby nasz master był niedostępny, ClusterControl użyje dowolnego innego dostępnego węzła). Chcieliśmy również włączyć szyfrowanie, ponieważ będziemy wysyłać nasze kopie zapasowe przez sieć.
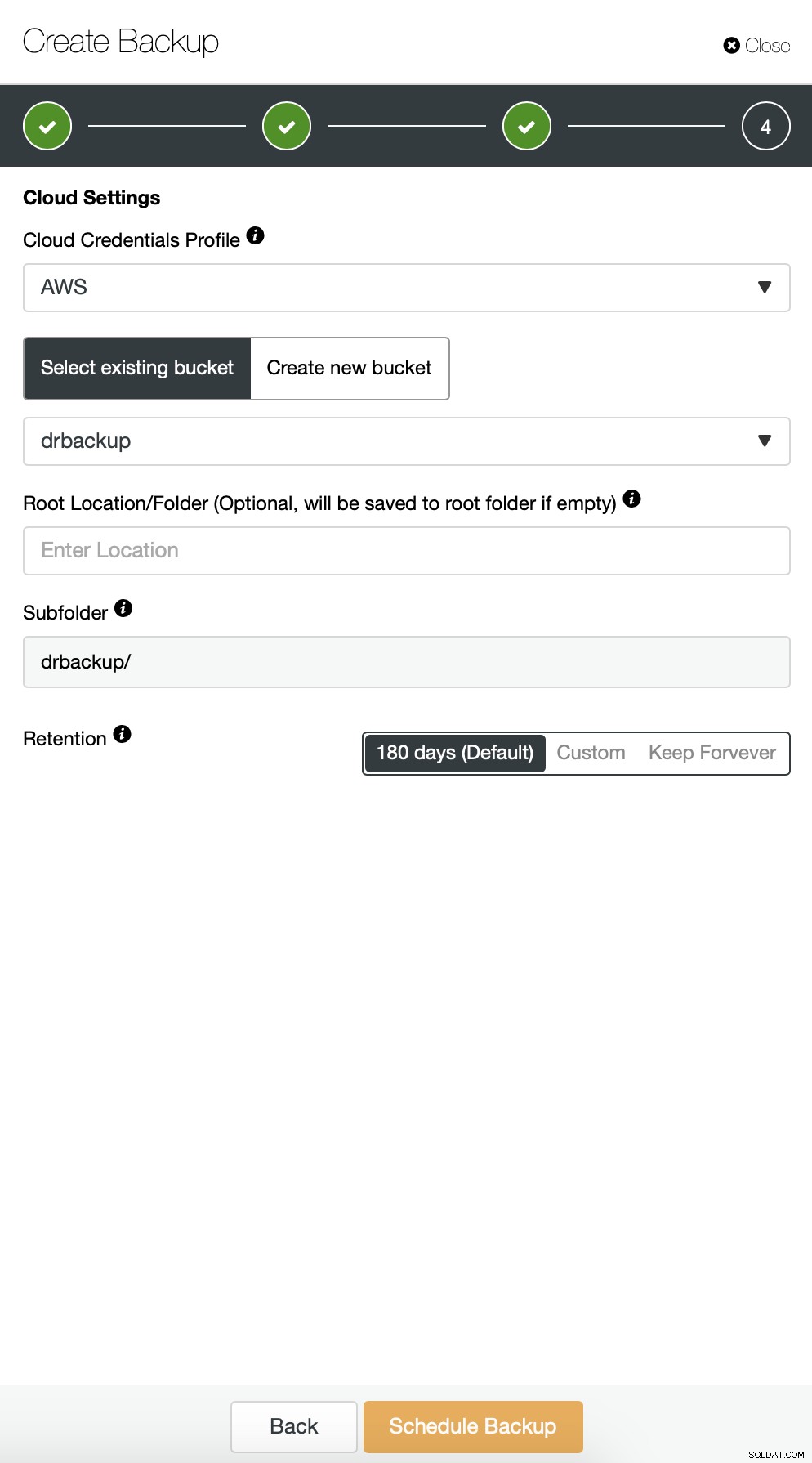
Następnie musimy wybrać dane uwierzytelniające, wybrać istniejący zasobnik S3 lub utworzyć w razie potrzeby nowy.
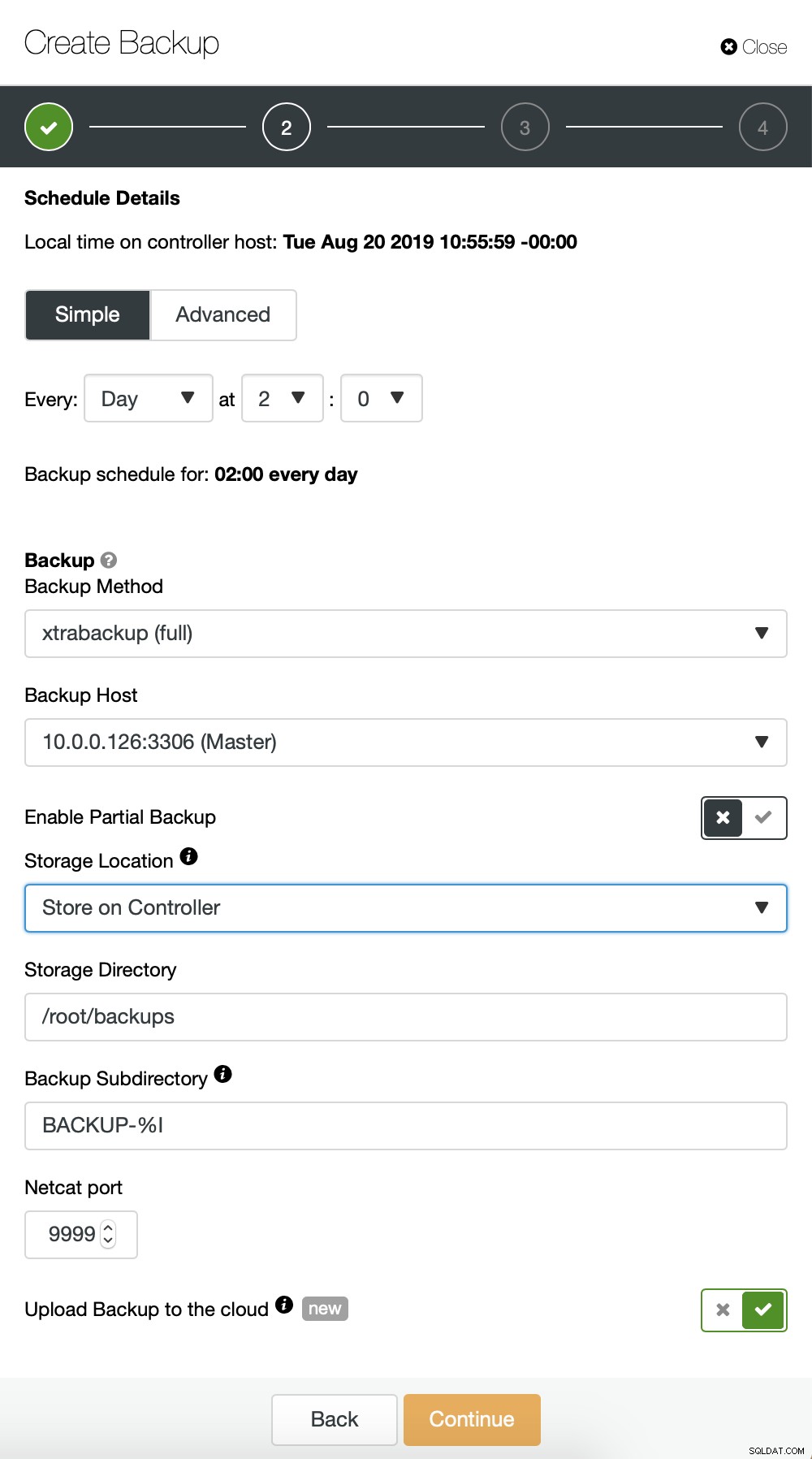
W zasadzie powtarzamy proces tworzenia przyrostowej kopii zapasowej, tym razem użyliśmy okno dialogowe „Zaawansowane”, aby uruchamiać kopie zapasowe co 10 minut.
Reszta ustawień jest podobna, możemy również ponownie użyć wiadra S3.
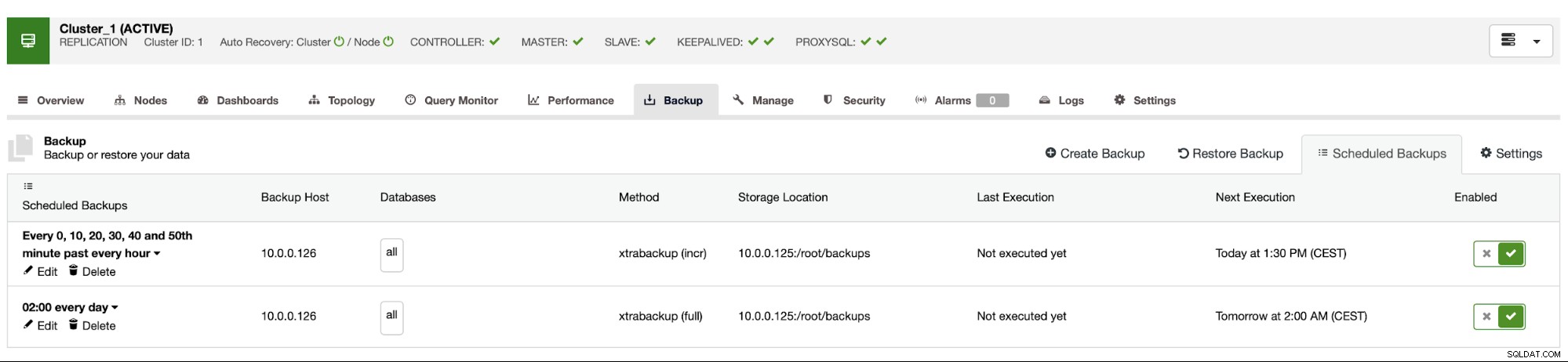
Harmonogram tworzenia kopii zapasowych wygląda jak powyżej. Nie musimy ręcznie uruchamiać pełnej kopii zapasowej, ClusterControl uruchomi przyrostową kopię zapasową zgodnie z planem, a jeśli wykryje, że nie jest dostępna pełna kopia zapasowa, uruchomi pełną kopię zapasową zamiast przyrostowej.
Przy takiej konfiguracji możemy śmiało powiedzieć, że możemy odzyskać dane w dowolnym systemie zewnętrznym z dokładnością do 10 minut.
Ręczne przywracanie kopii zapasowej
Jeśli zdarzy się, że będziesz musiał przywrócić kopię zapasową w instancji odzyskiwania po awarii, musisz wykonać kilka kroków. Zdecydowanie zalecamy testowanie tego procesu od czasu do czasu, upewniając się, że działa poprawnie i jesteś biegły w jego wykonywaniu.
Najpierw musimy zainstalować narzędzie wiersza poleceń AWS na naszym serwerze docelowym:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userNastępnie musimy skonfigurować go z odpowiednimi danymi uwierzytelniającymi:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonMożemy teraz przetestować, czy mamy dostęp do danych w naszym zasobniku S3:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Teraz musimy pobrać dane. Stworzymy katalog na kopie zapasowe - pamiętaj, że musimy pobrać cały zestaw kopii zapasowych - zaczynając od pełnej kopii zapasowej do ostatniej kopii przyrostowej, którą chcemy zastosować.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Teraz są dwie opcje. Kopie zapasowe możemy pobierać pojedynczo:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Możemy również, zwłaszcza jeśli masz napięty harmonogram rotacji, zsynchronizować całą zawartość zasobnika z tym, co mamy lokalnie na serwerze:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Jak pamiętasz, kopie zapasowe są szyfrowane. Musimy mieć klucz szyfrowania, który jest przechowywany w ClusterControl. Upewnij się, że jego kopia jest przechowywana w bezpiecznym miejscu, poza głównym centrum danych. Jeśli nie możesz do niego dotrzeć, nie będziesz w stanie odszyfrować kopii zapasowych. Klucz można znaleźć w konfiguracji ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Jest zakodowany przy użyciu base64, dlatego musimy go najpierw zdekodować i zapisać w pliku, zanim będziemy mogli rozpocząć odszyfrowywanie kopii zapasowej:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> hasło
Teraz możemy ponownie użyć tego pliku do odszyfrowania kopii zapasowych. Na razie załóżmy, że wykonamy jedną pełną i dwie przyrostowe kopie zapasowe.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Mamy odszyfrowane dane, teraz musimy przystąpić do konfiguracji naszego serwera MySQL. Najlepiej byłoby, gdyby była to dokładnie ta sama wersja, co w systemach produkcyjnych. Użyjemy Percona Server dla MySQL:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Nic skomplikowanego, tylko regularna instalacja. Gdy wszystko będzie gotowe i gotowe, musimy go zatrzymać i usunąć zawartość jego katalogu danych.
service mysql stop
rm -rf /var/lib/mysql/*Aby przywrócić kopię zapasową, będziemy potrzebować Xtrabackup - narzędzia, którego CC używa do jej utworzenia (przynajmniej dla Perona i Oracle MySQL, MariaDB używa MariaBackup). Ważne jest, aby to narzędzie było zainstalowane w tej samej wersji, co na serwerach produkcyjnych:
apt install percona-xtrabackup-24To wszystko, co musimy przygotować. Teraz możemy rozpocząć przywracanie kopii zapasowej. W przypadku przyrostowych kopii zapasowych należy pamiętać, że należy je przygotować i zastosować na podstawowej kopii zapasowej. Należy również przygotować kopię zapasową bazy. Bardzo ważne jest uruchomienie przygotowania z opcją „--apply-log-only”, aby zapobiec uruchomieniu przez xtrabackup fazy wycofywania. W przeciwnym razie nie będziesz w stanie zastosować następnej przyrostowej kopii zapasowej.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/W ostatnim poleceniu zezwoliliśmy xtrabackup na wycofywanie nieukończonych transakcji - później nie będziemy stosować więcej przyrostowych kopii zapasowych. Teraz nadszedł czas, aby zapełnić katalog danych kopią zapasową, uruchomić MySQL i sprawdzić, czy wszystko działa zgodnie z oczekiwaniami:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Jak widać, wszystko jest w porządku. MySQL uruchomił się poprawnie i byliśmy w stanie uzyskać do niego dostęp (a dane tam są!). Udało nam się przywrócić działanie naszej bazy danych w innej lokalizacji. Całkowity wymagany czas zależy ściśle od rozmiaru danych - musieliśmy pobrać dane z S3, odszyfrować je i rozpakować, a na koniec przygotować kopię zapasową. Mimo to jest to bardzo tania opcja (musisz płacić tylko za dane S3), która zapewnia ciągłość działania w przypadku katastrofy.



