Zgadzam się z Strawberry co do schematu. Możemy omawiać pomysły na lepszą wydajność i to wszystko. Ale oto moje podejście do tego, jak rozwiązać ten problem po kilku rozmowach i zmianach w pytaniu.
Zwróć uwagę na zmiany danych poniżej, aby poradzić sobie z różnymi warunkami brzegowymi, które obejmują książki bez obrazów w tej tabeli i tie-breaki. Znaczenie tie-breaków przy użyciu max(upvotes) . OP kilka razy zmienił pytanie i dodał nową kolumnę w tabeli obrazów.
Zmodyfikowane pytanie stało się zwrotem 1 wiersza make na książkę. Zdrap to, zawsze 1 wiersz na książkę, nawet jeśli nie ma obrazów. Informacja o obrazie do zwrócenia to ta z maksymalną liczbą głosów za.
Tabela książek
create table books
( id int primary key,
name varchar(1000),
releasedate date,
purchasecount int
) ENGINE=InnoDB;
insert into books values(1,"fool","1963-12-18",456);
insert into books values(2,"foo","1933-12-18",11);
insert into books values(3,"fooherty","1943-12-18",77);
insert into books values(4,"eoo","1953-12-18",678);
insert into books values(5,"fooe","1973-12-18",459);
insert into books values(6,"qoo","1983-12-18",500);
Zmiany danych w stosunku do pierwotnego pytania.
Głównie nowe upvotes kolumna.
Poniżej znajduje się dodany wiersz tie-break.
create table images
( bookid int,
poster varchar(150) primary key,
bucketid int,
upvotes int -- a new column introduced by OP
) ENGINE=InnoDB;
insert into images values (1,"xxx",12,27);
insert into images values (5,"pqr",11,0);
insert into images values (5,"swt",11,100);
insert into images values (2,"yyy",77,65);
insert into images values (1,"qwe",111,69);
insert into images values (1,"blah_blah_tie_break",111,69);
insert into images values (3,"qwqqe",14,81);
insert into images values (1,"qqawe",8,45);
insert into images values (2,"z",81,79);
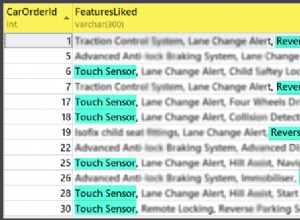
Wizualizacja tabeli pochodnej
Ma to tylko pomóc w wizualizacji wewnętrznego elementu końcowego zapytania. Pokazuje gotcha w sytuacjach tie-breaków, stąd rownum zmienny. Ta zmienna jest resetowana do 1 za każdym razem, gdy bookid zmienia się w przeciwnym razie zwiększa się. Na koniec (nasze ostatnie zapytanie) chcemy tylko rownum=1 wierszy, tak aby na książkę zwracany był maksymalnie 1 wiersz (jeśli istnieje).

Ostateczne zapytanie
select b.id,b.purchasecount,xDerivedImages2.poster,xDerivedImages2.bucketid
from books b
left join
( select i.bookid,i.poster,i.bucketid,i.upvotes,
@rn := if(@lastbookid = i.bookid, @rn + 1, 1) as rownum,
@lastbookid := i.bookid as dummy
from
( select bookid,max(upvotes) as maxup
from images
group by bookid
) xDerivedImages
join images i
on i.bookid=xDerivedImages.bookid and i.upvotes=xDerivedImages.maxup
cross join (select @rn:=0,@lastbookid:=-1) params
order by i.bookid
) xDerivedImages2
on xDerivedImages2.bookid=b.id and xDerivedImages2.rownum=1
order by b.purchasecount desc
limit 10
Wyniki
+----+---------------+---------------------+----------+
| id | purchasecount | poster | bucketid |
+----+---------------+---------------------+----------+
| 4 | 678 | NULL | NULL |
| 6 | 500 | NULL | NULL |
| 5 | 459 | swt | 11 |
| 1 | 456 | blah_blah_tie_break | 111 |
| 3 | 77 | qwqqe | 14 |
| 2 | 11 | z | 81 |
+----+---------------+---------------------+----------+
Znaczenie cross join jest jedynie wprowadzenie i ustawienie wartości początkowych dla 2 zmiennych. To wszystko.
Wynikiem jest dziesięć najlepszych książek w porządku malejącym od purchasecount z informacjami z images jeśli istnieje (w przeciwnym razie NULL ) w przypadku obrazu z największą liczbą głosów. Wybrany obraz przestrzega reguł tie-break, wybierając pierwszy, jak wspomniano powyżej w sekcji Wizualizacja za pomocą rownum .
Ostateczne myśli
Zostawiam OP, aby zaklinował się w odpowiednim where na końcu, ponieważ podane przykładowe dane nie zawierały użytecznej nazwy książki do wyszukania. Ta część jest banalna. Aha, i zrób coś ze schematem dla dużej szerokości twoich kluczy podstawowych. Ale w tej chwili jest to nie na temat.