Konfiguracja replikacji w MySQL jest łatwa, ale zarządzanie nią w środowisku produkcyjnym nigdy nie było łatwym zadaniem. Nawet z nowszym automatycznym pozycjonowaniem GTID, nadal może się nie udać, jeśli nie wiesz, co robisz. Po skonfigurowaniu replikacji różne rzeczy mogą pójść nie tak. Łatwo można popełnić błędy, które mogą mieć katastrofalne zakończenie dla Twoich danych.
W tym poście przedstawimy niektóre z najczęstszych błędów popełnianych podczas replikacji MySQL oraz sposoby ich zapobiegania.
Konfigurowanie replikacji
Podczas konfigurowania replikacji MySQL należy przygotować węzły podrzędne zestawem danych z urządzenia głównego. Dzięki rozwiązaniom takim jak klaster Galera jest to automatycznie obsługiwane za pomocą wybranej przez Ciebie metody. W przypadku replikacji MySQL musisz to zrobić samodzielnie, więc naturalnie korzystasz ze standardowego narzędzia do tworzenia kopii zapasowych.
W przypadku MySQL dostępnych jest wiele różnych narzędzi do tworzenia kopii zapasowych, ale najczęściej używanym jest mysqldump. Mysqldump wyprowadza logiczną kopię zapasową zestawu danych twojego mastera. Oznacza to, że kopia danych nie będzie kopią binarną, ale dużym plikiem zawierającym zapytania służące do odtworzenia zestawu danych. W większości przypadków powinno to zapewnić (prawie) identyczną kopię Twoich danych, ale są przypadki, w których tak się nie stanie – ze względu na to, że zrzut jest oparty na podstawie obiektu. Oznacza to, że nawet zanim zaczniesz replikować dane, Twój zbiór danych nie jest taki sam jak ten na wzorcu.
Istnieje kilka poprawek, które możesz zrobić, aby mysqldump był bardziej niezawodny, na przykład zrzut jako pojedyncza transakcja, a także nie zapomnij uwzględnić procedur i wyzwalaczy:
mysqldump -uuser -ppass --single-transaction --routines --triggers --all-databases > dumpfile.sqlDobrą praktyką jest sprawdzenie, czy twój węzeł podrzędny jest w 100% taki sam, używając pt-table-checksum po skonfigurowaniu replikacji:
pt-table-checksum --replicate=test.checksums --ignore-databases mysql h=localhost,u=user,p=passTo narzędzie obliczy sumę kontrolną dla każdej tabeli w urządzeniu głównym, zreplikuje polecenie do urządzenia podrzędnego, a następnie węzeł podrzędny wykona tę samą operację sumy kontrolnej. Jeśli którakolwiek z tabel nie jest taka sama, powinno to być wyraźnie widoczne w tabeli sum kontrolnych.
Korzystanie z niewłaściwej metody replikacji
Domyślną metodą replikacji MySQL była tak zwana replikacja oparta na instrukcjach. Ta metoda jest dokładnie tym, czym jest:strumieniem replikacji każdej instrukcji uruchamianej na urządzeniu głównym, który będzie odtwarzany w węźle podrzędnym. Ponieważ sam MySQL jest wielowątkowy, ale jego (tradycyjna) replikacja nie jest, kolejność instrukcji w strumieniu replikacji może nie być w 100% taka sama. Również powtórzenie instrukcji może dać różne wyniki, jeśli nie zostanie wykonane dokładnie w tym samym czasie.
Może to skutkować różnymi zestawami danych między urządzeniem nadrzędnym i podrzędnym ze względu na dryf danych. Nie stanowiło to problemu przez wiele lat, ponieważ niewielu uruchamiało MySQL z wieloma jednoczesnymi wątkami, ale przy nowoczesnych architekturach wieloprocesorowych stało się to bardzo prawdopodobne przy normalnym, codziennym obciążeniu.
Odpowiedzią MySQL była tak zwana replikacja oparta na wierszach. Replikacja oparta na wierszach replikuje dane, gdy tylko jest to możliwe, ale w niektórych wyjątkowych przypadkach nadal używa instrukcji. Dobrym przykładem może być zmiana biblioteki DLL w tabeli, gdzie replikacja musiałaby następnie skopiować każdy wiersz w tabeli poprzez replikację. Ponieważ jest to nieefektywne, takie stwierdzenie zostanie powtórzone w tradycyjny sposób. Gdy replikacja oparta na wierszach wykryje dryf danych, zatrzyma wątek podrzędny, aby zapobiec pogorszeniu sytuacji.
Następnie istnieje metoda pomiędzy tymi dwoma:replikacja w trybie mieszanym. Ten typ replikacji zawsze replikuje instrukcje, z wyjątkiem sytuacji, gdy zapytanie zawiera funkcję UUID(), używane są wyzwalacze, procedury składowane, funkcje UDF i kilka innych wyjątków. Tryb mieszany nie rozwiąże problemu dryfu danych i, wraz z replikacją opartą na instrukcjach, należy go unikać.
Replikacja cykliczna
Uruchamianie replikacji MySQL z wieloma wzorcami jest często konieczne w przypadku środowiska z wieloma centrami danych. Ponieważ aplikacja nie może czekać, aż master w innym centrum danych potwierdzi zapis, preferowany jest lokalny master. Normalnie automatyczne przesunięcie przyrostu jest używane do zapobiegania kolizjom danych między urządzeniami nadrzędnymi. Szeroko akceptowanym rozwiązaniem jest umożliwienie dwóm mistrzom pisania do siebie nawzajem w ten sposób.
 Replikacja MySQL Master-Master
Replikacja MySQL Master-Master Jeśli jednak musisz zapisywać dane w wielu centrach danych w tej samej bazie danych, otrzymujesz wiele masterów, które muszą zapisywać swoje dane między sobą. Przed MySQL 5.7.6 nie było metody wykonywania replikacji typu mesh, więc alternatywą byłoby użycie zamiast tego replikacji pierścieniowej.
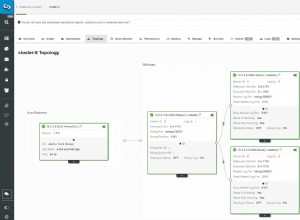
 Topologia replikacji pierścieniowej MySQL
Topologia replikacji pierścieniowej MySQL Replikacja pierścieniowa w MySQL jest problematyczna z następujących powodów:opóźnienia, wysoka dostępność i dryf danych. Zapisanie niektórych danych na serwerze A zajęłoby trzy przeskoki, aby wylądować na serwerze D (przez serwer B i C). Ponieważ (tradycyjna) replikacja MySQL jest jednowątkowa, każde długotrwałe zapytanie w replikacji może zatrzymać cały pierścień. Również jeśli któryś z serwerów ulegnie awarii, pierścień zostanie przerwany i obecnie nie ma oprogramowania do przełączania awaryjnego, które mogłoby naprawić struktury pierścienia. Wtedy może wystąpić dryf danych, gdy dane są zapisywane na serwerze A i jednocześnie zmieniane na serwerze C lub D.
 Uszkodzona replikacja pierścienia
Uszkodzona replikacja pierścienia Ogólnie rzecz biorąc, replikacja cykliczna nie pasuje do MySQL i należy jej unikać za wszelką cenę. Galera byłaby dobrą alternatywą dla zapisów w wielu centrach danych, ponieważ została zaprojektowana z myślą o tym.
Zatrzymywanie replikacji z dużymi aktualizacjami
Często różne zadania wsadowe sprzątania wykonują różne zadania, od czyszczenia starych danych po obliczanie średnich „polubień” pobranych z innego źródła. Oznacza to, że w określonych odstępach czasu zadanie spowoduje dużą aktywność bazy danych i najprawdopodobniej zapisze wiele danych z powrotem do bazy danych. Oczywiście oznacza to, że aktywność w strumieniu replikacji wzrośnie równomiernie.
Replikacja oparta na instrukcjach będzie replikować dokładnie zapytania używane w zadaniach wsadowych, więc jeśli przetwarzanie zapytania na urządzeniu głównym zajmie pół godziny, wątek podrzędny zostanie zatrzymany na co najmniej taki sam czas. Oznacza to, że żadne inne dane nie mogą się replikować, a węzły podrzędne zaczną pozostawać w tyle za urządzeniem nadrzędnym. Jeśli przekroczy to próg narzędzia do przełączania awaryjnego lub serwera proxy, może usunąć te węzły podrzędne z dostępnych węzłów w klastrze. Jeśli używasz replikacji opartej na instrukcjach, możesz temu zapobiec, dzieląc dane zadania na mniejsze partie.
Teraz możesz pomyśleć, że nie ma to wpływu na replikację opartą na wierszach, ponieważ będzie ona replikować informacje o wierszu zamiast zapytania. Jest to częściowo prawda, ponieważ w przypadku zmian DDL replikacja powraca do formatu opartego na instrukcjach. Również duża liczba operacji CRUD wpłynie na strumień replikacji:w większości przypadków jest to nadal operacja jednowątkowa, a zatem każda transakcja będzie czekać na odtworzenie poprzedniej za pośrednictwem replikacji. Oznacza to, że jeśli masz wysoką współbieżność na urządzeniu głównym, urządzenie podrzędne może zatrzymać się z powodu przeciążenia transakcji podczas replikacji.
Aby obejść ten problem, zarówno MariaDB, jak i MySQL oferują replikację równoległą. Implementacja może się różnić w zależności od dostawcy i wersji. MySQL 5.6 oferuje replikację równoległą, o ile zapytania są oddzielone schematem. MariaDB 10.0 i MySQL 5.7 mogą obsługiwać replikację równoległą w różnych schematach, ale mają inne granice. Wykonywanie zapytań za pośrednictwem równoległych wątków podrzędnych może przyspieszyć strumień replikacji, jeśli intensywnie piszesz. Jeśli jednak nie, najlepiej będzie trzymać się tradycyjnej replikacji jednowątkowej.
Zmiany schematu
Wykonywanie zmian schematu w działającej konfiguracji produkcyjnej jest zawsze kłopotliwe. Ma to związek z faktem, że zmiana DDL w większości przypadków blokuje tabelę i zwalnia ją dopiero po zastosowaniu zmiany DDL. Sytuacja staje się jeszcze gorsza, gdy zaczniesz replikować te zmiany DDL za pośrednictwem replikacji MySQL, gdzie dodatkowo zatrzyma to strumień replikacji.
Często stosowanym obejściem jest zastosowanie zmiany schematu najpierw do węzłów podrzędnych. W przypadku replikacji opartej na instrukcjach działa to dobrze, ale w przypadku replikacji opartej na wierszach może to działać do pewnego stopnia. Replikacja oparta na wierszach umożliwia istnienie dodatkowych kolumn na końcu tabeli, więc dopóki jest w stanie zapisać pierwsze kolumny, wszystko będzie w porządku. Najpierw zastosuj zmianę do wszystkich urządzeń podrzędnych, następnie przełącz awaryjnie do jednego z podrzędnych, a następnie zastosuj zmianę do urządzenia nadrzędnego i dołącz go jako podrzędny. Jeśli zmiana obejmuje wstawienie kolumny w środku lub usunięcie kolumny, zadziała to z replikacją opartą na wierszach.
Istnieją narzędzia, które mogą bardziej niezawodnie przeprowadzać zmiany schematu online. Zmiana schematu online Percona (znana jako pt-osc) utworzy tabelę cienia z nową strukturą tabeli, wstawi nowe dane za pomocą wyzwalaczy i wypełni dane w tle. Po zakończeniu tworzenia nowej tabeli po prostu zamieni starą tabelę na nową w ramach transakcji. To nie działa we wszystkich przypadkach, zwłaszcza jeśli istniejąca tabela ma już wyzwalacze.

Alternatywą jest nowe narzędzie Gh-ost autorstwa Github. To narzędzie online do zmiany schematu najpierw utworzy kopię istniejącego układu tabeli, zmieni układ tabeli na nowy, a następnie połączy proces jako replikę MySQL. Wykorzysta strumień replikacji do znalezienia nowych wierszy, które zostały wstawione do oryginalnej tabeli i jednocześnie wypełni tabelę. Gdy zakończy się wypełnianie, oryginalna i nowa tabela zostaną zamienione. Oczywiście wszystkie operacje na nowej tabeli również trafią do strumienia replikacji, dlatego w każdej replice migracja odbywa się w tym samym czasie.
Tabele pamięci i replikacja
Chociaż jesteśmy przy temacie DDL, częstym problemem jest tworzenie tabel pamięci. Tabele pamięci są tabelami nietrwałymi, ich struktura tabel pozostaje, ale tracą dane po ponownym uruchomieniu MySQL. Podczas tworzenia nowej tablicy pamięci zarówno na urządzeniu nadrzędnym, jak i podrzędnym, obaj będą mieli pustą tabelę i będzie to działać idealnie. Gdy któryś z nich zostanie ponownie uruchomiony, tabela zostanie opróżniona i wystąpią błędy replikacji.
Replikacja oparta na wierszach zostanie przerwana, gdy dane w węźle podrzędnym zwrócą różne wyniki, a replikacja oparta na instrukcjach zostanie przerwana, gdy spróbuje wstawić dane, które już istnieją. W przypadku tabel pamięci jest to częsty przerywacz replikacji. Naprawa jest łatwa:po prostu utwórz nową kopię danych, zmień silnik na InnoDB i teraz powinien być bezpieczny dla replikacji.
Ustawianie zmiennej tylko do odczytu na wartość Prawda
Jak opisaliśmy wcześniej, brak tych samych danych w węzłach podrzędnych może przerwać replikację. Często jest to spowodowane przez coś (lub kogoś) zmieniającego dane w węźle podrzędnym, ale nie w węźle głównym. Gdy dane węzła głównego zostaną zmienione, zostaną one zreplikowane do urządzenia podrzędnego, gdzie nie może zastosować zmiany, co spowoduje przerwanie replikacji.
Można temu zapobiec:ustawiając zmienną read_only na true. Uniemożliwi to każdemu dokonywanie zmian w danych, z wyjątkiem użytkowników replikacji i rootów. Większość menedżerów przełączania awaryjnego ustawia tę flagę automatycznie, aby uniemożliwić użytkownikom zapis do używanego systemu głównego podczas przełączania awaryjnego. Niektóre z nich zachowują to nawet po przełączeniu awaryjnym.
To nadal pozostawia użytkownikowi root wykonanie błędnego zapytania CRUD na węźle podrzędnym. Aby temu zapobiec, istnieje zmienna super_read_only od wersji MySQL 5.7.8, która nawet blokuje użytkownikowi root przed aktualizacją danych.
Włączanie identyfikatora GTID
W replikacji MySQL konieczne jest uruchomienie slave'a z właściwej pozycji w logach binarnych. Uzyskanie tej pozycji może być wykonane podczas tworzenia kopii zapasowej (obsługują to xtrabackup i mysqldump) lub gdy przestałeś korzystać z węzła, którego kopiujesz. Rozpoczęcie replikacji poleceniem ZMIEŃ MASTER NA wyglądałoby tak:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',MASTER_USER='replication_user', MASTER_PASSWORD='password', MASTER_LOG_FILE='master-bin.0001', MASTER_LOG_POS= 04;Rozpoczęcie replikacji w niewłaściwym miejscu może mieć katastrofalne skutki:dane mogą być zapisywane dwukrotnie lub nie być aktualizowane. Powoduje to dryf danych między węzłem głównym a węzłem podrzędnym.
Również wtedy, gdy przełączenie urządzenia głównego na urządzenie podrzędne wiąże się ze znalezieniem prawidłowej pozycji i zmianą urządzenia głównego na odpowiedniego hosta. MySQL nie zachowuje logów binarnych i pozycji ze swojego mastera, ale raczej tworzy własne logi binarne i pozycje. W przypadku ponownego wyrównania węzła podrzędnego do nowego urządzenia nadrzędnego może to stać się poważnym problemem:dokładna pozycja węzła nadrzędnego w trybie przełączania awaryjnego musi zostać znaleziona na nowym urządzeniu nadrzędnym, a następnie wszystkie urządzenia podrzędne mogą zostać ponownie wyrównane.

Aby rozwiązać ten problem, zarówno Oracle, jak i MariaDB wdrożyły globalny identyfikator transakcji (GTID). Identyfikatory GTID umożliwiają automatyczne wyrównywanie niewolników, a zarówno w MySQL, jak i MariaDB serwer sam ustala, jaka jest prawidłowa pozycja. Jednak oba zaimplementowały identyfikator GTID w inny sposób i dlatego są niekompatybilne. Jeśli musisz skonfigurować replikację między sobą, replikacja powinna być skonfigurowana z tradycyjnym pozycjonowaniem dziennika binarnego. Również oprogramowanie do przełączania awaryjnego powinno być świadome, aby nie używać identyfikatorów GTID.
Wniosek
Mamy nadzieję, że udzieliliśmy Ci wystarczająco dużo wskazówek, aby uniknąć kłopotów. To wszystko są powszechne praktyki ekspertów MySQL. Musieli się tego nauczyć na własnej skórze, a dzięki tym wskazówkom zapewniamy, że nie musisz.
Mamy dodatkowe oficjalne dokumenty, które mogą być przydatne, jeśli chcesz dowiedzieć się więcej o replikacji MySQL.
Powiązane artykuły Dokumentacja MySQL Replication Blueprint Dokumentacja MySQL Replication Blueprint obejmuje wszystkie aspekty topologii replikacji wraz z tajnikami wdrażania, konfiguracją replikacji, monitorowaniem, uaktualnieniami, wykonywaniem kopii zapasowych i zarządzaniem wysoką dostępnością za pomocą serwerów proxy.Pobierz usługę MySQL Replication for High AvailabilityTen samouczek zawiera informacje o MySQL Replication, z informacjami o najnowszych funkcjach wprowadzonych w wersjach 5.6 i 5.7. Istnieje również bardziej praktyczna, praktyczna sekcja dotycząca szybkiego wdrażania i zarządzania konfiguracją replikacji za pomocą ClusterControl.Pobierz