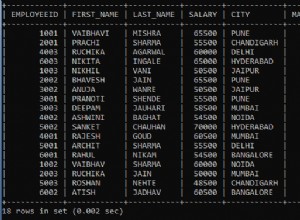
Nie wierzę, że GROUP BY da ci pożądany rezultat. I niestety MySQL nie obsługuje funkcji analitycznych (w ten sposób rozwiązalibyśmy ten problem w Oracle lub SQL Server).
Możliwe jest emulowanie pewnych podstawowych funkcji analitycznych, korzystając ze zmiennych zdefiniowanych przez użytkownika.
W tym przypadku chcemy emulować:
ROW_NUMBER() OVER(PARTITION BY doctor_id ORDER BY distance ASC) AS seq
Tak więc, zaczynając od oryginalnego zapytania, zmieniłem ORDER BY, aby sortował według doctor_id najpierw, a potem na obliczonej distance . (Dopóki nie znamy tych odległości, nie wiemy, która z nich jest „najbliższa”).
Z tym posortowanym wynikiem zasadniczo "numerujemy" wiersze dla każdego identyfikatora doctor_id, najbliższy jako 1, drugi najbliżej 2 i tak dalej. Kiedy otrzymamy nowy identyfikator doctor_id, zaczynamy ponownie od najbliższego jako 1.
Aby to osiągnąć, korzystamy ze zmiennych zdefiniowanych przez użytkownika. Używamy jednego do przypisania numeru wiersza (nazwa zmiennej to @i, a zwrócona kolumna ma alias seq). Druga zmienna, której używamy do „zapamiętania” identyfikatora doctor_id z poprzedniego wiersza, dzięki czemu możemy wykryć „przerwę” w identyfikatorze doctor_id, abyśmy mogli wiedzieć, kiedy ponownie rozpocząć numerowanie wierszy od 1.
Oto zapytanie:
SELECT z.*
, @i := CASE WHEN z.doctor_id = @prev_doctor_id THEN @i + 1 ELSE 1 END AS seq
, @prev_doctor_id := z.doctor_id AS prev_doctor_id
FROM
(
/* original query, ordered by doctor_id and then by distance */
SELECT zip,
( 3959 * acos( cos( radians(34.12520) ) * cos( radians( zip_info.latitude ) ) * cos(radians( zip_info.longitude ) - radians(-118.29200) ) + sin( radians(34.12520) ) * sin( radians( zip_info.latitude ) ) ) ) AS distance,
user_info.*, office_locations.*
FROM zip_info
RIGHT JOIN office_locations ON office_locations.zipcode = zip_info.zip
RIGHT JOIN user_info ON office_locations.doctor_id = user_info.id
WHERE user_info.status='yes'
ORDER BY user_info.doctor_id ASC, distance ASC
) z JOIN (SELECT @i := 0, @prev_doctor_id := NULL) i
HAVING seq = 1 ORDER BY z.distance
Zakładam, że oryginalne zapytanie zwraca wymagany zestaw wyników, po prostu ma za dużo wierszy i chcesz wyeliminować wszystkie oprócz „najbliższego” (wiersz z minimalną wartością odległości) dla każdego doctor_id.
Twoje pierwotne zapytanie zostało umieszczone w innym zapytaniu; jedyne zmiany, jakie wprowadziłem do pierwotnego zapytania, to uporządkowanie wyników według doctor_id, a następnie według odległości oraz usunięcie HAVING distance < 50 klauzula. (Jeśli chcesz zwrócić tylko odległości mniejsze niż 50, zostaw tę klauzulę w tym miejscu. Nie było jasne, czy to był twój zamiar, czy też zostało to określone w próbie ograniczenia wierszy do jednego na doctor_id.)
Kilka kwestii, na które należy zwrócić uwagę:
Zapytanie zastępujące zwraca dwie dodatkowe kolumny; nie są one tak naprawdę potrzebne w zestawie wyników, z wyjątkiem sposobów generowania zestawu wyników. (Możliwe jest ponowne zawinięcie całego SELECT w inny SELECT, aby pominąć te kolumny, ale jest to naprawdę bardziej bałaganiarskie, niż jest to warte. Po prostu odzyskałbym kolumny i wiedziałbym, że mogę je zignorować.)
Innym problemem jest to, że użycie .* w zapytaniu wewnętrznym jest nieco niebezpieczne, ponieważ naprawdę musimy zagwarantować, że nazwy kolumn zwrócone przez to zapytanie są unikalne. (Nawet jeśli nazwy kolumn są teraz różne, dodanie kolumny do jednej z tych tabel może wprowadzić „niejednoznaczny” wyjątek kolumny w zapytaniu. Najlepiej tego uniknąć, a to można łatwo rozwiązać, zastępując .* z listą kolumn do zwrócenia i określeniem aliasu dla dowolnej „duplikowanej” nazwy kolumny. (Użycie z.* w zewnętrznym zapytaniu nie jest problemem, o ile mamy kontrolę nad kolumnami zwracanymi przez z .)
Uzupełnienie:
Zauważyłem, że GROUP BY nie da ci zestawu wyników, którego potrzebujesz. Chociaż byłoby możliwe uzyskanie zestawu wyników za pomocą zapytania przy użyciu funkcji GROUP BY, instrukcja zwracająca poprawny zestaw wyników byłaby żmudna. Możesz określić MIN(distance) ... GROUP BY doctor_id , a to dałoby najmniejszą odległość, ALE nie ma gwarancji, że inne wyrażenia niezwiązane z agregacją na liście SELECT będą pochodzić z wiersza o minimalnej odległości, a nie z jakiegoś innego wiersza. (MySQL jest niebezpiecznie liberalny w odniesieniu do GROUP BY i agregacji. Aby silnik MySQL był bardziej ostrożny (i zgodny z innymi silnikami relacyjnych baz danych), SET sql_mode = ONLY_FULL_GROUP_BY
Dodatek 2:
Problemy z wydajnością zgłaszane przez Dariousa „niektóre zapytania zajmują 7 sekund”.
Aby przyspieszyć działanie, prawdopodobnie chcesz buforować wyniki funkcji. Zasadniczo zbuduj tabelę przeglądową. np.
CREATE TABLE office_location_distance
( office_location_id INT UNSIGNED NOT NULL COMMENT 'PK, FK to office_location.id'
, zipcode_id INT UNSIGNED NOT NULL COMMENT 'PK, FK to zipcode.id'
, gc_distance DECIMAL(18,2) COMMENT 'calculated gc distance, in miles'
, PRIMARY KEY (office_location_id, zipcode_id)
, KEY (zipcode_id, gc_distance, office_location_id)
, CONSTRAINT distance_lookup_office_FK
FOREIGN KEY (office_location_id) REFERENCES office_location(id)
ON UPDATE CASCADE ON DELETE CASCADE
, CONSTRAINT distance_lookup_zipcode_FK
FOREIGN KEY (zipcode_id) REFERENCES zipcode(id)
ON UPDATE CASCADE ON DELETE CASCADE
) ENGINE=InnoDB
To tylko pomysł. (Spodziewam się, że szukasz odległości office_location od konkretnego kodu pocztowego, więc indeks na (zipcode, gc_distance, office_location_id) jest indeksem pokrycia, którego potrzebuje twoje zapytanie.(Unikałbym przechowywania obliczonej odległości jako FLOAT, z powodu złej wydajność zapytań z typem danych FLOAT)
INSERT INTO office_location_distance (office_location_id, zipcode_id, gc_distance)
SELECT d.office_location_id
, d.zipcode_id
, d.gc_distance
FROM (
SELECT l.id AS office_location_id
, z.id AS zipcode_id
, ROUND( <glorious_great_circle_calculation> ,2) AS gc_distance
FROM office_location l
CROSS
JOIN zipcode z
ORDER BY 1,3
) d
ON DUPLICATE KEY UPDATE gc_distance = VALUES(gc_distance)
Dzięki buforowaniu i indeksowaniu wyników funkcji Twoje zapytania powinny być znacznie szybsze.
SELECT d.gc_distance, o.*
FROM office_location o
JOIN office_location_distance d ON d.office_location_id = o.id
WHERE d.zipcode_id = 63101
AND d.gc_distance <= 100.00
ORDER BY d.zipcode_id, d.gc_distance
Waham się przed dodaniem predykatu HAVING na INSERT/UPDATE do tabeli pamięci podręcznej; (jeśli masz niewłaściwą szerokość/długość geograficzną i obliczyłeś błędną odległość poniżej 100 mil; kolejny bieg po ustaleniu szerokości/długości i odległość wynosi 1000 mil... jeśli wiersz jest wykluczony z zapytania, wtedy istniejący wiersz w tabeli pamięci podręcznej nie zostanie zaktualizowany. (Możesz wyczyścić tabelę pamięci podręcznej, ale nie jest to naprawdę konieczne, to tylko dużo dodatkowej pracy dla bazy danych i dzienników. Jeśli zestaw wyników zapytania konserwacyjnego jest zbyt duży, można go podzielić, aby działał iteracyjnie dla każdego kodu pocztowego lub każdej lokalizacji_biura).
Z drugiej strony, jeśli nie interesują Cię żadne odległości powyżej określonej wartości, możesz dodać HAVING gc_distance < predykatu i znacznie zmniejszy rozmiar tabeli pamięci podręcznej.