To też nie jest dobra fragmentacja
W zeszłym miesiącu pisałem o nieoczekiwanej fragmentacji indeksu klastrowego, więc tym razem chciałbym omówić kilka rzeczy, które można zrobić, aby uniknąć fragmentacji indeksu. Zakładam, że przeczytałeś poprzedni post i znasz terminy, które tam zdefiniowałem, aw dalszej części tego artykułu, kiedy mówię „fragmentacja”, mam na myśli zarówno logiczną fragmentację, jak i problemy z niską gęstością strony.
Wybierz dobry klucz klastra
Najdroższą strukturą danych do usunięcia fragmentacji jest indeks klastrowy tabeli, ponieważ jest to największa struktura, ponieważ zawiera wszystkie dane tabeli. Z perspektywy fragmentacji sensowne jest wybranie klucza klastra, który pasuje do wzorca wstawiania tabeli, więc nie ma możliwości wstawienia na stronie, na której nie ma miejsca, a tym samym spowodowania podziału strony i wprowadzenia fragmentacji.
To, co stanowi najlepszy klucz klastra dla dowolnej tabeli, jest przedmiotem wielu dyskusji, ale ogólnie rzecz biorąc, nie pomylisz się, jeśli klucz klastra ma następujące proste właściwości:
- Wąskie (tzn. jak najmniej kolumn)
- Statyczny (tzn. nigdy go nie aktualizujesz)
- Unikalny
- Ciągle rosnący
Jest to stale rosnąca właściwość, która jest najważniejsza dla zapobiegania fragmentacji, ponieważ pozwala uniknąć losowych wstawek, które mogą powodować podziały stron na już pełnych stronach. Przykładami takiego wyboru klucza są kolumny tożsamości int i bigint, a nawet sekwencyjny identyfikator GUID z funkcji NEWSEQUENTIALID().
W przypadku tego typu kluczy nowe wiersze będą miały wartość klucza wyższą niż wszystkie inne w tabeli, dlatego punkt wstawiania nowego wiersza będzie znajdować się na końcu prawej strony w strukturze indeksu klastrowego. W końcu nowe wiersze wypełnią tę stronę, a kolejna strona zostanie dodana po prawej stronie indeksu, ale bez szkodliwego podziału strony.
Teraz, jeśli masz klastrowany klucz indeksu, który nigdy się nie zwiększa, może to być bardzo złożona i nieprzyjemna procedura, aby zmienić go na stale rosnący, więc nie martw się – zamiast tego możesz użyć współczynnika wypełnienia, jak omówiłem poniżej.
Nawiasem mówiąc, aby uzyskać znacznie głębszy wgląd w wybór klucza klastra i wszystkie jego konsekwencje, sprawdź kategorię bloga Kimberly's Clustering Key (czytaj od dołu do góry).
Nie aktualizuj kolumn klucza indeksu
Za każdym razem, gdy kluczowa kolumna jest aktualizowana, nie jest to zwykła aktualizacja w miejscu, chociaż wiele miejsc w Internecie i książkach mówi, że jest (są błędne). Nie można zaktualizować kolumny klucza, ponieważ nowa wartość klucza oznaczałaby wtedy, że wiersz ma niewłaściwą kolejność klucza dla indeksu. Zamiast tego aktualizacja kolumny klucza jest tłumaczona na usunięcie całego wiersza plus wstawienie całego wiersza z nową wartością klucza. Jeśli strona, na której zostanie wstawiony nowy wiersz, nie ma wystarczającej ilości miejsca, nastąpi podział strony, powodując fragmentację.
Unikanie aktualizacji kolumn kluczy powinno być łatwe w przypadku indeksu klastrowego, ponieważ jest to kiepski projekt, który wymaga zaktualizowania klucza klastra wiersza tabeli. Jednak w przypadku indeksów nieklastrowanych jest to nieuniknione, jeśli aktualizacje tabeli dotyczą kolumn, w których znajduje się indeks nieklastrowany. W takich przypadkach musisz użyć współczynnika wypełnienia.
Nie aktualizuj kolumn o zmiennej długości
Łatwiej powiedzieć niż zrobić. Jeśli musisz użyć kolumn o zmiennej długości i możliwe jest, że zostaną zaktualizowane, możliwe jest, że mogą się one rozrosnąć i wymagać więcej miejsca na zaktualizowany wiersz, co prowadzi do podziału strony, jeśli strona jest już pełna.
Jest kilka rzeczy, które możesz zrobić, aby uniknąć fragmentacji w takim przypadku:
- Użyj współczynnika wypełnienia
- Zamiast tego użyj kolumny o stałej długości, jeśli narzut wszystkich dodatkowych bajtów wypełniających jest mniejszym problemem niż fragmentacja lub użycie współczynnika wypełnienia
- Użyj wartości zastępczej, aby „zarezerwować” miejsce na kolumnę – jest to sztuczka, której możesz użyć, jeśli aplikacja wprowadzi nowy wiersz, a następnie wróci, aby wypełnić niektóre szczegóły, powodując rozszerzanie kolumn o zmiennej długości
- Wykonaj usuwanie i wstawianie zamiast aktualizacji
Użyj współczynnika wypełnienia
Jak widać, wiele sposobów na uniknięcie fragmentacji jest nie do zaakceptowania, ponieważ wiążą się ze zmianami aplikacji lub schematu, więc użycie współczynnika wypełnienia jest łatwym sposobem na złagodzenie fragmentacji.
Współczynnik wypełnienia indeksu to ustawienie indeksu, które określa, ile pustego miejsca należy pozostawić na każdej stronie na poziomie liścia podczas tworzenia, przebudowywania lub reorganizacji indeksu. Pomysł polega na tym, że na stronie jest wystarczająco dużo wolnego miejsca, aby umożliwić losowe wstawianie lub powiększanie wierszy (z dodawanego tagu wersjonowania lub aktualizowanych kolumn o zmiennej długości) bez wypełniania strony i konieczności jej podziału. Jednak w końcu strona się zapełni, więc okresowo wolne miejsce musi być odświeżone przez przebudowanie lub reorganizację indeksu (ogólnie nazywane wykonywaniem konserwacji indeksu). Sztuczka polega na znalezieniu właściwego współczynnika wypełnienia do użycia, wraz z odpowiednią częstotliwością konserwacji indeksu.
Możesz przeczytać więcej o ustawianiu współczynnika wypełnienia w MSDN tutaj. Nie wpadaj w pułapkę ustawiania współczynnika wypełnienia dla całego wystąpienia (przy użyciu sp_configure), ponieważ oznacza to, że wszystkie indeksy zostaną odbudowane lub zreorganizowane przy użyciu tej wartości współczynnika wypełnienia, nawet te indeksy, które nie mają żadnych problemów z fragmentacją. Nie chcesz, aby twoje duże indeksy klastrowe, z ładnymi, stale rosnącymi kluczami, marnowały 30% miejsca na poziomie liścia, przygotowując się do losowych wstawek, które nigdy się nie zdarzą. O wiele lepiej jest dowiedzieć się, które indeksy są faktycznie dotknięte fragmentacją i ustawić tylko dla nich współczynnik wypełnienia.
Nie ma właściwej odpowiedzi ani magicznej formuły, którą mogę ci na to dać. Powszechnie przyjętą praktyką jest umieszczenie współczynnika wypełnienia 70 (co oznacza pozostawienie 30% wolnego miejsca) dla tych indeksów, w których fragmentacja jest problemem, monitorowanie szybkości fragmentacji, a następnie modyfikowanie współczynnika wypełnienia lub częstotliwości konserwacji indeksu (lub oba).
Tak, oznacza to, że celowo marnujesz miejsce w indeksach, aby uniknąć fragmentacji, ale jest to dobry kompromis, biorąc pod uwagę, jak drogie są podziały stron i jak szkodliwa może być fragmentacja dla wydajności. I tak, wbrew temu, co niektórzy mogą powiedzieć, jest to nadal ważne, nawet jeśli używasz dysków SSD.
Podsumowanie
Jest kilka prostych rzeczy, które możesz zrobić, aby uniknąć fragmentacji, ale gdy tylko przejdziesz do indeksów nieklastrowanych lub użyjesz izolacji migawki lub czytelnych części pomocniczych, fragmentacja odradza się i musisz spróbować temu zapobiec.
Teraz nie szarpnij się i nie myśl, że powinieneś ustawić współczynnik wypełnienia na 70 we wszystkich swoich instancjach – musisz wybrać i ustawić je ostrożnie, jak opisałem powyżej.
I nie zapomnij o menedżerze fragmentacji SQL Sentry, którego możesz użyć (jako dodatku do Performance Advisor), aby dowiedzieć się, gdzie występują problemy z fragmentacją, a następnie je rozwiązać. Na przykład na karcie Indeksy możesz łatwo posortować swoje indeksy najpierw według największej fragmentacji (i, jeśli chcesz, zastosuj filtr do kolumny z liczbą wierszy, aby zignorować mniejsze tabele):
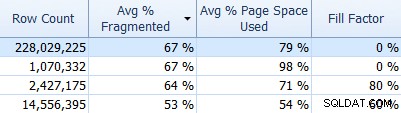
A następnie sprawdź, czy te indeksy używają domyślnego współczynnika wypełnienia (0%), czy może niedomyślnego współczynnika wypełnienia, który może nie być dobrym dopasowaniem do Twoich danych i wzorców DML. Pozwolę wam zgadnąć, które z powyższych zrzutów ekranu najbardziej by mnie zainteresowały zbadaniem. Wdrożenie bardziej odpowiednich współczynników wypełnienia indeksu to najprostszy sposób rozwiązania wszelkich zauważonych problemów.