Dwa pytania - czy opisy są standardowe (opisy nie ulegają zmianie) czy są one wprowadzane przez użytkownika? Jeśli są standardowe, dodaj kolumnę, która jest liczbą całkowitą i dokonaj porównania w tej kolumnie.
Jeśli wprowadzi go użytkownik, Twoja praca jest bardziej skomplikowana, ponieważ szukasz czegoś, co jest bardziej rozmyte. Użyłem algorytmu wyszukiwania bigramowego do oceny podobieństwa między dwoma ciągami, ale nie można tego zrobić bezpośrednio w mySQL.
Zamiast wyszukiwania rozmytego możesz użyć LIKE, ale jego skuteczność ogranicza się do skanowania tabeli, jeśli w końcu umieścisz „%” na początku wyszukiwanego terminu. Oznacza to również, że możesz uzyskać dopasowanie do wybranej części podciągu, co oznacza, że musisz znać podciąg z wyprzedzeniem.
Chętnie omówię więcej, gdy dowiem się, co próbujesz zrobić.
EDIT1:Ok, biorąc pod uwagę twoje opracowanie, będziesz musiał przeprowadzić wyszukiwanie w stylu rozmytym, jak wspomniałem. Używam metody bigramowej, która polega na braniu każdego wpisu dokonanego przez użytkownika i dzieleniu go na 2 lub 3 znaki. Następnie przechowuję każdy z tych fragmentów w innej tabeli, a każdy wpis jest przypisany do rzeczywistego opisu.
Przykład:
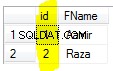
Description1:„Szybki bieg do przodu” Opis2:„Krótki bieg do przodu”
Jeśli podzielisz każdy na 2 znaki - 'A', 'f', 'fa', 'as','st'.....
Następnie możesz porównać liczbę fragmentów 2 znaków, które pasują do obu ciągów i uzyskać „wynik”, który będzie kojarzył się z dokładnością lub podobieństwem między nimi.
Biorąc pod uwagę, że nie wiem, jakiego języka programowania używasz, pominę implementację, ale jest to coś, co będzie musiało być zrobione nie wprost w mySQL.
Lub leniwą alternatywą byłoby skorzystanie z usługi wyszukiwania w chmurze, takiej jak Amazon, która zapewni wyszukiwanie na podstawie podanych przez Ciebie terminów ... nie jestem pewien, czy pozwalają one na ciągłe dodawanie nowych opisów do rozważenia, a w zależności od aplikacji, to może być trochę kosztowna (IMHO).
R
Kolejny post SO dotyczący implementacji bigram - zobacz ten SO bigram / wyszukiwanie rozmyte
--- Aktualizacja według opracowania osoby pytającej---
Po pierwsze, zakładam, że przeczytałeś teorię na dostarczonych przeze mnie linkach.. po drugie, postaram się zachować jak najbardziej agnostyczną bazę danych, ponieważ nie potrzebuje mySQL (chociaż go używam i działa bardziej niż dobrze)
Ok, więc metoda bigram działa dobrze przy tworzeniu/porównywaniu tablic w pamięci tylko wtedy, gdy możliwe dopasowania są stosunkowo małe, w przeciwnym razie dość szybko cierpi z powodu wydajności skanowania tabeli, takiej jak tabela mysql bez indeksów. Tak więc wykorzystasz mocne strony bazy danych, aby pomóc w indeksowaniu za Ciebie.
Potrzebujesz jednej tabeli do przechowywania wprowadzonych przez użytkownika „terminów” lub tekstu, który chcesz porównać. Najprostszą formą jest tabela z dwiema kolumnami, jedna to unikalna liczba całkowita autoinkrementacji, która zostanie zindeksowana, poniżej nazwiemy hd_id, druga to varchar(255), jeśli ciągi są dość krótkie, lub TEKST, jeśli mogą długo - możesz to nazwać, jak chcesz.
Następnie musisz utworzyć inną tabelę, która ma co najmniej TRZY kolumny - jedną dla kolumny referencyjnej z powrotem do kolumny z automatyczną inkrementacją drugiej tabeli (poniżej nazwiemy to hd_id), druga będzie varchar() powiedzmy co najwyżej 5 znaków (to pomieści twoje duże porcje), które poniżej nazwiemy "bigram", a trzecią kolumnę z automatycznym przyrostem o nazwie b_id poniżej. Ta tabela będzie zawierała wszystkie bigramy dla wpisu każdego użytkownika i będzie powiązana z wpisem ogólnym. Będziesz chciał zaindeksować kolumnę varchar samodzielnie (lub najpierw w kolejności w indeksie złożonym).
Teraz za każdym razem, gdy użytkownik wprowadzi termin, który chcesz przeszukać, musisz wprowadzić termin w pierwszej tabeli, a następnie podzielić go na bigramy i wprowadzić każdą porcję do drugiej tabeli, korzystając z odniesienia do ogólnego terminu w pierwszy stół do uzupełnienia relacji. W ten sposób dokonujesz sekcji w PHP, ale pozwalasz mySQL lub innej bazie danych na optymalizację indeksu za Ciebie. W fazie bigram może pomóc przechowywanie liczby bigram wykonanych w tabeli 1 dla fazy obliczeń. Poniżej znajduje się trochę kodu w PHP, który da Ci pomysł na tworzenie bigramów:
// split the string into len-character segments and store seperately in array slots
function get_bigrams($theString,$len)
{
$s=strtolower($theString);
$v=array();
$slength=strlen($s)-($len-1); // we stop short of $len-1 so we don't make short chunks as we run out of characters
for($m=0;$m<$slength;$m++)
{
$v[]=substr($s,$m,$len);
}
return $v;
}
Nie martw się o spacje w ciągach — są one naprawdę pomocne, jeśli myślisz o wyszukiwaniu rozmytym.
Więc dostajesz bigramy, wpisujesz je do tabeli, połączone z ogólnym tekstem w tabeli 1 poprzez indeksowaną kolumnę... co teraz?
Teraz za każdym razem, gdy szukasz terminu, takiego jak „Mój ulubiony termin do wyszukania”, możesz użyć funkcji php, aby przekształcić go w tablicę bigramów. Następnie użyjesz tego do utworzenia części IN (..) instrukcji SQL w twojej tabeli bigram(2). Poniżej znajduje się przykład:
select count(b_id) as matches,a.hd_id,description, from table2 a
inner join table1 b on (a.hd_id=b.hd_id)
where bigram in (" . $sqlstr . ")
group by hd_id order by matches desc limit X
Zostawiłem $sqlstr jako odniesienie do ciągu PHP - możesz to skonstruować samodzielnie jako listę oddzieloną przecinkami od funkcji bigram, używając implode lub czegokolwiek w tablicy zwróconej z get_bigrams lub sparametryzować, jeśli chcesz.
Jeśli zostanie wykonane poprawnie, powyższe zapytanie zwróci najbardziej dopasowane terminy wyszukiwania rozmytego w zależności od długości wybranego bigramu. Wybrana długość ma względną skuteczność w oparciu o oczekiwaną długość ogólnych ciągów wyszukiwania.
Wreszcie - powyższe zapytanie podaje tylko rozmytą rangę dopasowania. Możesz bawić się i ulepszać, porównując nie tylko mecze, ale także mecze z ogólną liczbą bigramów, co pomoże odciążyć długie ciągi wyszukiwania w porównaniu z krótkimi ciągami. Zatrzymałem się tutaj, ponieważ w tym momencie staje się on znacznie bardziej specyficzny dla aplikacji.
Mam nadzieję, że to pomoże!
R