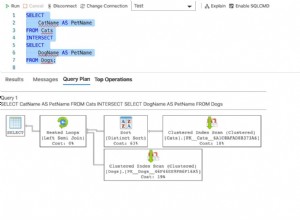
Krótka odpowiedź brzmi:tak, klucz podstawowy ma kolejność, wszystkie indeksy mają kolejność, a klucz główny jest po prostu unikalnym indeksem.
Jak słusznie powiedziałeś, nie powinieneś polegać na zwracaniu danych w kolejności, w jakiej są one przechowywane, optymalizator może je zwrócić w dowolnej kolejności, a to będzie zależeć od planu zapytania. Postaram się jednak wyjaśnić, dlaczego Twoje zapytanie działa od 12 lat.
Indeks klastrowy to tylko dane tabeli, a klucz klastrowania definiuje kolejność, w jakiej są przechowywane. Dane są przechowywane na liściu, a klucz klastrowania pomaga głównym (i nutom pośrednim) działać jako wskaźniki, aby szybko dostać się do prawy liść, aby pobrać dane. Indeks nieklastrowy ma bardzo podobną strukturę, ale najniższy poziom zawiera po prostu wskaźnik do prawidłowej pozycji na liściu indeksu klastrowego.
W MySQL klucz podstawowy i indeks klastrowy są synonimami, więc klucz podstawowy jest uporządkowany, jednak są to zasadniczo dwie różne rzeczy. W innych DBMS można zdefiniować zarówno klucz podstawowy, jak i indeks klastrowy, kiedy to zrobisz, twój klucz podstawowy stanie się unikalnym indeksem nieklastrowym ze wskaźnikiem do indeksu klastrowego.
Mówiąc najprościej, możesz sobie wyobrazić tabelę z kolumną ID, która jest kluczem podstawowym, i inną kolumną (A), struktura B-drzewa dla indeksu klastrowego wyglądałaby mniej więcej tak:
Root Node
+---+
| 1 |
+---+
Intermediate Nodes
+---+ +---+ +---+
| 1 | | 4 | | 7 |
+---+ +---+ +---+
Leaf
+-----------+ +-----------+ +-----------+
ID -> | 1 | 2 | 3 | | 4 | 5 | 6 | | 7 | 8 | 9 |
A -> | A | B | C | | D | E | F | | G | H | I |
+-----------+ +-----------+ +-----------+
W rzeczywistości strony liści będą znacznie większe, ale to tylko demo. Każda strona ma również wskaźnik do następnej strony i poprzedniej strony, aby ułatwić poruszanie się po drzewie. Więc kiedy robisz zapytanie takie jak:
SELECT ID, A
FROM T
WHERE ID > 5
LIMIT 1;
skanujesz unikalny indeks, więc jest bardzo prawdopodobne, że będzie to skanowanie sekwencyjne. Jednak bardzo prawdopodobne, że nie jest to gwarantowane.
MySQL przeskanuje węzeł główny, jeśli istnieje potencjalne dopasowanie, przejdzie do węzłów pośrednich, jeśli klauzula była podobna do WHERE ID < 0 wtedy MySQL wiedziałby, że nie ma żadnych wyników, nie przechodząc dalej niż węzeł główny.
Po przejściu do węzła pośredniego może zidentyfikować, że musi rozpocząć się na drugiej stronie (od 4 do 7), aby rozpocząć wyszukiwanie ID > 5 . Więc sekwencyjnie skanuje liść, zaczynając od strony drugiego liścia, po zidentyfikowaniu już LIMIT 1 zatrzyma się, gdy znajdzie dopasowanie (w tym przypadku 6) i zwróci te dane z liścia. W tak prostym przykładzie zachowanie to wydaje się być wiarygodne i logiczne. Próbowałem wymusić wyjątki, wybierając wartość identyfikatora, o której wiem, że znajduje się na końcu strony liścia, aby sprawdzić, czy liść zostanie zeskanowany w odwrotnej kolejności, ale jak dotąd nie byłem w stanie wywołać takiego zachowania, nie oznacza to jednak tak się nie stanie lub przyszłe wydania MySQL nie zrobią tego w testowanych przeze mnie scenariuszach.
Krótko mówiąc, po prostu dodaj zamówienie przez lub użyj MIN(ID) i gotowe. Nie straciłbym zbyt wiele snu, próbując zagłębić się w wewnętrzne działanie optymalizatora zapytań, aby zobaczyć, jaki rodzaj fragmentacji lub zakresy danych byłyby wymagane do zaobserwowania różnej kolejności indeksu klastrowego w ramach planu zapytania.