Wprowadzenie
Istnieją dwie szkoły myślenia o wykonywaniu obliczeń w twojej bazie danych:ludzie, którzy uważają, że jest to świetne, i ludzie, którzy się mylą. Nie oznacza to, że świat funkcji, procedur składowanych, generowanych lub obliczanych kolumn i wyzwalaczy jest pełen słońca i róż! Narzędzia te są dalekie od niezawodnych, a nieprzemyślane implementacje mogą działać słabo, traumatyzować ich opiekunów i nie tylko, co w pewnym stopniu wyjaśnia istnienie kontrowersji.
Ale bazy danych są z definicji bardzo dobre w przetwarzaniu i manipulowaniu informacjami, a większość z nich udostępnia tę samą kontrolę i moc swoim użytkownikom (w mniejszym stopniu SQLite i MS Access). Zewnętrzne programy do przetwarzania danych zaczynają od wyciągnięcia informacji z bazy danych, często przez sieć, zanim zdążą cokolwiek zrobić. A tam, gdzie programy bazodanowe mogą w pełni korzystać z natywnych operacji na zbiorach, indeksowania, tabel tymczasowych i innych owoców półwiecznej ewolucji baz danych, zewnętrzne programy o dowolnej złożoności zwykle wymagają pewnego poziomu ponownego wymyślania koła. Dlaczego więc nie uruchomić bazy danych?
Oto dlaczego możesz nie chcesz zaprogramować swoją bazę danych!
- Funkcjonalność bazy danych ma tendencję do bycia niewidoczną — szczególnie wyzwala. Ta słabość skaluje się w przybliżeniu wraz z rozmiarem zespołów i/lub aplikacji współpracujących z bazą danych, ponieważ mniej osób pamięta lub jest świadomych programowania w bazie danych. Dokumentacja pomaga, ale tylko tyle.
- SQL to język stworzony specjalnie do manipulowania zestawami danych. Nie jest szczególnie dobry w rzeczach, które nie manipulują zestawami danych, a jest tym mniej dobry, im bardziej skomplikowane stają się te inne rzeczy.
- Możliwości RDBMS i dialekty SQL różnią się. Proste generowane kolumny są szeroko obsługiwane, ale przeniesienie bardziej złożonej logiki bazy danych do innych sklepów wymaga minimum czasu i wysiłku.
- Aktualizacje schematu bazy danych są zwykle bardziej obciążone niż uaktualnienia aplikacji. Szybko zmieniającą się logikę najlepiej zachować gdzie indziej, chociaż warto jeszcze raz się temu przyjrzeć, gdy sytuacja się ustabilizuje.
- Zarządzanie programami bazodanowymi nie jest tak proste, jak można by się spodziewać. Wiele narzędzi do migracji schematów robi niewiele lub nic dla organizacji, co prowadzi do rozrastających się różnic i uciążliwych przeglądów kodu (wykresy zależności Sqitcha i przeróbki poszczególnych obiektów sprawiają, że jest to godny uwagi wyjątek, a migra stara się całkowicie ominąć problem). Podczas testowania frameworki, takie jak pgTAP i utPLSQL, poprawiają testy integracji z czarną skrzynką, ale także stanowią dodatkowe zobowiązanie do wsparcia i konserwacji.
- Dzięki ugruntowanej zewnętrznej bazie kodu każda zmiana strukturalna wydaje się być zarówno pracochłonna, jak i ryzykowna.
Z drugiej strony, w przypadku zadań, do których jest dostosowany, SQL oferuje szybkość, zwięzłość, trwałość i możliwość „kanonizacji” zautomatyzowanych przepływów pracy. Modelowanie danych to coś więcej niż przypinanie obiektów jak owady do kartonu, a rozróżnienie między danymi w ruchu a danymi w spoczynku jest trudne. Odpoczynek to naprawdę wolniejszy ruch w drobniejszym nachyleniu; informacje zawsze przepływają stąd do tam, a programowalność bazy danych jest potężnym narzędziem do zarządzania i kierowania tymi przepływami.
Niektóre aparaty baz danych dzielą różnicę między SQL a innymi językami programowania, uwzględniając również te inne języki programowania. SQL Server obsługuje funkcje napisane w dowolnym języku .NET Framework; Oracle ma procedury składowane w języku Java; PostgreSQL pozwala na rozszerzenia w języku C i jest programowalny przez użytkownika w Pythonie, Perlu i Tcl, z wtyczkami dodającymi skrypty powłoki, R, JavaScript i inne. Dopełniając zwykłych podejrzanych, to SQL lub nic dla MySQL i MariaDB, MS Access jest tylko programowalny w VBA, a SQLite nie jest w ogóle programowalny przez użytkownika.
Używanie języków innych niż SQL jest opcją, jeśli SQL jest niewystarczający do jakiegoś zadania lub jeśli chcesz ponownie użyć innego kodu, ale nie ominie innych problemów, które sprawiają, że programowanie baz danych jest mieczem o wielu ostrzach. Jeśli już, uciekanie się do nich jeszcze bardziej komplikuje wdrażanie i interoperacyjność. Zastrzeżenie autora skryptu:niech pisarz się strzeże.
Funkcje a procedury
Podobnie jak w przypadku innych aspektów implementacji standardu SQL, dokładne szczegóły różnią się nieco od RDBMS do RDBMS. Ogólnie:
- Funkcje nie mogą kontrolować transakcji.
- Funkcje zwracają wartości; procedury mogą modyfikować parametry oznaczone
OUTlubINOUTktóre można następnie odczytać w kontekście wywołującym, ale nigdy nie zwracają wyniku (z wyjątkiem SQL Server). - Funkcje są wywoływane z instrukcji SQL w celu wykonania pewnej pracy na pobieraniu lub przechowywaniu rekordów, podczas gdy procedury działają samodzielnie.
Mówiąc dokładniej, MySQL nie zezwala również na rekursję i niektóre dodatkowe instrukcje SQL w funkcjach. SQL Server zabrania funkcjom modyfikowania danych, wykonywania dynamicznego SQL i obsługi błędów. PostgreSQL w ogóle nie oddzielał procedur składowanych od funkcji do 2017 roku w wersji 11, więc funkcje Postgresa mogą robić prawie wszystko, co mogą procedury, z wyłączeniem kontroli transakcji.
Więc którego użyć, kiedy? Funkcje najlepiej nadają się do logiki, która stosuje rekord po rekordzie, gdy dane są przechowywane i pobierane. Bardziej złożone przepływy pracy, które są wywoływane samodzielnie i przenoszą dane wewnętrznie, są lepsze jako procedury.
Domyślne i generowanie
Nawet proste obliczenia mogą sprawiać problemy, jeśli są wykonywane wystarczająco często lub jeśli istnieje wiele konkurencyjnych implementacji. Operacje na wartościach w jednym wierszu — pomyśl o przeliczeniu jednostek metrycznych na imperialne, pomnożenie stawki przez przepracowane godziny dla sum częściowych faktur, obliczenie obszaru wielokąta geograficznego — można zadeklarować w definicji tabeli w celu rozwiązania jednego lub drugiego problemu :
CREATE TABLE pythag ( a INT NOT NULL, b INT NOT NULL, c DOUBLE PRECISION NOT NULL GENERATED ALWAYS AS (sqrt(pow(a, 2) + pow(b, 2))) STORED);
Większość RDBMS oferuje wybór między kolumnami „przechowywanymi” i „wirtualnymi”. W pierwszym przypadku wartość jest obliczana i przechowywana podczas wstawiania lub aktualizowania wiersza. Jest to jedyna opcja z PostgreSQL od wersji 12 i MS Access. Wirtualnie generowane kolumny są obliczane podczas zapytań, tak jak w widokach, więc nie zajmują miejsca, ale będą przeliczane częściej. Oba rodzaje są ściśle ograniczone:wartości nie mogą zależeć od informacji spoza wiersza, do którego należą, nie mogą być aktualizowane, a poszczególne systemy RDBMS mogą mieć jeszcze bardziej szczegółowe ograniczenia. Na przykład PostgreSQL zabrania partycjonowania tabeli na wygenerowanej kolumnie.
Wygenerowane kolumny to specjalistyczne narzędzie. Częściej wszystko, co jest potrzebne, to wartość domyślna na wypadek, gdyby wartość nie została podana podczas wstawiania. Funkcje takie jak now() pojawiają się często jako wartości domyślne kolumn, ale większość baz danych pozwala na funkcje niestandardowe i wbudowane (z wyjątkiem MySQL, gdzie tylko current_timestamp może być wartością domyślną).
Weźmy raczej suchy, ale prosty przykład numeru partii w formacie YYYYXXX, gdzie pierwsze cztery cyfry oznaczają bieżący rok, a pozostałe trzy liczniki przyrostowe:pierwsza partia wyprodukowana w tym roku to 2020001, druga 2020002 i tak dalej . Nie ma domyślnego typu ani wbudowanej funkcji, która generuje taką wartość, ale funkcja zdefiniowana przez użytkownika może numerować każdą partię
CREATE SEQUENCE lot_counter;CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN date_part('year', now())::TEXT || lpad(nextval('lot_counter'::REGCLASS)::TEXT, 2, '0');END;$$LANGUAGE plpgsql;CREATE TABLE lots ( lot_number TEXT NOT NULL DEFAULT next_lot_number () PRIMARY KEY, current_quantity INT NOT NULL DEFAULT 0, target_quantity INT NOT NULL, created_at TIMESTAMPTZ NOT NULL DEFAULT now(), completed_at TIMESTAMPTZ, CHECK (target_quantity > 0));
Odniesienia do danych w funkcjach
Powyższe podejście sekwencyjne ma jedną ważną słabość (i lot_counter nadal będzie miał tę samą wartość, co 31 grudnia. Istnieje jednak więcej niż jeden sposób śledzenia, ile partii zostało utworzonych w ciągu roku, i przez zapytanie lots sam next_lot_number funkcja może zagwarantować prawidłową wartość po upływie roku.
CREATE OR REPLACE FUNCTION next_lot_number () RETURNS TEXT AS $$BEGIN RETURN ( SELECT date_part('year', now())::TEXT || lpad((count(*) + 1)::TEXT, 2, '0') FROM lots WHERE date_part('year', created_at) = date_part('year', now()) );END;$$LANGUAGE plpgsql;ALTER TABLE lots ALTER COLUMN lot_number SET DEFAULT next_lot_number();
Przepływy pracy
Nawet funkcja z pojedynczą instrukcją ma zasadniczą przewagę nad kodem zewnętrznym:wykonanie nigdy nie opuszcza bezpieczeństwa gwarancji ACID bazy danych. Porównaj next_lot_number powyżej możliwości aplikacji klienckiej lub nawet procesu ręcznego, wykonując
Programy przechowywane z wieloma instrukcjami otwierają ogromną przestrzeń możliwości, ponieważ SQL zawiera wszystkie narzędzia potrzebne do pisania kodu proceduralnego, od obsługi wyjątków po punkty zapisu (to nawet Turing z funkcjami okien i typowymi wyrażeniami tabelowymi!). W bazie danych można wykonywać całe przepływy pracy związane z przetwarzaniem danych, minimalizując ekspozycję na inne obszary systemu i eliminując czasochłonne podróże w obie strony między bazą danych a innymi domenami.
Ogólnie rzecz biorąc, większość architektury oprogramowania polega na zarządzaniu i izolowaniu złożoności, zapobiegając jej rozlaniu się poza granice między podsystemami. Jeśli jakiś mniej lub bardziej skomplikowany przepływ pracy obejmuje pobieranie danych do zaplecza aplikacji, skryptu lub zadania crona, analizowanie i dodawanie do nich oraz przechowywanie wyników — czas zapytać, co tak naprawdę wymaga wyjścia poza bazę danych.
Jak wspomniano powyżej, jest to obszar, w którym na pierwszy plan wysuwają się różnice między smakami RDBMS a dialektami SQL. Funkcja lub procedura opracowana dla jednej bazy danych prawdopodobnie nie będzie działać w innej bez zmian, niezależnie od tego, czy zastąpi to TOP SQL Server dla standardowego LIMIT lub całkowicie przerobić sposób przechowywania stanu tymczasowego w korporacyjnej migracji Oracle do PostgreSQL. Kanonizowanie przepływów pracy w SQL zobowiązuje Cię również do korzystania z obecnej platformy i dialektu bardziej dokładnie niż prawie każdy inny wybór, jakiego możesz dokonać.
Obliczenia w zapytaniach
Do tej pory przyjrzeliśmy się wykorzystaniu funkcji do przechowywania i modyfikowania danych, niezależnie od tego, czy są one powiązane z definicjami tabel, czy też zarządzają wielotabelowymi przepływami pracy. W pewnym sensie jest to potężniejsze zastosowanie, do jakiego można je wykorzystać, ale funkcje mają również miejsce w pobieraniu danych. Wiele narzędzi, których możesz już używać w swoich zapytaniach, zostało zaimplementowanych jako funkcje, od standardowych wbudowanych funkcji, takich jak count do rozszerzeń, takich jak jsonb_build_object Postgresa , ST_SnapToGrid PostGIS , i więcej. Oczywiście, ponieważ są one ściślej zintegrowane z samą bazą danych, są w większości napisane w językach innych niż SQL (np. C w przypadku PostgreSQL i PostGIS).
Jeśli często zdarza Ci się (lub myślisz, że może się okazać), że musisz pobrać dane, a następnie wykonać jakąś operację na każdym rekordzie, zanim będzie naprawdę gotowe, zamiast tego rozważ przekształcenie ich po wyjściu z bazy danych! Przewidujesz określoną liczbę dni roboczych od daty? Generowanie różnicy między dwoma JSONB pola? Praktycznie każde obliczenie, które zależy tylko od informacji, o które pytasz, można wykonać w SQL. A to, co dzieje się w bazie danych – o ile jest do niej konsekwentnie używany – jest kanoniczne, jeśli chodzi o wszystko, co jest zbudowane na bazie danych.
Trzeba powiedzieć:jeśli pracujesz z backendem aplikacji, jego zestaw narzędzi do dostępu do danych może ograniczać przebieg, jaki uzyskasz z rozszerzania wyników zapytań o funkcje. Większość takich bibliotek może wykonywać dowolny kod SQL, ale te, które generują typowe instrukcje SQL na podstawie klas modeli, mogą, ale nie muszą umożliwiać dostosowywania zapytania SELECT listy. Wygenerowane kolumny lub widoki mogą być tutaj odpowiedzią.
Wyzwalacze i konsekwencje
Funkcje i procedury są wystarczająco kontrowersyjne wśród projektantów baz danych i użytkowników, ale rzeczy naprawdę startuj z wyzwalaczami. Wyzwalacz definiuje automatyczną akcję, zwykle procedurę (SQLite pozwala tylko na jedną instrukcję), która ma być wykonana przed, po lub zamiast innej akcji.
Akcja inicjująca to zazwyczaj wstawienie, aktualizacja lub usunięcie tabeli, a procedurę wyzwalacza można zazwyczaj ustawić tak, aby wykonywała się dla każdego rekordu lub dla całej instrukcji. SQL Server umożliwia również wyzwalacze w widokach, które można aktualizować, głównie jako sposób na wymuszenie bardziej szczegółowych środków bezpieczeństwa; i to, PostgreSQL i Oracle oferują jakąś formę zdarzenia lub
Typowym zastosowaniem wyzwalaczy o niskim ryzyku jest bardzo silne ograniczenie zapobiegające przechowywaniu nieprawidłowych danych. We wszystkich głównych relacyjnych bazach danych tylko klucze podstawowe i obce oraz UNIQUE ograniczenia mogą oceniać informacje spoza rekordu kandydata. Nie można zadeklarować w definicji tabeli, że na przykład tylko dwie partie mogą zostać utworzone w ciągu miesiąca — a najprostsze rozwiązanie oparte na bazie danych i kodach jest podatne na podobny stan wyścigu, jak podejście policz, a następnie ustaw lot_number nad. Aby wymusić jakiekolwiek inne ograniczenie, które dotyczy całej tabeli lub innych tabel, potrzebujesz
CREATE FUNCTION enforce_monthly_lot_limit () RETURNS TRIGGERAS $$DECLARE current_count BIGINT;BEGIN SELECT count(*) INTO current_count FROM lots WHERE date_trunc('month', created_at) = date_trunc('month', NEW.created_at); IF current_count >= 2 THEN RAISE EXCEPTION 'Two lots already created this month'; END IF; RETURN NEW;END;$$LANGUAGE plpgsql;CREATE TRIGGER monthly_lot_limitBEFORE INSERT ON lotsFOR EACH ROWEXECUTE PROCEDURE enforce_monthly_lot_limit();
Po rozpoczęciu wykonywania lots samo w sobie może być ostateczną operacją wyzwalacza zainicjowaną przez wstawienie do orders , bez ludzkiego użytkownika lub zaplecza aplikacji upoważnionego do pisania w lots bezpośrednio. Lub jako items są dodawane do wielu, wyzwalacz może obsłużyć aktualizację current_quantity i rozpocznij inny proces, gdy osiągnie target_quantity .
Wyzwalacze i funkcje mogą działać na poziomie dostępu ich definiującego (w PostgreSQL SECURITY DEFINER deklaracja obok LANGUAGE funkcji ), co daje ograniczonym użytkownikom możliwość inicjowania procesów o szerszym zakresie – i sprawia, że walidacja i testowanie tych procesów jest jeszcze ważniejsze.
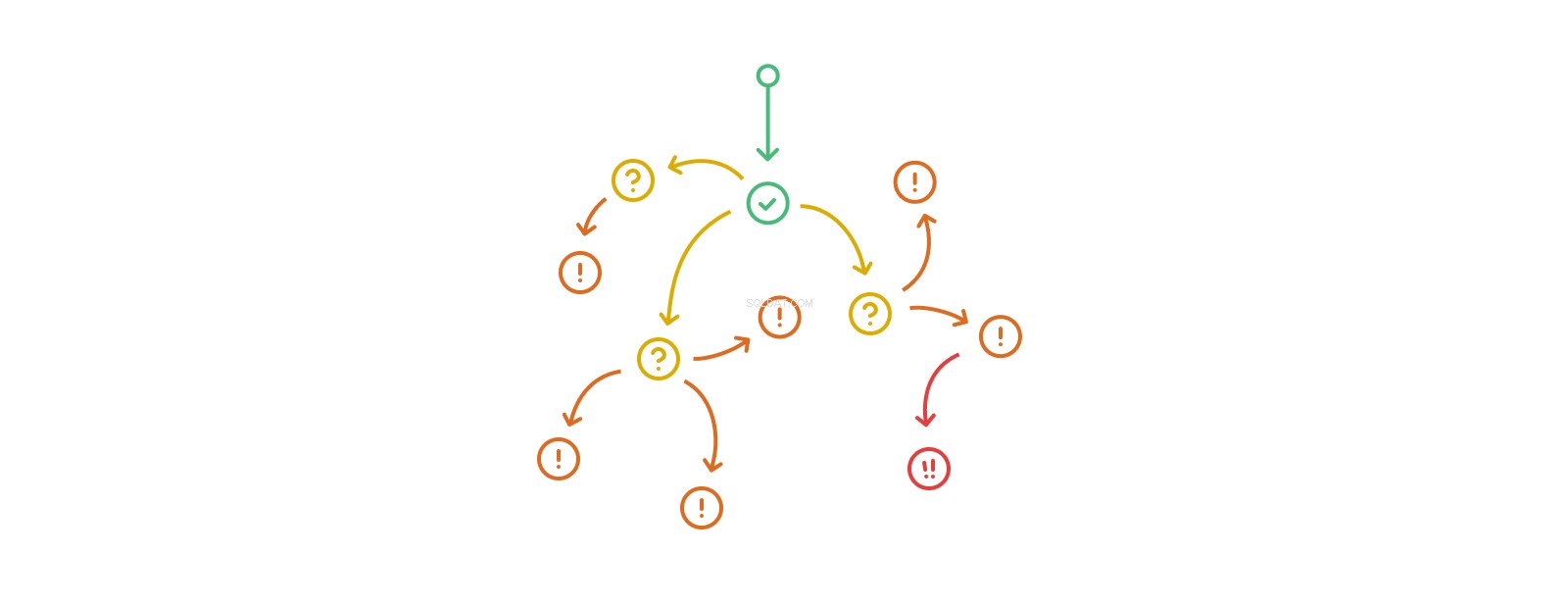
Stos wywołań wyzwalacz-akcja-wyzwalacz-akcja może stać się dowolnie długi, chociaż prawdziwa rekurencja w postaci wielokrotnego modyfikowania tych samych tabel lub rekordów w dowolnym takim przepływie jest nielegalna na niektórych platformach i ogólnie zły pomysł w prawie wszystkich okolicznościach. Zagnieżdżanie wyzwalaczy szybko przewyższa naszą zdolność do zrozumienia jego zasięgu i skutków. Bazy danych intensywnie wykorzystujące zagnieżdżone wyzwalacze zaczynają dryfować ze sfery skomplikowanych w kierunku złożonych, stając się trudne lub niemożliwe do analizy, debugowania i przewidywania.
Praktyczna programowalność
Obliczenia w bazie danych są nie tylko szybsze i bardziej zwięzłe, ale eliminują niejasności i wyznaczają standardy. Powyższe przykłady uwalniają użytkowników baz danych od konieczności samodzielnego obliczania numerów partii lub obaw o przypadkowe utworzenie większej liczby partii, niż są w stanie obsłużyć. Zwłaszcza programiści aplikacji byli często szkoleni, aby myśleć o bazach danych jako o „głupim magazynie”, zapewniającym jedynie strukturę i trwałość, i w ten sposób mogą znaleźć się – lub, co gorsza, nie zdawać sobie sprawy, że tak jest – niezdarnie artykułować poza bazą danych, co mogą zrobić bardziej efektywnie w SQL.
Programowalność jest niesłusznie pomijaną cechą relacyjnych baz danych. Istnieją powody, aby tego unikać, a więcej, aby ograniczyć jego użycie, ale funkcje, procedury i wyzwalacze to potężne narzędzia do ograniczania złożoności, jaką model danych narzuca systemom, w których jest osadzony.