Wprowadzenie
Przechowywanie danych to jedno; przechowywanie sensownych, użytecznych, poprawnych dane to zupełnie inna sprawa. Podczas gdy znaczenie i użyteczność są same w sobie cechami subiektywnymi, przynajmniej poprawność można logicznie zdefiniować i wymusić. Typy już zapewniają, że liczby są liczbami, a daty datami, ale nie gwarantują, że waga lub odległość są liczbami dodatnimi, ani nie zapobiegają nakładaniu się zakresów dat. Ograniczenia krotek, tabel i baz danych stosują reguły do przechowywanych danych i odrzucają wartości lub kombinacje wartości, które nie przechodzą procesu weryfikacji.
Ograniczenia nie powodują, że inne techniki walidacji danych wejściowych są bezużyteczne, nawet jeśli testują te same potwierdzenia. Czas spędzony na próbie i niepowodzeniu przechowywania nieprawidłowych danych to strata czasu. Komunikaty o naruszeniu, takie jak assert w systemach i językach programowania aplikacji, ujawnia tylko pierwszy problem z pierwszym rekordem kandydata bardziej szczegółowo niż ktokolwiek, kto nie jest bezpośrednio zaangażowany w potrzeby bazy danych. Ale jeśli chodzi o poprawność danych, ograniczenia są prawem, na dobre lub na złe; wszystko inne jest radą.
W krotkach:wartość niezerowa, domyślna i sprawdzona
Najprostszą kategorią są ograniczenia inne niż null. Krotka musi mieć wartość atrybutu ograniczonego lub inaczej zestaw dozwolonych wartości dla kolumny nie zawiera już pustego zestawu. Brak wartości oznacza brak krotki:wstawienie lub aktualizacja są odrzucane.
Ochrona przed wartościami null jest tak prosta, jak zadeklarowanie column_name COLUMN_TYPE NOT NULL w CREATE TABLE lub ADD COLUMN . Wartości null powodują całe kategorie problemów między bazą danych a użytkownikami końcowymi, więc odruchowe definiowanie ograniczeń innych niż null w dowolnej kolumnie bez uzasadnionego powodu, aby zezwalać na wartości null, jest dobrym nawykiem.
Dostarczenie wartości domyślnej, jeśli nic nie jest określone (przez pominięcie lub jawne NULL ) we wstawce lub aktualizacji nie zawsze jest uważane za ograniczenie, ponieważ rekordy kandydatów są modyfikowane i przechowywane, a nie odrzucane. W wielu DBMS wartości domyślne mogą być generowane przez funkcję, chociaż MySQL nie zezwala na funkcje zdefiniowane przez użytkownika w tym celu.
Każda inna reguła walidacji, która zależy tylko od wartości w ramach pojedynczej krotki, może zostać zaimplementowana jako CHECK ograniczenie. W pewnym sensie NOT NULL samo w sobie jest skrótem dla CHECK (column_name IS NOT NULL); większość różnicy ma komunikat o błędzie otrzymany z naruszeniem. CHECK , jednak może zastosować i wymusić prawdziwość dowolnego predykatu logicznego dla pojedynczej krotki. Na przykład tabela przechowująca lokalizacje geograficzne powinna CHECK (latitude >= -90 AND latitude < 90) , i podobnie dla długości od -180 do 180 -- lub, jeśli to możliwe, użyj i zweryfikuj GEOGRAPHY typ danych.
W tabelach:unikatowe i wykluczające
Ograniczenia na poziomie tabeli testują krotki względem siebie. W ograniczeniu przez unikalność tylko jeden rekord może mieć dowolny zestaw wartości dla ograniczonych kolumn. Nullability może tutaj powodować problemy, ponieważ NULL nigdy nie równa się niczemu innemu, włącznie z NULL samo. Unikalne ograniczenie dla (batman, robin) dlatego pozwala na nieskończoną liczbę kopii każdego Robinlessa Batmana.
Ograniczenia wykluczenia są obsługiwane tylko w PostgreSQL i DB2, ale wypełniają bardzo przydatną niszę:mogą zapobiegać nakładaniu się. Określ ograniczone pola i operacje, według których każde z nich będzie oceniane, a nowy rekord zostanie zaakceptowany tylko wtedy, gdy żaden istniejący rekord nie zostanie pomyślnie porównany z każdym polem i operacją. Na przykład schedules tabela może być skonfigurowana do odrzucania konfliktów:
-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Operacje upsert, takie jak ON CONFLICT w PostgreSQL klauzula lub ON DUPLICATE KEY UPDATE MySQL użyj ograniczenia na poziomie tabeli, aby wykryć konflikty. I podobnie jak ograniczenia inne niż null mogą być wyrażone jako CHECK ograniczeniami, unikatowe ograniczenie może być wyrażone jako ograniczenie wykluczające równość.
Klucz podstawowy
Unikalne ograniczenia mają szczególnie przydatny przypadek specjalny. Dzięki dodatkowemu ograniczeniu niezerowemu dla unikatowej kolumny lub kolumn, każdy rekord w tabeli może być pojedynczo identyfikowany przez jego wartości dla ograniczonych kolumn, które są zbiorczo określane jako klucz . W tabeli może współistnieć wiele kluczy kandydujących, na przykład users nadal czasami mają odrębny unikalny i niepusty email s i username s; ale zadeklarowanie klucza podstawowego ustanawia pojedyncze kryterium, według którego rekordy są publicznie i wyłącznie znane. Niektóre RDBMS nawet organizują wiersze na stronach według klucza podstawowego, nazywanego w tym celu indeksem klastrowym , aby wyszukiwanie według wartości klucza podstawowego było jak najszybsze.
Istnieją dwa rodzaje klucza podstawowego. Klucz naturalny jest definiowany na kolumnie lub kolumnach „naturalnie” zawartych w danych tabeli, podczas gdy klucz zastępczy lub syntetyczny jest wymyślany wyłącznie w celu stania się kluczem. Klucze naturalne wymagają uwagi — więcej rzeczy może się zmienić, niż często przyznają projektanci baz danych, od nazw po schematy numeracji. Tabela przeglądowa zawierająca nazwy krajów i regionów może używać ich odpowiednich kodów ISO 3166 jako bezpiecznego naturalnego klucza podstawowego, ale users tabela z naturalnym kluczem opartym na zmiennych wartościach, takich jak nazwiska lub adresy e-mail, zachęca do kłopotów. W razie wątpliwości utwórz klucz zastępczy.
Jeśli klucz naturalny obejmuje wiele kolumn, zawsze należy przynajmniej rozważyć klucz zastępczy, ponieważ zarządzanie kluczami wielokolumnowymi wymaga więcej wysiłku. Jeśli jednak naturalny klucz jest odpowiedni, kolumny powinny być uporządkowane z rosnącą szczegółowością, tak jak w indeksach:kod kraju to kod regionu, a nie odwrotnie.
Klucz zastępczy był historycznie pojedynczą kolumną liczb całkowitych, czyli BIGINT gdzie ostatecznie zostaną przypisane miliardy. Relacyjne bazy danych mogą automatycznie wypełniać klucze zastępcze następną liczbą całkowitą w serii, co zwykle nazywa się SERIAL lub IDENTITY .
Licznik liczbowy z automatycznym zwiększaniem nie jest pozbawiony wad:dodawanie rekordów ze wstępnie wygenerowanymi kluczami może powodować konflikty, a jeśli wartości sekwencyjne są ujawniane użytkownikom, łatwo jest im odgadnąć, jakie mogą być inne prawidłowe klucze. Uniwersalnie unikalne identyfikatory lub UUID pozwalają uniknąć tych słabości i stały się powszechnym wyborem dla kluczy zastępczych, chociaż są również znacznie większe na stronie niż zwykła liczba. Najczęściej używane są typy UUID v1 (oparte na adresach MAC) i v4 (pseudolosowe).
W bazie danych:klucze obce
Relacyjne bazy danych implementują tylko jedną klasę ograniczenia wielotabelowego,
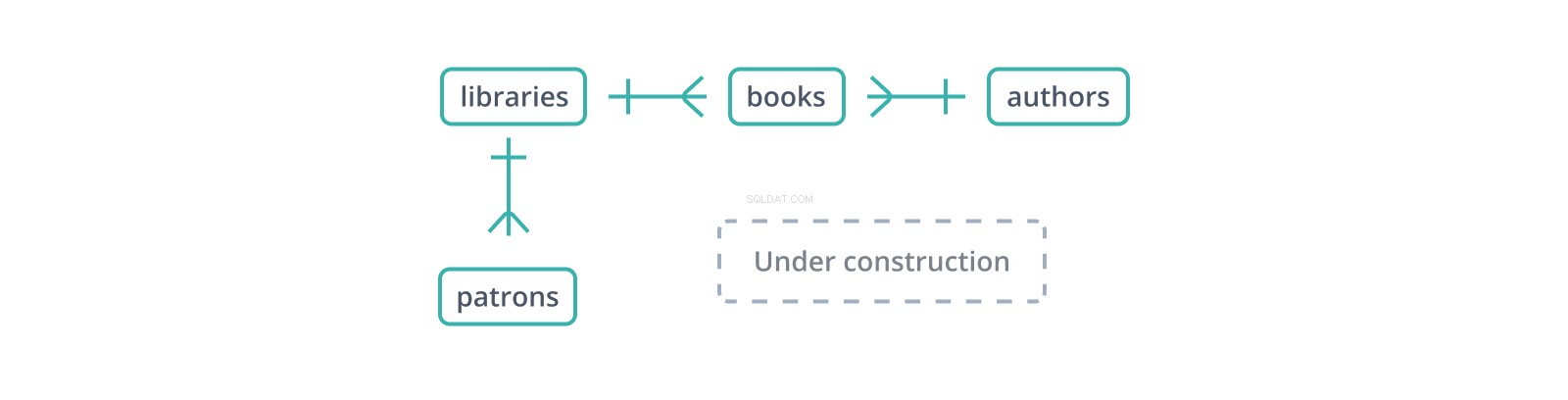
Ten nieformalny „schemat relacji między podmiotami” lub ERD pokazuje początki schematu bazy danych bibliotek i ich kolekcji oraz patronów. Każda krawędź reprezentuje relację między tabelami, które łączy. | glif wskazuje pojedynczy rekord na boku, podczas gdy glif „kurzej łapki” reprezentuje wiele:biblioteka zawiera wiele książek i ma wielu klientów.
Klucz obcy to kopia klucza podstawowego innej tabeli, kolumna po kolumnie (punkt na korzyść kluczy zastępczych:tylko jedna kolumna do skopiowania i odniesienia), z wartościami łączącymi rekordy w tej tabeli z rekordami „nadrzędnymi”. W powyższym schemacie books tabela utrzymuje library_id klucz obcy do libraries , które przechowują książki, oraz author_id do authors , którzy je piszą. Ale co się stanie, jeśli książka zostanie wstawiona z author_id? który nie istnieje w authors ?
Jeśli klucz obcy nie jest ograniczony – tj. jest tylko kolejną kolumną lub kolumnami – książka może mieć autora, który nie istnieje. To jest problem:jeśli ktoś spróbuje skorzystać z linku między books i authors , kończą się nigdzie. Jeśli authors.author_id jest szeregową liczbą całkowitą, istnieje również możliwość, że nikt nie zauważy aż do fałszywego author_id zostanie ostatecznie przydzielony i otrzymujesz konkretną kopię Don Kichota przypisywane najpierw nikomu znanemu, a potem Pierre'owi Menardowi, a Miguela Cervantesa nigdzie nie można znaleźć.
Ograniczenie klucza obcego nie może zapobiec błędnemu przypisaniu książki w przypadku błędnego author_id wskaż istniejący rekord w authors , więc inne kontrole i testy pozostają ważne. Jednak zestaw istniejących wartości kluczy obcych jest prawie zawsze małym podzbiorem możliwych wartości kluczy obcych, dzięki czemu ograniczenia kluczy obcych będą przechwytywać i zapobiegać większości błędnych wartości. Z ograniczeniem klucza obcego Kichot z nieistniejącym autorem zostanie odrzucony zamiast nagrany.
Czy to skąd pochodzi „relacyjne” w „relacyjnej bazie danych”?
Klucze obce tworzą relacje między tabelami, ale znane nam tabele są matematycznymi relacjami wśród zestawów możliwych wartości dla każdego atrybutu. Pojedyncza krotka wiąże wartość z kolumny A z wartością z kolumny B i dalej. W oryginalnym artykule E.F. Codda użyto słowa „relacyjne” w tym sensie.
Spowodowało to niekończące się zamieszanie i prawdopodobnie będzie to trwać bez końca.
Dla niektórych wartości poprawnych
Istnieje wiele innych sposobów, w jakie dane mogą być nieprawidłowe, niż omówiono tutaj. Ograniczenia pomagają, ale nawet one są tak elastyczne; wiele typowych specyfikacji wewnątrz tabeli, takich jak ograniczenie do dwóch lub więcej przypadków, w których wartość może pojawić się w kolumnie, można wymusić tylko za pomocą wyzwalaczy.
Ale są też sposoby, w jakie sama struktura tabeli może prowadzić do niespójności. Aby temu zapobiec, musimy zebrać klucze podstawowe i obce nie tylko w celu zdefiniowania i sprawdzenia poprawności, ale także normalizacji relacje między tabelami. Po pierwsze jednak ledwo zarysowaliśmy powierzchnię tego, jak relacje między tabelami definiują strukturę samej bazy danych.



