Bazy danych, które obsługują aplikacje biznesowe, powinny często obsługiwać dane tymczasowe. Załóżmy na przykład, że umowa z dostawcą jest ważna tylko przez ograniczony czas. Może być ważny od określonego punktu w czasie lub może być ważny przez określony przedział czasu — od początkowego punktu czasowego do końcowego punktu czasowego. Ponadto wiele razy trzeba przeprowadzić audyt wszystkich zmian w jednej lub kilku tabelach. Może być również konieczne pokazanie stanu w określonym momencie lub wszystkich zmian dokonanych w tabeli w określonym czasie. Z punktu widzenia integralności danych może być konieczne zaimplementowanie wielu dodatkowych ograniczeń czasowych.
Przedstawiamy dane czasowe
W tabeli z obsługą czasową nagłówek reprezentuje predykat z co najmniej jednorazowym parametrem reprezentującym przedział gdy reszta predykatu jest prawidłowa — kompletny predykat jest zatem predykatem ze znacznikiem czasu. Wiersze reprezentują propozycje ze znacznikiem czasu, a poprawny okres czasu wiersza jest zwykle wyrażany za pomocą dwóch atrybutów:od i do lub rozpocznij i koniec .
Rodzaje tabel czasowych
Być może zauważyłeś podczas części wprowadzającej, że istnieją dwa rodzaje problemów czasowych. Pierwszy to czas ważności propozycji – w jakim okresie propozycja reprezentowana przez wiersz ze znacznikiem czasu w tabeli była rzeczywiście prawdziwa. Na przykład umowa z dostawcą obowiązywała tylko od punktu 1 do punktu 2. Ten rodzaj czasu ważności ma znaczenie dla ludzi, ma znaczenie dla biznesu. Czas ważności jest również nazywany czasem aplikacji lub czas ludzki . Możemy mieć wiele ważnych okresów dla tego samego podmiotu. Na przykład wspomniana umowa, która obowiązywała od punktu czasowego 1 do punktu czasowego 2, może również obowiązywać od punktu czasowego 7 do punktu czasowego 9.
Drugą kwestią czasową jest czas transakcji . Wiersz do umowy, o której mowa powyżej, został wstawiony w punkcie czasowym 1 i był jedyną wersją prawdy znaną bazie danych, dopóki ktoś jej nie zmienił, a nawet do końca czasu. Gdy wiersz jest aktualizowany w punkcie czasowym 2, oryginalny wiersz był znany jako zgodny z bazą danych od punktu czasowego 1 do punktu czasowego 2. Wstawiany jest nowy wiersz dla tej samej propozycji z czasem ważnym dla bazy danych od punktu czasowego 2 do koniec czasu. Czas transakcji jest również znany jako czas systemowy lub czas bazy danych .
Oczywiście można również zaimplementować zarówno tabele wersji aplikacji, jak i systemu. Takie tabele nazywają się dwuczasowe tabele.
W SQL Server 2016 otrzymujesz natychmiastową obsługę czasu systemowego za pomocą tabeli czasowych w wersji systemowej . Jeśli potrzebujesz wdrożyć czas aplikacji, musisz samodzielnie opracować rozwiązanie.
Operatory interwałowe Allena
Teoria danych czasowych w modelu relacyjnym zaczęła ewoluować ponad trzydzieści lat temu. Przedstawię sporo użytecznych operatorów logicznych i kilka operatorów, które działają na przedziałach i zwracają przedział. Operatory te są znane jako operatory Allena, nazwane na cześć J. F. Allena, który zdefiniował ich liczbę w pracy badawczej z 1983 roku na temat przedziałów czasowych. Wszystkie są nadal akceptowane jako ważne i potrzebne. System zarządzania bazą danych może pomóc w radzeniu sobie z czasami aplikacji, wdrażając te operatory po wyjęciu z pudełka.
Pozwólcie, że najpierw przedstawię notację, której będę używał. Będę pracował na dwóch interwałach, oznaczonych i1 i i2 . Początkowy punkt czasowy pierwszego interwału to b1 , a koniec to e1 ; początkowy punkt czasowy drugiego interwału to b2 a koniec to e2 . Operatory logiczne Allena są zdefiniowane w poniższej tabeli.
[table id=2 /]
Oprócz operatorów logicznych istnieją trzy operatory Allena, które akceptują interwały jako parametry wejściowe i zwracają interwał. Operatory te tworzą prostą algebrę przedziałów . Zwróć uwagę, że te operatory mają taką samą nazwę jak operatory relacyjne, które prawdopodobnie już znasz:Suma, Przecięcie i Minus. Jednak nie zachowują się dokładnie tak, jak ich relacyjni odpowiednicy. Ogólnie rzecz biorąc, używając dowolnego z trzech operatorów interwałów, jeśli operacja spowodowałaby powstanie pustego zestawu punktów czasowych lub zestawu, którego nie można opisać jednym interwałem, operator powinien zwrócić NULL. Połączenie dwóch przedziałów ma sens tylko wtedy, gdy przedziały się spotykają lub nakładają. Skrzyżowanie ma sens tylko wtedy, gdy odstępy się nakładają. Operator interwału minus ma sens tylko w niektórych przypadkach. Na przykład (3:10) Minus (5:7) zwraca NULL, ponieważ wynik nie może być opisany przez jeden przedział. Poniższa tabela podsumowuje definicje operatorów algebry przedziałowej.
[identyfikator tabeli=3/]
Problem z wydajnością nakładających się zapytań Jednym z najbardziej złożonych operatorów do wdrożenia jest nakładanie się operator. Nie jest łatwo zoptymalizować zapytania, które wymagają znalezienia nakładających się przedziałów. Jednak takie zapytania są dość częste w tabelach czasowych. W tym i następnych dwóch artykułach pokażę kilka sposobów na optymalizację takich zapytań. Ale zanim przedstawię rozwiązania, pozwól, że przedstawię problem.
Do wyjaśnienia problemu potrzebuję trochę danych. Poniższy kod pokazuje przykład, jak utworzyć tabelę z przedziałami ważności wyrażonymi za pomocą b i e kolumny, w których początek i koniec przedziału są reprezentowane jako liczby całkowite. Tabela jest wypełniana danymi demonstracyjnymi z tabeli WideWorldImporters.Sales.OrderLines. Pamiętaj, że istnieje wiele wersji WideWorldImporters bazy danych, więc możesz uzyskać nieco inne wyniki. Użyłem pliku kopii zapasowej WideWorldImporters-Standard.bak z https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 do przywrócenia tej demonstracyjnej bazy danych na mojej instancji SQL Server .
Tworzenie danych demonstracyjnych
Utworzyłem tabelę demonstracyjną dbo.Intervals w tempd bazę danych z następującym kodem.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Zwróć także uwagę na indeksy Utworzony. Te dwa indeksy są optymalne do wyszukiwania na początku lub na końcu interwału. Możesz sprawdzić minimalny początek i maksymalny koniec wszystkich interwałów za pomocą następującego kodu.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
W wynikach widać, że minimalny punkt czasowy rozpoczęcia to 1, a maksymalny punkt czasowy zakończenia to 1155.
Nadawanie kontekstu danym
Możesz zauważyć, że reprezentuję początek i koniec punkty czasu jako liczby całkowite. Teraz muszę nadać interwałom kontekst czasowy. W tym przypadku pojedynczy punkt czasowy reprezentuje dzień . Poniższy kod tworzy tablicę wyszukiwania dat i zapełnia go. Pamiętaj, że data rozpoczęcia to 1 lipca 2014 r.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Teraz możesz dwukrotnie połączyć tabelę dbo.Intervals z tabelą dbo.DateNums, aby nadać kontekst liczbom całkowitym reprezentującym początek i koniec interwałów.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Przedstawiamy problem z wydajnością
Problem z zapytaniami tymczasowymi polega na tym, że podczas odczytu z tabeli SQL Server może używać tylko jednego indeksu i skutecznie eliminować wiersze, które nie są kandydatami na wynik tylko z jednej strony, a następnie skanować resztę danych. Na przykład musisz znaleźć w tabeli wszystkie przedziały, które nakładają się na dany przedział. Pamiętaj, że dwa przedziały zachodzą na siebie, gdy początek pierwszego jest mniejszy lub równy końcowi drugiego, a początek drugiego jest mniejszy lub równy końcowi pierwszego, lub matematycznie, gdy (b1 ≤ e2) AND (b2 ≤ e1).
Następujące zapytanie wyszukało wszystkie przedziały, które nakładają się na przedział (10, 30). Zauważ, że drugi warunek (b2 ≤ e1) jest odwracany do (e1 ≥ b2) dla prostszego odczytu (początek i koniec przedziałów z tabeli znajdują się zawsze po lewej stronie warunku). Podany lub wyszukiwany interwał znajduje się na początku osi czasu dla wszystkich interwałów w tabeli.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Zapytanie wykorzystało 36 logicznych odczytów. Jeśli sprawdzisz plan wykonania, zobaczysz, że zapytanie użyło indeksu seek w indeksie idx_b z predykatem seek [tempdb].[dbo].[Intervals].b <=Operator skalarny((30)) , a następnie skanowanie wiersze i wybierz wynikowe wiersze przy użyciu predykatu rezydualnego [tempdb].[dbo].[Intervals].[e]>=(10). Ponieważ przeszukiwany interwał znajduje się na początku osi czasu, predykat wyszukiwania pomyślnie wyeliminował większość wierszy; tylko kilka przedziałów w tabeli ma punkt początkowy niższy lub równy 30.
Otrzymalibyśmy podobnie wydajne zapytanie, gdyby przeszukiwany interwał znajdował się na końcu osi czasu, po prostu SQL Server użyłby indeksu idx_e do wyszukiwania. Co się jednak stanie, jeśli przeszukiwany interwał znajdzie się pośrodku osi czasu, jak pokazano w poniższym zapytaniu?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Tym razem zapytanie użyło 111 odczytów logicznych. Przy większej tabeli różnica w porównaniu z pierwszym zapytaniem byłaby jeszcze większa. Jeśli sprawdzisz plan wykonania, możesz dowiedzieć się, że SQL Server używał indeksu idx_e z [tempdb].[dbo].[Intervals].e>=Operator skalarny((570)) seek predicate i [tempdb].[ dbo].[Przedziały].[b]<=(590) predykat resztkowy. Predykat wyszukiwania wyklucza około połowy wierszy z jednej strony, podczas gdy połowa wierszy z drugiej strony jest skanowana, a wynikowe wiersze są wyodrębniane z predykatem rezydualnym.
Ulepszone rozwiązanie T-SQL
Istnieje rozwiązanie, które wykorzystywałoby ten indeks do eliminacji wierszy z obu stron przeszukiwanego przedziału za pomocą jednego indeksu. Poniższy rysunek przedstawia tę logikę.
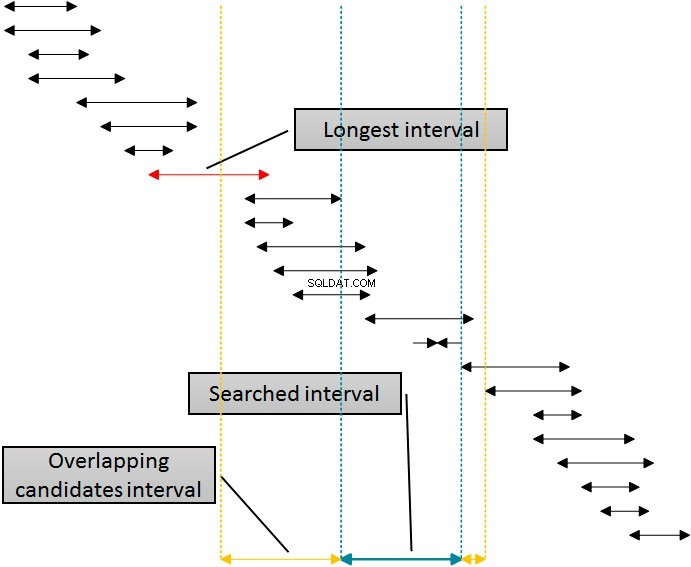
Przedziały na rysunku są posortowane według dolnej granicy, reprezentującej wykorzystanie indeksu idx_b przez SQL Server. Eliminacja przedziałów z prawej strony danego (wyszukiwanego) przedziału jest prosta:wystarczy wyeliminować wszystkie przedziały, których początek jest przynajmniej o jedną jednostkę większy (bardziej w prawo) od końca danego przedziału. Możesz zobaczyć tę granicę na rysunku oznaczonym linią kropkowaną najbardziej po prawej stronie. Eliminacja z lewej strony jest jednak bardziej złożona. Aby użyć tego samego indeksu, indeksu idx_b do eliminacji od lewej, muszę użyć początku interwałów w tabeli w klauzuli WHERE zapytania. Muszę odejść w lewą stronę od początku danego (wyszukiwanego) interwału przynajmniej na długość najdłuższego interwału w tabeli, który jest zaznaczony na rysunku. Interwały, które zaczynają się przed lewą żółtą linią, nie mogą nakładać się na podany (niebieski) interwał.
Ponieważ wiem już, że długość najdłuższego interwału wynosi 20, mogę w dość prosty sposób napisać rozszerzone zapytanie.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
To zapytanie pobiera te same wiersze, co poprzednie, tylko z 20 logicznymi odczytami. Jeśli sprawdzisz plan wykonania, zobaczysz, że użyto idx_b z predykatem seek Seek Keys[1]:Start:[tempdb].[dbo].[Intervals].b>=Operator skalarny((550)) , End:[tempdb].[dbo].[Intervals].b <=Operator skalarny((590)), który pomyślnie wyeliminował wiersze z obu stron osi czasu, a następnie predykat rezydualny [tempdb].[dbo]. [Przedziały].[e]>=(570) AND [tempdb].[dbo].[Przedziały].[e]<=(610) zostały użyte do wybrania wierszy z bardzo ograniczonego skanowania częściowego.
Oczywiście można by odwrócić liczbę, aby objąć przypadki, w których indeks idx_e byłby bardziej przydatny. Z tym indeksem eliminacja z lewej strony jest prosta – wyeliminuj wszystkie interwały, które kończą się przynajmniej jedną jednostkę przed początkiem danego interwału. Tym razem eliminacja z prawej strony jest bardziej złożona – koniec przedziałów w tabeli nie może być bardziej na prawo niż koniec danego przedziału plus maksymalna długość wszystkich przedziałów w tabeli.
Należy pamiętać, że ta wydajność jest konsekwencją konkretnych danych w tabeli. Maksymalna długość interwału to 20. W ten sposób SQL Server może bardzo skutecznie eliminować interwały z obu stron. Jeśli jednak w tabeli byłby tylko jeden długi przedział, kod stałby się znacznie mniej wydajny, ponieważ SQL Server nie byłby w stanie wyeliminować wielu wierszy z jednej strony, ani z lewej, ani z prawej, w zależności od tego, którego indeksu użyje . W każdym razie w rzeczywistości długość interwału nie zmienia się wiele razy, więc ta technika optymalizacji może być bardzo przydatna, zwłaszcza że jest prosta.
Wniosek
Pamiętaj, że jest to tylko jedno z możliwych rozwiązań. Możesz znaleźć rozwiązanie, które jest bardziej złożone, ale zapewnia przewidywalną wydajność bez względu na długość najdłuższego interwału w artykule Interval Queries in SQL Server autorstwa Itzika Ben-Gana (https://sqlmag.com/t-sql/ sql-server-interval-query). Jednak bardzo podoba mi się ulepszony T-SQL rozwiązanie, które przedstawiłem w tym artykule. Rozwiązanie jest bardzo proste; wszystko, co musisz zrobić, to dodać dwa predykaty do klauzuli WHERE w nakładających się zapytaniach. To jednak nie koniec możliwości. Bądź na bieżąco, w następnych dwóch artykułach pokażę Ci więcej rozwiązań, dzięki czemu będziesz mieć bogaty zestaw możliwości w swoim zestawie narzędzi optymalizacyjnych.
Przydatne narzędzie:
dbForge Query Builder dla SQL Server – pozwala użytkownikom szybko i łatwo tworzyć złożone zapytania SQL za pomocą intuicyjnego interfejsu wizualnego bez ręcznego pisania kodu.