[ Część 1 | Część 2 | Część 3 | Część 4 ]
W pierwszej części tej serii zobaczyliśmy, jak problem z Halloween dotyczy UPDATE zapytania. Krótko mówiąc, problem polegał na tym, że indeks używany do lokalizowania rekordów do aktualizacji miał zmodyfikowane klucze przez samą operację aktualizacji (kolejny dobry powód, aby używać zawartych w indeksie kolumn zamiast rozszerzania kluczy). Optymalizator zapytań wprowadził operator Eager Table Spool, aby oddzielić strony odczytu i zapisu planu wykonania, aby uniknąć problemu. W tym poście zobaczymy, jak ten sam podstawowy problem może wpłynąć na INSERT i DELETE oświadczenia.
Wstaw oświadczenia
Teraz wiemy trochę o warunkach, które wymagają ochrony przed Halloween, dość łatwo jest utworzyć INSERT przykład, który obejmuje odczytywanie i zapisywanie kluczy o tej samej strukturze indeksu. Najprostszym przykładem jest duplikowanie wierszy w tabeli (gdzie dodanie nowych wierszy nieuchronnie modyfikuje klucze indeksu klastrowanego):
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
SELECT SomeKey FROM dbo.Demo; Problem polega na tym, że nowo wstawione wiersze mogą zostać napotkane po stronie odczytu planu wykonania, potencjalnie skutkując pętlą, która dodaje wiersze na zawsze (lub przynajmniej do osiągnięcia pewnego limitu zasobów). Optymalizator zapytań rozpoznaje to ryzyko i dodaje Chętny bufor tabeli, aby zapewnić niezbędną separację faz :
Bardziej realistyczny przykład
Prawdopodobnie nie często piszesz zapytania duplikujące każdy wiersz w tabeli, ale prawdopodobnie piszesz zapytania, w których tabela docelowa dla INSERT pojawia się również gdzieś w SELECT klauzula. Jednym z przykładów jest dodawanie wierszy z tabeli pomostowej, które jeszcze nie istnieją w miejscu docelowym:
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
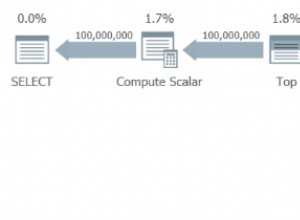
); Plan wykonania to:
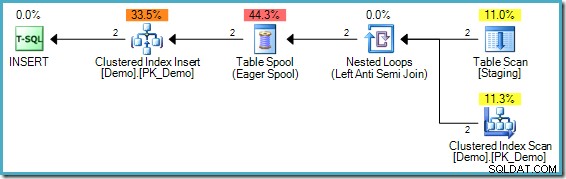
Problem w tym przypadku jest nieco inny, choć wciąż stanowi przykład tego samego problemu podstawowego. W docelowej tabeli Demo nie ma wartości „1234”, ale tabela Staging zawiera dwa takie wpisy. Bez separacji faz pierwsza napotkana wartość „1234” zostałaby wstawiona pomyślnie, ale drugie sprawdzenie wykazałoby, że wartość „1234” już istnieje i nie będzie próbowała wstawić jej ponownie. Całość zakończyłaby się pomyślnie.
Może to przynieść pożądany rezultat w tym konkretnym przypadku (i może nawet wydawać się intuicyjnie poprawne), ale nie jest to poprawna implementacja. Standard SQL wymaga, aby zapytania modyfikujące dane wykonywały się tak, jakby trzy fazy ograniczeń odczytu, zapisu i sprawdzania zachodziły całkowicie oddzielnie (patrz część pierwsza).
Wyszukując wszystkie wiersze do wstawienia jako pojedynczą operację, powinniśmy wybrać oba wiersze „1234” z tabeli Staging, ponieważ ta wartość nie istnieje jeszcze w miejscu docelowym. Dlatego plan wykonania powinien próbować wstawić oba Wiersze „1234” z tabeli Staging, skutkujące naruszeniem klucza podstawowego:
Msg 2627, poziom 14, stan 1, wiersz 1Naruszenie ograniczenia klucza podstawowego „PK_Demo”.
Nie można wstawić zduplikowanego klucza w obiekcie „dbo.Demo”.
Wartość zduplikowanego klucza to ( 1234).
Oświadczenie zostało zakończone.
Separacja faz zapewniana przez bufor tabeli zapewnia, że wszystkie kontrole na istnienie są zakończone przed wprowadzeniem jakichkolwiek zmian w tabeli docelowej. Jeśli uruchomisz zapytanie w SQL Server z przykładowymi danymi powyżej, otrzymasz (poprawny) komunikat o błędzie.
Ochrona Halloween jest wymagana dla instrukcji INSERT, w przypadku których do tabeli docelowej odwołuje się również klauzula SELECT.
Usuń wyciągi
Możemy się spodziewać, że problem z Halloween nie dotyczy DELETE oświadczenia, ponieważ nie powinno mieć większego znaczenia, jeśli próbujemy usunąć wiersz wiele razy. Możemy zmodyfikować nasz przykład tabeli pomostowej, aby usunąć wiersze z tabeli Demo, które nie istnieją w Staging:
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Ten test wydaje się potwierdzać naszą intuicję, ponieważ w planie wykonania nie ma buforu tabeli:
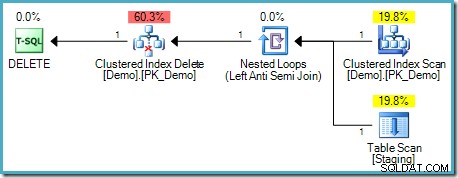
Ten typ DELETE nie wymaga separacji faz, ponieważ każdy wiersz ma unikalny identyfikator (identyfikator RID, jeśli tabela jest stertą, kluczami indeksu klastrowego i ewentualnie unikyfikatorem w przeciwnym razie). Ten unikalny lokalizator wierszy to stabilny klucz – nie ma mechanizmu, dzięki któremu może się to zmienić podczas realizacji tego planu, więc problem Halloween nie powstaje.
USUŃ ochronę Halloween
Niemniej jednak istnieje co najmniej jeden przypadek, w którym DELETE wymaga ochrony Halloween:gdy plan odwołuje się do wiersza w tabeli innego niż ten, który jest usuwany. Wymaga to samodzielnego łączenia, często spotykanego podczas modelowania relacji hierarchicznych. Uproszczony przykład pokazano poniżej:
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Naprawdę powinno być zdefiniowane tutaj odwołanie do klucza obcego w tej samej tabeli, ale zignorujmy na chwilę ten projekt, który zawodzi – struktura i dane są jednak prawidłowe (i niestety często zdarza się, że klucze obce są pomijane w prawdziwym świecie). W każdym razie naszym zadaniem jest usunięcie dowolnego wiersza, w którym ref kolumna wskazuje na nieistniejący pk wartość. Naturalne DELETE zapytanie spełniające to wymaganie to:
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
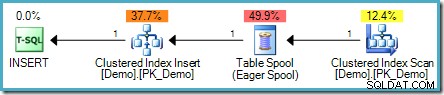
); Plan zapytań to:
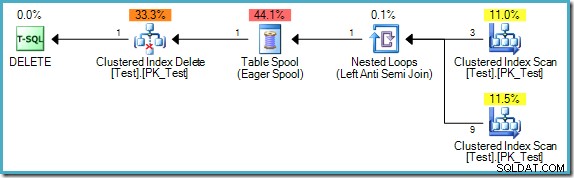
Zauważ, że ten plan zawiera teraz kosztowną szpulę stołu Chętny. W tym przypadku wymagana jest separacja faz, ponieważ w przeciwnym razie wyniki mogą zależeć od kolejności przetwarzania wierszy:
Jeśli silnik wykonawczy zaczyna się od wiersza, w którym pk =B, nie znajdzie pasującego wiersza (ref =A i nie ma wiersza, w którym pk =A). Jeśli wykonanie przechodzi do wiersza, w którym pk =C, zostanie również usunięty, ponieważ właśnie usunęliśmy wiersz B wskazywany przez jego ref kolumna. Efektem końcowym byłoby to, że iteracyjne przetwarzanie w tej kolejności usunęłoby wszystkie wiersze z tabeli, co jest wyraźnie niepoprawne.
Z drugiej strony, jeśli silnik wykonawczy przetworzy wiersz z pk =D najpierw znajdzie pasujący wiersz (ref =C). Zakładając, że wykonanie będzie kontynuowane w odwrotnej kolejności pk kolejności, jedynym wierszem usuniętym z tabeli będzie ten, w którym pk =B. To jest poprawny wynik (pamiętaj, że zapytanie powinno zostać wykonane tak, jakby fazy odczytu, zapisu i walidacji następowały sekwencyjnie i bez nakładania się).
Rozdzielanie faz w celu walidacji ograniczeń
Na marginesie, możemy zobaczyć inny przykład separacji faz, jeśli do poprzedniego przykładu dodamy ograniczenie klucza obcego tej samej tabeli:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); Plan wykonania WSTAWKI to:
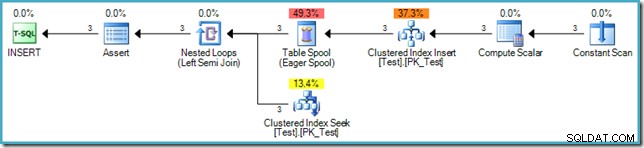
Sama wstawka nie wymaga ochrony Halloween, ponieważ plan nie odczytuje z tej samej tabeli (źródłem danych jest wirtualna tabela w pamięci reprezentowana przez operatora Constant Scan). Standard SQL wymaga jednak, aby faza 3 (sprawdzanie ograniczeń) miała miejsce po zakończeniu fazy pisania. Z tego powodu do planu dodano separację faz Eager Table Spool po Clustered Index Index i tuż przed sprawdzeniem każdego wiersza, aby upewnić się, że ograniczenie klucza obcego pozostaje ważne.
Jeśli zaczynasz myśleć, że przetłumaczenie opartego na zbiorach deklaratywnego zapytania dotyczącego modyfikacji SQL na solidny, iteracyjny plan wykonania fizycznego jest trudną sprawą, zaczynasz rozumieć, dlaczego przetwarzanie aktualizacji (którego ochrona Halloween jest tylko bardzo małą częścią) jest najbardziej złożona część procesora zapytań.
Instrukcje DELETE wymagają ochrony Halloween, gdy występuje samodołączanie tabeli docelowej.
Podsumowanie
Ochrona Halloween może być kosztowną (ale niezbędną) funkcją w planach wykonania, która zmienia dane (gdzie „zmiana” obejmuje całą składnię SQL, która dodaje, zmienia lub usuwa wiersze). Ochrona Halloween jest wymagana do UPDATE plany, w których klucze wspólnej struktury indeksu są zarówno odczytywane, jak i modyfikowane, dla INSERT plany, w których odwołuje się do tabeli docelowej po stronie odczytu planu i dla DELETE plany, w których wykonywane jest samodzielne łączenie w tabeli docelowej.
W następnej części tej serii zostaną omówione niektóre specjalne optymalizacje problemów Halloween, które dotyczą tylko MERGE oświadczenia.
[ Część 1 | Część 2 | Część 3 | Część 4 ]