W tym artykule skupimy się na analizie operacyjnej w czasie rzeczywistym i jak zastosować to podejście do bazy danych OLTP. Kiedy spojrzymy na tradycyjny model analityczny, widzimy, że OLTP i środowiska analityczne to odrębne struktury. Po pierwsze, tradycyjne środowiska modeli analitycznych muszą tworzyć zadania ETL (Extract, Transform and Load). Ponieważ musimy przenieść dane transakcyjne do hurtowni danych. Tego typu architektura ma pewne wady. Są to koszt, złożoność i opóźnienie danych. Aby wyeliminować te wady, potrzebujemy innego podejścia.
Analiza operacyjna w czasie rzeczywistym
Firma Microsoft ogłosiła analizę operacyjną w czasie rzeczywistym w programie SQL Server 2016. Ta funkcja umożliwia łączenie transakcyjnej bazy danych z obciążeniem zapytań analitycznych bez żadnych problemów z wydajnością. Analiza operacyjna w czasie rzeczywistym zapewnia:
- struktura hybrydowa
- zapytania transakcyjne i analityczne mogą być wykonywane w tym samym czasie
- nie powoduje żadnych problemów z wydajnością i opóźnieniami.
- prosta implementacja.
Ta funkcja może przezwyciężyć wady tradycyjnego środowiska analitycznego. Głównym motywem tej funkcji jest to, że indeks magazynu kolumn utrzymuje kopię danych bez wpływu na wydajność systemu transakcyjnego. Ten motyw umożliwia wykonywanie zapytań analitycznych bez wpływu na wydajność. Minimalizuje to wpływ na wydajność. Głównym ograniczeniem tej funkcji jest to, że nie możemy zbierać danych z różnych źródeł danych.
Indeks magazynu kolumn nieklastrowanych
SQL Server 2016 wprowadza aktualizowalny „Indeks magazynu kolumn bez klastrów”. Indeks magazynu kolumn bez klastrów jest indeksem opartym na kolumnach, który zapewnia korzyści w zakresie wydajności zapytań analitycznych. Ta funkcja pozwala nam tworzyć ramy analizy operacyjnej w czasie rzeczywistym. Oznacza to, że możemy jednocześnie realizować transakcje i zapytania analityczne. Weź pod uwagę, że potrzebujemy miesięcznej całkowitej sprzedaży. W tradycyjnym modelu musimy rozwijać zadania ETL, data mart i hurtownię danych. Ale w analizie operacyjnej w czasie rzeczywistym możemy to zrobić bez konieczności hurtowni danych lub jakichkolwiek zmian w strukturze OLTP. Musimy tylko utworzyć odpowiedni nieklastrowany indeks magazynu kolumn.
Architektura nieklastrowanego indeksu magazynu kolumn
Przyjrzyjmy się pokrótce architekturze nieklastrowanego indeksu magazynu kolumn i mechanizmu uruchamiania. Indeks magazynu kolumn nieklastrowanych zawiera kopię części lub wszystkich wierszy i kolumn w tabeli źródłowej. Głównym tematem nieklastrowanego indeksu magazynu kolumn jest zachowanie kopii danych i używanie tej kopii danych. Tak więc ten mechanizm minimalizuje wpływ na wydajność transakcyjnej bazy danych. Nieklastrowany indeks magazynu kolumn może utworzyć jedną lub więcej niż jedną kolumnę i zastosować filtr do kolumn.
Kiedy wstawiamy nowy wiersz do tabeli, która ma nieklastrowany indeks magazynu kolumn, po pierwsze, SQL Server tworzy „grupę wierszy”. Rowgroup to logiczna struktura, która reprezentuje zestaw wierszy. Następnie SQL Server przechowuje te wiersze w magazynie tymczasowym. Nazwa tego tymczasowego magazynu to „deltastore”. SQL Server używa tego tymczasowego obszaru przechowywania, ponieważ ten mechanizm poprawia współczynnik kompresji i zmniejsza fragmentację indeksu. Gdy liczba wierszy osiągnie 1 048 577, SQL Server zamyka stan grupy wierszy. SQL Server kompresuje tę grupę wierszy i zmienia stan na „skompresowany”.
Teraz utworzymy tabelę i dodamy nieklastrowany indeks magazynu kolumn.
DROP TABLE IF EXISTS Test_tabeli_analizyCREATE TABLE Test_tabeli_analizy(ID INT PRIMARY KEY IDENTITY(1,1),Nazwa_kontynentu VARCHAR(20),Nazwa_kraju VARCHAR(20),Nazwa_miasta VARCHAR(20),Sprzedaż INT,Profit_Amnt INT)GO
UTWÓRZ INDEKS KOLUMNÓW BEZKLATOWYCH [NonClusteredColumnStoreIndex] ON [dbo]. [Test tabeli_analizy]( [Nazwa_kraju], [Nazwa_miasta] , Kwota_sprzedaży) Z (DROP_EXISTING =OFF, COMPRESSION_DELAY =0) NA [PRIMARY]W tym kroku wstawimy kilka wierszy i przyjrzymy się właściwościom nieklastrowanego indeksu magazynu kolumn.
INSERT INTO Analysis_TableTest VALUES('Europa','Niemcy','Monachium','100','12')INSERT INTO Analysis_TableTest VALUES('Europa','Turcja','Stambuł','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europa','Francja','Paryż','190','23')INSERT INTO Analysis_TableTest VALUES('Ameryka','USA','Nowy Jork','180',' 19') INSERT INTO Analysis_TableTest VALUES('Azja','Japonia','Tokio','190','17')GOTo zapytanie wyświetli stany grup wierszy, całkowitą liczbę wierszy i inne wartości.
SELECT i.object_id, object_name(i.object_id) AS TableName, i.name AS IndexName, i.index_id, i.type_desc, CSRowGroups.*, 100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull FROM sys.indexes AS i DOŁĄCZ DO sys.column_store_row_groups AS CSRowGroups ON i.object_id =CSRowGroups.object_id AND i.index_id =CSRowGroups.index_id ORDER BY object_name(i.object_id), i.name, row_group_id;
Powyższy obrazek pokazuje nam stan deltastore i całkowitą liczbę wierszy, które nie są skompresowane. Teraz wypełnimy tabelę większą ilością danych, a gdy liczba wierszy osiągnie 1 048 577, SQL Server zamknie pierwszą grupę wierszy i otworzy nową grupę wierszy.
INSERT INTO Analysis_TableTest VALUES('Europa','Niemcy','Monachium','100','12')INSERT INTO Analysis_TableTest VALUES('Europa','Turcja','Stambuł','200',' 24')INSERT INTO Analysis_TableTest VALUES('Europa','Francja','Paryż','190','23')INSERT INTO Analysis_TableTest VALUES('Ameryka','USA','Nowy Jork','180',' 19') INSERT INTO Analysis_TableTest VALUES('Azja','Japonia','Tokio','190','17')GO 2000000
SQL Server skompresuje tę grupę wierszy i utworzy nową grupę wierszy. Opcja „COMPRESSION_DELAY” pozwala nam kontrolować, jak długo grupa wierszy czeka w stanie zamkniętym.
Kiedy uruchamiamy polecenia utrzymania indeksu (reorganizuj, odbuduj) usunięte wiersze są fizycznie usuwane, a indeks jest defragmentowany.
Kiedy aktualizujemy (usuwamy + wstawiamy) niektóre wiersze w tej tabeli, usunięte wiersze są oznaczane jako „usunięte”, a nowe zaktualizowane wiersze są wstawiane do deltastore.
Analityczny test wydajności zapytań
W tym nagłówku wypełnimy dane w tabeli Analysis_TableTest. Wstawiłem 4 miliony rekordów. (Musisz przetestować ten krok i następne kroki w swoim środowisku testowym. Mogą wystąpić problemy z wydajnością, a także polecenie DBCC DROPCLEANBUFFERS może obniżyć wydajność. To polecenie usunie wszystkie dane bufora z puli buforów.)
Teraz uruchomimy następujące zapytanie analityczne i zbadamy wartości wydajności.
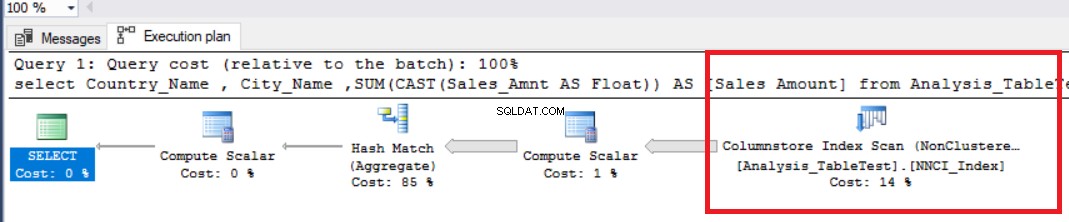
USTAW STATYSTYKI CZASU POCZĄTKU STATYSTYKI IO ONDBCC DROPCLEANBUFFERSselect Nazwa_kraju , Nazwa_miasta ,SUM(CAST(Sprzedaż_Amnt AS Float)) AS [Kwota sprzedaży] z grupy Analiza_Test tabeli według Nazwa_kraju , Nazwa_miasta
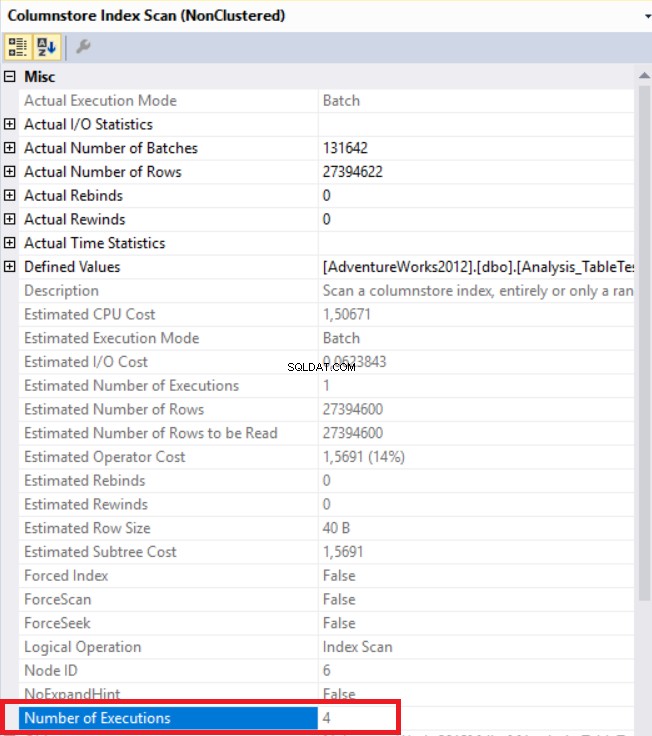
Na powyższym obrazku widzimy nieklastrowany operator skanowania indeksu magazynu kolumn. Poniższa tabela przedstawia czasy procesora i wykonania. Ta kwerenda zużywa 1,765 milisekundy procesora i ukończona w 0,791 milisekundy. Czas procesora jest dłuższy niż czas, który upłynął, ponieważ plan wykonania używa procesorów równoległych i rozdziela zadania na 4 procesory. Możemy to zobaczyć we właściwościach operatora „Columnstore Index Scan”. Wskazuje na to wartość „Liczba egzekucji”.
Teraz dodamy podpowiedź do zapytania, aby zmniejszyć liczbę procesorów. Nie zobaczymy żadnego operatora równoległości.
SET STATISTICS TIME ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSselect Nazwa_kraju , Nazwa_miasta ,SUM(CAST(Sprzedaż_Amnt AS Float)) AS [Kwota sprzedaży] z grupy Analiza_Test tabeli według Nazwa_kraju , Nazwa_miastaOPCJA (MAXDOP 1)
Poniższa tabela określa czasy realizacji. Na tym wykresie widzimy, że upływający czas jest większy niż czas procesora, ponieważ SQL Server używał tylko jednego procesora.
Teraz wyłączymy nieklastrowany indeks magazynu kolumn i wykonamy to samo zapytanie.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLEGOSET STATISTICS TIME ONSET STATISTICS IO ONDBCC DROPCLEANBUFFERSselect Nazwa_kraju , Nazwa_miasta ,SUM(CAST(Sprzedaż_Amnt AS Float)) AS [Nazwa_Kwoty_SprzedażyOP Nazwa_grupy_Analiza_T 1)
Powyższa tabela pokazuje nam, że nieklastrowany indeks magazynu kolumn zapewnia niesamowitą wydajność w zapytaniach analitycznych. W przybliżeniu zaindeksowane zapytanie magazynu kolumn jest pięć razy lepsze od drugiego.
Wniosek
Analityka operacyjna w czasie rzeczywistym zapewnia niesamowitą elastyczność, ponieważ możemy wykonywać zapytania analityczne w systemach OLTP bez żadnych opóźnień danych. Jednocześnie te zapytania analityczne nie wpływają na wydajność bazy danych OLTP. Ta funkcja daje nam możliwość zarządzania danymi transakcyjnymi i zapytaniami analitycznymi w tym samym środowisku.
Referencje
Indeksy magazynu kolumn — wskazówki dotyczące ładowania danych
Zacznij korzystać ze sklepu kolumnowego, aby uzyskać analizy operacyjne w czasie rzeczywistym
Analiza operacyjna w czasie rzeczywistym
Dalsze czytanie:
Skanowanie wstecz indeksu SQL Server:zrozumienie, dostrajanie
Korzystanie z indeksów w tabelach SQL Server zoptymalizowanych pod kątem pamięci