Replikacja typu master-slave MySQL jest dość łatwa i prosta w konfiguracji. Jest to główny powód, dla którego ludzie wybierają tę technologię jako pierwszy krok do osiągnięcia lepszej dostępności bazy danych. Jednak odbywa się to kosztem złożoności zarządzania i utrzymania; do administratora należy utrzymanie integralności danych, zwłaszcza podczas przełączania awaryjnego, powrotu po awarii, konserwacji, aktualizacji i tak dalej.
Istnieje wiele artykułów opisujących, jak wykonać operację przełączania awaryjnego dla konfiguracji replikacji. Omówiliśmy ten temat również w tym poście na blogu Wprowadzenie do przełączania awaryjnego dla replikacji MySQL — blog 101. W tym poście na blogu omówimy zadania po katastrofie podczas przywracania oryginalnej topologii - wykonywanie operacji powrotu po awarii.
Dlaczego potrzebujemy powrotu po awarii?
Lider replikacji (główny) to najbardziej krytyczny węzeł w konfiguracji replikacji. Wymaga dobrych specyfikacji sprzętowych, aby zapewnić stabilne przetwarzanie zapisów, generowanie zdarzeń replikacji, przetwarzanie krytycznych odczytów i tak dalej. Gdy podczas odzyskiwania po awarii lub konserwacji wymagane jest przełączanie awaryjne, często zdarza się, że promujemy nowego lidera z gorszym sprzętem. Ta sytuacja może chwilowo być w porządku, jednak na dłuższą metę wyznaczony master musi zostać przywrócony, aby poprowadzić replikację, gdy zostanie uznana za zdrową.
W przeciwieństwie do przełączania awaryjnego, powrót po awarii zwykle odbywa się w kontrolowanym środowisku poprzez przełączanie, rzadko zdarza się w trybie paniki. Daje to zespołowi operacyjnemu trochę czasu na dokładne zaplanowanie i przećwiczenie ćwiczenia w celu płynnego przejścia. Głównym celem jest po prostu przywrócenie starego dobrego wzorca do najnowszego stanu i przywrócenie konfiguracji replikacji do pierwotnej topologii. Istnieją jednak przypadki, w których powrót po awarii jest krytyczny, na przykład gdy nowo promowany master nie działał zgodnie z oczekiwaniami i wpływał na ogólną usługę bazy danych.
Jak bezpiecznie wykonać powrót po awarii?
Po przejściu awaryjnym stary system główny byłby poza łańcuchem replikacji w celu konserwacji lub odzyskiwania. Aby dokonać przełączenia, należy wykonać następujące czynności:
- Dostarcz starego urządzenia głównego do prawidłowego stanu, czyniąc go najbardziej aktualnym urządzeniem podrzędnym.
- Zatrzymaj aplikację.
- Sprawdź, czy wszyscy niewolnicy zostali złapani.
- Promuj starego mistrza jako nowego lidera.
- Przekieruj wszystkich niewolników na nowego mistrza.
- Uruchom aplikację, pisząc do nowego mastera.
Rozważ następującą konfigurację replikacji:
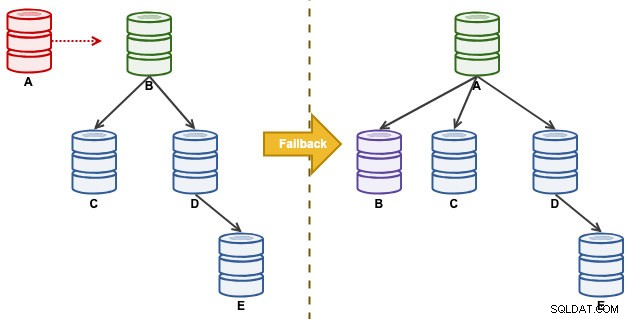
„A” był wzorcem do momentu zapełnienia dysku, który spowodował spustoszenie w łańcuchu replikacji. Po zdarzeniu przełączania awaryjnego nasza topologia replikacji była prowadzona przez B i replikowała się do C do E. Ćwiczenie powrotu po awarii przywróci A jako lidera i przywróci oryginalną topologię sprzed awarii. Zwróć uwagę, że wszystkie węzły działają na MySQL 8.0.15 z włączonym GTID. Różne główne wersje mogą używać różnych poleceń i kroków.
Chociaż tak teraz wygląda nasza architektura po przełączeniu awaryjnym (zaczerpniętym z widoku topologii ClusterControl):
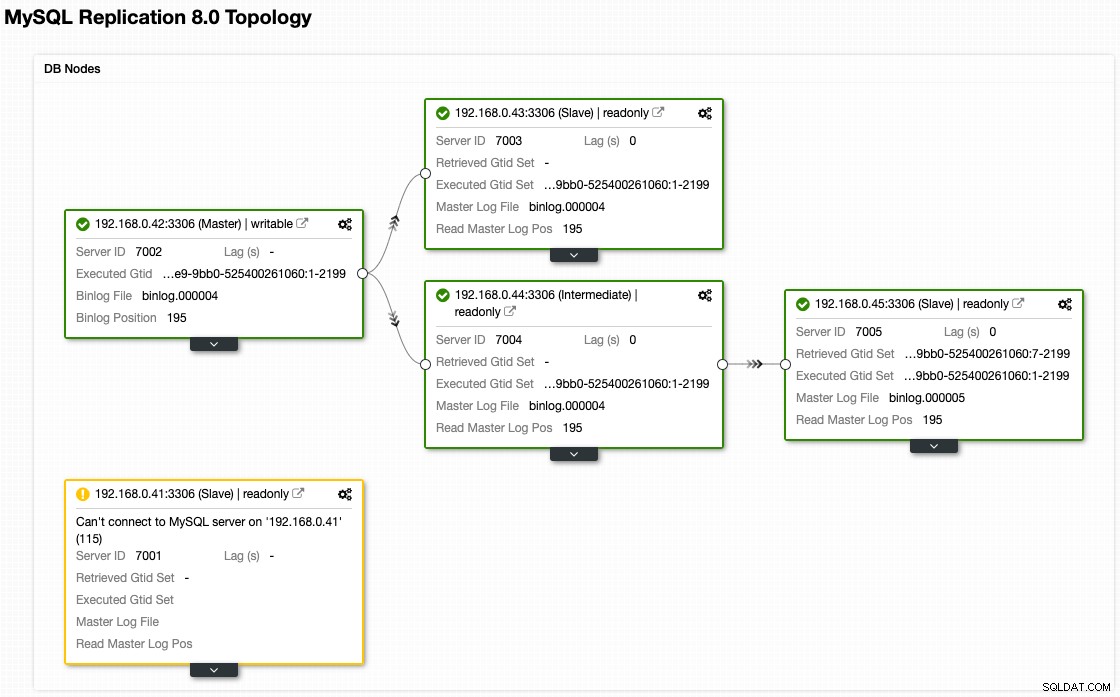
Obsługa obsługi węzła
Zanim A może być wzorcem, musi zostać zaktualizowany o aktualny stan bazy danych. Najlepszym sposobem, aby to zrobić, jest przekształcenie A jako urządzenia podrzędnego na aktywnego urządzenia nadrzędnego, B. Ponieważ wszystkie węzły są skonfigurowane z log_slave_updates=ON (oznacza to, że urządzenie podrzędne produkuje również logi binarne), możemy w rzeczywistości wybrać inne urządzenia podrzędne, takie jak C i D jako źródło prawdy dla wstępnej synchronizacji. Jednak im bliżej aktywnego mistrza, tym lepiej. Należy pamiętać o dodatkowym obciążeniu, jakie może to spowodować podczas tworzenia kopii zapasowej. Ta część zajmuje większość godzin powrotu po awarii. W zależności od stanu węzła i rozmiaru zestawu danych synchronizacja starego mastera może zająć trochę czasu (może to zająć godziny i dni).
Gdy problem na „A” zostanie rozwiązany i gotowy do przyłączenia się do łańcucha replikacji, najlepszym pierwszym krokiem jest próba replikacji z „B” (192.168.0.42) za pomocą instrukcji CHANGE MASTER:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Jeśli replikacja działa, w stanie replikacji powinien pojawić się następujący komunikat:
Slave_IO_Running: Yes
Slave_SQL_Running: YesJeśli replikacja nie powiedzie się, spójrz na Last_IO_Error lub Last_SQL_Error z danych wyjściowych statusu urządzenia podrzędnego. Na przykład, jeśli zobaczysz następujący błąd:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Następnie musimy utworzyć użytkownika replikacji na bieżącym aktywnym masterze, B:
mysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Następnie uruchom ponownie urządzenie podrzędne na A, aby ponownie rozpocząć replikację:
mysql> STOP SLAVE;
mysql> START SLAVE;Innym częstym błędem, który można zobaczyć, jest ten wiersz:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...To prawdopodobnie oznacza, że urządzenie podrzędne ma problem z odczytaniem binarnego pliku dziennika z bieżącego urządzenia nadrzędnego. W niektórych przypadkach urządzenie podrzędne może być daleko w tyle, przez co w bieżącym systemie głównym brakuje wymaganych zdarzeń binarnych do rozpoczęcia replikacji lub pliki binarne na urządzeniu głównym zostały wyczyszczone podczas przełączania awaryjnego i tak dalej. W takim przypadku najlepszym sposobem jest wykonanie pełnej synchronizacji poprzez wykonanie pełnej kopii zapasowej na B i przywrócenie jej na A. Na B możesz użyć mysqldump lub Percona Xtrabackup, aby wykonać pełną kopię zapasową:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupPrzenieś plik kopii zapasowej do A, ponownie zainicjuj istniejącą instalację MySQL w celu prawidłowego oczyszczenia i przywróć bazę danych:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordPo przywróceniu skonfiguruj łącze replikacji do aktywnego systemu głównego B (192.168.0.42) i włącz tryb tylko do odczytu. W A, uruchom następujące instrukcje:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */W przypadku Percona Xtrabackup zapoznaj się ze stroną dokumentacji dotyczącą przywracania do A. Wymaga to wstępnego przygotowania kopii zapasowej przed zastąpieniem katalogu danych MySQL.
Gdy A zacznie poprawnie replikować, monitoruj Seconds_Behind_Master w statusie urządzenia podrzędnego. To da ci wyobrażenie o tym, jak daleko niewolnik zostawił i jak długo musisz czekać, zanim dogoni. W tym momencie nasza architektura wygląda tak:
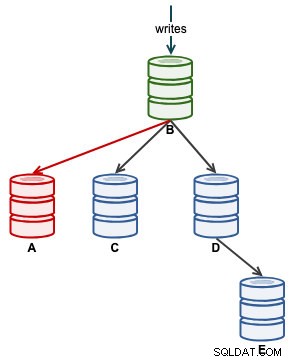
Gdy Seconds_Behind_Master spadnie z powrotem do 0, jest to moment, w którym A dogonił jako aktualne urządzenie podrzędne.
Jeśli używasz ClusterControl, możesz ponownie zsynchronizować węzeł, przywracając go z istniejącej kopii zapasowej lub utworzyć i przesłać strumieniowo kopię zapasową bezpośrednio z aktywnego węzła głównego:
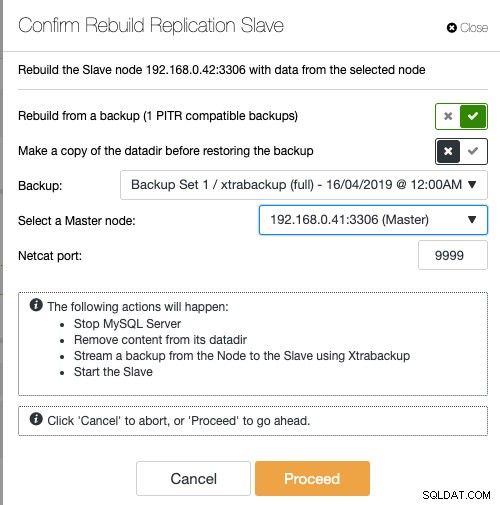
Zalecanym sposobem zbudowania urządzenia podrzędnego jest ustawienie slave'a z istniejącą kopią zapasową, ponieważ nie ma to żadnego wpływu na aktywny serwer master podczas przygotowywania węzła.
Promuj starego mistrza
Przed promowaniem A jako nowego mastera najbezpieczniejszym sposobem jest zatrzymanie wszystkich operacji zapisu na B. Jeśli nie jest to możliwe, po prostu zmuś B do działania w trybie tylko do odczytu:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Następnie w A uruchom SHOW SLAVE STATUS i sprawdź następujący stan replikacji:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesWartość Read_Master_Log_Pos i Exec_Master_Log_Pos musi być identyczna, podczas gdy Seconds_Behind_Master wynosi 0, a stan musi być 'Slave przeczytał cały dziennik przekaźników'. Upewnij się, że wszystkie urządzenia podrzędne przetworzyły jakiekolwiek polecenia w swoim dzienniku przekaźnikowym, w przeciwnym razie ryzykujesz, że nowe zapytania wpłyną na transakcje z dziennika przekaźnikowego, wywołując różnego rodzaju problemy (na przykład aplikacja może usunąć niektóre wiersze, do których mają dostęp transakcje z dziennika przekaźników).
W dniu A zatrzymaj replikację i użyj instrukcji RESET SLAVE ALL, aby usunąć całą konfigurację związaną z replikacją i wyłączyć tylko do odczytu:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';W tym momencie A jest gotowy do przyjmowania zapisów (tylko do odczytu=OFF), jednak urządzenia podrzędne nie są do niego podłączone, jak pokazano poniżej:
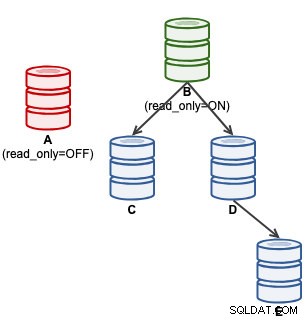
W przypadku użytkowników ClusterControl, promowanie A można wykonać za pomocą funkcji „Promuj urządzenie podrzędne” w obszarze Akcje węzła. ClusterControl automatycznie degraduje aktywnego mastera B, promuje slave A jako master i przekierowuje C i D do replikacji z A. B zostanie odłożony na bok, a użytkownik musi jawnie wybrać „Zmień wzorzec replikacji”, aby ponownie dołączyć do replikacji B z A na późniejszym etapie .
Repointing Slave
Teraz można bezpiecznie zmienić master na powiązanych slave'ach na replikację z A (192.168.0.41). Na wszystkich urządzeniach podrzędnych z wyjątkiem E, skonfiguruj następujące ustawienia:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Jeśli jesteś użytkownikiem ClusterControl, możesz pominąć ten krok, ponieważ ponowne wskazywanie jest wykonywane automatycznie, gdy wcześniej zdecydowałeś się promować A.
Następnie możemy uruchomić naszą aplikację, aby pisać w A. W tym momencie nasza architektura wygląda mniej więcej tak:
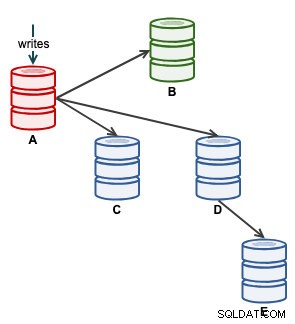
Z widoku topologii ClusterControl przywróciliśmy nasz klaster replikacji do jego oryginalnej architektury, która wygląda tak:
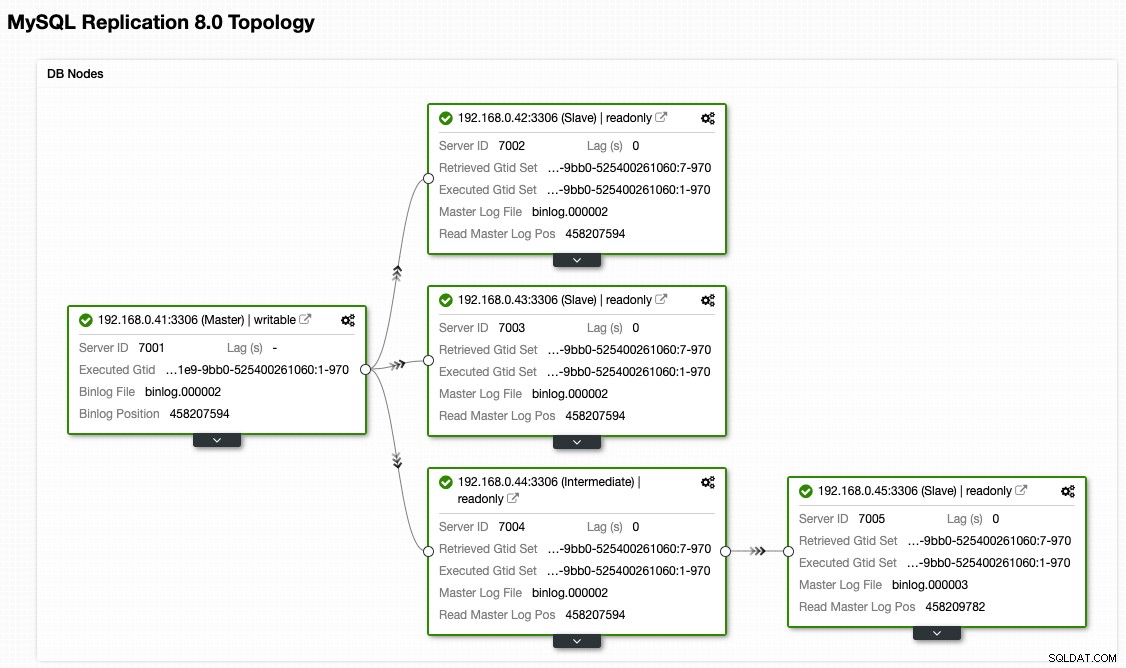
Zwróć uwagę, że ćwiczenie powrotu po awarii jest znacznie mniej ryzykowne w porównaniu z przełączaniem po awarii. Ważne jest, aby zaplanować to ćwiczenie poza godzinami szczytu, aby zminimalizować wpływ na Twoją firmę.
Ostateczne myśli
Operacje przełączania awaryjnego i powrotu po awarii muszą być wykonywane ostrożnie. Operacja jest dość prosta, jeśli masz niewielką liczbę węzłów, ale w przypadku wielu węzłów ze złożonym łańcuchem replikacji może to być ćwiczenie ryzykowne i podatne na błędy. Pokazaliśmy również, jak ClusterControl może być używany do uproszczenia złożonych operacji, wykonując je za pomocą interfejsu użytkownika, a widok topologii jest wizualizowany w czasie rzeczywistym, dzięki czemu masz wiedzę na temat topologii replikacji, którą chcesz zbudować.