Wprowadzenie
Programistom często mówi się, aby używali procedur składowanych w celu uniknięcia tak zwanych zapytań ad hoc co może spowodować niepotrzebne rozdęcie pamięci podręcznej planu. Widzisz, kiedy powtarzający się kod SQL jest pisany niespójnie lub gdy istnieje kod, który generuje dynamiczny SQL w locie, SQL Server ma tendencję do tworzenia planu wykonania dla każdego indywidualnego wykonania. Może to obniżyć ogólną wydajność o:
Żądanie fazy kompilacji dla każdego wykonania kodu.
Nadmiarowanie pamięci podręcznej planów zbyt dużą liczbą uchwytów planów, których nie można użyć ponownie.
Optymalizuj pod kątem obciążeń ad hoc
Jednym ze sposobów rozwiązywania tego problemu w przeszłości jest optymalizacja instancji pod kątem obciążeń ad hoc. Może to być pomocne tylko wtedy, gdy większość baz danych lub najważniejsze bazy danych w instancji głównie wykonuje ad hoc SQL.
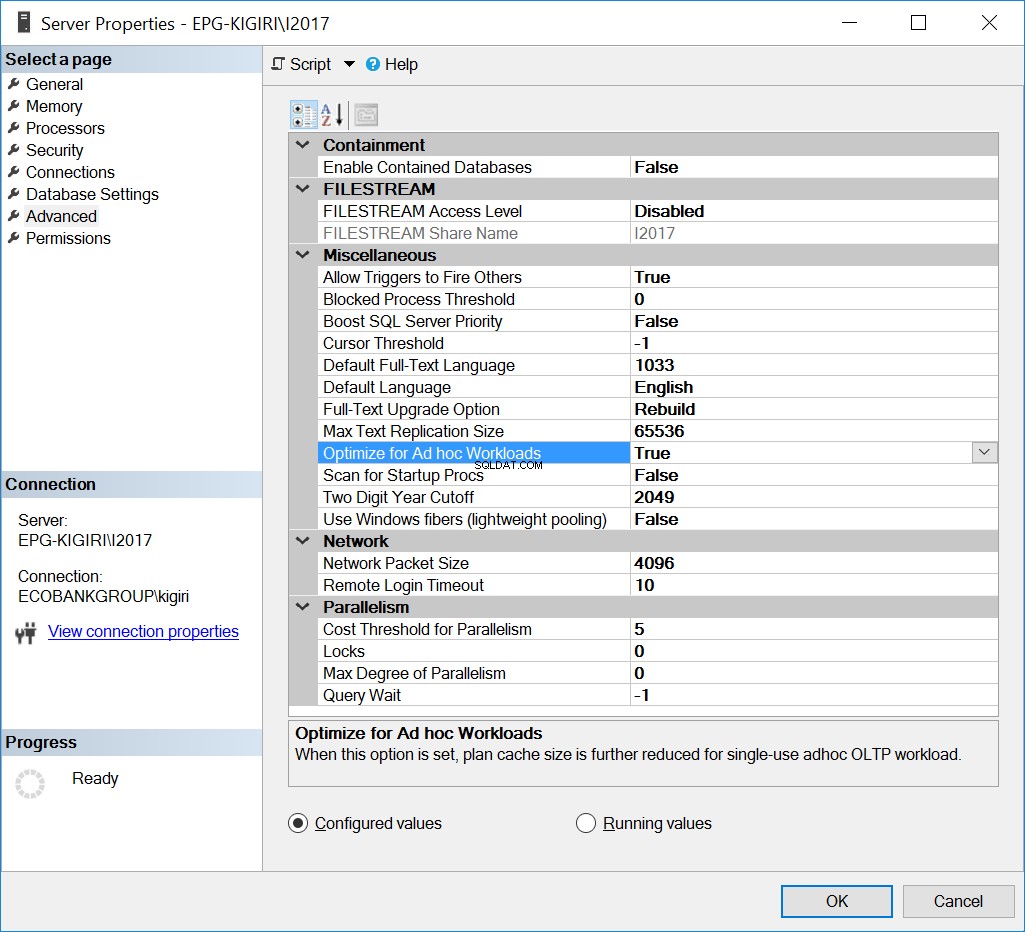
Rys. 1 Optymalizacja pod kątem obciążeń ad hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
Zasadniczo ta opcja nakazuje SQL Serverowi zapisanie częściowej wersji planu, znanej jako skompilowany odcinek planu. Odgałęzienie zajmuje znacznie mniej miejsca niż cały plan.
Jako alternatywę dla tej metody, niektórzy ludzie podchodzą do problemu dość brutalnie i od czasu do czasu opróżniają pamięć podręczną planu. Lub, w bardziej ostrożny sposób, opróżnij „plany jednorazowego użytku” za pomocą DBCC FREESYSTEMCACHE. Opróżnianie całej pamięci podręcznej planów ma swoje wady, jak być może już wiesz.
Korzystanie z zapisanych procedur i parametrów
Korzystając z procedur składowanych, można praktycznie wyeliminować problem powodowany przez ad hoc SQL. Procedura składowana jest kompilowana tylko raz, a ten sam plan jest ponownie wykorzystywany do kolejnych wykonań tych samych lub podobnych zapytań SQL. Gdy procedury składowane są używane do implementacji logiki biznesowej, kluczowa różnica w zapytaniach SQL, które zostaną ostatecznie wykonane przez SQL Server, polega na parametrach przekazywanych w czasie wykonywania. Ponieważ plan już istnieje i jest gotowy do użycia, SQL Server użyje tego samego planu bez względu na przekazany parametr.
Przekrzywione dane
W niektórych scenariuszach dane, z którymi mamy do czynienia, nie są rozłożone równomiernie. Możemy to zademonstrować – najpierw będziemy musieli stworzyć tabelę:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Nasza tabela zawiera dane członków klubu z różnych krajów. Duża liczba członków klubu pochodzi z Ghany, podczas gdy dwa inne narody mają odpowiednio dziesięciu i dwóch członków. Aby skupić się na agendzie i dla uproszczenia, użyłem tylko trzech krajów i tej samej nazwy dla członków pochodzących z tego samego kraju. Ponadto dodałem indeks klastrowy w kolumnie ID i indeks nieklastrowy w kolumnie CountryCode, aby zademonstrować wpływ różnych planów wykonania dla różnych wartości.
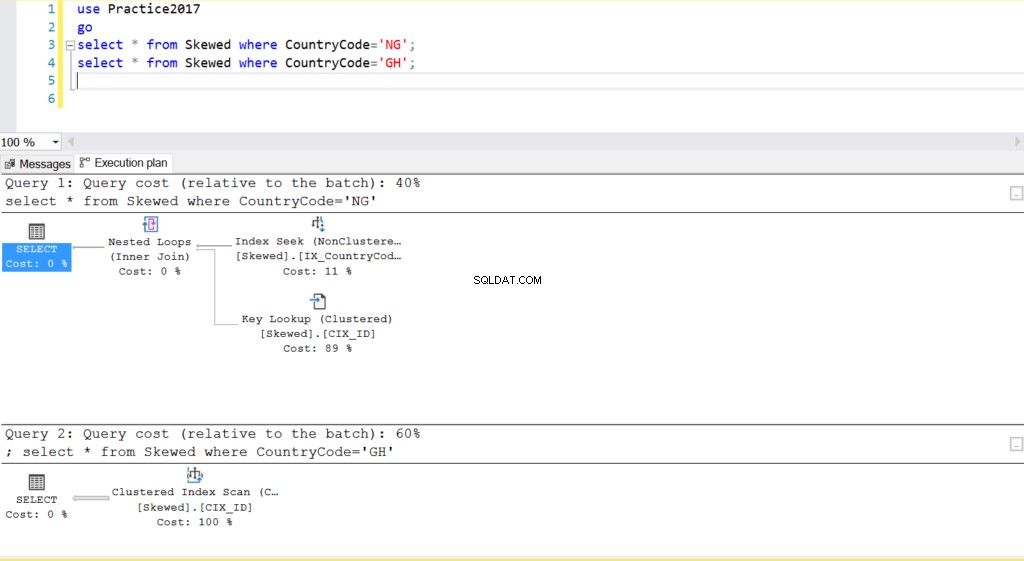
Rys. 2 plany wykonania dla dwóch zapytań
Kiedy wysyłamy zapytanie do tabeli o rekordy, w których CountryCode to NG i GH, okazuje się, że SQL Server używa w tych przypadkach dwóch różnych planów wykonania. Dzieje się tak, ponieważ oczekiwana liczba wierszy dla CountryCode=’NG’ to 10, podczas gdy dla CountryCode=’GH’ to 10000. SQL Server określa preferowany plan wykonania na podstawie statystyk tabeli. Jeśli oczekiwana liczba wierszy jest duża w porównaniu z łączną liczbą wierszy w tabeli, SQL Server zdecyduje, że lepiej jest po prostu wykonać pełne skanowanie tabeli, zamiast odwoływać się do indeksu. Przy znacznie mniejszej szacowanej liczbie wierszy indeks staje się przydatny.
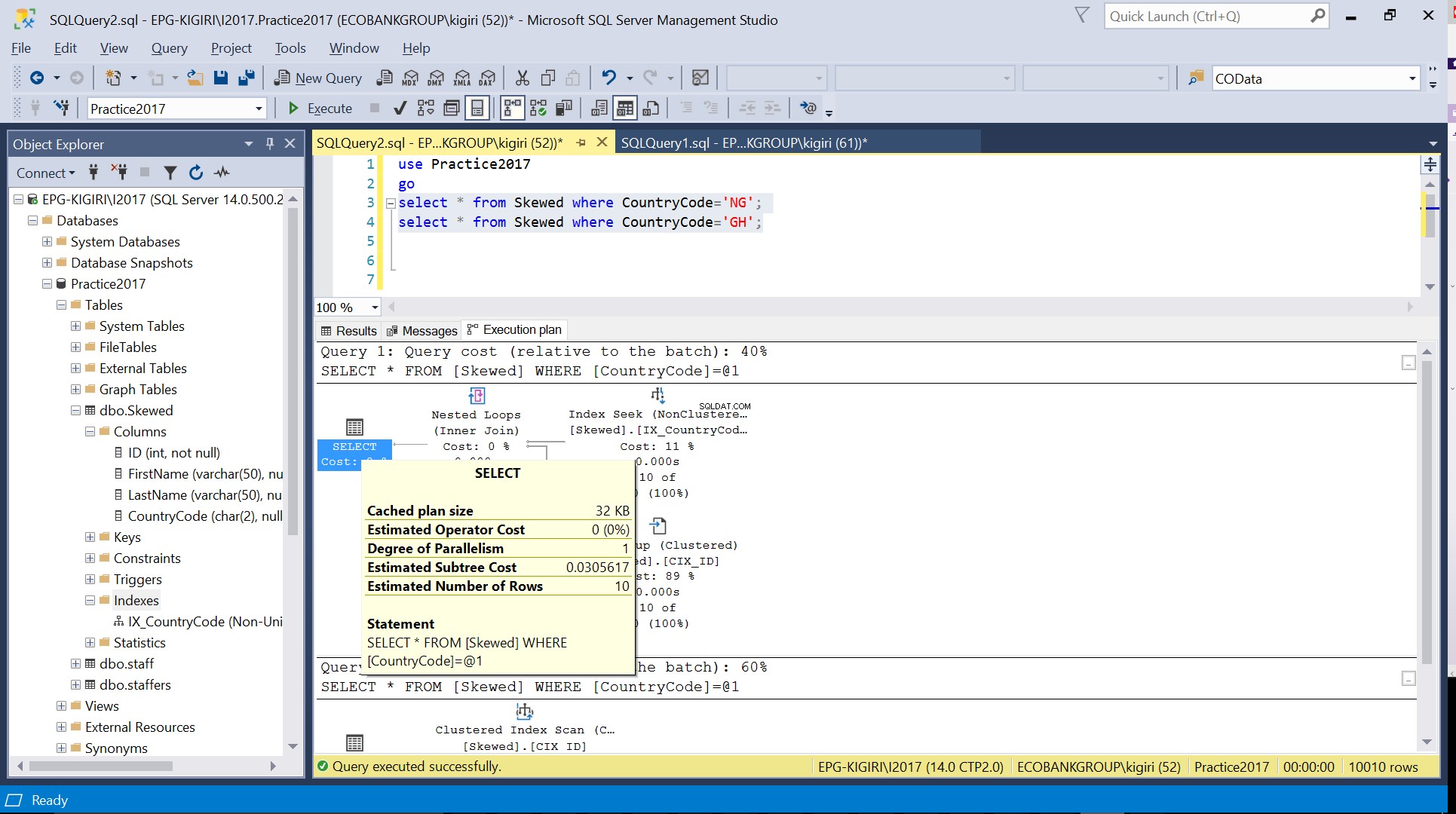
Rys. 3 Szacowana liczba wierszy dla CountryCode='NG'
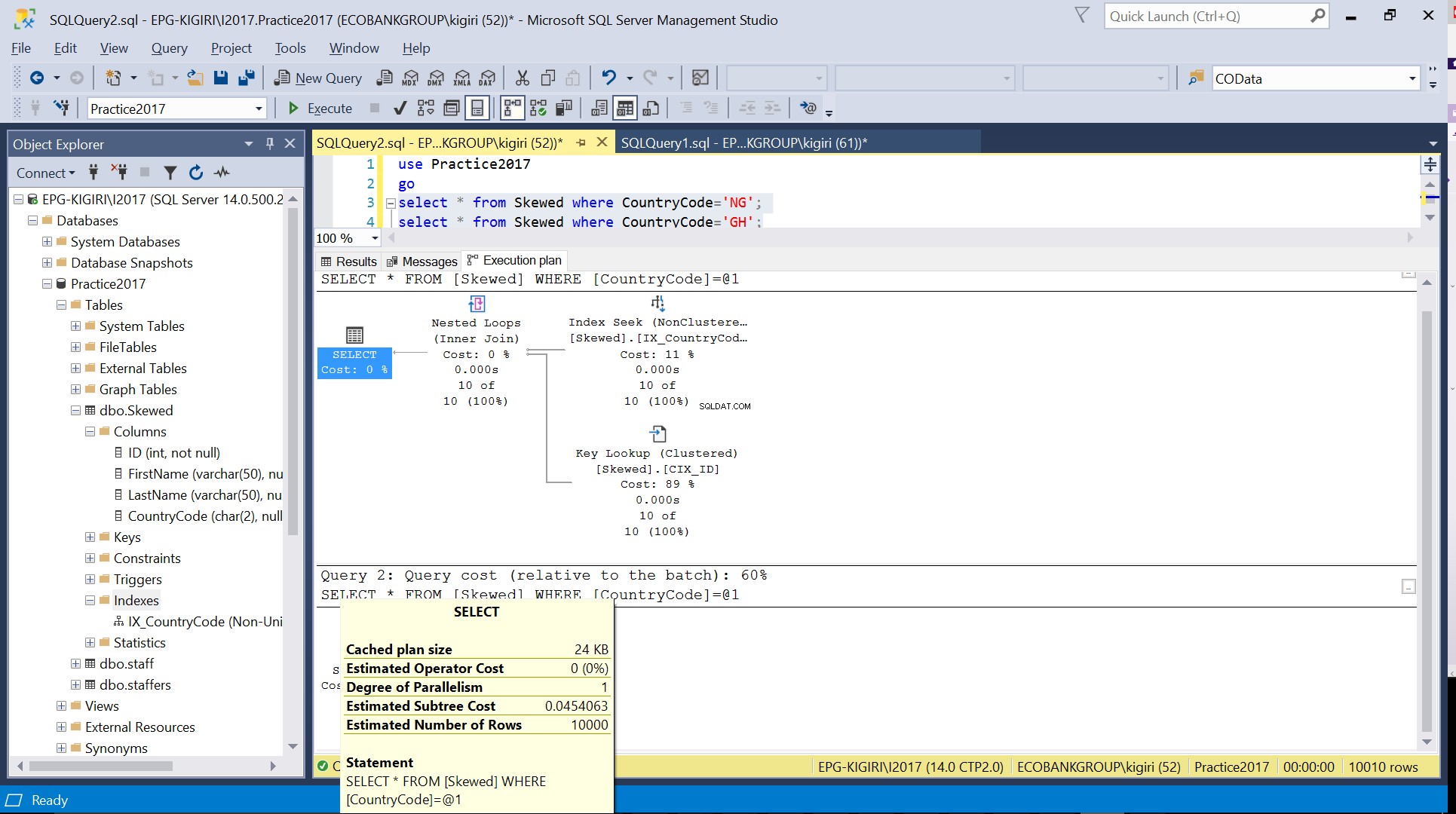
Rys. 4 Szacowana liczba wierszy dla CountryCode=’GH’
Wprowadź procedury składowane
Możemy utworzyć procedurę składowaną do pobierania żądanych rekordów przy użyciu tego samego zapytania. Tym razem jedyną różnicą jest to, że jako parametr przekazujemy CountryCode (patrz Listing 3). Robiąc to, odkrywamy, że plan wykonania jest taki sam bez względu na to, jaki parametr przekażemy. Plan wykonania, który będzie używany, jest określany przez plan wykonania zwrócony przy pierwszym wywołaniu procedury składowanej. Na przykład, jeśli najpierw uruchomimy procedurę z CountryCode='GH', od tego momentu użyje ona pełnego skanowania tabeli. Jeśli następnie wyczyścimy pamięć podręczną procedur i najpierw uruchomimy procedurę z CountryCode='NG', w przyszłości będzie ona korzystać ze skanowania opartego na indeksie.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
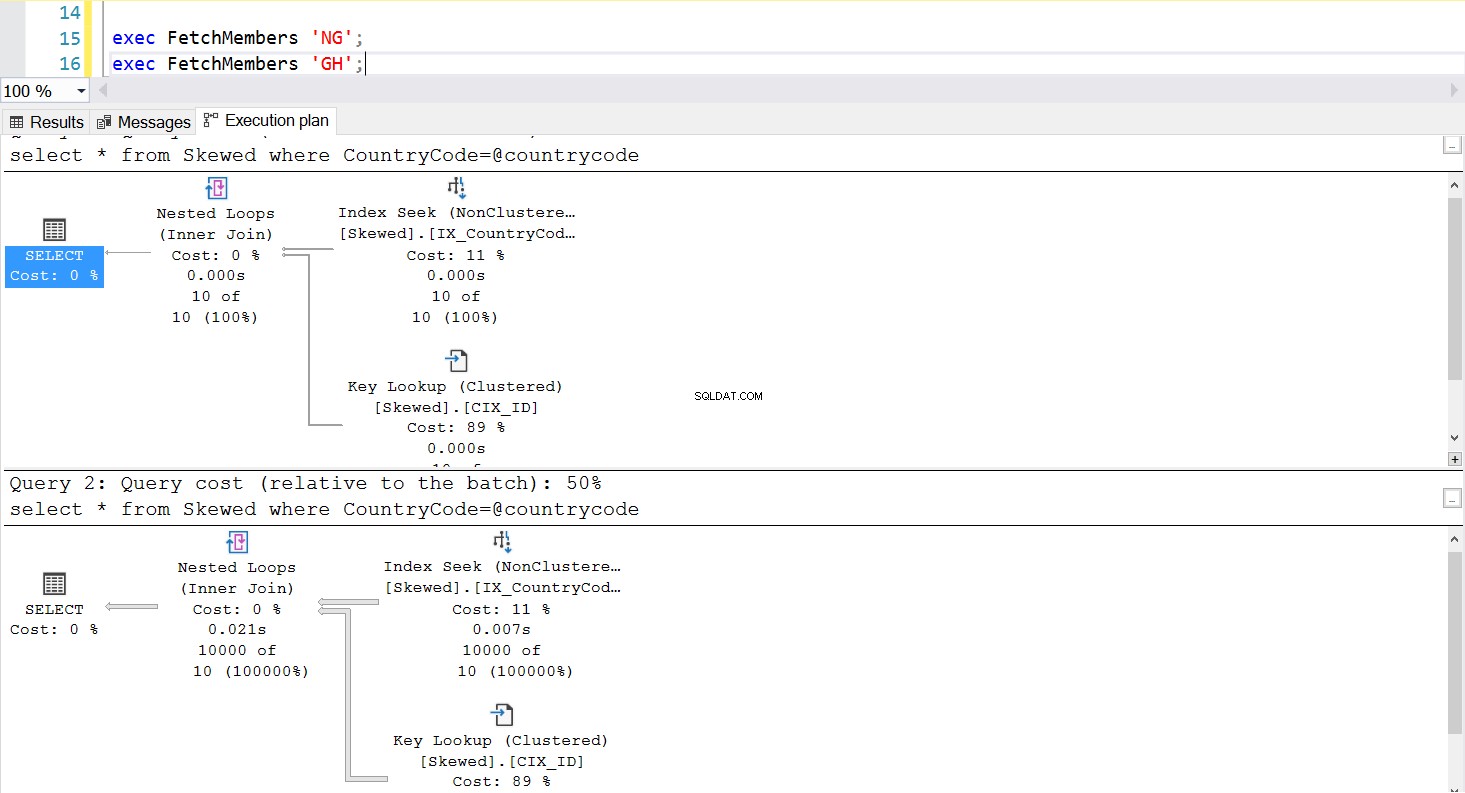
Rys. 5 Indeks szuka planu wykonania, gdy „NG” jest używane jako pierwsze
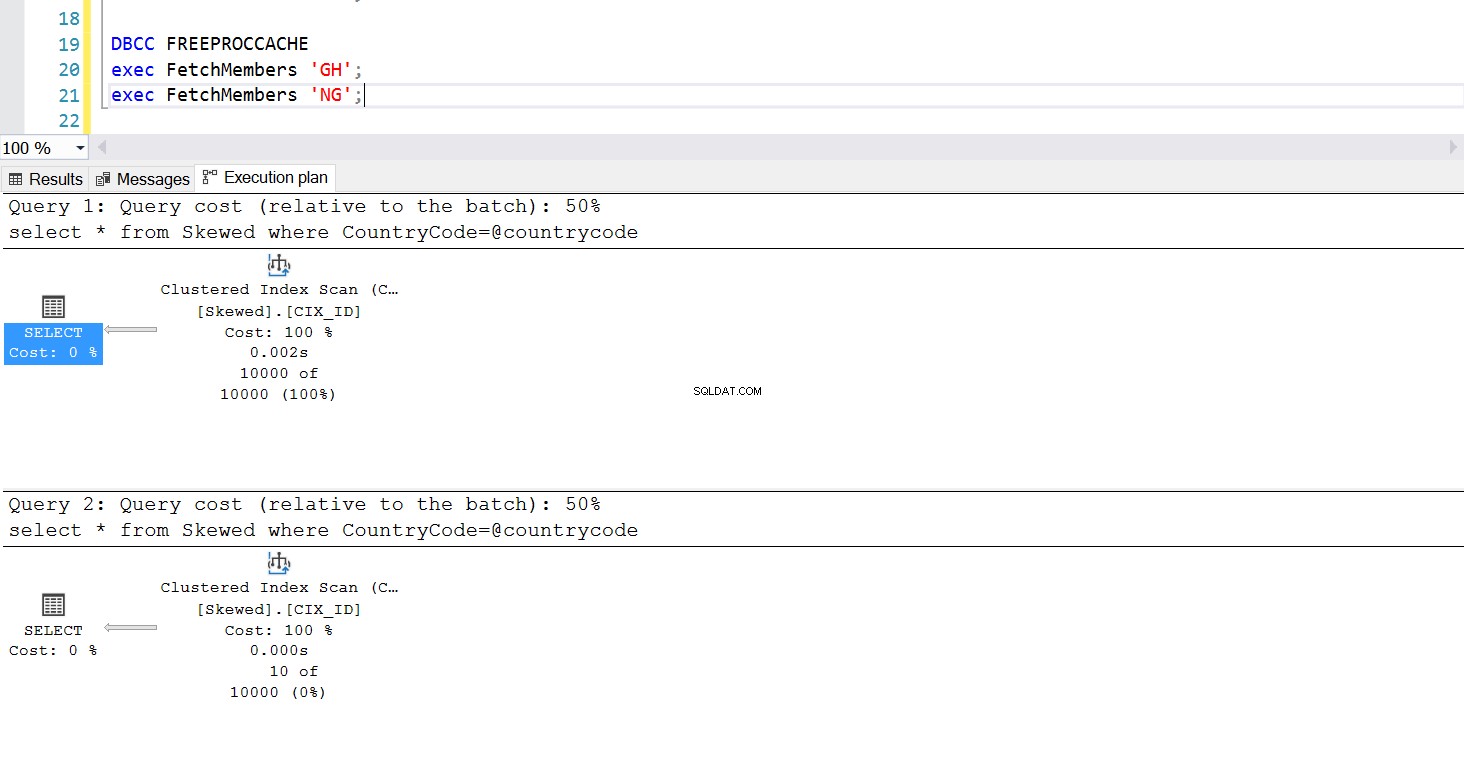
Rys. 6 Plan wykonania skanowania indeksu klastrowego, gdy „GH” jest używany jako pierwszy
Wykonanie procedury składowanej przebiega zgodnie z założeniami – wymagany plan wykonania jest konsekwentnie stosowany. Może to jednak stanowić problem, ponieważ jeden plan wykonania nie jest odpowiedni dla wszystkich zapytań, jeśli dane są przekrzywione. Używanie indeksu do pobierania kolekcji wierszy prawie tak dużej, jak cała tabela, nie jest wydajne — podobnie jak pełne skanowanie w celu pobrania tylko niewielkiej liczby wierszy. To jest problem z wykrywaniem parametrów.
Możliwe rozwiązania
Jednym z powszechnych sposobów zarządzania problemem wykrywania parametrów jest celowe wywoływanie rekompilacji za każdym razem, gdy wykonywana jest procedura składowana. Jest to znacznie lepsze niż opróżnianie pamięci podręcznej planu — z wyjątkiem sytuacji, gdy chcesz opróżnić pamięć podręczną tego konkretnego zapytania SQL, co jest całkowicie możliwe. Spójrz na zaktualizowaną wersję procedury składowanej. Tym razem używa OPCJI (RECOMPILE) do zarządzania problemem. Rys. 6 pokazuje nam, że za każdym razem, gdy wykonywana jest nowa procedura składowana, używa ona planu odpowiedniego do przekazywanego parametru.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
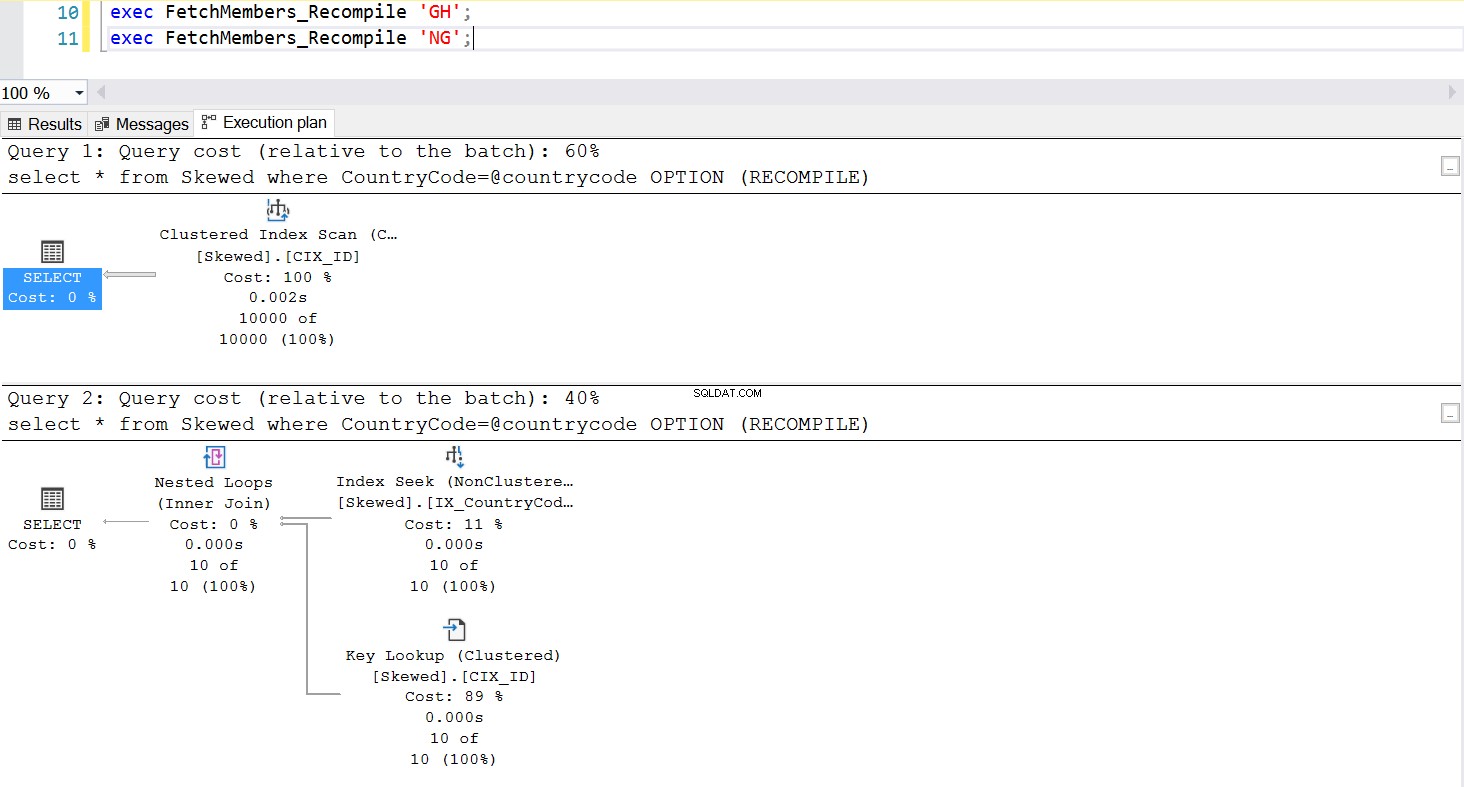
Rys. 7 Zachowanie procedury składowanej za pomocą OPCJI (RECOMPILE)
Wniosek
W tym artykule przyjrzeliśmy się, jak spójne plany wykonania procedur składowanych mogą stać się problemem, gdy dane, z którymi mamy do czynienia, są przekrzywione. Pokazaliśmy to również w praktyce i poznaliśmy wspólne rozwiązanie problemu. Śmiem twierdzić, że ta wiedza jest nieoceniona dla programistów korzystających z SQL Server. Istnieje wiele innych rozwiązań tego problemu – Brent Ozar zagłębił się w temat i podkreślił kilka głębszych szczegółów i rozwiązań na SQLDay Poland 2017. Odpowiedni link wymieniłem w sekcji referencyjnej.
Referencje
Planowanie pamięci podręcznej i optymalizacja pod kątem obciążeń adhoc
Identyfikowanie i naprawianie problemów z podsłuchiwaniem parametrów