Czy myślisz o czymś, kiedy tworzysz nową bazę danych? Myślę, że większość z Was odmówiłaby, ponieważ wszyscy używamy domyślnych parametrów, choć daleko im do optymalnych. Istnieje jednak wiele ustawień dysków, które naprawdę pomagają zwiększyć niezawodność i wydajność systemu.
Nie będziemy mówić o znaczeniu systemu plików NTFS dla niezawodności danych, chociaż ten system plików pozwala MS SQL Server na korzystanie z dysku w najbardziej efektywny sposób.
Jeśli brakuje Ci zasobów i coś zaczyna działać wolno, pierwszą rzeczą, która przychodzi ci na myśl, jest aktualizacja. Ale modernizacja nie jest wymagana w każdym przypadku. Strojenie może ujść na sucho, ale powinno się to robić nie wtedy, gdy serwer zaczyna działać wolno, ale na etapie projektowania i instalacji.
Optymalizacja jest procesem złożonym i często dotyczy nie tylko określonego programu (w naszym przypadku pewnej bazy danych), ale także systemu operacyjnego i sprzętu. Chociaż będziemy głównie mówić o bazach danych, nie możemy ignorować zewnętrznych rzeczy.
Architektura danych
SQL Server przechowuje, odczytuje i zapisuje dane w blokach po 8 KB każdy. Te bloki nazywane są stronami. Baza danych może przechowywać 128 stron na megabajt (1 megabajt lub 1048576 bajtów podzielone przez 8 kilobajtów lub 8192 bajty). Wszystkie strony są przechowywane w pewnym zakresie. Rozszerzenie to ostatnie 8 kolejnych stron lub 64 KB. Tak więc 1 megabajt przechowuje 16 zakresów.
Strony i ekstenty są podstawą fizycznej struktury bazy danych SQL Server. MS SQL Server wykorzystuje różne typy stron, niektóre z nich śledzą przydzielone miejsce, inne zawierają dane użytkownika i indeksy. Strony śledzące przydzielone miejsce zawierają gęsto skompresowane dane. Pozwala MS SQL Server na efektywne przechowywanie ich w pamięci w celu łatwego odczytu.
SQL Server używa dwóch rodzajów ekstentów:
- Zakresy, które przechowują strony od dwóch do wielu obiektów, nazywane są zakresami mieszanymi. Każda tabela zaczyna się jako zakres mieszany. Używasz zakresu mieszanego głównie dla stron, które przechowują przestrzeń i zawierają małe obiekty.
- Rozszerzenia, które mają wszystkie 8 stron przydzielone do jednego obiektu, są nazywane zakresami jednolitymi. Są używane, gdy tabela lub indeks wymaga więcej niż 64 KB.
Pierwszy ekstent dla każdego pliku jest jednolity i zawiera strony nagłówka pliku, kolejne ekstenty zawierają po 3 przydzielone strony. Serwer przydziela te mieszane zakresy podczas tworzenia podstawowego pliku danych i używa tych stron do swoich wewnętrznych zadań. Strona nagłówka pliku zawiera atrybuty pliku, takie jak nazwa bazy danych przechowywanej w pliku, grupa plików, minimalny rozmiar, rozmiar przyrostu. To jest pierwsza strona każdego pliku (strona 0).
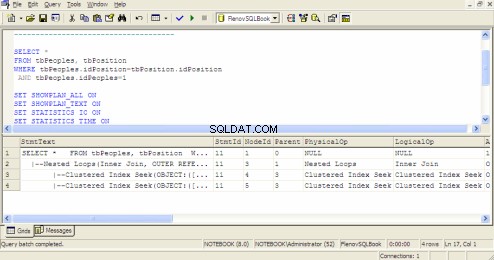
Plan wykonywania zapytań w analizatorze zapytań SQL
Wolne miejsce na stronie (PFS ) na przydzielonej stronie, która zawiera informacje o wolnym miejscu dostępnym w pliku. Te informacje są przechowywane na stronie 1. Każda taka strona może rozciągać się na 8000 sąsiadujących stron, co stanowi około 64 Mb danych.
Dziennik transakcji zbiera wszystkie informacje o zmianach zachodzących na serwerze w celu przywrócenia bazy danych w momencie błędu systemu i zapewnienia integralności danych.
Zauważ, że wszystkie liczby są wielokrotnościami 8 lub 16. Dzieje się tak, ponieważ kontroler dysku twardego łatwiej odczytuje dane o tym rozmiarze. Dane są odczytywane z dysku po stronach, czyli co 8 kilobajtów, co jest wartością całkiem optymalną.
Ochrona strony
Od wersji MS SQL Server 2005 serwer bazy danych posiada nową opcję – kontrolę danych na poziomie strony. Jeśli AGE_VERIFY_CHECKSUM parametr jest włączony (domyślnie włączony), serwer będzie kontrolował sumy kontrolne stron. Jeśli zajrzymy do instrukcji dla tego parametru, zobaczymy, że suma kontrolna umożliwia śledzenie błędów wejścia/wyjścia, których system operacyjny nie jest w stanie śledzić. Jakie to są błędy? Wygląda na to, że są to wewnętrzne problemy serwera bazy danych.
Kontrola integralności danych nigdy się nie kończy, więc lepiej ją włączyć. W tym celu musimy wykonać następujące polecenie:
ALTER DATABASE имя базы SET PAGE_VERIFY
Jeśli na stronie pojawi się błąd, serwer poinformuje nas o tym. Ale jak możemy to szybko naprawić? W tym celu istnieje możliwość przywrócenia danych na poziomie strony.
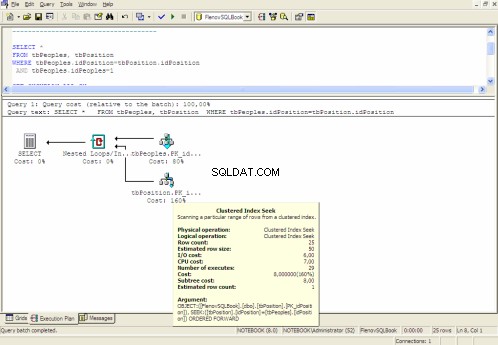
Graficzny plan wykonania
Rozwój pliku
Kiedy tworzymy bazę danych, jesteśmy proszeni o wybranie początkowego rozmiaru i metody inkrementacji. Gdy brakuje nam aktualnej przestrzeni, serwer rozszerza ją zgodnie z ustawioną metodą przyrostu.
Istnieją trzy metody inkrementacji plików:
- Wzrost w megabajtach.
- Wzrost o procent.
- Ręczny wzrost.
Pierwsze dwie metody są wykonywane automatycznie, ale są zalecane tylko dla testowych baz danych, ponieważ administrator nie ma kontroli nad rozmiarem pliku.
Jeśli plik zostanie powiększony o określoną liczbę megabajtów, w pewnym momencie prędkość wstawiania danych może wzrosnąć, a wzrost pliku może stać się zbyt częsty, co wiąże się z dodatkowymi kosztami. Nieopłacalny jest też przyrost plików w procentach. Zaleca się użycie 10% przyrostu pliku i jest to OK dla małych i średnich baz danych. Ale kiedy osiągnie 1000 gigabajtów, przy każdym wzroście będzie wymagać 100 gigabajtów. Doprowadzi to do bezsensownego marnowania miejsca na dysku.
Zawsze kontroluj zmiany wielkości plików i dzienników transakcji. Pozwoli to na najbardziej efektywne wykorzystanie zasobów dysku.
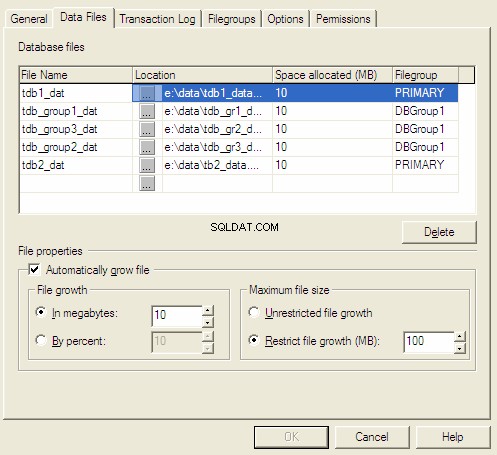
Właściwości bazy danych MS SQL Server
Kompresja danych
Dysk twardy pozostaje sensownym punktem komputera. Wydajność procesorów gwałtownie rośnie, podczas gdy dyski twarde nie mogą zaoferować czegoś nowego. Aby zaoszczędzić liczbę operacji wejścia/wyjścia i zmniejszyć ilość danych przechowywanych na dysku twardym, możesz użyć dysków z kompresją. Tylko takie dyski nadają się do przechowywania grup plików tylko do odczytu. Być może dzieje się tak dlatego, że do pisania wymagana jest kompresja i wiąże się to z dodatkowymi kosztami procesora.
Kompresja danych i stan tylko do odczytu są dobre dla danych archiwalnych. Na przykład dane księgowe z ostatnich lat nie są wymagane do pisania i mogą zajmować zbyt dużo miejsca. Umieszczając dane w archiwalnej sekcji dysku, znacznie zaoszczędzisz miejsce.
Dyski zapewniające niezawodność
Poniższa metoda pozwala jednocześnie zwiększyć niezawodność i wydajność, i ponownie jest związana z dyskami twardymi. No tak, mechanika jest nie tylko najwolniejsza, ale i najbardziej zawodna. Jeśli chodzi o niezawodność to nie zbierałem statystyk, ale zarówno w domu jak i w pracy zajmuję się głównie dyskami twardymi.
Tak więc, aby zwiększyć wydajność i niezawodność, możesz po prostu użyć dwóch lub więcej dysków twardych zamiast jednego. Będzie jeszcze lepiej, jeśli zostaną podłączone do osobnych kontrolerów. Bazę danych można przechowywać na jednym dysku, a dzienniki transakcji na innym. Jeśli istnieje trzeci dysk, może on przechowywać system.
Przechowywanie danych i dziennika na osobnych dyskach pozwala znacznie zwiększyć niezawodność. Załóżmy, że masz wszystko na jednym dysku i spada. Co robić? Możesz dotrzeć do firmy, która spróbuje wszystko odzyskać lub spróbuje zrobić to samo na własną rękę, ale szansa na odzyskanie jest daleka od 100%. Poza tym przywrócenie serwera do pracy może zająć dużo czasu. Szybkie odzyskiwanie można wykonać tylko do momentu wykonania ostatniej kopii zapasowej. Reszta jest wątpliwa.
A teraz załóżmy, że masz dane i dziennik transakcji na różnych dyskach. Jeśli dysk z logiem zgaśnie, dane nadal tam będą. Jedyną rzeczą jest to, że nie możesz dodawać nowych danych, ale jeśli utworzysz nowy dziennik, możesz kontynuować pracę.
Jeśli dysk z danymi zgaśnie, nadal możemy zarezerwować dziennik transakcji, aby zapobiec najmniejszej utracie danych. Następnie odzyskujemy dane z pełnej kopii zapasowej (zawsze należy to zrobić wcześniej, dobry administrator robi to przynajmniej raz dziennie) i dodajemy zmiany z kopii zapasowej dziennika.
Dyski zwiększające wydajność
Jeśli dane i logi znajdują się na osobnych dyskach, oznacza to nie tylko bezpieczeństwo, ale także wzrost wydajności. Chodzi o to, że serwer bazy danych może jednocześnie zapisywać dane w dzienniku i pliku danych.
Możemy pójść dalej i przydzielić jeden dysk twardy do dziennika transakcji i kilka dysków twardych do danych. Serwer częściej pracuje z danymi, dlatego wymaga kilku magazynów, z którymi możesz pracować jednocześnie. A jeśli te pamięci są podłączone do różnych kontrolerów, gwarantowana jest jednoczesna praca.
Najszybszym i najbardziej niezawodnym wariantem jest użycie RAID . Jednak nie każdy RAID jest jednocześnie niezawodny i szybki. W przypadku grup plików zaleca się wybranie RAID10 , ponieważ zawiera dobrze wyważone funkcje, ale w zależności od danych z bazy danych możesz wybrać inny wariant.
Możesz użyć oprogramowania lub rozwiązania sprzętowego jako RAID . Oprogramowanie jest tańsze, ale wymaga dodatkowych zasobów procesora. A procesor nie ma wolnych zasobów. Dlatego lepiej jest korzystać z rozwiązań sprzętowych, w których za RAID odpowiada dedykowany chip. .
Indeksy
Wszyscy wiedzą, że indeksy pomagają zwiększyć szybkość wyszukiwania danych. Większość z nas rozumie, że indeksy negatywnie wpływają na wstawianie i aktualizowanie danych, więc im więcej masz indeksów, tym trudniej jest je utrzymać serwerowi. Niewielu nawet myśli, że indeksy wymagają konserwacji. Strony bazy danych zawierające dane indeksowe mogą się przepełnić i ostatecznie stracić równowagę.
Tak, możemy zignorować różne parametry i po prostu odtworzyć indeksy raz w miesiącu, co przypomina konserwację. SQL Server zawiera dwa parametry, które zapobiegają dezaktualizacji indeksów w pół godziny po ich utworzeniu:FILLFACTOR i PAD_INDEX .
Możesz użyć opcji FILLFACTOR, aby zoptymalizować wydajność operacji wstawiania i aktualizowania, które zawierają indeks klastrowany lub nieklastrowany. Dane indeksowe mogą być przechowywane na wielu stronach danych. Jak wspomniałem powyżej, każda strona składa się z 8 KB. Gdy strona indeksu jest pełna, serwer tworzy nową stronę i dzieli stronę do wstawiania danych na dwie.
Serwer potrzebuje czasu na podział strony i utworzenie nowej strony. Aby zoptymalizować podział strony, użyj FILLFACTOR możliwość określenia procentu wolnego miejsca na wszystkich kartach strony indeksu. Im większe miejsce na dysku mają strony na poziomie liścia, tym rzadziej będziesz musiał dzielić strony indeksu. W takim przypadku drzewo indeksu będzie zbyt duże, a jego obejście zajmie więcej czasu.
PAD_INDEX opcja wskazuje procent wypełnienia stron bez kartek. Możesz użyć PAD_INDEX tylko wtedy, gdy FILLFACTOR opcja jest określona, ponieważ wartość procentowa PAD_INDEX zależy od wartości procentowej określonej w FILLFACTOR .
Statystyki
Statystyki pozwalają serwerowi na podjęcie właściwej decyzji między użyciem indeksu a skanowaniem pełnej tabeli. Załóżmy, że masz listę pracowników odlewni. Taka lista będzie składała się z około 90% mężczyzn.
Załóżmy teraz, że musimy znaleźć wszystkie kobiety. Ponieważ jest ich niewiele, najskuteczniejszą opcją będzie użycie indeksu. Ale jeśli musimy znaleźć wszystkich mężczyzn, wydajność indeksu spada. Liczba wybranych rekordów jest zbyt duża i pominięcie drzewa indeksu dla każdego z nich będzie kosztowało. O wiele prostsze jest przeskanowanie całej tabeli – wykonanie będzie znacznie szybsze, ponieważ serwer będzie musiał jednorazowo odczytać wszystkie niskopoziomowe liście indeksu, bez konieczności wielokrotnych odczytów wszystkich poziomów.
SQL Server zbiera statystyki, odczytując wszystkie wartości pól lub za pomocą szablonu do tworzenia równomiernie rozłożonej i posortowanej listy wartości. SQL Server dynamicznie wykrywa procent wierszy, które należy przetestować, na podstawie liczby wierszy w tabeli. Podczas zbierania statystyk optymalizator zapytań wykona pełne skanowanie lub szablony wierszy.
Aby statystyka działała, musi zostać utworzona. W przypadku masowej aktualizacji danych statystyki mogą zawierać błędne dane, a serwer podejmie błędną decyzję. Ale wszystko da się naprawić – trzeba monitorować statystyki. Więcej szczegółowych informacji można znaleźć w książkach dotyczących języka Transact-SQL lub MS SQL Server.
Podsumowanie
Domyślne ustawienia nie pozwalają na wykorzystanie całego potencjału sprzętu i pracę z różnymi serwerami. Odpowiedzialność za ustawienia spoczywa na administratorach. Fakt, że produkty Microsoft mają proste programy instalacyjne, graficzne narzędzia administracyjne i możliwość pracy w trybie offline, nie oznacza, że jest to optymalny wariant.
Nie uważamy takich opcji dostrajania bazy danych za akcelerację sprzętową. Jeśli wszystkie opcje dostrajania są wyczerpane, lepiej pomyśleć o aktualizacji, ponieważ przyspieszenie sprzętowe negatywnie wpływa na niezawodność systemu.
Najważniejszą rzeczą jest to, że jakakolwiek optymalizacja serwera bazy danych lub jakakolwiek aktualizacja nie pomoże, jeśli zapytania nie zostaną zoptymalizowane.



