Czy SQL DISTINCT jest dobry (lub zły), gdy trzeba usunąć duplikaty w wynikach?
Niektórzy twierdzą, że to dobrze i dodają DISTINCT, gdy pojawiają się duplikaty. Niektórzy twierdzą, że to złe i sugerują używanie GROUP BY bez funkcji agregującej. Inni twierdzą, że DISTINCT i GROUP BY są takie same, gdy trzeba usunąć duplikaty.
W tym poście zagłębimy się w szczegóły, aby uzyskać prawidłowe odpowiedzi. W końcu użyjesz najlepszego słowa kluczowego w zależności od potrzeb. Zacznijmy.
Krótkie przypomnienie podstaw instrukcji SQL SELECT DISTINCT
Zanim zagłębimy się głębiej, przypomnijmy sobie, czym jest instrukcja SQL SELECT DISTINCT. Tabela bazy danych może zawierać zduplikowane wartości z wielu powodów, ale możemy chcieć uzyskać tylko wartości unikatowe. W takim przypadku przydaje się SELECT DISTINCT. Ta klauzula DISTINCT sprawia, że instrukcja SELECT pobiera tylko unikalne rekordy.
Składnia instrukcji jest prosta:
SELECT DISTINCT column
FROM table_name
WHERE [condition];W tym przypadku warunek WHERE jest opcjonalny.
Oświadczenie dotyczy zarówno jednej kolumny, jak i wielu kolumn. Składnia tej instrukcji zastosowana do wielu kolumn jest następująca:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Zwróć uwagę, że scenariusz odpytywania kilku kolumn zasugeruje użycie kombinacji wartości we wszystkich kolumnach zdefiniowanych przez wyrażenie w celu określenia unikalności.
A teraz przyjrzyjmy się praktycznemu wykorzystaniu i pułapkom stosowania instrukcji SELECT DISTINCT.
Jak działa SQL DISTINCT w celu usunięcia duplikatów
Uzyskanie odpowiedzi nie jest tak trudne do znalezienia. SQL Server dostarczył nam plany wykonania, aby zobaczyć, jak zapytanie zostanie przetworzone, aby uzyskać potrzebne wyniki.
Poniższa sekcja koncentruje się na planie wykonania podczas korzystania z DISTINCT. Musisz nacisnąć Ctrl-M w SQL Server Management Studio przed wykonaniem poniższych zapytań. Lub kliknij Dołącz rzeczywisty plan wykonania z paska narzędzi.
Plany zapytań w SQL DISTINCT
Zacznijmy od porównania 2 zapytań. Pierwsze nie użyje DISTINCT, a drugie użyje.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Oto plan wykonania:
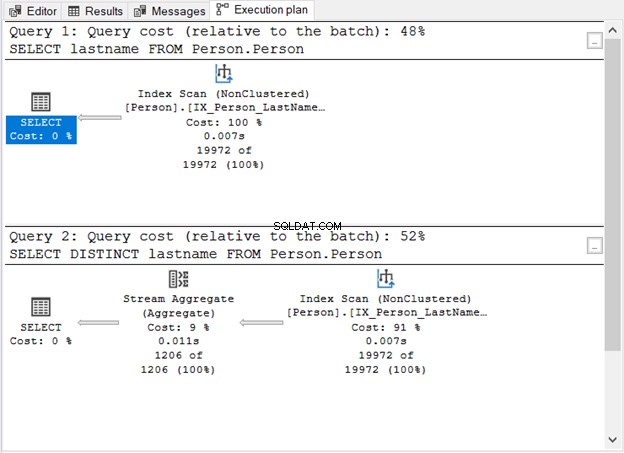
Co pokazał nam Rysunek 1?
- Bez słowa kluczowego DISTINCT zapytanie jest proste.
- Po dodaniu DISTINCT pojawia się dodatkowy krok.
- Koszt zapytania przy użyciu DISTINCT jest wyższy niż bez niego.
- Oba mają operatory skanowania indeksu. Jest to zrozumiałe, ponieważ w naszych zapytaniach nie ma konkretnej klauzuli WHERE.
- Dodatkowy krok, operator Stream Aggregate, służy do usuwania duplikatów.
Liczba logicznych odczytów jest taka sama (107), jeśli sprawdzisz STATISTICS IO. Jednak liczba rekordów jest bardzo różna. Pierwsze zapytanie zwraca 19 972 wierszy. Tymczasem drugie zapytanie zwraca 1206 wierszy.
Dlatego nie możesz dodać DISTINCT w dowolnym momencie. Ale jeśli potrzebujesz unikalnych wartości, jest to konieczne obciążenie.
Istnieją operatory używane do wyprowadzania unikalnych wartości. Przyjrzyjmy się niektórym z nich.
AGREGAT STRUMIENIA
Jest to operator, który widziałeś na rysunku 1. Akceptuje pojedyncze dane wejściowe i wyprowadza zagregowany wynik. Na rysunku 1 dane wejściowe pochodzą od operatora skanowania indeksu. Jednak Stream Aggregate wymaga posortowanych danych wejściowych.
Jak widać na rysunku 1, używa on IX_Person_LastName_FirstName_MiddleName , nieunikalny indeks nazwisk. Ponieważ indeks już sortuje rekordy według nazwy, Stream Aggregate akceptuje dane wejściowe. Bez indeksu optymalizator zapytań może zdecydować się na użycie w planie dodatkowego operatora sortowania. A to będzie droższe. Lub może użyć Hash Match.
HASH MATCH (AGREGACJA)
Innym operatorem używanym przez DISTINCT jest Hash Match. Ten operator jest używany do złączeń i agregacji.
Używając DISTINCT, Hash Match agreguje wyniki w celu uzyskania unikalnych wartości. Oto jeden przykład.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
A oto plan wykonania:
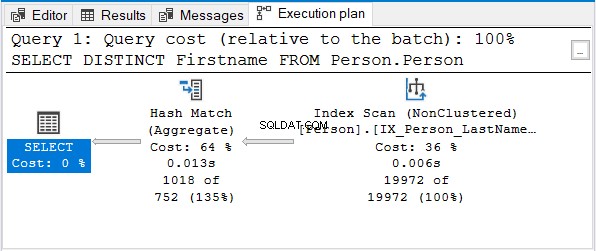
Ale dlaczego nie Stream Aggregate?
Zwróć uwagę, że używany jest ten sam indeks nazw. Ten indeks jest sortowany według Nazwisko pierwszy. A więc Imię tylko zapytanie zostanie nieposortowane.
Hash Match (Aggregate) to kolejny logiczny wybór do usunięcia duplikatów.
PASOWANIE HASH (FLOW DISTINCT)
Hash Match (Aggregate) jest operatorem blokującym. W ten sposób nie wygeneruje danych wyjściowych, które przetworzył w całym strumieniu wejściowym. Jeśli ograniczymy liczbę wierszy (na przykład użycie TOP z DISTINCT), wygeneruje unikalny wynik, gdy tylko te wiersze będą dostępne. Na tym właśnie polega Hash Match (Flow Distinct).
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Zapytanie wykorzystuje TOP 100 wraz z DISTINCT. Oto plan wykonania:
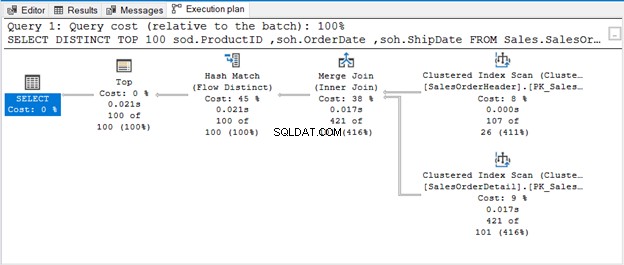
GDY NIE MA OPERATORA DO USUNIĘCIA DUPLIKATÓW
Tak. To może się zdarzyć. Rozważ poniższy przykład.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Następnie sprawdź plan wykonania:
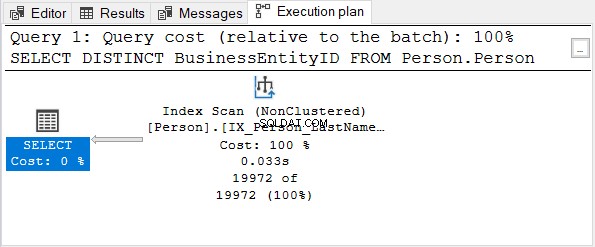
BusinessEntityID kolumna jest kluczem podstawowym. Ponieważ ta kolumna jest już unikalna, nie ma sensu stosować DISTINCT. Spróbuj usunąć DISTINCT z instrukcji SELECT – plan wykonania jest taki sam jak na rysunku 4.
To samo dotyczy używania DISTINCT na kolumnach z unikalnym indeksem.
SQL DISTINCT działa na WSZYSTKICH kolumnach na liście SELECT
Do tej pory w naszych przykładach używaliśmy tylko 1 kolumny. Jednak DISTINCT działa na WSZYSTKICH kolumnach określonych na liście SELECT.
Oto przykład. To zapytanie zapewni, że wartości wszystkich 3 kolumn będą niepowtarzalne.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Zwróć uwagę na kilka pierwszych wierszy w zestawie wyników na rysunku 5.
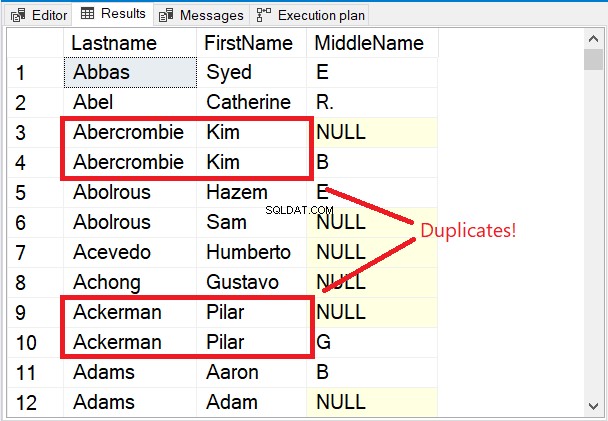
Pierwsze kilka rzędów jest niepowtarzalnych. Słowo kluczowe DISTINCT zapewniło, że Drugie imię brana jest również pod uwagę kolumna. Zwróć uwagę na 2 nazwiska w czerwonym polu. Biorąc pod uwagę nazwisko i Imię tylko uczyni je duplikatami. Ale dodanie Drugiego imienia do miksu wszystko się zmieniło.
Co zrobić, jeśli chcesz uzyskać unikalne imię i nazwisko, ale w wyniku uwzględnić drugie imię?
Masz 2 opcje:
- Dodaj klauzulę WHERE, aby usunąć drugie imiona o wartości NULL. To usunie wszystkie imiona z NULL drugim imieniem.
- Lub dodaj klauzulę GROUP BY do Nazwiska i Imię kolumny. Następnie użyj funkcji agregującej MIN na Drugim imieniu kolumna. Otrzymasz jedno drugie imię z tym samym nazwiskiem i imieniem.
SQL DISTINCT vs. GROUP BY
W przypadku korzystania z funkcji GROUP BY bez funkcji agregującej działa jak DISTINCT. Skąd wiemy? Jednym ze sposobów, aby się tego dowiedzieć, jest skorzystanie z przykładu.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Uruchom je i sprawdź plan wykonania. Czy to jak na poniższym zrzucie ekranu?
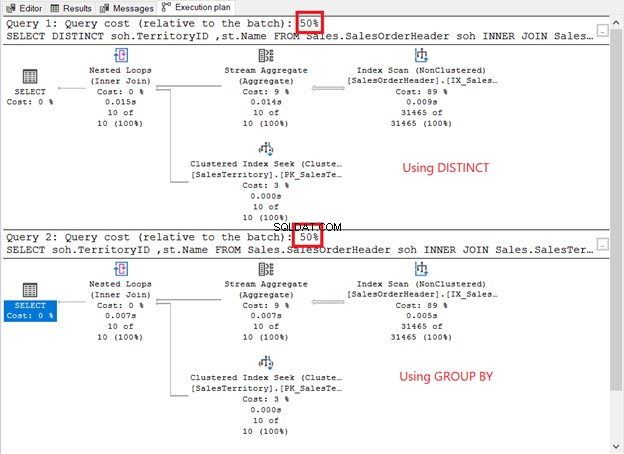
Jak się porównują?
- Mają te same operatory planu i kolejność.
- Koszt operatora każdego i koszt zapytania są takie same.
Jeśli zaznaczysz QueryPlanHash właściwości dwóch operatorów SELECT są takie same. Dlatego optymalizator zapytań użył tego samego procesu, aby zwrócić te same wyniki.
W końcu nie możemy powiedzieć, że używanie GROUP BY jest lepsze niż DISTINCT w zwracaniu unikalnych wartości. Możesz to udowodnić, używając powyższych przykładów, aby zastąpić DISTINCT przez GROUP BY.
To jest teraz kwestia preferencji, z których będziesz korzystać. Wolę WYRÓŻNIONE. Wyraźnie mówi o intencji w zapytaniu – aby uzyskać unikalne wyniki. A dla mnie GROUP BY służy do grupowania wyników za pomocą funkcji agregującej. Ta intencja jest również jasna i spójna z samym słowem kluczowym. Nie wiem, czy ktoś inny utrzyma moje zapytania pewnego dnia. Tak więc kod powinien być czytelny.
Ale to nie koniec historii.
Kiedy SQL DISTINCT nie jest takie samo jak GROUP BY
Właśnie wyraziłem swoją opinię, a potem to?
To prawda. Nie będą cały czas takie same. Rozważ ten przykład.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Chociaż zestaw wyników jest nieposortowany, wiersze są takie same jak w poprzednim przykładzie. Jedyną różnicą jest użycie podzapytania:
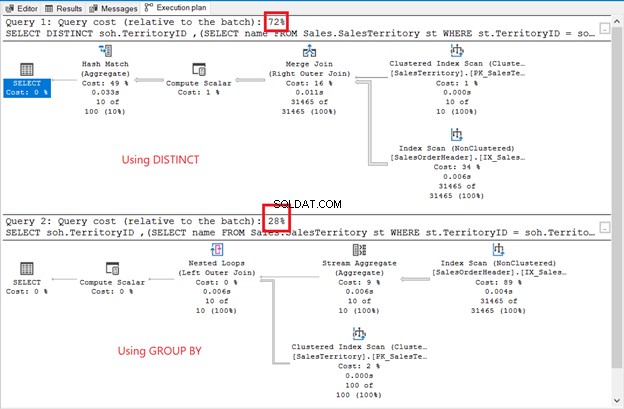
Różnice są oczywiste:operatorzy, koszt zapytania, ogólny plan. Tym razem GROUP BY wygrywa z zaledwie 28% kosztem zapytania. Ale o to chodzi.
Celem jest pokazanie, że mogą być różne. To wszystko. To nie jest zalecenie. Korzystanie z połączenia ma lepszy plan wykonania (patrz ponownie Rysunek 6).
Konkluzja
Oto, czego nauczyliśmy się do tej pory:
- DISTINCT dodaje operatora planu do usuwania duplikatów.
- DISTINCT i GROUP BY bez funkcji agregującej dają ten sam plan. Krótko mówiąc, przez większość czasu są takie same.
- Czasami DISTINCT i GROUP BY mogą mieć różne plany, gdy podzapytanie jest zaangażowane w listę SELECT.
Czy zatem SQL DISTINCT jest dobry czy zły w usuwaniu duplikatów w wynikach?
Wyniki mówią, że jest dobrze. Nie jest ani lepszy, ani gorszy niż GROUP BY, ponieważ plany są takie same. Ale dobrym zwyczajem jest sprawdzenie planu wykonania. Pomyśl o optymalizacji od samego początku. W ten sposób, jeśli natkniesz się na jakiekolwiek różnice w DISTINCT i GROUP BY, zauważysz je.
Poza tym nowoczesne narzędzia znacznie ułatwiają to zadanie. Na przykład popularny produkt dbForge SQL Complete firmy Devart ma specyficzną funkcję, która oblicza wartości w funkcjach agregujących w gotowym zestawie wyników siatki wyników SSMS. Są tam również obecne wartości DISTINCT.
Podoba Ci się post? Następnie rozpowszechniaj informacje, udostępniając je na swoich ulubionych platformach społecznościowych.
Powiązane artykuły, aby uzyskać więcej informacji
- SQL GROUP BY:3 proste wskazówki dotyczące grupowania wyników jak profesjonalista
- SQL INSERT INTO SELECT:5 łatwych sposobów obsługi duplikatów
- Co to są funkcje agregujące SQL? (Łatwe wskazówki dla początkujących)
- Optymalizacja zapytań SQL:5 podstawowych faktów zwiększających liczbę zapytań