Funkcja okna ROW_NUMBER ma wiele praktycznych zastosowań, znacznie wykraczających poza oczywiste potrzeby rankingowe. W większości przypadków, gdy obliczasz numery wierszy, musisz je obliczyć w oparciu o pewną kolejność, a żądaną specyfikację kolejności podajesz w klauzuli kolejności okien funkcji. Istnieją jednak przypadki, w których trzeba obliczyć numery wierszy w dowolnej kolejności; innymi słowy, w oparciu o porządek niedeterministyczny. Może to dotyczyć całego wyniku zapytania lub partycji. Przykłady obejmują przypisywanie unikalnych wartości do wierszy wyników, deduplikację danych i zwracanie dowolnego wiersza na grupę.
Należy zauważyć, że konieczność przypisywania numerów wierszy w oparciu o niedeterministyczną kolejność różni się od konieczności przypisywania ich w kolejności losowej. W przypadku tego pierwszego po prostu nie obchodzi cię, w jakiej kolejności są one przypisywane i czy powtarzające się wykonania zapytania nadal przypisują te same numery wierszy do tych samych wierszy, czy nie. W przypadku tego ostatniego oczekujesz, że powtarzające się egzekucje będą nadal zmieniać, które wiersze są przypisane do których numerów wierszy. W tym artykule omówiono różne techniki obliczania numerów wierszy w niedeterministycznym porządku. Mamy nadzieję, że uda się znaleźć technikę, która będzie zarówno niezawodna, jak i optymalna.
Specjalne podziękowania dla Paula White'a za wskazówkę dotyczącą ciągłego składania, za technikę stałej czasu pracy i za to, że zawsze jest świetnym źródłem informacji!
Kiedy zamówienie ma znaczenie
Zacznę od przypadków, w których kolejność numerów wierszy ma znaczenie.
W moich przykładach użyję tabeli o nazwie T1. Użyj poniższego kodu, aby utworzyć tę tabelę i wypełnić ją przykładowymi danymi:
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.T1; GO CREATE TABLE dbo.T1 ( id INT NOT NULL CONSTRAINT PK_T1 PRIMARY KEY, grp VARCHAR(10) NOT NULL, datacol INT NOT NULL ); INSERT INTO dbo.T1(id, grp, datacol) VALUES (11, 'A', 50), ( 3, 'B', 20), ( 5, 'A', 40), ( 7, 'B', 10), ( 2, 'A', 50);
Rozważ następujące zapytanie (nazwiemy je Zapytanie 1):
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Tutaj chcesz, aby numery wierszy były przypisane w każdej grupie identyfikowanej przez grp kolumny, uporządkowane według kolumny datacol. Kiedy uruchomiłem to zapytanie w moim systemie, otrzymałem następujące dane wyjściowe:
id grp datacol n --- ---- -------- --- 5 A 40 1 2 A 50 2 11 A 50 3 7 B 10 1 3 B 20 2
Numery wierszy są tutaj przypisywane w kolejności częściowo deterministycznej, a częściowo niedeterministycznej. Mam na myśli to, że masz pewność, że w obrębie tej samej partycji wiersz o większej wartości datacol otrzyma większą wartość numeru wiersza. Jednak ponieważ datacol nie jest unikatowa w obrębie partycji grp, kolejność przypisywania numerów wierszy między wierszami z tymi samymi wartościami grp i datacol jest niedeterministyczna. Tak jest w przypadku wierszy o wartościach id 2 i 11. Oba mają wartość grp A i wartość datacol 50. Kiedy po raz pierwszy wykonałem to zapytanie w moim systemie, wiersz o id 2 otrzymał wiersz numer 2, a wiersz o id 11 uzyskał wiersz numer 3. Nieważne, że to się zdarzy w praktyce w SQL Server; gdybym ponownie uruchomił zapytanie, teoretycznie wiersz o id 2 mógłby zostać przypisany wiersz numer 3, a wiersz o id 11 mógłby zostać przypisany wiersz numer 2.
Jeśli musisz przypisać numery wierszy w oparciu o całkowicie deterministyczną kolejność, gwarantując powtarzalne wyniki podczas wykonywania zapytania, o ile dane bazowe nie ulegną zmianie, potrzebujesz unikalnej kombinacji elementów w klauzulach partycjonowania i porządkowania okien. Można to osiągnąć w naszym przypadku, dodając kolumnę id do klauzuli kolejności okien jako rozstrzygającej. Klauzula OVER miałaby postać:
OVER (PARTITION BY grp ORDER BY datacol, id)
W każdym razie, podczas obliczania numerów wierszy na podstawie jakiejś znaczącej specyfikacji porządkowania, jak w zapytaniu 1, SQL Server musi przetworzyć wiersze uporządkowane według kombinacji elementów partycjonowania i porządkowania okien. Można to osiągnąć, pobierając dane z indeksu w kolejności wstępnej lub sortując dane. W tej chwili nie ma indeksu na T1 do obsługi obliczeń ROW_NUMBER w zapytaniu 1, więc SQL Server musi zdecydować się na sortowanie danych. Można to zobaczyć w planie dla Zapytania 1 pokazanym na rysunku 1.
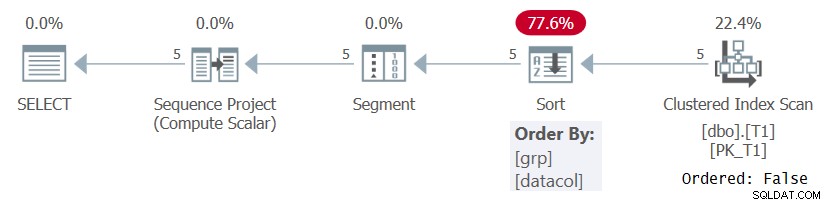 Rysunek 1:Plan dla zapytania 1 bez indeksu pomocniczego
Rysunek 1:Plan dla zapytania 1 bez indeksu pomocniczego
Zwróć uwagę, że plan skanuje dane z indeksu klastrowego z właściwością Ordered:False. Oznacza to, że skanowanie nie musi zwracać wierszy uporządkowanych według klucza indeksu. Dzieje się tak, ponieważ indeks klastrowy jest tutaj używany tylko dlatego, że obejmuje zapytanie, a nie z powodu kolejności kluczy. Następnie plan stosuje sortowanie, co skutkuje dodatkowymi kosztami, skalowaniem N Log N i opóźnionym czasem odpowiedzi. Operator segmentu generuje flagę wskazującą, czy wiersz jest pierwszym w partycji, czy nie. Na koniec operator projektu sekwencji przypisuje numery wierszy zaczynając od 1 w każdej partycji.
Jeśli chcesz uniknąć konieczności sortowania, możesz przygotować indeks pokrywający z listą kluczy opartą na elementach partycjonowania i porządkowania oraz listę dołączania opartą na elementach pokrywających. Lubię myśleć o tym indeksie jako o indeksie POC (do partycjonowania , zamawianie i przykrycie ). Oto definicja POC, który obsługuje nasze zapytanie:
CREATE INDEX idx_grp_data_i_id ON dbo.T1(grp, datacol) INCLUDE(id);
Uruchom ponownie zapytanie 1:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY datacol) AS n FROM dbo.T1;
Plan tego wykonania pokazano na rysunku 2.
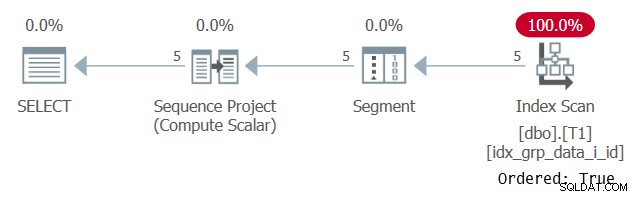 Rysunek 2:Plan dla zapytania 1 z indeksem POC
Rysunek 2:Plan dla zapytania 1 z indeksem POC
Zauważ, że tym razem plan skanuje indeks POC z właściwością Ordered:True. Oznacza to, że skanowanie gwarantuje, że wiersze zostaną zwrócone w kolejności klucza indeksu. Ponieważ dane są pobierane w kolejności wstępnej z indeksu, tak jak potrzebuje to funkcja okna, nie ma potrzeby jawnego sortowania. Skalowanie tego planu jest liniowe, a czas odpowiedzi jest dobry.
Gdy kolejność nie ma znaczenia
Sprawy stają się nieco skomplikowane, gdy trzeba przypisać numery wierszy w zupełnie niedeterministycznej kolejności. Naturalną rzeczą do zrobienia w takim przypadku jest użycie funkcji ROW_NUMBER bez określania klauzuli kolejności okien. Najpierw sprawdźmy, czy pozwala na to standard SQL. Oto odpowiednia część standardu definiująca reguły składni dla funkcji okien:
Zasady składni…
5) Niech WNS będzie
6) Jeśli określono
a) Jeśli określono
…
f) ROW_NUMBER() OVER WNS jest odpowiednikiem
…
Zauważ, że pozycja 6 zawiera listę funkcji
Spróbujmy więc i spróbujmy obliczyć numery wierszy bez porządkowania okien w SQL Server:
SELECT id, grp, datacol, ROW_NUMBER() OVER() AS n FROM dbo.T1;
Ta próba skutkuje następującym błędem:
Msg 4112, Poziom 15, Stan 1, Wiersz 53Funkcja 'ROW_NUMBER' musi mieć klauzulę OVER z ORDER BY.
Rzeczywiście, jeśli sprawdzisz dokumentację SQL Server dotyczącą funkcji ROW_NUMBER, znajdziesz następujący tekst:
„order_by_clauseKlauzula ORDER BY określa kolejność, w jakiej wiersze są przypisywane do ich unikatowego ROW_NUMBER w określonej partycji. Jest to wymagane”.
Tak więc najwyraźniej klauzula kolejności okien jest obowiązkowa dla funkcji ROW_NUMBER w SQL Server. Nawiasem mówiąc, tak samo jest w przypadku Oracle.
Muszę powiedzieć, że nie jestem pewien, czy rozumiem uzasadnienie tego wymogu. Pamiętaj, że pozwalasz na definiowanie numerów wierszy w oparciu o częściowo niedeterministyczny porządek, jak w zapytaniu 1. Dlaczego więc nie pozwolić na niedeterminizm w całości? Być może jest jakiś powód, o którym nie myślę. Jeśli możesz wymyślić taki powód, udostępnij.
W każdym razie możesz argumentować, że jeśli nie zależy ci na kolejności, biorąc pod uwagę, że klauzula kolejności okien jest obowiązkowa, możesz określić dowolną kolejność. Problem z tym podejściem polega na tym, że jeśli złożysz zamówienie według jakiejś kolumny z przywoływanych tabel, może to wiązać się z niepotrzebną utratą wydajności. Gdy nie ma indeksu pomocniczego, zapłacisz za jawne sortowanie. Gdy istnieje indeks pomocniczy, ograniczasz mechanizm pamięci masowej do strategii skanowania kolejności indeksów (zgodnie z listą indeksów połączonych). Nie pozwalasz mu na większą elastyczność, jak zwykle, gdy kolejność nie ma znaczenia przy wyborze między skanowaniem kolejności indeksu a skanowaniem kolejności alokacji (na podstawie stron uprawnień).
Jednym z pomysłów, który warto wypróbować, jest określenie stałej, takiej jak 1, w klauzuli kolejności okien. Jeśli jest obsługiwany, można mieć nadzieję, że optymalizator jest wystarczająco sprytny, aby zdać sobie sprawę, że wszystkie wiersze mają tę samą wartość, więc nie ma rzeczywistego znaczenia porządkowania, a zatem nie ma potrzeby wymuszania sortowania lub skanowania kolejności indeksu. Oto zapytanie próbujące tego podejścia:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1) AS n FROM dbo.T1;
Niestety SQL Server nie obsługuje tego rozwiązania. Generuje następujący błąd:
Msg 5308, Poziom 16, Stan 1, Wiersz 56Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują indeksów liczb całkowitych jako wyrażeń klauzuli ORDER BY.
Najwyraźniej SQL Server zakłada, że jeśli używasz stałej liczby całkowitej w klauzuli kolejności okien, reprezentuje ona pozycję porządkową elementu na liście SELECT, tak jak w przypadku określenia liczby całkowitej w klauzuli ORDER BY prezentacji. W takim przypadku inną opcją, którą warto wypróbować, jest określenie stałej niecałkowitej, na przykład:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No Order') AS n FROM dbo.T1;
Okazuje się, że to rozwiązanie również nie jest obsługiwane. SQL Server generuje następujący błąd:
Msg 5309, Poziom 16, Stan 1, Wiersz 65Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Najwyraźniej klauzula kolejności okien nie obsługuje żadnego rodzaju stałej.
Do tej pory dowiedzieliśmy się, co następuje na temat znaczenia porządkowania okien funkcji ROW_NUMBER w SQL Server:
- Wymagane jest ZAMÓWIENIE PRZEZ.
- Nie można uporządkować według stałej całkowitej, ponieważ SQL Server uważa, że próbujesz określić pozycję porządkową w SELECT.
- Nie można uporządkować według jakiejkolwiek stałej.
Wniosek jest taki, że powinieneś porządkować według wyrażeń, które nie są stałymi. Oczywiście możesz uporządkować według listy kolumn z żądanej tabeli (tabeli). Ale my poszukujemy wydajnego rozwiązania, w którym optymalizator może zdać sobie sprawę, że nie ma znaczenia przy zamawianiu.
Składanie ciągłe
Jak dotąd wniosek jest taki, że nie można używać stałych w klauzuli kolejności okien w ROW_NUMBER, ale co z wyrażeniami opartymi na stałych, tak jak w następującym zapytaniu:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+0) AS n FROM dbo.T1;
Jednak ta próba pada ofiarą procesu znanego jako ciągłe składanie, który zwykle ma pozytywny wpływ na wydajność zapytań. Ideą tej techniki jest zwiększenie wydajności zapytań poprzez zwinięcie niektórych wyrażeń opartych na stałych do ich stałych wynikowych na wczesnym etapie przetwarzania zapytania. Szczegóły dotyczące tego, jakie wyrażenia można składać na stałe, znajdziesz tutaj. Nasze wyrażenie 1+0 jest składane do 1, co skutkuje tym samym błędem, który pojawił się podczas bezpośredniego określania stałej 1:
Msg 5308, Poziom 16, Stan 1, Wiersz 79Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują indeksów liczb całkowitych jako wyrażeń klauzuli ORDER BY.
Spotkasz się z podobną sytuacją, gdy spróbujesz połączyć dwa literały ciągu znaków, na przykład:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 'No' + ' Order') AS n FROM dbo.T1;
Pojawia się ten sam błąd, który pojawił się podczas bezpośredniego określania dosłownego „Brak zamówienia”:
Msg 5309, Level 16, State 1, Line 55Funkcje okienkowe, agregaty i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Świat Bizarro – błędy, które zapobiegają błędom
Życie jest pełne niespodzianek…
Jedną z rzeczy, która zapobiega ciągłemu składaniu, jest sytuacja, w której wyrażenie normalnie powodowałoby błąd. Na przykład wyrażenie 2147483646+1 może być składane na stałe, ponieważ daje w wyniku prawidłową wartość typu INT. W rezultacie próba uruchomienia następującego zapytania kończy się niepowodzeniem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483646+1) AS n FROM dbo.T1;Msg 5308, Level 16, State 1, Line 109
Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują indeksów liczb całkowitych jako wyrażeń klauzuli ORDER BY.
Jednak wyrażenie 2147483647+1 nie może być składane na stałe, ponieważ taka próba spowodowałaby błąd przepełnienia INT. Implikacja przy zamawianiu jest dość ciekawa. Wypróbuj następujące zapytanie (nazwiemy je Zapytanie 2):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 2147483647+1) AS n FROM dbo.T1;
Co dziwne, to zapytanie działa pomyślnie! Dzieje się tak, że z jednej strony SQL Server nie stosuje składania stałych, a zatem porządkowanie opiera się na wyrażeniu, które nie jest pojedynczą stałą. Z drugiej strony optymalizator stwierdza, że wartość porządkowania jest taka sama dla wszystkich wierszy, więc całkowicie ignoruje wyrażenie porządkowania. Zostało to potwierdzone podczas sprawdzania planu dla tego zapytania, jak pokazano na rysunku 3.
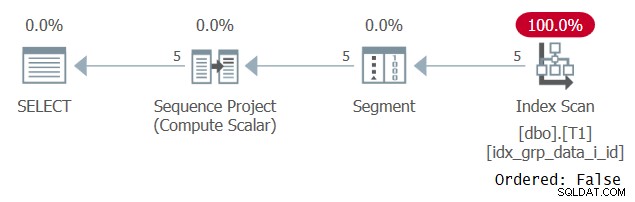 Rysunek 3:Plan dla zapytania 2
Rysunek 3:Plan dla zapytania 2
Zauważ, że plan skanuje indeks pokrywający z właściwością Ordered:False. To był dokładnie nasz cel dotyczący wydajności.
W podobny sposób następujące zapytanie obejmuje udaną próbę składania i dlatego kończy się niepowodzeniem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/1) AS n FROM dbo.T1;Msg 5308, Poziom 16, Stan 1, Wiersz 123
Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują indeksów liczb całkowitych jako wyrażeń klauzuli ORDER BY.
Następujące zapytanie wiąże się z nieudaną próbą stałego składania i dlatego kończy się pomyślnie, generując plan pokazany wcześniej na rysunku 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1/0) AS n FROM dbo.T1;
Poniższe zapytanie obejmuje udaną próbę złożenia stałej (literał VARCHAR '1' jest niejawnie konwertowany na INT 1, a następnie 1 + 1 jest składany do 2), a zatem kończy się niepowodzeniem:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'1') AS n FROM dbo.T1;Msg 5308, Poziom 16, Stan 1, Wiersz 134
Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują indeksów liczb całkowitych jako wyrażeń klauzuli ORDER BY.
Poniższe zapytanie obejmuje nieudaną próbę składania stałej (nie można przekonwertować 'A' na INT), a zatem kończy się pomyślnie, generując plan pokazany wcześniej na rysunku 3:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY 1+'A') AS n FROM dbo.T1;
Szczerze mówiąc, mimo że ta dziwaczna technika osiąga nasz pierwotny cel wydajności, nie mogę powiedzieć, że uważam ją za bezpieczną i dlatego nie czuję się tak komfortowo na niej polegać.
Stałe wykonawcze oparte na funkcjach
Kontynuując poszukiwania dobrego rozwiązania do obliczania numerów wierszy z niedeterministycznym porządkiem, istnieje kilka technik, które wydają się bezpieczniejsze niż ostatnie dziwaczne rozwiązanie:użycie stałych wykonawczych opartych na funkcjach, użycie podzapytania opartego na stałej, użycie aliasowanej kolumny opartej na stała i przy użyciu zmiennej.
Jak wyjaśniam w błędach, pułapkach i najlepszych praktykach T-SQL — determinizm — większość funkcji w T-SQL jest oceniana tylko raz na odwołanie w zapytaniu — nie raz na wiersz. Dzieje się tak nawet w przypadku większości niedeterministycznych funkcji, takich jak GETDATE i RAND. Istnieje bardzo niewiele wyjątków od tej reguły, takich jak funkcje NEWID i CRYPT_GEN_RANDOM, które są oceniane raz na wiersz. Większość funkcji, takich jak GETDATE, @@SPID i wiele innych, jest oceniana raz na początku zapytania, a ich wartości są następnie uznawane za stałe czasu wykonywania. Odwołanie do takich funkcji nie jest składane na stałe. Te cechy sprawiają, że stała czasu wykonania oparta na funkcji jest dobrym wyborem jako element porządkowania okien i rzeczywiście wydaje się, że obsługuje ją T-SQL. Jednocześnie optymalizator zdaje sobie sprawę, że w praktyce kolejność nie ma znaczenia, co pozwala uniknąć niepotrzebnych kar za wydajność.
Oto przykład użycia funkcji GETDATE:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY GETDATE()) AS n FROM dbo.T1;
To zapytanie otrzyma taki sam plan, jak pokazano wcześniej na rysunku 3.
Oto kolejny przykład użycia funkcji @@SPID (zwracając identyfikator bieżącej sesji):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @@SPID) AS n FROM dbo.T1;
A co z funkcją PI? Wypróbuj następujące zapytanie:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY PI()) AS n FROM dbo.T1;
Ten błąd kończy się następującym błędem:
Msg 5309, Poziom 16, Stan 1, Wiersz 153Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Funkcje takie jak GETDATE i @@SPID są ponownie oceniane raz na wykonanie planu, więc nie mogą być stale składane. PI reprezentuje zawsze tę samą stałą i dlatego zostaje złożona.
Jak wspomniano wcześniej, bardzo niewiele funkcji jest ocenianych raz na wiersz, takich jak NEWID i CRYPT_GEN_RANDOM. To sprawia, że są one złym wyborem jako element porządkujący okna, jeśli potrzebujesz niedeterministycznego porządku — nie mylić z porządkiem losowym. Po co płacić niepotrzebną karę sortowania?
Oto przykład użycia funkcji NEWID:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY NEWID()) AS n FROM dbo.T1;
Plan dla tego zapytania pokazano na rysunku 4, potwierdzając, że SQL Server dodał jawne sortowanie na podstawie wyniku funkcji.
 Rysunek 4:Plan dla zapytania 3
Rysunek 4:Plan dla zapytania 3
Jeśli chcesz, aby numery wierszy były przypisywane w kolejności losowej, za wszelką cenę, to jest to technika, której chcesz użyć. Musisz tylko mieć świadomość, że wiąże się to z kosztami sortowania.
Korzystanie z podzapytania
Możesz również użyć podzapytania opartego na stałej jako wyrażenia porządkującego okna (np. ORDER BY (SELECT 'Brak zamówienia')). Również w przypadku tego rozwiązania optymalizator SQL Server rozpoznaje, że kolejność nie ma znaczenia, a zatem nie narzuca niepotrzebnego sortowania ani nie ogranicza wyboru silnika pamięci masowej do tych, które muszą gwarantować porządek. Spróbuj uruchomić następujące zapytanie jako przykład:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'No Order')) AS n FROM dbo.T1;
Otrzymujesz taki sam plan, jak pokazano wcześniej na rysunku 3.
Jedną z wielkich zalet tej techniki jest to, że możesz dodać swój osobisty akcent. Może naprawdę lubisz wartości NULL:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS n FROM dbo.T1;
Może naprawdę lubisz określoną liczbę:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 42)) AS n FROM dbo.T1;
Może chcesz wysłać komuś wiadomość:
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY (SELECT 'Lilach, will you marry me?')) AS n FROM dbo.T1;
Masz rację.
Wykonalne, ale niezręczne
Jest kilka technik, które działają, ale są trochę niezręczne. Jednym z nich jest zdefiniowanie aliasu kolumny dla wyrażenia opartego na stałej, a następnie użycie tego aliasu kolumny jako elementu porządkującego okna. Można to zrobić za pomocą wyrażenia tabelowego lub operatora CROSS APPLY i konstruktora wartości tabeli. Oto przykład tego ostatniego:
SELECT id, grp, datacol,
ROW_NUMBER() OVER(ORDER BY [I'm a bit ugly]) AS n
FROM dbo.T1 CROSS APPLY ( VALUES('No Order') ) AS A([I'm a bit ugly]); Otrzymujesz taki sam plan, jak pokazano wcześniej na rysunku 3.
Inną opcją jest użycie zmiennej jako elementu porządkującego okna:
DECLARE @ImABitUglyToo AS INT = NULL; SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY @ImABitUglyToo) AS n FROM dbo.T1;
To zapytanie pobiera również plan pokazany wcześniej na rysunku 3.
Co jeśli użyję własnego UDF?
Możesz pomyśleć, że użycie własnego UDF, który zwraca stałą, może być dobrym wyborem jako elementu porządkującego okna, gdy chcesz uzyskać porządek niedeterministyczny, ale tak nie jest. Rozważ następującą definicję UDF jako przykład:
DROP FUNCTION IF EXISTS dbo.YouWillRegretThis; GO CREATE FUNCTION dbo.YouWillRegretThis() RETURNS INT AS BEGIN RETURN NULL END; GO
Spróbuj użyć UDF jako klauzuli porządkowania okien, w ten sposób (nazwiemy to zapytanie 4):
SELECT id, grp, datacol, ROW_NUMBER() OVER(ORDER BY dbo.YouWillRegretThis()) AS n FROM dbo.T1;
Przed SQL Server 2019 (lub równoległym poziomem zgodności <150) funkcje zdefiniowane przez użytkownika są oceniane na wiersz. Nawet jeśli zwracają stałą, nie są inline. W konsekwencji z jednej strony można użyć takiego UDF jako elementu porządkującego okna, ale z drugiej strony skutkuje to karą za sortowanie. Potwierdza to badanie planu dla tego zapytania, jak pokazano na rysunku 5.
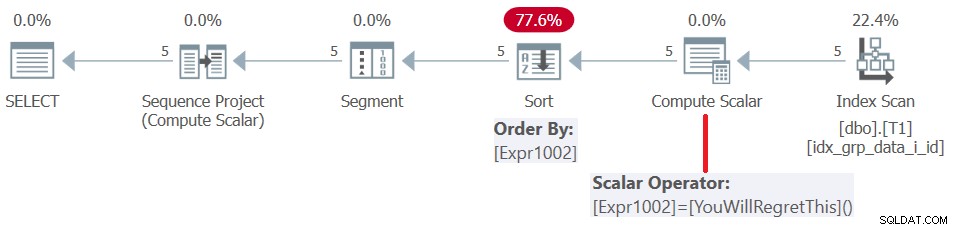 Rysunek 5:Plan dla zapytania 4
Rysunek 5:Plan dla zapytania 4
Począwszy od SQL Server 2019, przy poziomie zgodności>=150, takie funkcje zdefiniowane przez użytkownika są wbudowane, co w większości jest świetną rzeczą, ale w naszym przypadku skutkuje błędem:
Msg 5309, Poziom 16, Stan 1, Wiersz 217Funkcje okienkowe, agregacje i funkcje NEXT VALUE FOR nie obsługują stałych jako wyrażeń klauzuli ORDER BY.
Tak więc użycie UDF opartego na stałej jako elementu porządkującego okna wymusza sortowanie lub błąd w zależności od używanej wersji SQL Server i poziomu zgodności bazy danych. Krótko mówiąc, nie rób tego.
Podzielone na partycje numery wierszy o niedeterministycznej kolejności
Typowym przypadkiem użycia partycjonowanych numerów wierszy opartych na niedeterministycznej kolejności jest zwracanie dowolnego wiersza na grupę. Biorąc pod uwagę, że z definicji element oddzielający istnieje w tym scenariuszu, można by pomyśleć, że bezpieczną techniką w takim przypadku byłoby użycie elementu oddzielającego okno również jako elementu porządkującego okna. W pierwszym kroku obliczasz numery wierszy w następujący sposób:
SELECT id, grp, datacol, ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n FROM dbo.T1;
Plan dla tego zapytania pokazano na rysunku 6.
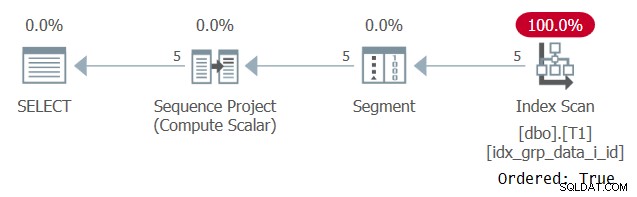 Rysunek 6:Plan dla zapytania 5
Rysunek 6:Plan dla zapytania 5
Powodem, dla którego nasz indeks pomocniczy jest skanowany za pomocą właściwości Ordered:True, jest to, że SQL Server musi przetwarzać wiersze każdej partycji jako pojedynczą jednostkę. Tak jest przed filtrowaniem. Jeśli filtrujesz tylko jeden wiersz na partycję, jako opcje dostępne są zarówno algorytmy oparte na kolejności, jak i na hash.
Drugim krokiem jest umieszczenie zapytania z obliczeniem numeru wiersza w wyrażeniu tabelowym, a w zapytaniu zewnętrznym filtrowanie wiersza z numerem wiersza 1 w każdej partycji, na przykład:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY grp) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Teoretycznie ta technika ma być bezpieczna, ale Paul white znalazł błąd, który pokazuje, że przy użyciu tej metody można uzyskać atrybuty z różnych wierszy źródłowych w zwróconym wierszu wyników na partycję. Używanie stałej czasu wykonywania opartej na funkcji lub podzapytaniu opartej na stałej, ponieważ element porządkujący wydaje się być bezpieczny nawet w tym scenariuszu, więc upewnij się, że zamiast tego używasz rozwiązania takiego jak:
WITH C AS
(
SELECT id, grp, datacol,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY (SELECT 'No Order')) AS n
FROM dbo.T1
)
SELECT id, grp, datacol
FROM C
WHERE n = 1; Nikt nie przejdzie tą drogą bez mojej zgody
Próba obliczenia numerów wierszy na podstawie niedeterministycznej kolejności jest powszechną potrzebą. Byłoby miło, gdyby T-SQL po prostu uczynił klauzulę kolejności okien opcjonalną dla funkcji ROW_NUMBER, ale tak nie jest. Jeśli nie, byłoby miło, gdyby przynajmniej zezwalało na użycie stałej jako elementu porządkującego, ale to też nie jest obsługiwana opcja. Ale jeśli poprosisz ładnie, w postaci podzapytania opartego na stałej lub stałej uruchomieniowej opartej na funkcji, SQL Server na to pozwoli. To są dwie opcje, z którymi czuję się najbardziej komfortowo. Naprawdę nie czuję się komfortowo z dziwacznymi błędnymi wyrażeniami, które wydają się działać, więc nie mogę polecić tej opcji.