Poniżej znajduje się zupa dla orzechów, jak skonfigurować i wdrożyć aplikację Django w Amazon Web Services (AWS), zachowując przy tym zdrowy rozsądek.
Stosowane narzędzia/technologie:
- Python v2.7.8
- Django v1.7
- Amazon Elastic Beanstalk, EC2, S3 i RDS
- EB CLI 3.x
- PostgreSQL
Teraz z Pythonem 3! Sprawdź zaktualizowaną wersję tego artykułu tutaj.
Ten artykuł został zaktualizowany, aby obejmował wdrażanie w Pythonie 3, ponieważ AWS ma teraz mnóstwo miłości do Pythona 3.
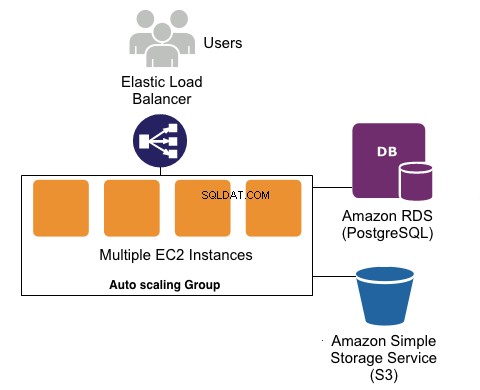
Elastyczna łodyga fasoli kontra EC2
Elastic Beanstalk to platforma jako usługa (PaaS), która usprawnia konfigurację, wdrażanie i konserwację Twojej aplikacji w Amazon AWS. Jest to usługa zarządzana, łącząca serwer (EC2), bazę danych (RDS) i pliki statyczne (S3). Możesz szybko wdrożyć aplikację i zarządzać nią, która automatycznie skaluje się wraz z rozwojem witryny. Sprawdź oficjalną dokumentację, aby uzyskać więcej informacji.
Pierwsze kroki
Będziemy używać prostej aplikacji „Obraz dnia”, którą możesz pobrać z tego repozytorium:
$ git clone https://github.com/realpython/image-of-the-day.git
$ cd image-of-the-day/
$ git checkout tags/start_here
Po pobraniu kodu utwórz virtualenv i zainstaluj wymagania przez pip:
$ pip install -r requirements.txt
Następnie, z PostgreSQL działającym lokalnie, skonfiguruj nową bazę danych o nazwie iotd . Ponadto, w zależności od lokalnej konfiguracji Postgres, może być konieczne zaktualizowanie DATABASES konfiguracja w settings.py .
Na przykład zaktualizowałem konfigurację do:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'iotd',
'USER': '',
'PASSWORD': '',
'HOST': 'localhost',
'PORT': '5432',
}
}
Teraz możesz skonfigurować schemat bazy danych, utworzyć administratora i uruchomić aplikację:
$ python manage.py migrate
$ python manage.py createsuperuser
$ python manage.py runserver
Przejdź do strony administratora w przeglądarce pod adresem https://localhost:8000/admin i dodaj nowy obraz, który zostanie wyświetlony na stronie głównej.
Aplikacja nie ma być bardzo ekscytująca; używamy go tylko do celów demonstracyjnych. Wszystko, co robi, to przesyłanie obrazu przez interfejs administratora i wyświetlanie go na pełnym ekranie na stronie głównej. To powiedziawszy, chociaż jest to stosunkowo podstawowa aplikacja, nadal pozwoli nam zbadać wiele „gotchas”, które istnieją podczas wdrażania w Amazon Beanstalk i RDS.
Teraz, gdy mamy już uruchomioną witrynę na naszym lokalnym komputerze, zacznijmy proces wdrażania Amazon.
CLI dla elastycznej fasoli AWS
Do pracy z Amazon Elastic Beanstalk możemy użyć pakietu o nazwie awsebcli. W chwili pisania tego tekstu najnowsza wersja to 3.0.10, a zalecany sposób instalacji to pip:
$ pip install awsebcli
Nie używaj brew do instalacji tego pakietu. W chwili pisania tego tekstu instaluje wersję 2.6.3, która jest zepsuta w subtelny sposób, co prowadzi do poważnej frustracji.
Teraz przetestuj instalację, aby upewnić się, że działa:
$ eb --version
Powinno to dać ładny numer wersji 3.x:
EB CLI 3.0.10 (Python 2.7.8)
Aby faktycznie zacząć korzystać z Elastic Beanstalk, potrzebujesz konta z AWS (niespodzianka!). Zarejestruj się (lub zaloguj).
Konfiguruj EB – zainicjuj swoją aplikację
Gdy AWS Elastic Beanstalk CLI działa, pierwszą rzeczą, którą chcemy zrobić, jest stworzenie środowiska Beanstalk, na którym będzie hostowana aplikacja. Uruchom to z katalogu projektu („obraz dnia”):
$ eb init
Spowoduje to wyświetlenie szeregu pytań, które pomogą Ci skonfigurować środowisko.
Region domyślny
Wybranie regionu najbliższego użytkownikom końcowym zapewni zazwyczaj najlepszą wydajność. Sprawdź tę mapę, jeśli nie masz pewności, którą wybrać.
Poświadczenia
Następnie poprosi o Twoje dane logowania do AWS.
Tutaj najprawdopodobniej będziesz chciał skonfigurować użytkownika uprawnień. Zobacz ten przewodnik, aby dowiedzieć się, jak go skonfigurować. Jeśli skonfigurujesz nowego użytkownika, musisz upewnić się, że ma on odpowiednie uprawnienia. Najprostszym sposobem, aby to zrobić, jest po prostu dodanie „Dostęp administratora” do użytkownika. (Prawdopodobnie nie jest to jednak najlepszy wybór ze względów bezpieczeństwa.) Aby poznać konkretne zasady/role, których użytkownik potrzebuje do tworzenia aplikacji Elastic Beanstalk/zarządzania nią, zobacz link tutaj.
Nazwa aplikacji
Będzie to domyślnie nazwa katalogu. Po prostu idź z tym.
Wersja Pythona
Następnie CLI powinien automagicznie wykryć, że używasz Pythona i po prostu poprosić o potwierdzenie. Powiedz tak. Następnie musisz wybrać wersję platformy. Wybierz Python 2.7 .
SSH
Powiedz tak, aby skonfigurować SSH dla swoich instancji.
Para kluczy RSA
Następnie musisz wygenerować parę kluczy RSA, która zostanie dodana do pliku ~/.ssh teczka. Ta para kluczy zostanie również przesłana do klucza publicznego EC2 dla regionu określonego w kroku pierwszym. Umożliwi to połączenie SSH z instancją EC2 w dalszej części tego samouczka.
Co osiągnęliśmy?
Raz eb init zostanie zakończony, zobaczysz nowy ukryty folder o nazwie .elasticbeanstalk w katalogu twojego projektu:
├── .elasticbeanstalk
│ └── config.yml
├── .gitignore
├── README.md
├── iotd
│ ├── images
│ │ ├── __init__.py
│ │ ├── admin.py
│ │ ├── migrations
│ │ │ ├── 0001_initial.py
│ │ │ └── __init__.py
│ │ ├── models.py
│ │ ├── tests.py
│ │ └── views.py
│ ├── iotd
│ │ ├── __init__.py
│ │ ├── settings.py
│ │ ├── urls.py
│ │ └── wsgi.py
│ ├── manage.py
│ ├── static
│ │ ├── css
│ │ │ └── bootstrap.min.css
│ │ └── js
│ │ ├── bootstrap.min.js
│ │ └── jquery-1.11.0.min.js
│ └── templates
│ ├── base.html
│ └── images
│ └── home.html
├── requirements.txt
└── www
└── media
└── sitelogo.png
Wewnątrz tego katalogu znajduje się config.yml plik, który jest plikiem konfiguracyjnym używanym do definiowania pewnych parametrów dla nowo powstałej aplikacji Beanstalk.
W tym momencie, jeśli wpiszesz eb console otworzy domyślną przeglądarkę i przejdzie do konsoli Elastic Beanstalk. Na stronie powinieneś zobaczyć jedną aplikację (o nazwie image-of-the-day jeśli dokładnie podążasz), ale żadnych środowisk.
Aplikacja reprezentuje aplikację kodu i jest tym, co eb init stworzony dla nas. Dzięki Elastic Beanstalk aplikacja może mieć wiele środowisk (tj. programistycznych, testowych, pomostowych, produkcyjnych). Od Ciebie zależy, jak chcesz skonfigurować/zarządzać tymi środowiskami. W przypadku prostych aplikacji Django lubię mieć środowisko programistyczne na moim laptopie, a następnie tworzyć środowisko testowe i produkcyjne na Beanstalk.
Skonfigurujmy środowisko testowe…
Konfiguruj EB — stwórz środowisko
Wracając do terminala, w katalogu projektu wpisz:
$ eb create
Podobnie jak eb init , to polecenie wyświetli serię pytań.
Nazwa środowiska
Powinieneś użyć podobnej konwencji nazewnictwa do tego, co sugeruje Amazon – np. nazwa_aplikacji-nazwa_środowiska – zwłaszcza gdy/jeśli zaczniesz hostować wiele aplikacji za pomocą AWS. Użyłem - iod-test .
Prefiks DNS CNAME
Po wdrożeniu aplikacji w Elastic Beanstalk automatycznie otrzymasz nazwę domeny, taką jak xxx.elasticbeanstalk.com. DNS CNAME prefix jest tym, co chcesz użyć zamiast xxx . Po prostu wybierz ustawienie domyślne.
Co się teraz dzieje?
W tym momencie eb faktycznie stworzy dla Ciebie Twoje środowisko. Bądź cierpliwy, ponieważ może to zająć trochę czasu.
Jeśli pojawi się błąd podczas tworzenia środowiska, na przykład - aws.auth.client.error.ARCInstanceIdentityProfileNotFoundException - sprawdź, czy poświadczenia, których używasz, mają odpowiednie uprawnienia do tworzenia środowiska Beanstalk, jak omówiono wcześniej w tym poście.
Natychmiast po utworzeniu środowiska eb spróbuje wdrożyć Twoją aplikację, kopiując cały kod z katalogu projektu do nowej instancji EC2, uruchamiając pip install -r requirements.txt w trakcie.
Powinieneś zobaczyć kilka informacji o konfigurowanym środowisku wyświetlanych na ekranie, a także informacje o eb próbuje wdrożyć. Zobaczysz również kilka błędów. W szczególności powinieneś zobaczyć te wiersze ukryte gdzieś w danych wyjściowych:
ERROR: Your requirements.txt is invalid. Snapshot your logs for details.
Nie martw się - to naprawdę nie jest nieważne. Sprawdź dzienniki, aby uzyskać szczegółowe informacje:
$ eb logs
Spowoduje to pobranie wszystkich ostatnich plików dziennika z instancji EC2 i przesłanie ich do terminala. To dużo informacji, więc możesz chcieć przekierować dane wyjściowe do pliku (eb logs -z ). Przeglądając dzienniki, zobaczysz jeden plik dziennika o nazwie eb-activity.log :
Error: pg_config executable not found.
Problem polega na tym, że próbowaliśmy zainstalować psycopy2 (powiązania Postgres Python), ale musimy również zainstalować sterowniki klienta Postgres. Ponieważ nie są one domyślnie instalowane, musimy je najpierw zainstalować. Naprawmy to…
Dostosowywanie procesu wdrażania
eb odczyta niestandardowy plik .config pliki z folderu o nazwie „.ebextensions” na głównym poziomie projektu (katalog „image-of-the-day”). Te .config pliki umożliwiają instalowanie pakietów, uruchamianie dowolnych poleceń i/lub ustawianie zmiennych środowiskowych. Pliki w katalogu „.ebextensions” powinny być zgodne z JSON lub YAML składni i są wykonywane w kolejności alfabetycznej.
Instalowanie pakietów
Pierwszą rzeczą, którą musimy zrobić, to zainstalować kilka pakietów, aby nasza pip install polecenie zakończy się pomyślnie. Aby to zrobić, utwórzmy najpierw plik o nazwie .ebextensions/01_packages.config :
packages:
yum:
git: []
postgresql93-devel: []
Instancje EC2 działają pod kontrolą systemu Amazon Linux, który jest odmianą Redhata, więc możemy użyć yum do zainstalowania potrzebnych nam pakietów. Na razie zainstalujemy tylko dwa pakiety - git i klienta Postgres.
Po utworzeniu tego pliku w celu ponownego wdrożenia aplikacji musimy wykonać następujące czynności:
$ git add .ebextensions/
$ git commit -m "added eb package configuration"
Musimy zatwierdzić zmiany, ponieważ polecenie wdrażania eb deploy działa od ostatniego zatwierdzenia i dlatego będzie świadomy zmian w naszych plikach dopiero po zatwierdzeniu ich w git. (Pamiętaj jednak, że nie musimy naciskać; pracujemy z naszej lokalnej kopii…)
Jak zapewne zgadłeś, następne polecenie to:
$ eb deploy
Powinieneś teraz zobaczyć tylko jeden błąd:
INFO: Environment update is starting.
INFO: Deploying new version to instance(s).
ERROR: Your WSGIPath refers to a file that does not exist.
INFO: New application version was deployed to running EC2 instances.
INFO: Environment update completed successfully.
Dowiedzmy się, co się dzieje…
Konfigurowanie naszego środowiska Python
Instancje EC2 w Beanstalk uruchamiają Apache, a Apache znajdzie naszą aplikację Pythona zgodnie z ustawionym przez nas WSGIPATH. Domyślnie eb zakłada, że nasz plik wsgi nazywa się application.py . Istnieją dwa sposoby na poprawienie tego-
Opcja 1:korzystanie z ustawień konfiguracji specyficznych dla środowiska
$ eb config
To polecenie otworzy domyślny edytor, edytując plik konfiguracyjny o nazwie .elasticbeanstalk/iod-test.env.yml . Ten plik w rzeczywistości nie istnieje lokalnie; eb ściągnąłem go z serwerów AWS i przedstawiłem, abyś mógł zmienić w nim ustawienia. Jeśli dokonasz jakichkolwiek zmian w tym pseudopliku, a następnie zapiszesz i wyjdziesz, eb zaktualizuje odpowiednie ustawienia w Twoim środowisku Beanstalk.
Jeśli szukasz w pliku terminów „WSGI” i powinieneś znaleźć sekcję konfiguracji, która wygląda tak:
aws:elasticbeanstalk:container:python:
NumProcesses: '1'
NumThreads: '15'
StaticFiles: /static/=static/
WSGIPath: application.py
Zaktualizuj ścieżkę WSGIPath:
aws:elasticbeanstalk:container:python:
NumProcesses: '1'
NumThreads: '15'
StaticFiles: /static/=static/
WSGIPath: iotd/iotd/wsgi.py
A potem będziesz miał poprawnie skonfigurowany WSGIPath. Jeśli następnie zapiszesz plik i wyjdziesz, eb automatycznie zaktualizuje konfigurację środowiska:
Printing Status:
INFO: Environment update is starting.
INFO: Updating environment iod-test's configuration settings.
INFO: Successfully deployed new configuration to environment.
INFO: Environment update completed successfully.
Zaleta korzystania z eb config Metoda zmiany ustawień polega na tym, że można określić różne ustawienia dla środowiska. Ale możesz także zaktualizować ustawienia za pomocą tego samego pliku .config pliki, których używaliśmy wcześniej. Spowoduje to użycie tych samych ustawień dla każdego środowiska, jak w pliku .config pliki zostaną zastosowane podczas wdrażania (po ustawieniach z eb config zostały zastosowane).
Opcja 2:korzystanie z globalnych ustawień konfiguracji
Aby użyć .config opcję pliku, utwórzmy nowy plik o nazwie /.ebextensions/02_python.config :
option_settings:
"aws:elasticbeanstalk:application:environment":
DJANGO_SETTINGS_MODULE: "iotd.settings"
"PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"
"aws:elasticbeanstalk:container:python":
WSGIPath: iotd/iotd/wsgi.py
NumProcesses: 3
NumThreads: 20
"aws:elasticbeanstalk:container:python:staticfiles":
"/static/": "www/static/"
Co się dzieje?
DJANGO_SETTINGS_MODULE: "iotd.settings"- dodaje ścieżkę do modułu ustawień."PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"- aktualizuje nasząPYTHONPATHaby Python mógł znaleźć moduły w naszej aplikacji. (Zauważ, że użycie pełnej ścieżki jest konieczne.)WSGIPath: iotd/iotd/wsgi.pyustala naszą ścieżkę WSGI.NumProcesses: 3iNumThreads: 20- aktualizuje liczbę procesów i wątków używanych do uruchomienia naszej aplikacji WSGI."/static/": "www/static/"ustawia ścieżkę naszych plików statycznych.
Ponownie, możemy wykonać git commit następnie eb deploy aby zaktualizować te ustawienia.
Następnie dodajmy bazę danych.
Konfigurowanie bazy danych
Spróbuj wyświetlić wdrożoną witrynę:
$ eb open
To polecenie pokaże wdrożoną aplikację w domyślnej przeglądarce. Powinieneś zobaczyć błąd odmowy połączenia:
OperationalError at /
could not connect to server: Connection refused
Is the server running on host "localhost" (127.0.0.1) and accepting
TCP/IP connections on port 5432?
Dzieje się tak, ponieważ nie skonfigurowaliśmy jeszcze bazy danych. W tym momencie eb skonfiguruje środowisko Beanstalk, ale nie skonfiguruje RDS (warstwy bazy danych). Musimy to ustawić ręcznie.
Konfiguracja bazy danych
Ponownie użyj eb console aby otworzyć stronę konfiguracji Beanstalk.
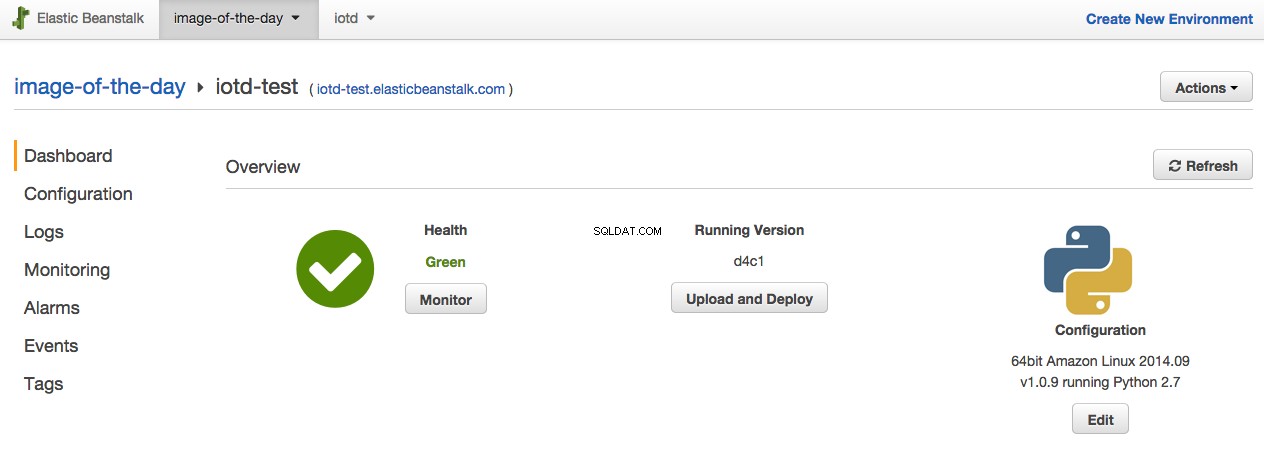
Następnie wykonaj następujące czynności:
- Kliknij link „Konfiguracja”.
- Przewiń do samego dołu strony, a następnie w sekcji „Poziom danych” kliknij link „utwórz nową bazę danych RDS”.
- Na stronie konfiguracji RDS zmień „DB Engine” na „postgres”.
- Dodaj „Nazwę użytkownika głównego” i „Hasło główne”.
- Zapisz zmiany.
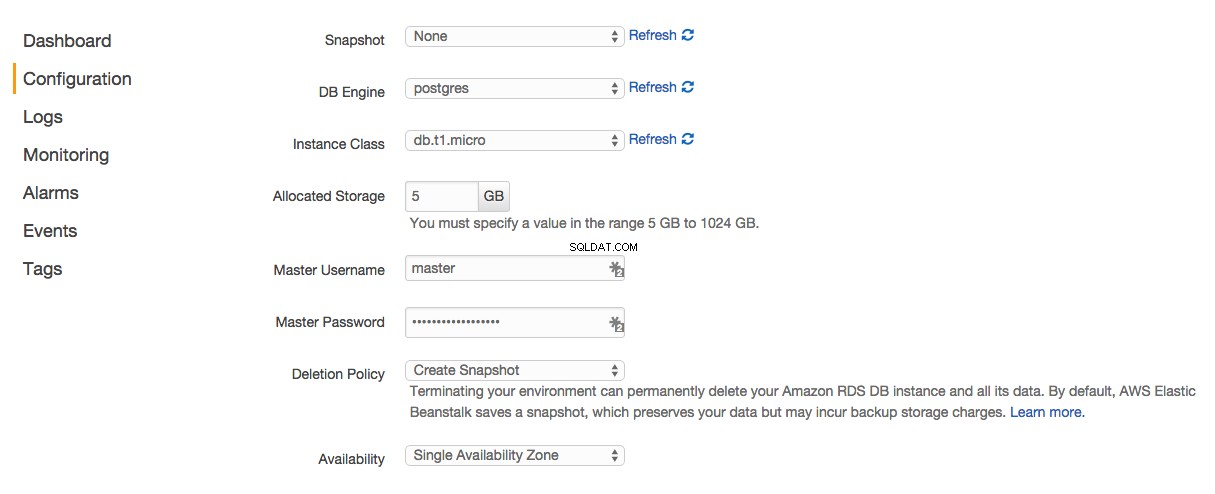
Beanstalk stworzy dla Ciebie RDS. Teraz musimy pobrać naszą aplikację Django, aby połączyć się z RDS. Beanstalk pomoże nam w tym, udostępniając nam szereg zmiennych środowiskowych w instancjach EC2, które szczegółowo opisują sposób łączenia się z serwerem Postgres. Wszystko, co musimy zrobić, to zaktualizować nasz settings.py plik, aby skorzystać z tych zmiennych środowiskowych. Potwierdź, że DATABASES parametr konfiguracyjny odzwierciedla następujące elementy w settings.py :
if 'RDS_DB_NAME' in os.environ:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': os.environ['RDS_DB_NAME'],
'USER': os.environ['RDS_USERNAME'],
'PASSWORD': os.environ['RDS_PASSWORD'],
'HOST': os.environ['RDS_HOSTNAME'],
'PORT': os.environ['RDS_PORT'],
}
}
else:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'iotd',
'USER': 'iotd',
'PASSWORD': 'iotd',
'HOST': 'localhost',
'PORT': '5432',
}
}
To po prostu mówi:„Użyj ustawień zmiennych środowiskowych, jeśli są obecne, w przeciwnym razie użyj naszych domyślnych ustawień programistycznych”. Proste.
Obsługa migracji baz danych
Przy naszej konfiguracji bazy danych nadal musimy upewnić się, że migracje są przeprowadzane, aby struktura tabeli bazy danych była poprawna. Możemy to zrobić, modyfikując .ebextensions/02_python.config i dodając następujące wiersze na górze pliku:
container_commands:
01_migrate:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput"
leader_only: true
container_commands umożliwiają uruchamianie dowolnych poleceń po wdrożeniu aplikacji na instancji EC2. Ponieważ instancja EC2 jest skonfigurowana przy użyciu środowiska wirtualnego, musimy najpierw aktywować to środowisko wirtualne przed uruchomieniem polecenia migracji. Również leader_only: true ustawienie oznacza „Uruchom to polecenie tylko w pierwszej instancji podczas wdrażania w wielu instancjach”.
Nie zapominaj, że nasza aplikacja korzysta z administratora Django, więc będziemy potrzebować superużytkownika…
Utwórz użytkownika administratora
Niestety createsuperuser nie pozwala na określenie hasła podczas korzystania z --noinput opcja, więc będziemy musieli napisać własne polecenie. Na szczęście Django bardzo ułatwia tworzenie niestandardowych poleceń.
Utwórz plik iotd/images/management/commands/createsu.py :
from django.core.management.base import BaseCommand
from django.contrib.auth.models import User
class Command(BaseCommand):
def handle(self, *args, **options):
if not User.objects.filter(username="admin").exists():
User.objects.create_superuser("admin", "admin@admin.com", "admin")
Upewnij się, że dodałeś odpowiedni __init__.py również pliki:
└─ management
├── __init__.py
└── commands
├── __init__.py
└── createsu.py
Ten plik pozwoli Ci uruchomić python manage.py createsu , i utworzy superużytkownika bez pytania o hasło. Możesz rozszerzyć polecenie, aby używać zmiennych środowiskowych lub innych środków umożliwiających zmianę hasła.
Po utworzeniu polecenia możemy po prostu dodać kolejne polecenie do naszych container_commands sekcja w .ebextensions/02_python.config :
02_createsu:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu"
leader_only: true
Zanim to przetestujesz, upewnijmy się, że wszystkie nasze pliki statyczne są umieszczone we właściwym miejscu…
Pliki statyczne
Dodaj jeszcze jedno polecenie w container_commands :
03_collectstatic:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput"
Cały plik wygląda więc tak:
container_commands:
01_migrate:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py migrate --noinput"
leader_only: true
02_createsu:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py createsu"
leader_only: true
03_collectstatic:
command: "source /opt/python/run/venv/bin/activate && python iotd/manage.py collectstatic --noinput"
option_settings:
"aws:elasticbeanstalk:application:environment":
DJANGO_SETTINGS_MODULE: "iotd.settings"
"PYTHONPATH": "/opt/python/current/app/iotd:$PYTHONPATH"
"ALLOWED_HOSTS": ".elasticbeanstalk.com"
"aws:elasticbeanstalk:container:python":
WSGIPath: iotd/iotd/wsgi.py
NumProcesses: 3
NumThreads: 20
"aws:elasticbeanstalk:container:python:staticfiles":
"/static/": "www/static/"
Musimy teraz upewnić się, że STATIC_ROOT jest prawidłowo ustawiony w settings.py plik:
STATIC_ROOT = os.path.join(BASE_DIR, "..", "www", "static")
STATIC_URL = '/static/'
Upewnij się, że zatwierdziłeś www do git, aby można było utworzyć katalog statyczny. Następnie uruchom eb deploy znowu, a teraz powinieneś być w biznesie:
INFO: Environment update is starting.
INFO: Deploying new version to instance(s).
INFO: New application version was deployed to running EC2 instances.
INFO: Environment update completed successfully.
W tym momencie powinieneś być w stanie przejść do https://your_app_url/admin, zalogować się, dodać obraz, a następnie zobaczyć ten obraz wyświetlany na głównej stronie aplikacji.
Sukces!
Korzystanie z S3 do przechowywania multimediów
Dzięki tej konfiguracji za każdym razem, gdy ponownie wdrożymy, stracimy wszystkie przesłane obrazy. Czemu? Cóż, po uruchomieniu eb deploy , uruchomiona zostanie nowa instancja. Nie tego chcemy, ponieważ wtedy będziemy mieć wpisy w bazie danych dla obrazów, ale żadnych powiązanych obrazów. Rozwiązaniem jest przechowywanie plików multimedialnych w Amazon Simple Storage Service (Amazon S3) zamiast w samej instancji EC2.
Będziesz musiał:
- Utwórz zasobnik
- Zdobądź ARN (nazwa zasobu Amazon) użytkownika
- Dodaj uprawnienia zasobnika
- Skonfiguruj swoją aplikację Django, aby używała S3 do obsługi plików statycznych
Ponieważ są już dobre opisy na ten temat, wskażę ci mój ulubiony:Używam Amazon S3 do przechowywania plików statycznych i multimedialnych Django
Konfiguracja Apache
Ponieważ używamy Apache z Beanstalk, prawdopodobnie chcemy skonfigurować Apache, aby (między innymi) włączyć kompresję gzip, aby klienci mogli szybciej pobierać pliki. Można to zrobić za pomocą container_commands . Utwórz nowy plik .ebextensions/03_apache.config i dodaj następujące:
container_commands:
01_setup_apache:
command: "cp .ebextensions/enable_mod_deflate.conf /etc/httpd/conf.d/enable_mod_deflate.conf"
Następnie musisz utworzyć plik .ebextensions/enable_mod_deflate.conf :
# mod_deflate configuration
<IfModule mod_deflate.c>
# Restrict compression to these MIME types
AddOutputFilterByType DEFLATE text/plain
AddOutputFilterByType DEFLATE text/html
AddOutputFilterByType DEFLATE application/xhtml+xml
AddOutputFilterByType DEFLATE text/xml
AddOutputFilterByType DEFLATE application/xml
AddOutputFilterByType DEFLATE application/xml+rss
AddOutputFilterByType DEFLATE application/x-javascript
AddOutputFilterByType DEFLATE text/javascript
AddOutputFilterByType DEFLATE text/css
# Level of compression (Highest 9 - Lowest 1)
DeflateCompressionLevel 9
# Netscape 4.x has some problems.
BrowserMatch ^Mozilla/4 gzip-only-text/html
# Netscape 4.06-4.08 have some more problems
BrowserMatch ^Mozilla/4\.0[678] no-gzip
# MSIE masquerades as Netscape, but it is fine
BrowserMatch \bMSI[E] !no-gzip !gzip-only-text/html
<IfModule mod_headers.c>
# Make sure proxies don't deliver the wrong content
Header append Vary User-Agent env=!dont-vary
</IfModule>
</IfModule>
Spowoduje to włączenie kompresji gzip, która powinna pomóc w rozmiarze pobieranych plików. Możesz również użyć tej samej strategii, aby automatycznie zminimalizować i połączyć CSS/JS oraz wykonać dowolne inne przetwarzanie wstępne, które musisz zrobić.
Rozwiązywanie problemów
Nie zapomnij o bardzo pomocnym eb ssh polecenie, które przeniesie Cię do instancji EC2, dzięki czemu będziesz mógł przeglądać i sprawdzać, co się dzieje. Podczas rozwiązywania problemów należy pamiętać o kilku katalogach:
/opt/python- Korzeń miejsca, w którym skończy się aplikacja./opt/python/current/app- Aktualna aplikacja hostowana w środowisku./opt/python/on-deck/app- Aplikacja jest początkowo umieszczana na pokładzie, a następnie, po zakończeniu całego wdrożenia, zostanie przeniesiona docurrent. Jeśli otrzymujesz błędy w swoichcontainer_commands, sprawdźon-deckfolder, a niecurrentfolder./opt/python/current/env- Wszystkie zmienne env, któreebskonfiguruje się dla Ciebie. Jeśli próbujesz odtworzyć błąd, możesz najpierw potrzebowaćsource /opt/python/current/envaby ustawić rzeczy tak, jak byłyby, gdy działa eb Deployment.opt/python/run/venv- Wirtualne środowisko używane przez Twoją aplikację; musisz także uruchomićsource /opt/python/run/venv/bin/activatejeśli próbujesz odtworzyć błąd
Wniosek
Wdrożenie do Elastic Beanstalk na początku może być nieco zniechęcające, ale kiedy zrozumiesz, gdzie są wszystkie części i jak wszystko działa, jest to całkiem łatwe i niezwykle elastyczne. Zapewnia również środowisko, które będzie się automatycznie skalować wraz ze wzrostem użytkowania. Mam nadzieję, że masz już dość, by być niebezpiecznym! Powodzenia w kolejnym wdrożeniu Beanstalk.
Czy coś przeoczyliśmy? Masz inne wskazówki lub triki? Proszę o komentarz poniżej.