W zeszłym roku Andy Mallon napisał na blogu o rozbudowie kolumny z int do bigint bez przestojów. (Dlaczego nie jest to operacja tylko na metadanych we współczesnych wersjach SQL Server, jest poza mną, ale to kolejny post.)
Zwykle, gdy mamy do czynienia z tym problemem, są to szerokie i ogromne tabele (zarówno pod względem liczby wierszy, jak i samego rozmiaru), a kolumna, którą musimy zmienić, jest jedyną/wiodącą kolumną w kluczu klastrowania. Zwykle występują również inne komplikacje — ograniczenia dotyczące kluczy obcych przychodzących, wiele nieklastrowanych indeksów i zajęta baza danych, która jest bardzo wrażliwa na aktywność dzienników (ponieważ jest zaangażowana w śledzenie zmian, replikację, grupy dostępności lub wszystkie trzy ).
Z tego powodu musimy przyjąć podejście takie, jak opisał Andy, w którym tworzymy tabelę cieni z nowym schematem, tworzymy wyzwalacze, aby synchronizować obie kopie, a następnie wsadowo/wypełniamy we własnym tempie, dopóki zespół nie będzie gotowy do wymiany w kopii jako prawdziwa okazja.
Ale jestem leniwy!
W niektórych przypadkach możesz zmienić kolumnę bezpośrednio, jeśli możesz sobie pozwolić na mały okres przestoju/blokowania, i staje się to znacznie prostszą operacją. W zeszłym tygodniu pojawił się jeden taki przypadek, z tabelą ponad 1 TB, ale tylko 100 000 wierszy. Prawie wszystkie dane były poza wierszem (LOB), w razie potrzeby mogli sobie pozwolić na krótki okres przestoju, a mimo to planowali wyłączyć śledzenie zmian i ponownie je skonfigurować. Przekonany, że ponowne utworzenie klastra PK nie będzie musiało dotykać danych LOB (dużo), zasugerowałem, że może to być przypadek, w którym możemy po prostu zastosować zmianę bezpośrednio.
W wyizolowanym scenariuszu (bez przychodzących kluczy obcych, bez dodatkowych indeksów, bez działań zależnych od czytnika dziennika i bez obaw o współbieżność), zebrałem razem kilka testów, aby zobaczyć, w próżni, czego ta zmiana wymagałaby pod względem czasu trwania i wpływ na dziennik transakcji. Główne pytanie, na które nie wiedziałem, jak odpowiedzieć z góry, brzmiało:„Jaki jest przyrostowy koszt aktualizacji tabel w miejscu, gdy istnieje duża ilość danych, które nie są kluczowe?”
Postaram się zapakować dużo w jeden post tutaj. Zrobiłem wiele testów i są one powiązane, nawet jeśli nie wszystkie scenariusze testowe dotyczą Ciebie. Proszę o wyrozumiałość.
Stoły
Utworzyłem 6 tabel, w tym linię bazową, która tylko miał kolumnę klucza, jedną tabelę z 4K przechowywanymi w wierszu, a następnie cztery tabele, każda z kolumną varchar(max) wypełnioną różnymi ilościami danych ciągów (4K, 16K, 64K i 256K).
CREATE TABLE dbo.withJustId
(
id int NOT NULL,
CONSTRAINT pk_withJustId PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withoutLob
(
id int NOT NULL,
extradata varchar(4000) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withoutLob PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob004
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE('x', 4000)),
CONSTRAINT pk_withLob004 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob016
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 16000)),
CONSTRAINT pk_withLob016 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob064
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 64000)),
CONSTRAINT pk_withLob064 PRIMARY KEY CLUSTERED (id)
);
CREATE TABLE dbo.withLob256
(
id int NOT NULL,
extradata varchar(max) NOT NULL DEFAULT (REPLICATE(CONVERT(varchar(max),'x'), 256000)),
CONSTRAINT pk_withLob256 PRIMARY KEY CLUSTERED (id)
); Wypełniłem każdy z 100 000 wierszy:
INSERT dbo.withJustId (id) SELECT TOP (100000) id = ROW_NUMBER() OVER (ORDER BY c1.name) FROM sys.all_columns AS c1 CROSS JOIN sys.all_objects; INSERT dbo.withoutLob (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob004 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob016 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob064 (id) SELECT id FROM dbo.withJustId; INSERT dbo.withLob256 (id) SELECT id FROM dbo.withJustId;
Przyznaję, że powyższe jest nierealne; jak często mamy tabelę, która jest tylko identyfikatorem + dane LOB? Przeprowadziłem testy ponownie z tymi dodatkowymi czterema kolumnami, aby nadać stronom danych innych niż LOB trochę bardziej rzeczywistej treści:
fill1 char(320) NOT NULL DEFAULT ('x'),
count1 int NOT NULL DEFAULT (0),
count2 int NOT NULL DEFAULT (0),
dt datetime2 NOT NULL DEFAULT sysutcdatetime(), Te tabele są tylko nieco większe pod względem ogólnego rozmiaru, ale proporcjonalny wzrost ilości danych innych niż LOB (niezilustrowany na tym wykresie) jest dużą, ale ukrytą różnicą:
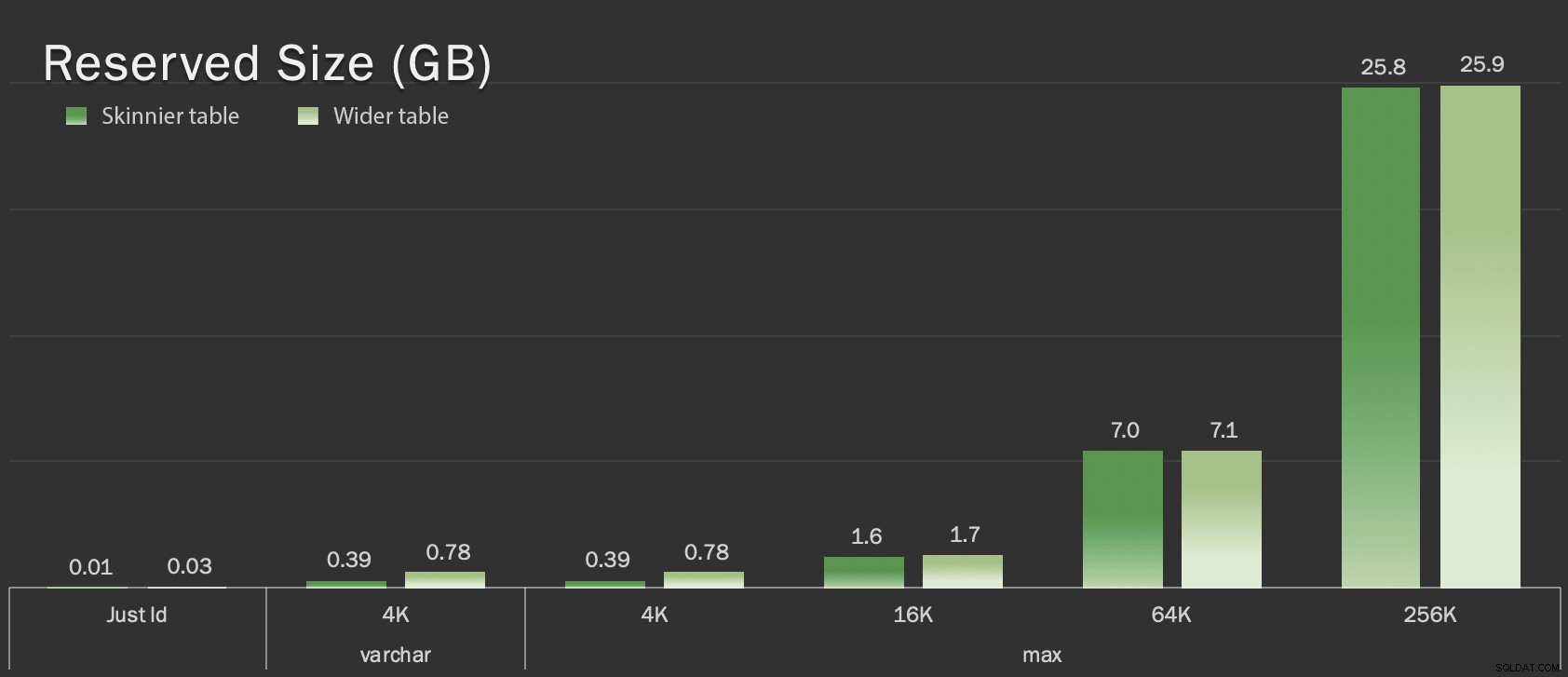 Zarezerwowany rozmiar tabel w GB
Zarezerwowany rozmiar tabel w GB
Testy
Następnie zmierzyłem i zebrałem dane dziennika dla każdej z tych operacji (z i bez ONLINE = ON ) z każdą odmianą tabeli:
ALTER TABLE dbo.<name> DROP CONSTRAINT pk_<name>; ALTER TABLE dbo.<name> ALTER COLUMN id bigint NOT NULL; -- WITH (ONLINE = ON); ALTER TABLE dbo.<name> ADD CONSTRAINT pk_<name> PRIMARY KEY CLUSTERED (id);
W rzeczywistości użyłem dynamicznego SQL do wygenerowania wszystkich tych testów, więc nie musiałem ręcznie majstrować przy skryptach przed każdym testem.
W innym poście podzielę się dynamicznym kodem SQL, którego użyłem do wygenerowania tych testów, i zbierzę czasy na każdym kroku.
Dla porównania przetestowałem też metodę Andy'ego (choć bez wsadów i tylko na chudej wersji stołu):
CREATE TABLE dbo.<name>_copy ( id bigint NOT NULL -- <, extradata column when relevant > CONSTRAINT pk_copy_<name> PRIMARY KEY CLUSTERED (id)); INSERT dbo.<name>_copy SELECT * FROM dbo.<name>; EXEC sys.sp_rename N'dbo.<name>', N'dbo.<name>_old', N'OBJECT'; EXEC sys.sp_rename N'dbo.<name>_copy', N'dbo.<name>', N'OBJECT';
Pominąłem tutaj szersze stoły; Nie chciałem wprowadzać złożoności kodowania i mierzenia operacji wsadowych. Oczywistym problemem jest tutaj to, że w przeciwieństwie do zmiany kolumny w miejscu, w przypadku metody cienia musisz skopiować każdy bajt danych LOB. Grupowanie może zminimalizować duży wpływ próby zrobienia tego w jednej transakcji, ale całe to tasowanie będzie ostatecznie musiało zostać powtórzone w dół strumienia. Grupowanie u źródła nie może całkowicie kontrolować tego, jak bardzo zaszkodzi w miejscu docelowym.
Wyniki
Pierwsze wyniki, które przedstawię, to tylko średnie czasy trwania zmian w miejscu, dla wszystkich 12 konfiguracji stołów oraz z ONLINE = ON i bez niego :
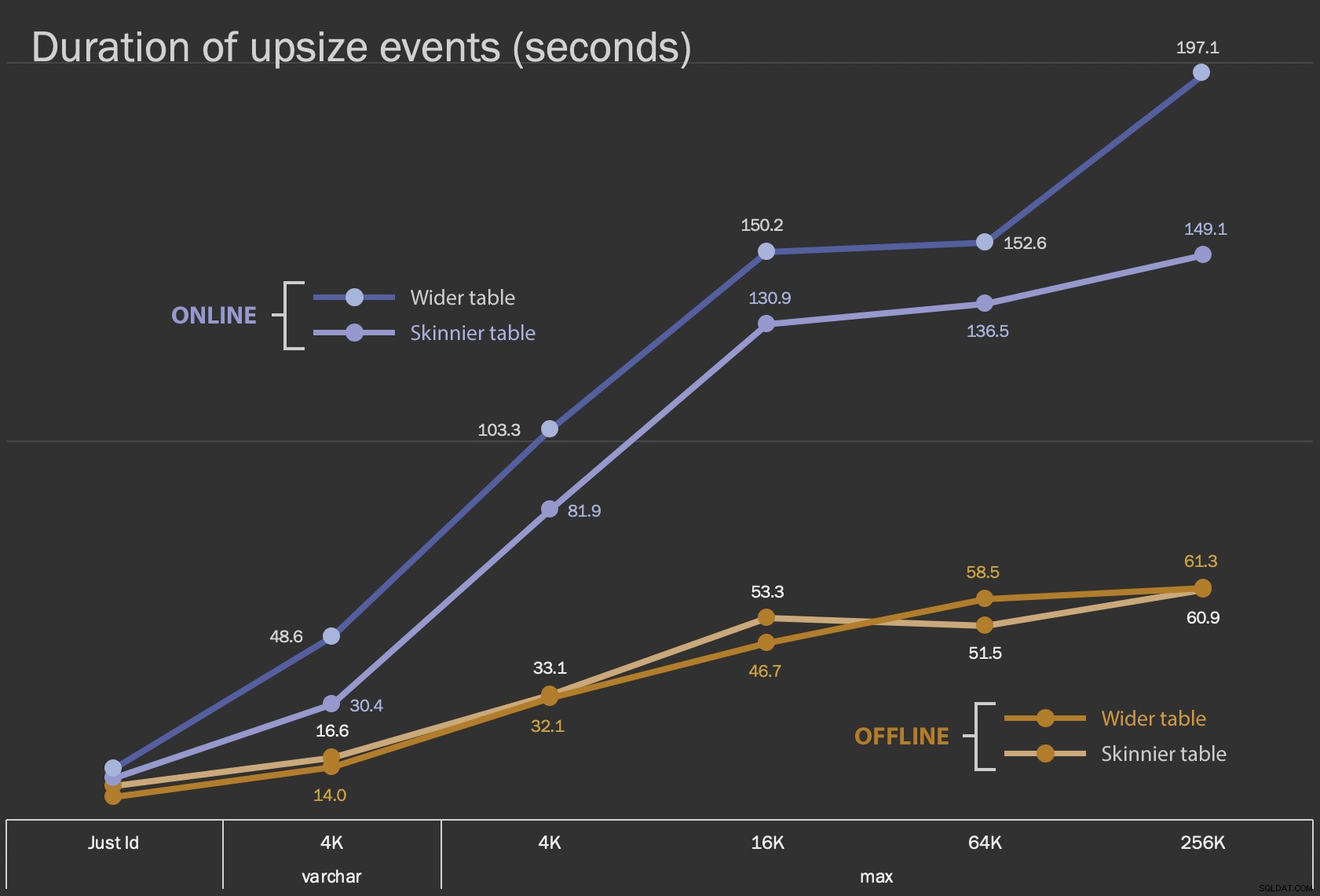 Czas (w sekundach) zmiany kolumny w miejscu
Czas (w sekundach) zmiany kolumny w miejscu
Wykonanie tego jako operacji online zajmuje więcej czasu (200 sekund w najgorszym przypadku), ale nie blokuje użytkowników. Wydaje się, że rośnie wraz z rozmiarem, ale nie całkiem liniowo. Wykonywanie tej operacji w trybie offline powoduje blokowanie, ale jest znacznie szybsze i nie zmienia się tak drastycznie, jak tabela się powiększa (nawet przy największym rozmiarze, nadal trwało to około minuty).
Porównanie tych operacji w miejscu z operacją wymiany i upuszczania jest trudne przy użyciu wykresu liniowego ze względu na ogromną różnicę w skali. Zamiast tego pokażę poziomy wykres słupkowy dla czasu trwania każdej konfiguracji tabeli. Gdy odtwarzanie jest szybsze, pomaluję tło tego wiersza na zielono; kiedy jest wolniejszy (lub mieści się pomiędzy metodami offline i online), prawdopodobnie nie muszę, ale pomaluję tło tego wiersza na czerwono.
| rozmiar LOB | Podejście | Konfiguracja tabeli | Czas trwania (sekundy) | ||
|---|---|---|---|
| Tylko identyfikator | ZMIEŃ tryb offline | Stół Skinnier (10 MB) | 8.8 |
| Większa tabela (30 MB) | 6.3 | ||
| ALTER Online | Węższy stół | 11,0 | |
| Szersza tabela | 13,6 | ||
| Odtwórz | Węższy stół | 3.4 | |
| varchar 4K | Offline | Stół Skinnier (390 MB) | 16,6 |
| Szersza tabela (780 MB) | 14,0 | ||
| Online | Węższy stół | 30.4 | |
| Szersza tabela | 48,6 | ||
| Odtwórz | Węższy stół | 1290,0 | |
| maks. 4k | Offline | Stół Skinnier (390 MB) | 33,1 |
| Szersza tabela (780 MB) | 32,1 | ||
| Online | Węższy stół | 81,9 | |
| Szersza tabela | 103,3 | ||
| Odtwórz | Węższy stół | 28,9 | |
| maks. 16 tys. | Offline | Węższy stół (1,6 GB) | 53,3 |
| Większa tabela (1,7 GB) | 46,7 | ||
| Online | Węższy stół | 130.9 | |
| Szersza tabela | 150,2 | ||
| Odtwórz | Węższy stół | 81,8 | |
| maks. 64k | Offline | Stół Skinnier (7,0 GB) | 51,5 |
| Szersza tabela (7,1 GB) | 58,5 | ||
| Online | Węższy stół | 136,5 | |
| Szersza tabela | 152,6 | ||
| Odtwórz | Węższy stół | 226,5 | |
| maks. 256 tys. | Offline | Stół Skinnier (25,8 GB) | 60,9 |
| Szersza tabela (25,9 GB) | 61,3 | ||
| Online | Węższy stół | 149,1 | |
| Szersza tabela | 197,1 | ||
| Odtwórz | Węższy stół | 1 576,7 | |
To niesprawiedliwe potrząsanie metodą Andy'ego, ponieważ – w prawdziwym świecie – nie wykonałbyś całej operacji za jednym zamachem. Nie pokazywałem tutaj użycia dziennika transakcji dla zwięzłości, ale łatwiej byłoby to kontrolować również poprzez grupowanie w operacji side-by-side. Chociaż jego podejście wymaga więcej pracy z góry, jest o wiele bezpieczniejsze pod względem przestojów i/lub blokowania. Ale możesz zauważyć, że w przypadkach, w których masz dużo danych poza wierszem i możesz sobie pozwolić na krótką przerwę, bezpośrednia zmiana kolumny jest o wiele mniej bolesna. „Zbyt duże, aby zmienić na miejscu” jest subiektywne i może dawać różne wyniki w zależności od tego, co oznacza „duży”. Przed podjęciem decyzji warto przetestować zmianę na rozsądnej kopii, ponieważ operacja w miejscu może stanowić akceptowalny kompromis.
Wniosek
Nie napisałem tego, żeby kłócić się z Andym. Podejście w oryginalnym poście jest solidne, w 100% niezawodne i używamy go cały czas. Kiedy jednak brutalna siła jest bardziej ceniona niż chirurgiczna precyzja, a zwłaszcza jeśli możesz poświęcić trochę czasu na przestój, prostsze podejście może mieć wartość w przypadku niektórych kształtów stołu.