SQL Server 2014 SP2 i nowsze produkują plany wykonania („rzeczywiste”), które mogą obejmować czas, który upłynął i wykorzystanie procesora dla każdego operatora planu wykonania (patrz KB3170113 i ten wpis na blogu autorstwa Pedro Lopes).
Interpretacja tych liczb nie zawsze jest tak prosta, jak można by się spodziewać. Istnieją ważne różnice między trybem wiersza i tryb wsadowy wykonanie, a także trudne problemy z równoległością w trybie wiersza . SQL Server wprowadza pewne korekty czasu równolegle planuje promować spójność, ale nie są one doskonale realizowane. Może to utrudnić wyciągnięcie wniosków dotyczących dostrajania dźwięku.
Ten artykuł ma na celu pomóc Ci zrozumieć, skąd pochodzą czasy w każdym przypadku i jak najlepiej je interpretować w kontekście.
Konfiguracja
Poniższe przykłady wykorzystują publiczny Stack Overflow 2013 baza danych (szczegóły pobierania), z dodanym pojedynczym indeksem:
CREATE INDEX PP ON dbo.Posts (PostTypeId ASC, CreationDate ASC) INCLUDE (AcceptedAnswerId);
Zapytania testowe zwracają liczbę pytań z zaakceptowaną odpowiedzią pogrupowaną według miesiąca i roku. Działają na SQL Server 2019 CU9 , na laptopie z 8 rdzeniami i 16 GB pamięci przydzielonej do instancji SQL Server 2019. Poziom zgodności 150 jest używany wyłącznie.
Wykonywanie szeregowe w trybie wsadowym
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Plan wykonania to (kliknij, aby powiększyć):
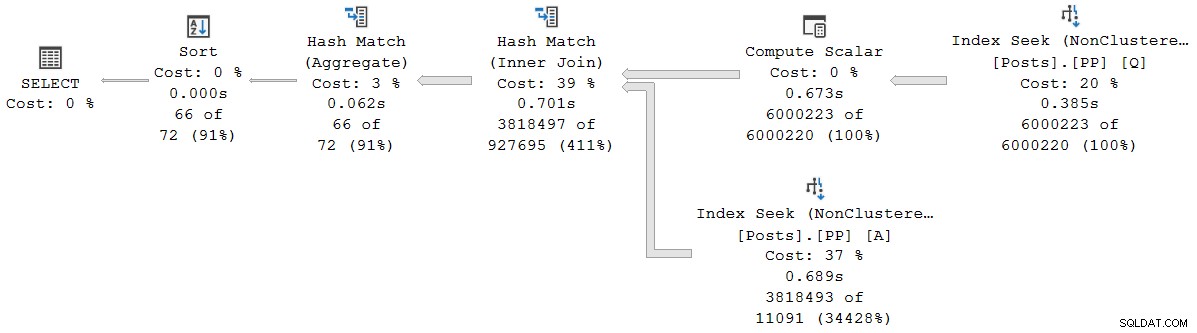
Każdy operator w tym planie działa w trybie wsadowym dzięki trybowi wsadowemu w sklepie rowstore Funkcja inteligentnego przetwarzania zapytań w SQL Server 2019 (nie jest potrzebny indeks magazynu kolumn). Zapytanie trwa 2523 ms z wykorzystaniem 2,522 ms czasu procesora, gdy wszystkie potrzebne dane znajdują się już w puli buforów.
Jak zauważył Pedro Lopes we wcześniej zamieszczonym poście na blogu, czasy, które upłynął i czas pracy procesora zgłoszony dla poszczególnych trybów wsadowych operatory reprezentują czas używany przez samego operatora .
SSMS wyświetla czas, który upłynął w reprezentacji graficznej. Aby zobaczyć czasy procesora , wybierz operatora planu, a następnie zajrzyj do Właściwości okno. Ten szczegółowy widok pokazuje zarówno czas, jaki upłynął, jak i czas procesora, na operatora i na wątek.
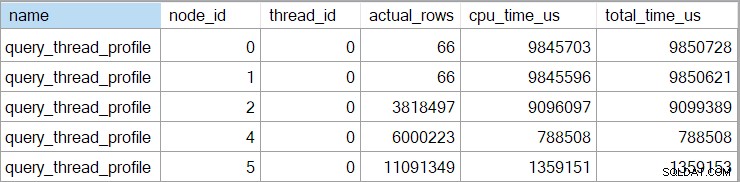
Czasy showplanu (w tym reprezentacja XML) są skrócone do milisekund. Jeśli potrzebujesz większej precyzji, użyj query_thread_profile zdarzenie rozszerzone, które raportuje w mikrosekundach . Dane wyjściowe z tego zdarzenia dla planu wykonania pokazanego powyżej to:
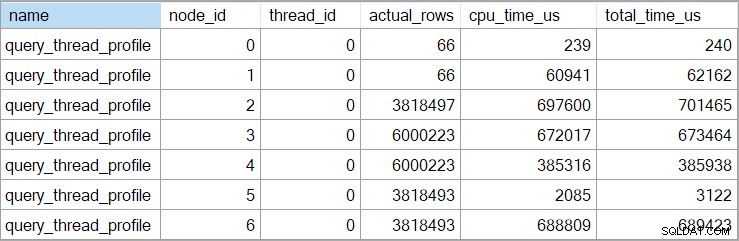
Pokazuje to, że czas, jaki upłynął od połączenia (węzeł 2), wynosi 701465µs (skrócony do 701ms w planie pokazu). Czas trwania agregatu to 62 162 µs (62 ms). Wyszukiwanie indeksu „pytań” jest wyświetlane jako działające przez 385 ms, podczas gdy rozszerzone zdarzenie pokazuje, że prawdziwa wartość dla węzła 4 wynosiła 385 938 µs (prawie 386 ms).
SQL Server korzysta z wysokiej precyzji CounterPerformanceCounter API do przechwytywania danych o czasie. Wykorzystuje to sprzęt, zwykle oscylator kwarcowy, który wytwarza tiki z bardzo wysoką stałą szybkością, niezależnie od szybkości procesora, ustawień mocy lub czegokolwiek w tym rodzaju. Zegar działa w tym samym tempie nawet podczas snu. Zobacz link, bardzo szczegółowy artykuł, jeśli jesteś zainteresowany wszystkimi drobniejszymi szczegółami. Krótkie podsumowanie mówi, że możesz ufać, że liczby mikrosekundowe są dokładne.
W tym czystym planie w trybie wsadowym całkowity czas wykonania jest bardzo zbliżony do sumy czasów, jakie upłynął dla poszczególnych operatorów. Różnica w dużej mierze sprowadza się do pracy po złożeniu oświadczenia niezwiązanej z operatorami planu (którzy do tego czasu wszyscy zamknęli), chociaż skrócenie milisekund również odgrywa pewną rolę.
W czystych planach w trybie wsadowym musisz ręcznie zsumować bieżące i podrzędne czasy operatora, aby uzyskać skumulowaną czas, jaki upłynął w dowolnym węźle.
Wykonywanie równoległe w trybie wsadowym
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
); Plan wykonania to:
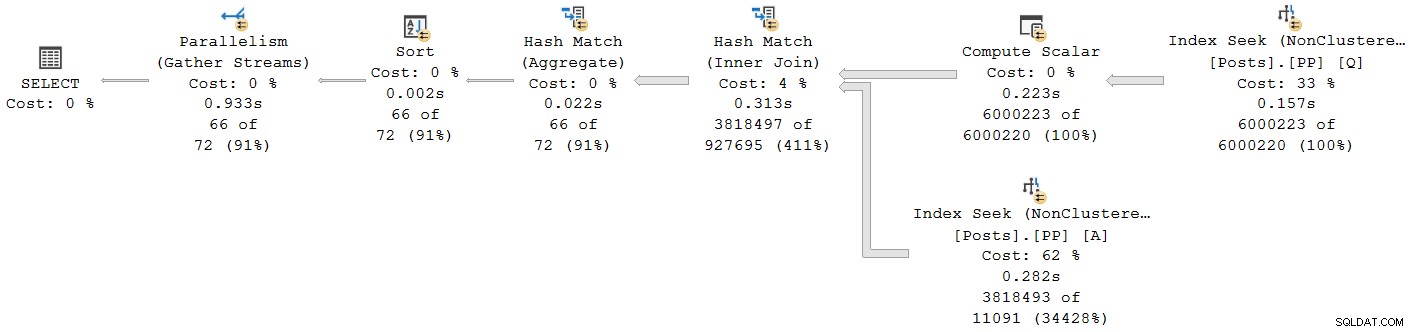
Każdy operator z wyjątkiem wymiany strumienia końcowego pobierania działa w trybie wsadowym. Całkowity czas, który upłynął to 933ms z 6,673 ms czasu procesora z ciepłą pamięcią podręczną.
Wybór połączenia mieszającego i przeglądanie Właściwości SSMS okno, widzimy czas, który upłynął i czas procesora na wątek dla tego operatora:
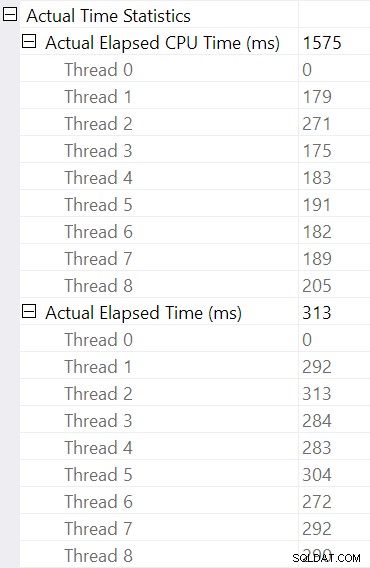
Czas procesora zgłaszana dla operatora to suma czasów procesora poszczególnych wątków. Zgłoszony operator upłynął czas to maksymalna czasu, jaki upłynął na wątek. Oba obliczenia są wykonywane na obciętych wartościach milisekundowych na wątek. Tak jak poprzednio, całkowity czas wykonania jest bardzo zbliżony do sumy czasów, jakie upłynął dla poszczególnych operatorów.
Plany równoległe w trybie wsadowym nie używają wymian do dystrybucji pracy między wątkami. Operatory wsadowe są zaimplementowane, aby wiele wątków mogło wydajnie działać na jednej udostępnionej strukturze (np. tablica mieszająca). Pewna synchronizacja między wątkami jest nadal wymagana w planach równoległych w trybie wsadowym, ale punkty synchronizacji i inne szczegóły nie są widoczne w wynikach showplanu.
Wykonywanie szeregowe w trybie wiersza
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 1,
USE HINT ('DISALLOW_BATCH_MODE')
); Plan wykonania jest wizualnie taki sam jak plan seryjny w trybie wsadowym, ale każdy operator działa teraz w trybie wiersza:
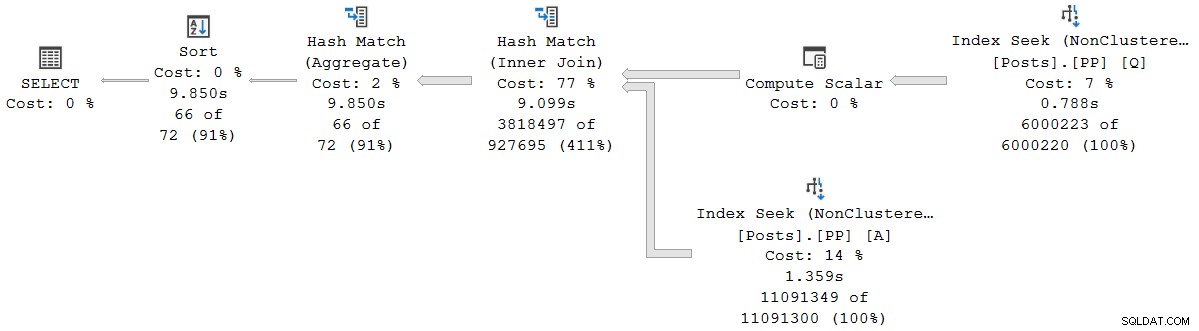
Zapytanie trwa 9850 ms z czasem procesora 9845 ms. Zgodnie z oczekiwaniami jest to znacznie wolniejsze niż zapytanie w trybie wsadowym (2523ms/2522ms). Co ważniejsze dla obecnej dyskusji, tryb wiersza operator, który upłynął, a czasy procesora reprezentują czas używany przez bieżący operator i wszystkie jego dzieci .
Rozszerzone zdarzenie pokazuje również skumulowany czas procesora i upływający czas w każdym węźle (w mikrosekundach):
Brak danych dla operatora skalarnego obliczeń (węzeł 3), ponieważ wykonanie w trybie wiersza może odroczyć większość obliczeń wyrażeń do operatora, który wykorzystuje wynik. Obecnie nie jest to zaimplementowane do wykonywania w trybie wsadowym.
Zgłoszona skumulowana czas, jaki upłynął dla operatorów trybu wierszowego oznacza, że czas pokazany dla końcowego operatora sortowania jest zbliżony do całkowitego czasu wykonania zapytania (i tak z dokładnością do milisekund). Czas, jaki upłynął na połączenie haszujące, obejmuje również wkłady z dwóch indeksów szukanych poniżej, a także jego własny czas. Aby obliczyć czas, jaki upłynął dla samego łączenia haszującego w trybie wiersza musielibyśmy odjąć od niego oba czasy wyszukiwania.
Obie prezentacje mają swoje zalety i wady (łącznie dla trybu wierszowego, pojedynczy operator tylko dla trybu wsadowego). Niezależnie od tego, co wolisz, ważne jest, aby zdawać sobie sprawę z różnic.
Mieszane plany trybu wykonania
Ogólnie rzecz biorąc, nowoczesne plany wykonania mogą zawierać dowolną kombinację operatorów trybu wierszowego i wsadowego. Operatorzy trybu wsadowego będą zgłaszać czasy tylko dla siebie. Operatorzy trybu wiersza uwzględnią łączną sumę do tego momentu w planie, w tym wszystkie operatorzy podrzędni. Żeby było jasne:łączne czasy operatora trybu wiersza obejmują dowolne operatory podrzędne trybu wsadowego.
Widzieliśmy to wcześniej w planie równoległego trybu wsadowego:ostateczny (tryb wierszowy) operator strumieni zbierania miał wyświetlany (skumulowany) czas, który upłynął 0,933 s — łącznie ze wszystkimi jego podrzędnymi operatorami trybu wsadowego. Wszyscy pozostali operatorzy byli w trybie wsadowym, więc raportowali czasy tylko dla pojedynczego operatora.
Ta sytuacja, w której niektórzy operatorzy planu w tym samym planie mają skumulowane czasy, a inne nie, bez wątpienia będą uważane za dezorientujące przez wielu ludzi.
Wykonywanie równoległe w trybie wiersza
SELECT
CA.TheYear,
CA.TheMonth,
AcceptedAnswers = COUNT_BIG(*)
FROM dbo.Posts AS Q
JOIN dbo.Posts AS A
ON A.Id = Q.AcceptedAnswerId
CROSS APPLY
(
VALUES
(
YEAR(Q.CreationDate),
MONTH (Q.CreationDate)
)
) AS CA (TheYear, TheMonth)
WHERE
Q.PostTypeId = 1
AND A.PostTypeId = 2
GROUP BY
CA.TheYear, CA.TheMonth
ORDER BY
CA.TheYear, CA.TheMonth
OPTION
(
MAXDOP 8,
USE HINT ('DISALLOW_BATCH_MODE')
); Plan wykonania to:

Każdy operator jest w trybie wiersza. Zapytanie trwa 4677 ms z czasem procesora 23 311 ms (suma wszystkich wątków).
W przypadku planu wyłącznie w trybie wierszowym spodziewamy się, że wszystkie czasy będą skumulowane . Przechodząc od dziecka do rodzica (od prawej do lewej), czasy powinny rosnąć w tym kierunku.
Przyjrzyjmy się tylko prawej części planu:
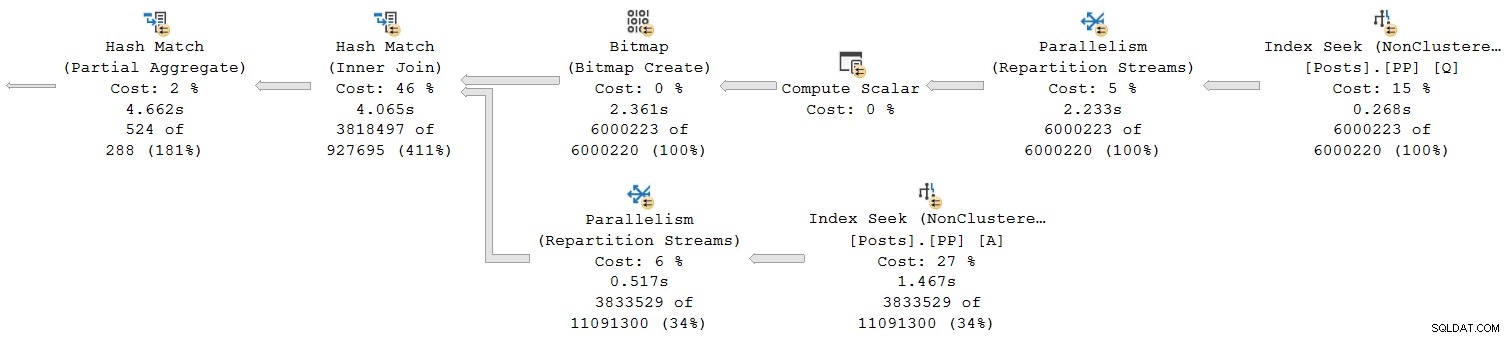
Pracując od prawej do lewej w górnym rzędzie, z pewnością wydaje się, że tak jest w przypadku czasów skumulowanych. Ale jest wyjątek na niższych danych wejściowych do łączenia mieszającego:czas wyszukiwania indeksu upłynął 1.467 s , podczas gdy jego rodzic strumienie repartycji mają czas, który upłynął tylko 0,517 s .
Jak może rodzic operator działa krócej niż jego dziecko czy czasy, które upłynęły, kumulują się w planach trybu wiersza?
Niespójne czasy
Odpowiedź na tę zagadkę składa się z kilku części. Weźmy to kawałek po kawałku, ponieważ jest to dość złożone:
Po pierwsze, pamiętaj, że wymiana (operator równoległości) składa się z dwóch części. Lewa ręka (konsument ) strona jest połączona z jednym zestawem wątków z operatorami w gałęzi równoległej po lewej stronie. Prawa ręka (producent ) strona giełdy jest połączona z innym zestawem wątków z operatorami w gałęzi równoległej po prawej stronie.
Rzędy od strony producenta są składane w pakiety a następnie przeniesione na stronę konsumenta. Zapewnia to stopień buforowania i kontrola przepływu między dwoma zestawami połączonych wątków. (Jeśli potrzebujesz odświeżenia na temat giełd i gałęzi planów równoległych, zapoznaj się z moim artykułem Plany wykonywania równoległego – gałęzie i wątki.)
Zakres skumulowanych czasów
Patrząc na równoległy oddział u producenta strona wymiany:
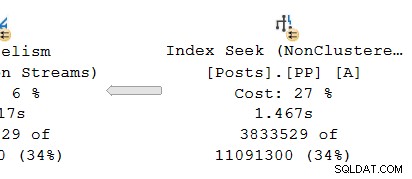
Jak zwykle, dodatkowe wątki robocze DOP (stopień równoległości) uruchamiają niezależny szereg kopię operatorów planu w tej branży. Tak więc w DOP 8 istnieje 8 niezależnych szeregowych wyszukiwań indeksów współpracujących ze sobą w celu wykonania części skanowania zakresu całej (równoległej) operacji wyszukiwania indeksu. Każde wyszukiwanie jednowątkowe jest połączone z innym wejściem (portem) po stronie producenta pojedynczego udostępnionego operatora giełdy.
Podobna sytuacja dotyczy konsumentu stronie wymiany. W DOP 8 istnieje 8 oddzielnych jednowątkowych kopii tej gałęzi, z których wszystkie działają niezależnie:
Każdy z tych jednowątkowych planów podrzędnych działa w zwykły sposób, z każdym operatorem kumulującym czas i łączny czas procesora w każdym węźle. Będąc operatorami trybu wierszowego, każda suma reprezentuje czas spędzony na skumulowanej sumie dla bieżącego węzła i każdego z jego elementów podrzędnych.
Najważniejsze jest to, że łączne sumy uwzględniaj tylko operatory w tym samym wątku i tylko w obecnej gałęzi . Mamy nadzieję, że ma to intuicyjny sens, ponieważ każdy wątek nie ma pojęcia, co może się dziać gdzie indziej.
Jak zbierane są dane trybu wiersza
Druga część układanki dotyczy sposobu, w jaki metryki dotyczące liczby wierszy i czasu są zbierane w planach trybu wierszy. Gdy wymagane są informacje o planie czasu wykonywania („rzeczywiste”), silnik wykonawczy dodaje niewidoczny operator profilowania po bezpośrednio w lewo (rodzic) każdego operatora w planie, który zostanie wykonany w czasie wykonywania.
Ten operator może rejestrować (między innymi) różnicę między czasem, w którym przekazał kontrolę do swojego operatora podrzędnego, a czasem, kiedy kontrola została zwrócona. Ta różnica czasu reprezentuje czas, jaki upłynął dla monitorowanego operatora i wszystkich jego dzieci , ponieważ dziecko odwołuje się do własnego dziecka w każdym wierszu i tak dalej. Operator może być wywoływany wiele razy (w celu zainicjowania, następnie raz w wierszu, w końcu do zamknięcia), więc czas zebrany przez operator profilowania jest kumulacją przez potencjalnie wiele iteracji na wiersz.
Więcej informacji na temat danych profilowania zebrane przy użyciu różnych metod przechwytywania, zobacz dokumentację produktu dotyczącą infrastruktury profilowania zapytań. Dla zainteresowanych takimi rzeczami, nazwa niewidzialnego operatora profilowania używanego przez standardową infrastrukturę to sqlmin!CQScanProfileNew . Jak wszystkie iteratory trybu wiersza, ma Open , GetRow i Close metody m.in. Każda metoda zawiera wywołania QueryPerformanceCounter systemu Windows API do zbierania bieżącej wartości licznika wysokiej rozdzielczości.
Ponieważ operator profilowania znajduje się po lewej operatora docelowego, mierzy tylko konsument stronie wymiany. Nie ma braku operatora profilowania dla producenta strona wymiany (niestety). Gdyby tak było, pasowałby lub przekraczał czas, który upłynął w wyszukiwaniu indeksu, ponieważ wyszukiwanie indeksu i strona producenta uruchamiają ten sam zestaw wątków, a strona producenta giełdy jest operatorem nadrzędnym wyszukiwania indeksu.
Ponowne poznanie czasu

Biorąc to wszystko pod uwagę, nadal możesz mieć problemy z czasami pokazanymi powyżej. Jak wyszukiwanie indeksu może zająć 1.467s aby przekazać wiersze po stronie producenta na giełdzie, ale po stronie konsumenta zajmuje tylko 0,517 s otrzymać je? Niezależnie od osobnych wątków, buforowania i tak dalej, z pewnością wymiana powinna trwać (od końca do końca) dłużej niż wyszukiwanie?
Cóż, tak, ale to inny pomiar od czasu, który upłynął lub czasu procesora. Bądźmy precyzyjni, co tutaj mierzymy.
W trybie wiersza czas, który upłynął , wyobraź sobie stoper na wątek u każdego operatora. Stoper uruchamia się kiedy SQL Server wprowadza kod operatora ze swojego rodzica i zatrzymuje się (ale nie resetuje się), gdy ten kod pozostawia operatora, aby zwrócić kontrolę z powrotem do rodzica (nie do dziecka). Czas, który upłynął zawiera wszelkie oczekiwania lub opóźnienia w harmonogramie – żadne z nich nie zatrzymuje zegarka.
W trybie wiersza Czas procesora , wyobraź sobie ten sam stoper o tych samych parametrach, z wyjątkiem tego, że zatrzymuje się podczas opóźnień i opóźnień w harmonogramie. Gromadzi czas tylko wtedy, gdy operator lub jeden z jego elementów podrzędnych aktywnie wykonuje na harmonogramie (CPU). Całkowity czas na stoper na wątek przypadający na operatora składa się z cyklu start-stop dla każdego wiersza.
Zastosujmy to do obecnej sytuacji po stronie konsumenckiej giełdy, a indeks szukamy:
Pamiętaj, że strona konsumencka giełdy i wyszukiwanie indeksu znajdują się w osobnych oddziałach, więc działają w osobnych wątkach . Strona konsumencka nie ma dzieci w tym samym wątku. Poszukiwanie indeksu ma stronę producenta giełdy jako swojego rodzica z tym samym wątkiem, ale nie mamy tam stopera.
Każdy wątek konsumencki rozpoczyna obserwację, gdy jego operator nadrzędny (strona sondująca sprzężenia mieszającego) przekazuje kontrolę (np. w celu pobrania wiersza). Zegarek działa dalej, podczas gdy konsument pobiera wiersz z aktualnego pakietu wymiany. Zegarek zatrzymuje się gdy kontrola opuszcza konsumenta i powraca do strony sondy łączenia mieszającego. Kolejni rodzice (częściowa agregacja i jej giełda nadrzędna) również będą działać na tym wierszu (i mogą poczekać), zanim kontrola powróci do konsumenta naszej giełdy, aby pobrać następny wiersz. W tym momencie strona konsumencka naszej giełdy zaczyna ponownie gromadzić upływający czas i czas procesora.
Tymczasem niezależnie od tego, co robią wątki po stronie konsumenta, szukanie indeksu wątki nadal lokalizują wiersze w indeksie i wprowadzają je na giełdę. Wątek poszukiwania indeksu uruchamia stoper, gdy strona producenta giełdy poprosi go o wiersz. Stoper jest wstrzymywany po przekazaniu wiersza do giełdy. Gdy giełda poprosi o następny wiersz, stoper wyszukiwania indeksu wznawia się.
Pamiętaj, że po stronie producenta giełdy może wystąpić CXPACKET czeka, aż bufory wymiany się zapełnią, ale nie doda to czasu zarejestrowanego podczas wyszukiwania indeksu, ponieważ jego stoper nie działa, gdy to się dzieje. Gdybyśmy mieli stoper po stronie producenta giełdy, brakujący czas pojawiłby się tam.
Aby wizualnie przybliżyć podsumowanie sytuacji, poniższy diagram pokazuje, kiedy każdy operator gromadzi upływ czasu w dwóch równoległych gałęziach:
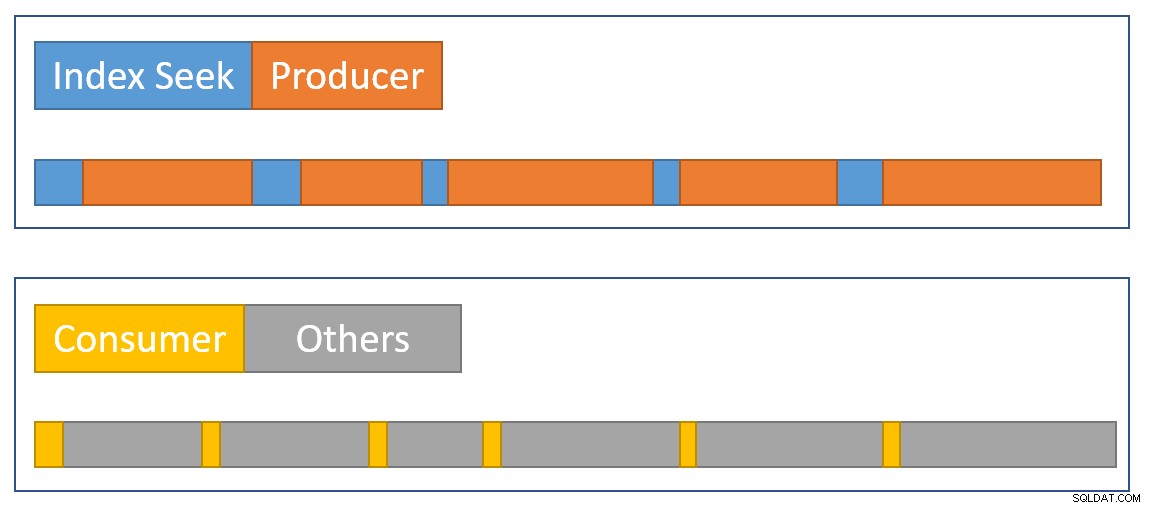
niebieski Słupki czasu wyszukiwania indeksu są krótkie, ponieważ pobieranie wiersza z indeksu jest szybkie. pomarańczowy czasy producentów mogą być długie z powodu CXPACKET czeka. żółty czasy konsumenckie są krótkie, ponieważ szybko można pobrać wiersz z giełdy, gdy dostępne są dane. szary segmenty czasu reprezentują czas używany przez innych operatorów (po stronie sondy łączenia haszującego, częściowej agregacji i po stronie producenta macierzystej wymiany) powyżej strony konsumenta giełdy.
Spodziewamy się, że pakiety wymiany zostaną szybko wypełnione według indeksu wyszukiwania, ale opróżniany powoli (relatywnie) przez operatorów po stronie konsumenta, ponieważ mają więcej pracy do wykonania. Oznacza to, że pakiety w wymianie będą zwykle pełne lub prawie pełne. Konsument będzie mógł szybko pobrać oczekujący wiersz, ale producent może poczekać na pojawienie się przestrzeni pakietowej.
Szkoda, że po stronie producenta giełdy nie widzimy upływu czasu. Od dawna uważam, że giełda powinna być reprezentowana przez dwa różnych operatorów w planach wykonawczych. Utrudniłoby to CXPACKET /CXCONSUMER analiza oczekiwania jest znacznie mniej potrzebna, a plany wykonania znacznie łatwiejsze do zrozumienia. Operator producenta giełdy naturalnie otrzyma własnego operatora profilowania.
Alternatywne projekty
Istnieje wiele sposobów, w jakie SQL Server może osiągnąć spójne skumulowane upływający czas i czas procesora w równoległych gałęziach zasadniczo . Zamiast profilować operatorów, każdy wiersz mógł zawierać informacje o tym, ile czasu upłynęło i jaki czas procesora zgromadził do tej pory podczas podróży przez plan. Z historią powiązaną z każdym wierszem, nie ma znaczenia, w jaki sposób giełdy redystrybuują wiersze między wątkami i tak dalej.
Nie tak zaprojektowano produkt, więc nie mamy tego (a i tak może to być nieefektywne). Aby być uczciwym, oryginalny projekt trybu wierszowego dotyczył tylko takich rzeczy, jak zbieranie rzeczywistej liczby wierszy i liczby iteracji u każdego operatora. Dodawanie do planów czasu, jaki upłynął na operatora, było funkcją, o którą bardzo oczekiwano , ale nie było łatwo włączyć go do istniejącego frameworka.
Po dodaniu przetwarzania w trybie wsadowym do produktu można było wdrożyć inne podejście (czas tylko dla bieżącego operatora) jako część oryginalnego rozwoju bez uszkadzania czegokolwiek. Ponownie, zasadniczo , operatory trybu wiersza można było zmodyfikować tak, aby działały w taki sam sposób, jak operatory trybu wsadowego, ale wymagałoby to wiele pracy przy przeprojektowaniu każdego istniejącego operatora trybu wiersza. Dodanie nowego punktu danych do istniejących operatorów profilowania w trybie wiersza było znacznie łatwiejsze. Biorąc pod uwagę ograniczone zasoby inżynieryjne i długą listę pożądanych ulepszeń produktu, często trzeba iść na takie kompromisy.
Drugi problem
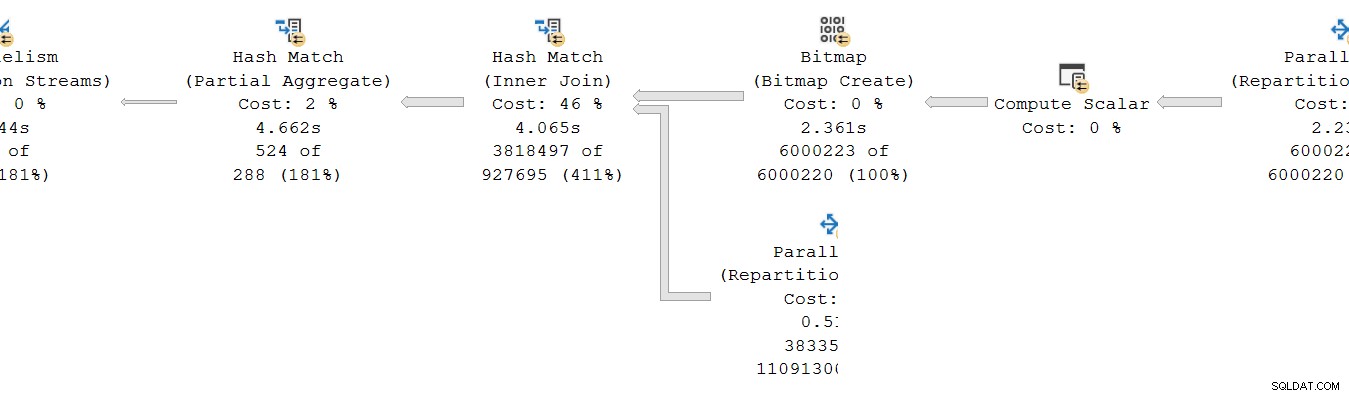
Kolejna skumulowana niespójność czasowa występuje w obecnym planie po lewej stronie:

Na pierwszy rzut oka wygląda to na ten sam problem:częściowy agregat ma czas 4.662s , ale powyższa giełda działa tylko przez 2,844 s . Oczywiście w grę wchodzą te same podstawowe mechaniki, co poprzednio, ale jest jeszcze jeden ważny czynnik. Jedna wskazówka dotyczy podejrzanie równych czasów zgłoszonych dla wymiany agregacji, sortowania i podziału strumienia.
Pamiętasz „korekty rozrządu”, o których wspomniałem we wstępie? Tutaj wkraczają one. Spójrzmy na poszczególne czasy, które upłynął dla wątków po stronie konsumenta wymiany strumieni podziału:
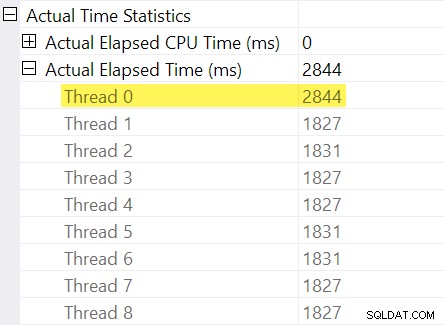
Przypomnijmy, że plany pokazują upływ czasu dla operatora równoległego jako maksimum razy na wątek. Wszystkie 8 wątków minęło około 1830 ms, ale istnieje dodatkowy wpis dla „Wątku 0” z 2844 ms. Rzeczywiście każdy operator w tej gałęzi równoległej (odbiorca giełdy, rodzaj i agregat strumienia) mają takie same 2844 ms wkładu z „Wątku 0”.
Zero wątku (aka zadanie nadrzędne lub koordynator) uruchamia tylko operatory bezpośrednio po lewej stronie operatora strumieni pobierania końcowego. Dlaczego jest do niego przypisana praca w równoległym odgałęzieniu?
Wyjaśnienie
Ten problem może wystąpić, gdy w gałęzi równoległej poniżej znajduje się operator blokujący (na prawo od) aktualnego. Bez tej korekty operatorzy w obecnym oddziale nie zgłaszaliby czasu, który upłynął o czas potrzebny do otwarcia gałęzi podrzędnej (są skomplikowane przyczyn architektonicznych tego).
SQL Server stara się to uwzględnić, rejestrując opóźnienie gałęzi podrzędnej na giełdzie w niewidocznym operatorze profilowania. Wartość czasu jest rejestrowana względem zadania nadrzędnego („Wątek 0”) w różnicy między pierwszą aktywną i ostatni aktywny czasy. (Zapisywanie numeru w ten sposób może wydawać się dziwne, ale w momencie, gdy numer musi zostać zarejestrowany, dodatkowe równoległe wątki robocze nie zostały jeszcze utworzone).
W obecnym przypadku korekta 2844 ms powstaje głównie ze względu na czas potrzebny sprzężeniu mieszającemu do zbudowania tablicy mieszającej. (Pamiętaj, że tym razem różni się od całkowitej czas wykonania połączenia mieszającego, który obejmuje czas potrzebny na przetworzenie strony próbnej połączenia).
Potrzeba dostosowania pojawia się, ponieważ sprzężenie haszujące blokuje dane wejściowe kompilacji. (Co ciekawe, skrót częściowa agregacja w planie nie jest uważane za blokowanie w tym kontekście, ponieważ przypisano mu tylko minimalną ilość pamięci, nigdy nie przelewa się do tempdb i po prostu przestaje agregować, jeśli zabraknie pamięci (w ten sposób powraca do trybu przesyłania strumieniowego). Craig Freedman wyjaśnia to w swoim poście, Partial Aggregation).
Biorąc pod uwagę, że korekta czasu, który upłynął, reprezentuje opóźnienie inicjalizacji w gałęzi podrzędnej, SQL Server powinien traktować wartość „Wątek 0” jako przesunięcie dla zmierzonych liczb czasu, jaki upłynął na wątek w ramach bieżącej gałęzi. Biorąc maksimum wszystkich wątków, ponieważ upływający czas jest ogólnie rozsądny, ponieważ wątki mają tendencję do rozpoczynania się w tym samym czasie. nie ma to sens, gdy jedna z wartości wątku jest przesunięciem dla wszystkich innych wartości!
Możemy wykonać poprawne obliczenie przesunięcia ręcznie korzystając z danych dostępnych w planie. Po stronie konsumenckiej giełdy mamy:
Maksymalny czas, jaki upłynął między dodatkowymi wątkami roboczymi, to 1831 ms (z wyłączeniem wartości przesunięcia zapisanej w „Wątku 0”). Dodawanie przesunięcia 2844 ms daje w sumie 4675 ms .
W każdym planie, w którym czasy na wątek są mniejsze niż przesunięcie, operator niepoprawnie pokaż przesunięcie jako całkowity czas, który upłynął. Może się tak zdarzyć, gdy wcześniejszy operator blokowania jest powolny (np. sortowanie lub agregacja globalna na dużym zbiorze danych), a późniejsze operatory oddziałów są mniej czasochłonne.
Wracając do tej części planu:
Zastąpienie przesunięcia 2844 ms błędnie przypisanego do strumieni podziału, sortowania i agregacji strumieni z naszymi obliczonymi 4675 ms wartość umieszcza ich skumulowany czas między 4662 ms w częściowej agregacji a 4676 ms w ostatnich strumieniach zbierania. (Sortowanie i agregacja działają na niewielkiej liczbie wierszy, więc ich obliczenia dotyczące czasu, który upłynął, są takie same jak sortowanie, ale ogólnie często byłyby różne):

Wszyscy operatorzy w powyższym fragmencie planu mają 0 ms czasu procesora, który upłynął we wszystkich wątkach (oprócz częściowej agregacji, która ma 14 891 ms). Plan z naszymi obliczonymi liczbami ma zatem znacznie więcej sensu niż ten wyświetlany:
- 4675 ms – 4662 ms =13 ms upłynęło jest znacznie bardziej rozsądną liczbą dla czasu zużywanego przez strumienie repartycji samodzielnie . Ten operator nie zużywa czasu procesora i przetwarza tylko 524 wiersze.
- 0ms upływający (z dokładnością do milisekund) jest rozsądny dla małego agregatu sortowania i strumienia (ponownie, z wyłączeniem ich dzieci).
- 4676 ms – 4675 ms =1 ms wydaje się, że końcowe strumienie zbierania zbierają 66 wierszy do nadrzędnego wątku zadania w celu zwrócenia ich do klienta.
Oprócz oczywistej niespójności w podanym planie między strumieniami częściowej agregacji (4662 ms) i repartycji (2844 ms), nierozsądne jest myślenie, że końcowe strumienie pobierania z 66 wierszy mogą być odpowiedzialne za 4676 ms – 2844 ms = 1832 ms upływu czasu. Poprawiona liczba (1 ms) jest znacznie dokładniejsza i nie wprowadzi w błąd tunerów zapytań.
Teraz, nawet jeśli to obliczenie przesunięcia zostało wykonane poprawnie, plany trybu równoległego mogą nie pokazać spójne czasy skumulowane we wszystkich przypadkach, z powodów omówionych wcześniej. Osiągnięcie pełnej spójności może być trudne, a nawet niemożliwe bez poważnych zmian architektonicznych.
Przewidując pytanie, które może pojawić się w tym momencie:Nie, wcześniejsza analiza poszukiwań giełdowych i indeksowych nie zawierała błędu obliczenia offsetu „Wątek 0”. Poniżej tej centrali nie ma operatora blokującego, więc nie występuje opóźnienie inicjalizacji.
Ostateczny przykład
To następne przykładowe zapytanie używa tej samej bazy danych i indeksu co poprzednio. Nie będę go zgłębiać zbyt szczegółowo, ponieważ służy tylko rozwinięciu punktów, które już przedstawiłem, dla zainteresowanego czytelnika.
Cechy tego demo to:
- Bez
ORDER GROUPwskazówka, pokazuje, że częściowy agregat nie jest uważany za operatora blokującego, więc przy wymianie strumieni podziału nie występuje korekta „Wątek 0”. Czasy, które upłynęły, są zgodne. - Z wskazówką, zamiast agregacji częściowej z haszem wprowadzane są sortowania blokujące. Dwa różne Korekty „Wątku 0” pojawiają się na dwóch wymianach partycjonujących. Czasy, które upłynął, są niespójne w obu gałęziach na różne sposoby.
Zapytanie:
SELECT * FROM
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 1
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C1
JOIN
(
SELECT
yr = YEAR(P.CreationDate),
mth = MONTH(P.CreationDate),
mx = MAX(P.CreationDate)
FROM dbo.Posts AS P
WHERE
P.PostTypeId = 2
GROUP BY
YEAR(P.CreationDate),
MONTH(P.CreationDate)
) AS C2
ON C2.yr = C1.yr
AND C2.mth = C1.mth
ORDER BY
C1.yr ASC,
C1.mth ASC
OPTION
(
--ORDER GROUP,
USE HINT ('DISALLOW_BATCH_MODE')
);
Plan wykonania bez ORDER GROUP (bez regulacji, stałe czasy):

Plan realizacji z ORDER GROUP (dwie różne korekty, niespójne czasy):

Podsumowanie i wnioski
Row mode plan operators report cumulative times inclusive of all child operators in the same thread. Batch mode operators record the time used inside that operator alone .
A single plan can include both row and batch mode operators; the row mode operators will record cumulative elapsed time, including any batch operators. Correctly interpreting elapsed times in mixed-mode plans can be challenging.
For parallel plans, total CPU time for an operator is the sum of individual thread contributions. Total elapsed time is the maximum of the per-thread numbers.
Row mode actual plans include an invisible profiling operator to the immediate left (parent) of executing visible operators to collect runtime statistics like total row count, number of iterations, and timings. Because the row mode profiling operator is a parent of the target operator, it captures activity for that operator and all children (but only in the same thread).
Exchanges are row mode operators. There is no separate hidden profiling operator for the producer side, so exchanges only show details and timings for the consumer side . The consumer side has no children in the same thread so it reports timings for itself only.
Long elapsed times on an exchange with low CPU usage generally mean the consumer side has to wait for rows (CXCONSUMER ). This is often caused by a slow producer side (with various root causes). For an example of that with a super investigation, see CXCONSUMER As a Sign of Slow Parallel Joins by Josh Darneli.
Batch mode operators do not use separate profiling operators. The batch mode operator itself contains code to record timing on every entry and exit (e.g. per batch). Passing control to a child operator counts as an exit . This is why batch mode operators record only their own activity (exclusive of their child operators).
Internal architectural details mean the way parallel row mode plans start up would cause elapsed times to be under-reported for operators in a parallel branch when a child parallel branch contains a blocking operator. An attempt is made to adjust for the timing offset caused by this, but the implementation appears to be incomplete, resulting in inconsistent and potentially misleading elapsed times. Multiple separate adjustments may be present in a single execution plan. Adjustments may accumulate when multiple branches contain blocking operators, and a single operator may combine more than one adjustment (e.g. merge join with an adjustment on each input).
Without the attempted adjustments, parallel row-mode plans would only show consistent elapsed times within a branch (i.e. between parallelism operators). This would not be ideal, but it would arguably be better than the current situation. As it is, we simply cannot trust elapsed times in parallel row-mode plans to be a true reflection of reality.
Look out for “Thread 0” elapsed times on exchanges, and the associated branch plan operators. These will sometimes show up as implausibly identical times for operators within that branch. You may need to manually add the offset to the maximum per-thread times for each affected operator to get sensible results.
The same adjustment mechanism exists for CPU times , but it appears non-functional at the moment. Unfortunately, this means you should not expect CPU times to be cumulative across branches in row mode parallel plans. This is somewhat ironic because it does make sense to sum CPU times (including the “Thread 0” value). I doubt many people rely on cumulative CPU times in execution plans though.
With any luck, these calculations will be improved in a future product update, if the required corrective work is not too onerous.
In the meantime, this all represents another reason to prefer batch mode plans when dealing with even moderately large numbers of rows. Performance will usually be improved, and the timing numbers will make more sense. Remember, SQL Server 2019 makes batch mode processing easier to achieve in practice because it does not require a columnstore index.