Wprowadzenie
- Istnieją określone zasady, których należy przestrzegać podczas tworzenia obiektów bazy danych. Aby poprawić wydajność bazy danych, do tabeli należy przypisać klucz podstawowy, indeksy klastrowe i nieklastrowe oraz ograniczenia. Chociaż przestrzegamy wszystkich tych zasad, w tabeli mogą nadal występować zduplikowane wiersze.
- Dobrą praktyką jest zawsze korzystanie z kluczy bazy danych. Korzystanie z kluczy bazy danych zmniejszy szanse na uzyskanie zduplikowanych rekordów w tabeli. Ale jeśli zduplikowane rekordy są już obecne w tabeli, istnieją określone sposoby usuwania tych zduplikowanych rekordów.
Sposoby usuwania zduplikowanych wierszy
- Korzystanie z DELETE JOIN oświadczenie o usunięciu zduplikowanych wierszy
Instrukcja DELETE JOIN jest dostępna w MySQL, która pomaga usunąć zduplikowane wiersze z tabeli.
Rozważ bazę danych o nazwie „studentdb”. Utworzymy w niej tabelę studenta.
mysql> USE studentdb;
Database changed
mysql> CREATE TABLE student (Stud_ID INT, Stud_Name VARCHAR(20), Stud_City VARCHAR(20), Stud_email VARCHAR(255), Stud_Age INT);
Query OK, 0 rows affected (0.15 sec)
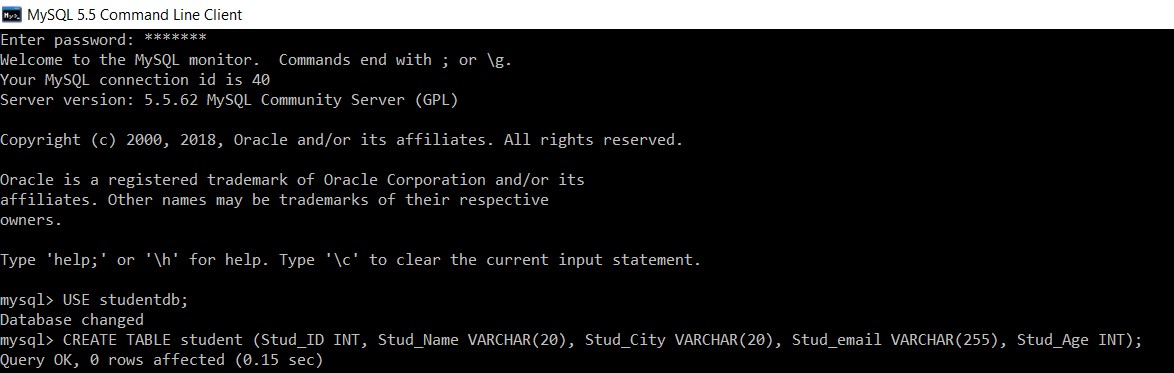
Pomyślnie utworzyliśmy tabelę „student” w bazie danych „studentdb”.
Teraz napiszemy następujące zapytania, aby wstawić dane do tabeli uczniów.
mysql> INSERT INTO student VALUES (1, "Ankit", "Nagpur", "example@sqldat.com", 32);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (2, "Soham", "Nanded", "example@sqldat.com", 35);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (3, "Soham", "Nanded", "example@sqldat.com", 26);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (4, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (5, "Ravi", "Chandigarh", "example@sqldat.com", 19);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (6, "Shyam", "Dehradun", "example@sqldat.com", 22);
Query OK, 1 row affected (0.09 sec)
mysql> INSERT INTO student VALUES (7, "Manthan", "Ambala", "example@sqldat.com", 24);
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO student VALUES (8, "Neeraj", "Noida", "example@sqldat.com", 25);
Query OK, 1 row affected (0.04 sec)
mysql> INSERT INTO student VALUES (9, "Anand", "Kashmir", "example@sqldat.com", 20);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO student VALUES (10, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.13 sec)
mysql> INSERT INTO student VALUES (11, "Raju", "Shimla", "example@sqldat.com", 29);
Query OK, 1 row affected (0.08 sec)
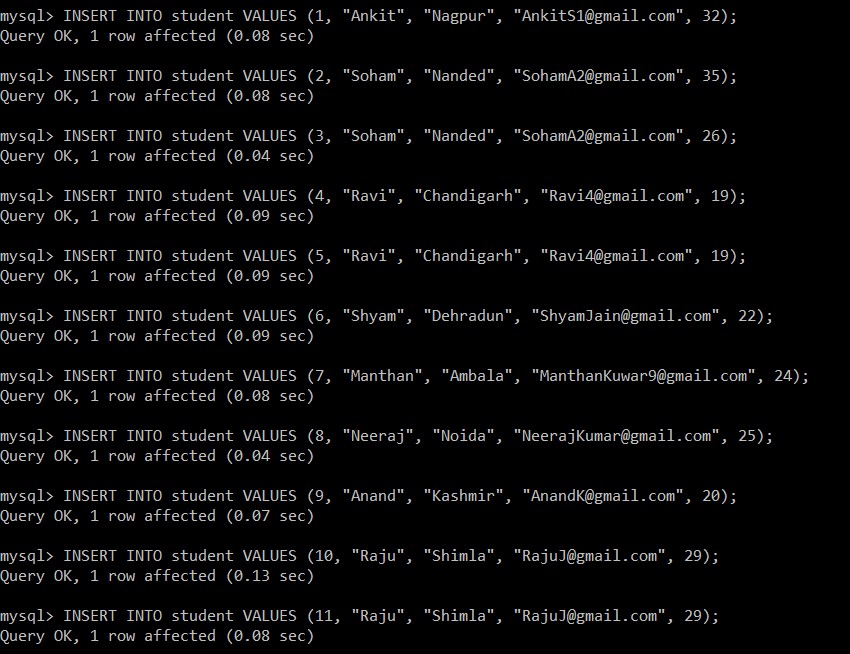
Teraz pobierzemy wszystkie rekordy z tabeli uczniów. Rozważymy tę tabelę i bazę danych we wszystkich poniższych przykładach.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
11 rows in set (0.00 sec)
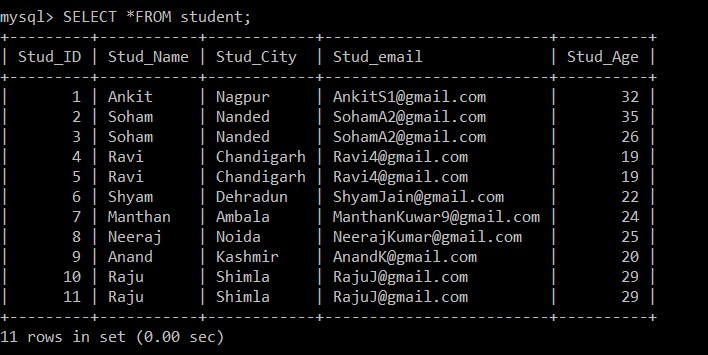
Przykład 1:
Napisz zapytanie, aby usunąć zduplikowane wiersze z tabeli uczniów za pomocą DELETE JOIN oświadczenie.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Użyliśmy zapytania DELETE z INNER JOIN. Aby zaimplementować INNER JOIN na jednej tabeli, utworzyliśmy dwie instancje s1 i s2. Następnie za pomocą klauzuli WHERE sprawdziliśmy dwa warunki, aby znaleźć zduplikowane wiersze w tabeli uczniów. Jeśli identyfikator e-mail w dwóch różnych rekordach jest taki sam, a identyfikator ucznia jest inny, zostanie on potraktowany jako zduplikowany rekord zgodnie z warunkiem klauzuli WHERE.
Wyjście:
Query OK, 3 rows affected (0.20 sec)Wyniki powyższego zapytania pokazują, że w tabeli uczniów znajdują się trzy zduplikowane rekordy.

Użyjemy zapytania SELECT, aby znaleźć zduplikowane rekordy, które zostały usunięte.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 3 | Soham | Nanded | example@sqldat.com | 26 |
| 5 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 11 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
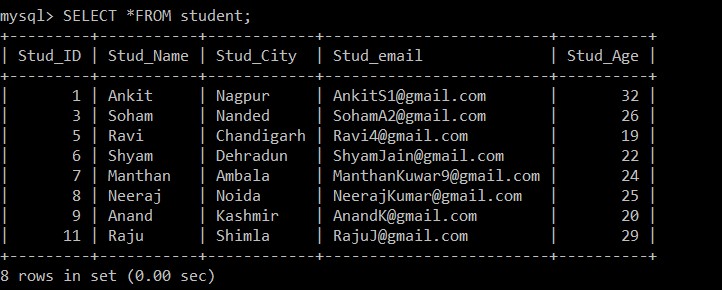
Teraz w tabeli uczniów jest tylko 8 rekordów, ponieważ trzy zduplikowane rekordy są usuwane z aktualnie wybranej tabeli. Zgodnie z następującym warunkiem:
s1.Stud_ID < s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Jeśli identyfikatory e-mail dowolnych dwóch rekordów są takie same, ponieważ między identyfikatorem ucznia jest używany znak mniej niż, zachowany zostanie tylko rekord z większymi identyfikatorami pracowników, a drugi zduplikowany rekord zostanie usunięty między tymi dwoma rekordami.
Przykład 2:
Napisz zapytanie, aby usunąć zduplikowane wiersze z tabeli uczniów, używając instrukcji delete join, zachowując zduplikowany rekord z mniejszym identyfikatorem pracownika i usuwając drugi.
mysql> DELETE s1 FROM student s1 INNER JOIN student s2 WHERE s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Użyliśmy zapytania DELETE z INNER JOIN. Aby zaimplementować INNER JOIN na jednej tabeli, utworzyliśmy dwie instancje s1 i s2. Następnie za pomocą klauzuli WHERE sprawdziliśmy dwa warunki, aby znaleźć wiersze duplikatów w tabeli student. Jeśli identyfikator e-mail obecny w dwóch różnych rekordach jest taki sam, a identyfikator ucznia jest inny, zostanie potraktowany jako zduplikowany rekord zgodnie z warunkiem klauzuli WHERE.
Wyjście:
Query OK, 3 rows affected (0.09 sec)Wyniki powyższego zapytania pokazują, że w tabeli uczniów znajdują się trzy zduplikowane rekordy.

Użyjemy zapytania SELECT, aby znaleźć zduplikowane rekordy, które zostały usunięte.
mysql> SELECT *FROM student;
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
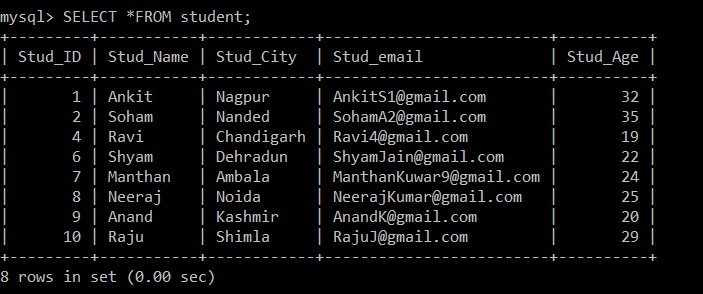
Teraz w tabeli uczniów jest tylko 8 rekordów, ponieważ trzy zduplikowane rekordy są usuwane z aktualnie wybranej tabeli. Zgodnie z następującym warunkiem:
s1.Stud_ID > s2.Stud_ID AND s1.Stud_email = s2.Stud_email;Jeśli identyfikatory e-mail dowolnych dwóch rekordów są takie same, ponieważ znak „większy niż” jest używany między identyfikatorem ucznia, zostanie zachowany tylko rekord z niższym identyfikatorem pracownika, a drugi zduplikowany rekord zostanie usunięty z tych dwóch rekordów.
- Użycie tabeli pośredniej do usuwania zduplikowanych wierszy
Poniższe kroki należy wykonać podczas usuwania zduplikowanych wierszy za pomocą tabeli pośredniej.
- Powinna zostać utworzona nowa tabela, która będzie taka sama jak rzeczywista tabela.
- Dodaj różne wiersze z rzeczywistej tabeli do nowo utworzonej tabeli.
- Upuść aktualną tabelę i zmień nazwę nowej tabeli na taką samą, jak rzeczywista tabela.
Przykład:
Napisz zapytanie, aby usunąć zduplikowane rekordy z tabeli uczniów za pomocą tabeli pośredniej.
Krok 1:
Najpierw utworzymy tabelę pośrednią, która będzie taka sama jak tabela pracowników.
mysql> CREATE TABLE temp_student LIKE student;
Query OK, 0 rows affected (0.14 sec)

Tutaj „pracownik” to oryginalny stół, a „temp_student” to stół pośredni.
Krok 2:
Teraz pobierzemy tylko unikalne rekordy z tabeli uczniów i wstawimy wszystkie pobrane rekordy do tabeli temp_student.
mysql> INSERT INTO temp_student SELECT *FROM student GROUP BY Stud_email;
Query OK, 8 rows affected (0.12 sec)
Records: 8 Duplicates: 0 Warnings: 0

Tutaj, przed wstawieniem odrębnych rekordów z tabeli uczniów do temp_student, wszystkie zduplikowane rekordy są filtrowane przez Stud_email. Następnie do temp_student zostały wstawione tylko rekordy z unikalnym identyfikatorem e-mail.
Krok 3:
Następnie usuniemy stół ucznia i zmienimy nazwę tabeli temp_student na stół ucznia.
mysql> DROP TABLE student;
Query OK, 0 rows affected (0.08 sec)
mysql> ALTER TABLE temp_student RENAME TO student;
Query OK, 0 rows affected (0.08 sec)
Tabela uczniów została pomyślnie usunięta, a nazwa temp_student została zmieniona na tabelę uczniów, która zawiera tylko unikalne rekordy.
Następnie musimy sprawdzić, czy tabela uczniów zawiera teraz tylko unikalne rekordy. Aby to sprawdzić, użyliśmy zapytania SELECT, aby zobaczyć dane zawarte w tabeli uczniów.
mysql> SELECT *FROM student;Wyjście:
+---------+-----------+------------+-------------------------+----------+
| Stud_ID | Stud_Name | Stud_City | Stud_email | Stud_Age |
+---------+-----------+------------+-------------------------+----------+
| 9 | Anand | Kashmir | example@sqldat.com | 20 |
| 1 | Ankit | Nagpur | example@sqldat.com | 32 |
| 7 | Manthan | Ambala | example@sqldat.com | 24 |
| 8 | Neeraj | Noida | example@sqldat.com | 25 |
| 10 | Raju | Shimla | example@sqldat.com | 29 |
| 4 | Ravi | Chandigarh | example@sqldat.com | 19 |
| 6 | Shyam | Dehradun | example@sqldat.com | 22 |
| 2 | Soham | Nanded | example@sqldat.com | 35 |
+---------+-----------+------------+-------------------------+----------+
8 rows in set (0.00 sec)
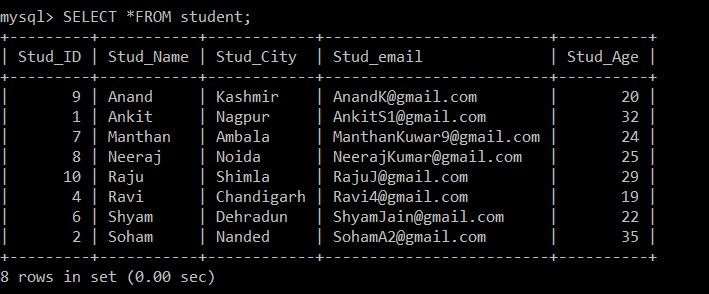
Teraz w tabeli uczniów jest tylko 8 rekordów, ponieważ trzy zduplikowane rekordy są usuwane z aktualnie wybranej tabeli. W kroku 2, podczas pobierania odrębnych rekordów z oryginalnej tabeli i wstawiania ich do tabeli pośredniej, w Stud_email użyto klauzuli GROUP BY, więc wszystkie rekordy zostały wstawione na podstawie identyfikatorów e-mail studentów. Tutaj tylko rekord o niższym identyfikatorze pracownika jest domyślnie przechowywany wśród zduplikowanych rekordów, a drugi jest usuwany.