Ten post ma „załączone zobowiązania:nie bez powodu. Zamierzamy zagłębić się w SQL VARCHAR, typ danych, który zajmuje się łańcuchami.
Jest to również „tylko dla twoich oczu”, ponieważ bez sznurków nie będzie żadnych postów na blogu, stron internetowych, instrukcji do gier, przepisów dodanych do zakładek i wielu innych rzeczy do przeczytania i przyjemności dla naszych oczu. Codziennie mamy do czynienia z miliardem strun. Tak więc, jako programiści, jesteśmy odpowiedzialni za efektywne przechowywanie tego rodzaju danych i uzyskiwanie do nich dostępu.
Mając to na uwadze, omówimy to, co ma największe znaczenie dla pamięci masowej i wydajności. Wprowadź nakazy i zakazy dla tego typu danych.
Ale wcześniej VARCHAR jest tylko jednym z typów ciągów w SQL. Co go wyróżnia?
Co to jest VARCHAR w SQL? (z przykładami)
VARCHAR to łańcuchowy lub znakowy typ danych o różnej wielkości. Możesz przechowywać w nim litery, cyfry i symbole. Począwszy od SQL Server 2019, podczas sortowania z obsługą UTF-8 można używać pełnego zakresu znaków Unicode.
Możesz deklarować kolumny lub zmienne VARCHAR za pomocą VARCHAR[(n)], gdzie n oznacza rozmiar łańcucha w bajtach. Zakres wartości dla n wynosi od 1 do 8000. To dużo danych znakowych. Ale co więcej, możesz to zadeklarować za pomocą VARCHAR(MAX), jeśli potrzebujesz gigantycznego ciągu do 2 GB. To wystarczająco dużo, by pomieścić listę sekretów i prywatnych rzeczy w Twoim pamiętniku! Pamiętaj jednak, że możesz również zadeklarować go bez rozmiaru i jeśli to zrobisz, domyślnie przyjmuje wartość 1.
Miejmy przykład.
DECLARE @actor VARCHAR(20) ='Robert Downey Jr.';DECLARE @movieCharacter VARCHAR(10) ='Iron Man';DECLARE @movie VARCHAR ='Avengers';SELECT @actor, @movieCharacter, @film 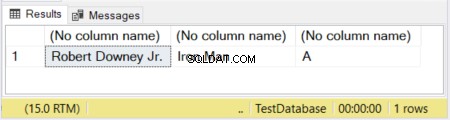
Na rysunku 1 pierwsze 2 kolumny mają zdefiniowane rozmiary. Trzecia kolumna pozostaje bez rozmiaru. Tak więc słowo „Avengers” zostało obcięte, ponieważ VARCHAR bez zadeklarowanego rozmiaru ma domyślnie 1 znak.
Teraz spróbujmy czegoś ogromnego. Pamiętaj jednak, że uruchomienie tego zapytania zajmie trochę czasu – 23 sekundy na moim laptopie.
-- To zajmie chwilę DECLARE @giganticString VARCHAR(MAX);SET @giganticString =REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)SELECT DATALENGTH(@giganticString) 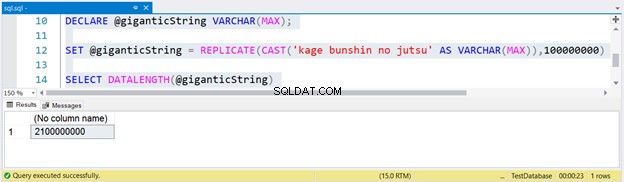
Aby wygenerować ogromną strunę, 100 milionów razy zreplikowaliśmy kage bunshin no jutsu. Zwróć uwagę na CAST w REPLICATE. Jeśli nie przerzucisz wyrażenia łańcuchowego na VARCHAR(MAX), wynik zostanie obcięty do maksymalnie 8000 znaków.
Ale jak SQL VARCHAR wypada w porównaniu z innymi typami danych łańcuchowych?
Różnica między CHAR i VARCHAR w SQL
W porównaniu z VARCHAR, CHAR jest typem danych znakowych o stałej długości. Bez względu na to, jak małą lub dużą wartość umieścisz w zmiennej CHAR, ostateczny rozmiar to rozmiar zmiennej. Sprawdź porównania poniżej.
DECLARE @tvSeriesTitle1 VARCHAR(20) ='Mandalorianin';DECLARE @tvSeriesTitle2 CHAR(20) ='Mandalorianin';SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue, DATALENGTH(@tvSeriesTitle2) AS CharValue kod> 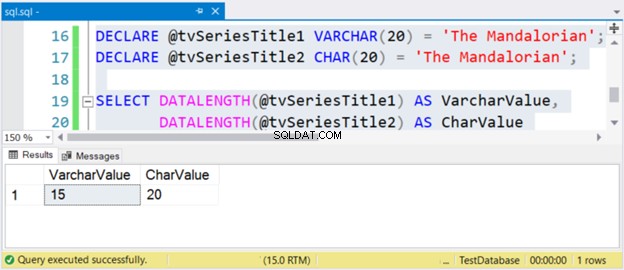
Długość ciągu „The Mandalorian” to 15 znaków. Tak więc VarcharValue kolumna poprawnie to odzwierciedla. Jednak CharValue zachowuje rozmiar 20 – jest wyściełany 5 spacjami po prawej stronie.
SQL VARCHAR vs NVARCHAR
Podczas porównywania tych typów danych przychodzą na myśl dwie podstawowe rzeczy.
Po pierwsze jest to rozmiar w bajtach. Każdy znak w NVARCHAR ma dwa razy większy rozmiar niż VARCHAR. NVARCHAR(n) wynosi tylko od 1 do 4000.
Następnie postacie, które może przechowywać. NVARCHAR może przechowywać znaki wielojęzyczne, takie jak koreański, japoński, arabski itp. Jeśli planujesz przechowywać koreańskie teksty piosenek K-Pop w swojej bazie danych, ten typ danych jest jedną z Twoich opcji.
Miejmy przykład. Będziemy używać grupy K-popowej 세븐틴 lub Seventeen po angielsku.
DECLARE @kpopGroupKorean NVARCHAR(5) =N'세븐틴';SELECT @kpopGroupKorean AS KPopGroup, DATALENGTH(@kpopGroupKorean) AS SizeInBytes, LEN(@kpopGroupKorean) AS [NoOfChars] Powyższy kod wyświetli wartość ciągu, jego rozmiar w bajtach i liczbę znaków. Jeśli są to znaki inne niż Unicode, liczba znaków jest równa rozmiarowi w bajtach. Ale tak nie jest. Sprawdź Rysunek 4 poniżej.
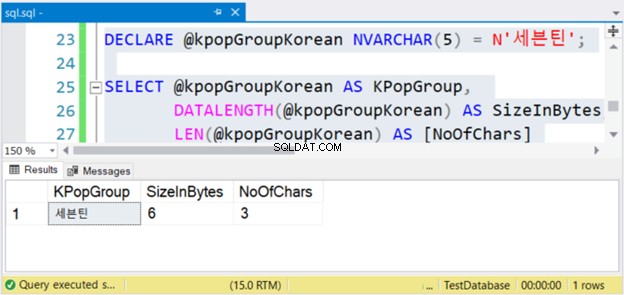
Widzieć? Jeśli NVARCHAR ma 3 znaki, rozmiar w bajtach jest podwójny. Ale nie z VARCHAR. To samo dotyczy również znaków angielskich.
Ale co z NCHAR? NCHAR jest odpowiednikiem CHAR dla znaków Unicode.
SQL Server VARCHAR z obsługą UTF-8
VARCHAR z obsługą UTF-8 jest możliwy na poziomie serwera, bazy danych lub na poziomie kolumny tabeli poprzez zmianę informacji o sortowaniu. Zestawienie do użycia powinno obsługiwać UTF-8.
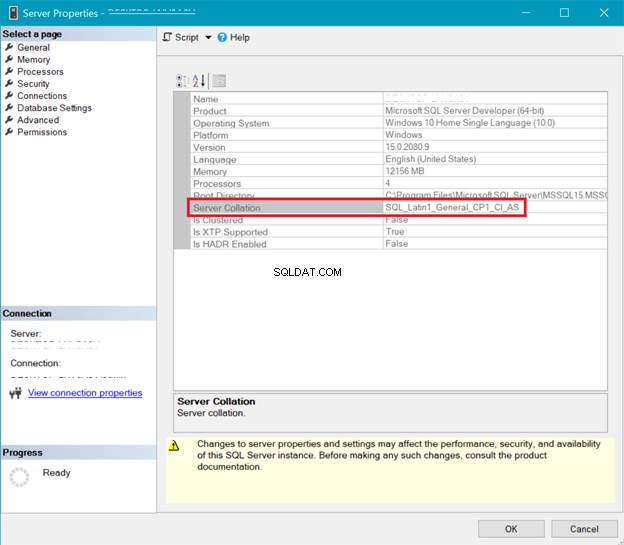
UKŁADANIE SERWERÓW SQL
Rysunek 5 przedstawia okno w SQL Server Management Studio, które pokazuje sortowanie serwerów.
POKŁADOWANIE BAZY DANYCH
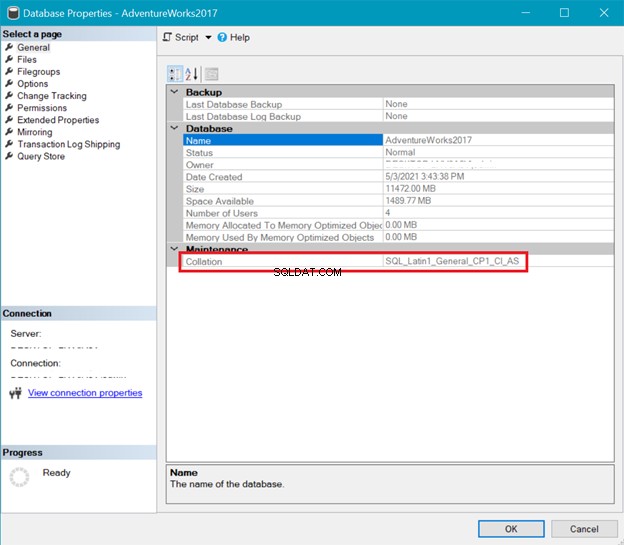
Tymczasem Rysunek 6 przedstawia zestawienie AdventureWorks baza danych.
UKŁADANIE KOLUMN TABELI
Zarówno powyższe sortowanie serwera, jak i bazy danych pokazuje, że UTF-8 nie jest obsługiwany. Ciąg sortowania powinien zawierać _UTF8 dla obsługi UTF-8. Ale nadal możesz używać obsługi UTF-8 na poziomie kolumny tabeli. Zobacz przykład.
CREATE TABLE SeventeenMemberList( id INT NOT NULL IDENTITY(1,1) PRIMARY KEY, KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL, EnglishName VARCHAR(20) NOT NULL) Powyższy kod ma Latin1_General_100_BIN2_UTF8 porównanie dla KoreanName kolumna. Chociaż VARCHAR, a nie NVARCHAR, ta kolumna akceptuje znaki języka koreańskiego. Wstawmy kilka rekordów, a następnie przejrzyjmy je.
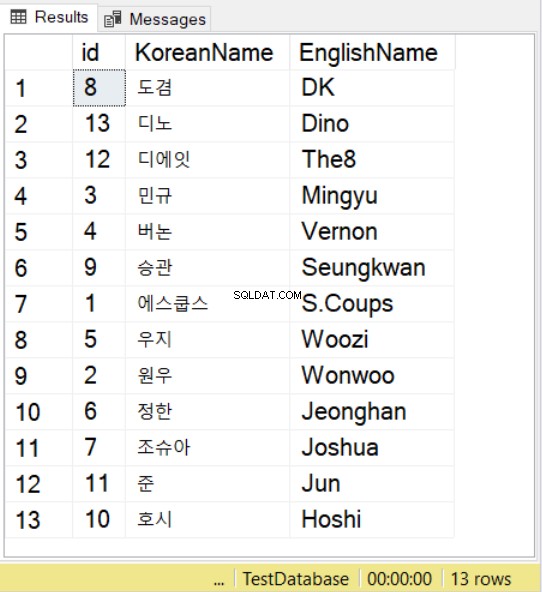
INSERT INTO SeventeenMemberList(KoreanName, EnglishName)VALUES (N'에스쿱스','S.Coups'),(N'원우','Wonwoo'),(N'민규','Mingyu') ,(N'버논','Vernon'),(N'우지','Woozi'),(N'정한','Jeonghan'),(N'조슈아','Joshua'),(N'도겸' ,'DK'),(N'승관','Seungkwan'),(N'호시','Hoshi'),(N'준','Jun'),(N'디에잇','The8') ,(N'디노','Dino')SELECT * FROM SiedemnastuCzłonków ORDER BY KoreanNameCOLLATE Latin1_General_100_BIN2_UTF8 Używamy nazw z grupy Seventeen K-pop, używając odpowiedników koreańskich i angielskich. W przypadku znaków koreańskich zwróć uwagę, że nadal musisz poprzedzić wartość N , podobnie jak to, co robisz z wartościami NVARCHAR.
Następnie, używając SELECT z ORDER BY, możesz również użyć sortowania. Możesz to zaobserwować w powyższym przykładzie. Będzie to zgodne z regułami sortowania dla określonego sortowania.
PRZECHOWYWANIE VARCHAR Z OBSŁUGĄ UTF-8
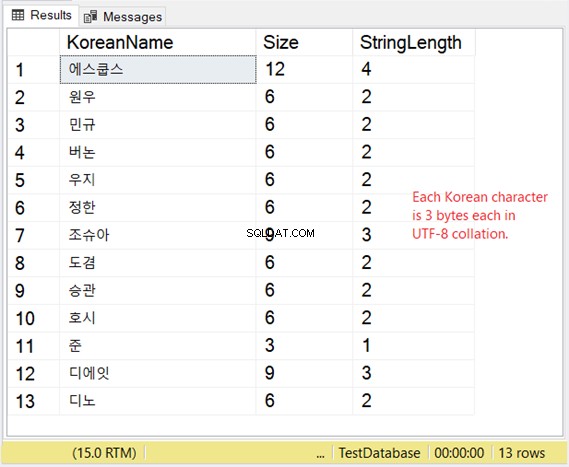
Ale jak wygląda przechowywanie tych postaci? Jeśli oczekujesz 2 bajtów na znak, czeka Cię niespodzianka. Sprawdź rysunek 8.
Tak więc, jeśli pamięć ma dla ciebie duże znaczenie, rozważ poniższą tabelę podczas korzystania z VARCHAR z obsługą UTF-8.
| Znaki | Rozmiar w bajtach |
| Ascii 0 – 127 | 1 |
| Skrypt łaciński oraz grecki, cyrylica, koptyjski, ormiański, hebrajski, arabski, syryjski, tāna i n’ko | 2 |
| pismo wschodnioazjatyckie, takie jak chiński, koreański i japoński | 3 |
| Znaki z zakresu 010000–10FFFF | 4 |
Nasz koreański przykład to skrypt wschodnioazjatycki, więc ma 3 bajty na znak.
Teraz, gdy skończyliśmy opisywać i porównywać VARCHAR z innymi typami łańcuchów, omówimy teraz nakazy i zakazy
Co robić w używaniu VARCHAR w SQL Server
1. Określ rozmiar
Co może pójść nie tak bez określenia rozmiaru?
OBCIĘCIE STRINGU
Jeśli będziesz leniwy przy określaniu rozmiaru, nastąpi obcięcie ciągu. Widziałeś już wcześniej tego przykład.
WPŁYW NA PRZECHOWYWANIE I WYDAJNOŚĆ
Inną kwestią jest pamięć i wydajność. Musisz tylko ustawić odpowiedni rozmiar dla swoich danych, a nie więcej. Ale skąd możesz wiedzieć? Aby uniknąć obcięcia w przyszłości, możesz po prostu ustawić go na największy rozmiar. To jest VARCHAR(8000) lub nawet VARCHAR(MAX). A 2 bajty będą przechowywane bez zmian. To samo z 2 GB. Czy to ma znaczenie?
Udzielenie odpowiedzi doprowadzi nas do koncepcji przechowywania danych w SQL Server. Mam inny artykuł wyjaśniający to szczegółowo z przykładami i ilustracjami.
Krótko mówiąc, dane są przechowywane na stronach 8KB. Gdy wiersz danych przekracza ten rozmiar, SQL Server przenosi go do innej jednostki alokacji stron o nazwie ROW_OVERFLOW_DATA.
Załóżmy, że masz 2-bajtowe dane VARCHAR, które mogą pasować do oryginalnej jednostki alokacji strony. Gdy zapiszesz ciąg większy niż 8000 bajtów, dane zostaną przeniesione na stronę przepełnienia wierszy. Następnie zmniejsz go ponownie do mniejszego rozmiaru, a zostanie przeniesiony z powrotem na oryginalną stronę. Ruch tam i z powrotem powoduje wiele operacji we/wy i wąskie gardło wydajności. Pobranie tego z 2 stron zamiast 1 wymaga również dodatkowego I/O.
Innym powodem jest indeksowanie. VARCHAR(MAX) to duże NO jako klucz indeksu. Tymczasem VARCHAR(8000) przekroczy maksymalny rozmiar klucza indeksu. To jest 1700 bajtów dla indeksów nieklastrowanych i 900 bajtów dla indeksów klastrowych.
WPŁYW KONWERSJI DANYCH
Jest jednak jeszcze jedna uwaga:konwersja danych. Wypróbuj z CAST bez rozmiaru, jak w poniższym kodzie.
SELECT SYSDATETIMEOFFSET() AS DateTimeInput,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength Ten kod dokona konwersji daty/czasu z informacją o strefie czasowej na VARCHAR.
Tak więc, jeśli będziemy leniwi przy określaniu rozmiaru podczas CAST lub CONVERT, wynik jest ograniczony tylko do 30 znaków.
Co powiesz na konwersję NVARCHAR na VARCHAR z obsługą UTF-8? Szczegółowe wyjaśnienie znajduje się później, więc czytaj dalej.
2. Użyj VARCHAR, jeśli rozmiar ciągu znacznie się różni
Nazwiska z AdventureWorks bazy danych różnią się wielkością. Jedną z najkrótszych nazw jest Min Su, a najdłuższą jest Osarumwense Uwaifiokun Agbonile. To od 6 do 31 znaków, w tym spacje. Zaimportujmy te nazwy do 2 tabel i porównajmy VARCHAR i CHAR.
-- Tabela używająca VARCHARCREATE TABLE VarcharAsIndexKey( id INT NOT NULL IDENTITY(1,1) PRIMARY KEY, varcharName VARCHAR(50) NOT NULL)GOCREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexTABLE-TableI-CHARGO-REchar Table CharAsIndexKey( id INT NOT NULL IDENTITY(1,1) PRIMARY KEY, charName CHAR(50) NOT NULL)GOCREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)GOINSERT INTO VarcharAsIndexKey (varcharName)ULL DISTINCTL' +Name (Drugie imię,'')FROM AdventureWorks.Person.Person INSERT INTO CharAsIndexKey (charName)SELECT DISTINCTLastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')FROM AdventureWorks.Person.Person GO Które z 2 są lepsze? Sprawdźmy odczyty logiczne, korzystając z poniższego kodu i sprawdzając dane wyjściowe STATISTICS IO.
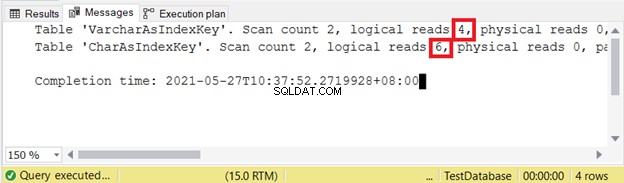
SET NOCOUNT ONSET STATISTICS IO ONSELECT id, varcharNameFROM VarcharAsIndexKeySELECT id, charNameFROM CharAsIndexKeySET STATISTICS IO OFF Odczyty logiczne:
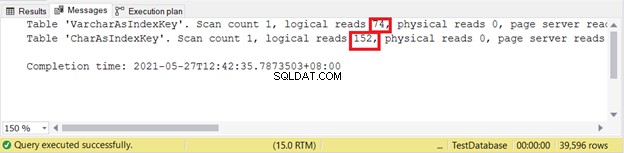
Im mniej logiczne czytanie, tym lepiej. W tym przypadku kolumna CHAR użyła więcej niż podwójnego odpowiednika VARCHAR. W ten sposób VARCHAR wygrywa w tym przykładzie.
3. Użyj VARCHAR jako klucza indeksu zamiast CHAR, gdy wartości różnią się rozmiarem
Co się stało, gdy użyto go jako klucza indeksu? Czy CHAR wypadnie lepiej niż VARCHAR? Użyjmy tych samych danych z poprzedniej sekcji i odpowiedzmy na to pytanie.
Prześlemy niektóre dane i sprawdzimy odczyty logiczne. W tym przykładzie filtr używa klucza indeksu.
SET NOCOUNT ONSET STATISTICS IO ONSELECT nazwa_zmienna FROM Nazwa_zmiennej_index WHERE Nazwa_zmiennej ='Sai, Adriana A' OR Nazwa_zmiennej ='Rogers, Caitlin D'SELECT Nazwa_znaka FROM Znak_IndexKey WHERE Nazwa_znaka ='Sai, Adriana A' OR Rogers, Caitlin D'SET STATISTICS IO WYŁĄCZONE Odczyty logiczne:
Dlatego klucze indeksu VARCHAR są lepsze niż klucze indeksu CHAR, gdy klucz ma różne rozmiary. Ale co powiesz na INSERT i UPDATE, które zmienią wpisy indeksu?
GDY UŻYWASZ WSTAW I AKTUALIZUJ
Przetestujmy 2 przypadki, a następnie sprawdźmy odczyty logiczne, tak jak zwykle.
USTAW STATYSTYKI IO ONWSTAW W VarcharAsIndexKey (varcharName)VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')INSERT INTO CharAsIndexKey (charName)VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')WYŁĄCZ STATYSTYKI IO Odczyty logiczne:
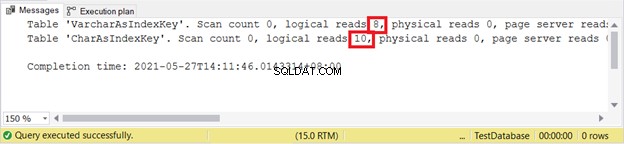
VARCHAR jest jeszcze lepszy podczas wstawiania rekordów. A może AKTUALIZACJA?
SET STATISTICS IO ONUPDATE VarcharAsIndexKeySET varcharName ='Hulk'WHERE varcharName ='Ruffalo, Mark'UPDATE CharAsIndexKeySET charName ='Hulk'WHERE charName ='Ruffalo, Mark'SET STATISTICS> IO OFF
Odczyty logiczne:
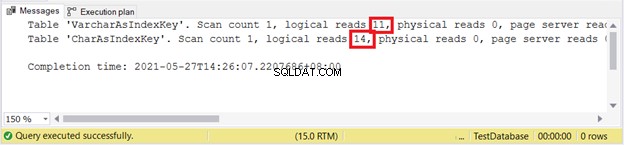
Wygląda na to, że VARCHAR ponownie wygrywa.
Ostatecznie wygrywa nasz test, chociaż może być mały. Czy masz większy przypadek testowy, który dowodzi czegoś przeciwnego?
4. Rozważ VARCHAR z obsługą UTF-8 dla danych wielojęzycznych (SQL Server 2019+)
Jeśli w twojej tabeli jest mieszanka znaków Unicode i innych niż Unicode, możesz rozważyć VARCHAR z obsługą UTF-8 przez NVARCHAR. Jeśli większość znaków mieści się w zakresie od ASCII 0 do 127, może to zapewnić oszczędność miejsca w porównaniu do NVARCHAR.
Aby zobaczyć, co mam na myśli, zróbmy porównanie.
NVARCHAR NA VARCHAR Z OBSŁUGĄ UTF-8
Czy zmigrowałeś już swoje bazy danych do SQL Server 2019? Czy planujesz migrację danych ciągów do sortowania UTF-8? Aby dać Ci wyobrażenie, przedstawimy przykład mieszanej wartości znaków japońskich i niejapońskich.
<> CREATE TABLE NVarcharToVarcharUTF8( NVarcharValue NVARCHAR(20) NOT NULL, VarcharUTF8 VARCHAR(45) UKŁADANIE Latin1_General_100_BIN2_UTF8 NOT NULL)GOINSERT INTO NVarcharToVarchar'Varchar- ar-UTF8(FAlu)' NARUTO-ナルト- 疾風伝'); -- NARUTO ShippûdenSELECT NVarcharValue,LEN(NVarcharValue) AS nvarcharNoOfChars ,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes,VarcharUTF8,LEN(VarcharUTF8) AS varcharVarchNarchB Teraz, gdy dane są ustawione, sprawdzimy rozmiar w bajtach dwóch wartości:

Niespodzianka! W przypadku NVARCHAR rozmiar wynosi 30 bajtów. To 15 razy więcej niż 2 znaki. Ale po konwersji na VARCHAR z obsługą UTF-8 rozmiar to tylko 27 bajtów. Dlaczego 27? Sprawdź, jak to jest obliczane.

Tak więc 9 znaków ma 1 bajt każdy. To interesujące, ponieważ w przypadku NVARCHAR litery angielskie mają również 2 bajty. Pozostałe japońskie znaki mają po 3 bajty.
Gdyby były to wszystkie znaki japońskie, 15-znakowy ciąg miałby 45 bajtów i zajmowałby maksymalny rozmiar VarcharUTF8 kolumna. Zauważ, że rozmiar NVarcharValue kolumna jest mniejsza niż VarcharUTF8 .
Rozmiary nie mogą być równe podczas konwersji z NVARCHAR lub dane mogą nie pasować. Możesz odwołać się do poprzedniej Tabeli 1.
Rozważ wpływ na rozmiar podczas konwersji NVARCHAR na VARCHAR z obsługą UTF-8.
Zabrania się używania VARCHAR w SQL Server
1. Gdy rozmiar łańcucha jest stały i nie dopuszcza wartości null, użyj zamiast tego znaku CHAR.
Ogólną zasadą praktyczną, gdy wymagany jest ciąg o stałym rozmiarze, jest użycie CHAR. Postępuję zgodnie z tym, gdy mam wymagania dotyczące danych, które wymagają spacji z prawej strony. W przeciwnym razie użyję VARCHAR. Miałem kilka przypadków użycia, kiedy musiałem zrzucić ciągi o stałej długości bez ograniczników do pliku tekstowego dla klienta.
Ponadto używam kolumn CHAR tylko wtedy, gdy kolumny nie będą dopuszczać wartości null. Czemu? Ponieważ rozmiar w bajtach kolumn CHAR, gdy NULL jest równy zdefiniowanemu rozmiarowi kolumny. Jednak VARCHAR, gdy NULL ma rozmiar 1, bez względu na zdefiniowany rozmiar. Uruchom poniższy kod i przekonaj się sam.
DECLARE @charValue CHAR(50) =NULL;DECLARE @varcharValue VARCHAR(1000) =NULL;SELECT DATALENGTH(ISNULL(@charvalue,0)) AS CharSize,DATALENGTH(ISNULL(@varcharvalue,0)) JAKO VarcharSize 2. Nie używaj VARCHAR(n) Jeśli n Przekroczy 8000 bajtów. Zamiast tego użyj VARCHAR(MAX).
Czy masz ciąg, który przekroczy 8000 bajtów? Nadszedł czas, aby użyć VARCHAR(MAX). Ale w przypadku najpopularniejszych form danych, takich jak nazwy i adresy, VARCHAR(MAX) jest przesadą i wpłynie na wydajność. Z mojego osobistego doświadczenia nie pamiętam wymogu, abym używał VARCHAR(MAX).
3. Podczas korzystania ze znaków wielojęzycznych w programie SQL Server 2017 i niższych. Zamiast tego użyj NVARCHAR.
Jest to oczywisty wybór, jeśli nadal używasz SQL Server 2017 i starszych.
Konkluzja
Typ danych VARCHAR dobrze nam służył w tak wielu aspektach. Tak było od czasu SQL Server 7. Jednak czasami nadal dokonujemy złych wyborów. W tym poście SQL VARCHAR jest zdefiniowany i porównany z innymi typami danych łańcuchowych z przykładami. I znowu, oto nakazy i zakazy dotyczące szybszej bazy danych:
Co należy:
- Określ rozmiar n w VARCHAR[(n)], nawet jeśli jest to opcjonalne.
- Użyj go, gdy rozmiar ciągu znacznie się różni.
- Uważaj kolumny VARCHAR za klucze indeksu zamiast CHAR.
- A jeśli używasz teraz SQL Server 2019, rozważ VARCHAR dla wielojęzycznych ciągów z obsługą UTF-8.
Nie:
- Nie używaj VARCHAR, gdy rozmiar łańcucha jest stały i nie może zawierać wartości null.
- Nie używaj VARCHAR(n), gdy rozmiar ciągu przekroczy 8000 bajtów.
- I nie używaj VARCHAR do wielojęzycznych danych podczas korzystania z SQL Server 2017 i wcześniejszych.
Masz coś jeszcze do dodania? Daj nam znać w sekcji Komentarze. Jeśli uważasz, że to pomoże twoim znajomym programistom, udostępnij to na swoich ulubionych platformach społecznościowych.