Daniel Keys Moran mówi:„Możesz mieć dane bez informacji, ale nie możesz mieć informacji bez danych”. Dane są kluczowym zasobem w każdej organizacji, jeśli stracisz dane, stracisz informacje. To z kolei może prowadzić do złych decyzji biznesowych lub nawet braku możliwości działania firmy. Posiadanie planu odzyskiwania danych po awarii jest koniecznością, a chmura może być tutaj szczególnie pomocna. Wykorzystując pamięć masową w chmurze, nie musisz przygotowywać pamięci masowej do przechowywania danych kopii zapasowych ani wydawać pieniędzy z góry na drogie systemy pamięci masowej. Amazon S3 i Google Cloud Storage to świetne opcje, ponieważ są niezawodne, niedrogie i trwałe.
Wcześniej pisaliśmy o przechowywaniu kopii zapasowych PostgreSQL na AWS, a także na GCP. Spójrzmy więc na kilka wskazówek dotyczących przechowywania kopii zapasowych danych TimescaleDB w AWS S3 i Cloud Storage.
Przygotowywanie zasobnika AWS S3
AWS zapewnia prosty interfejs sieciowy do zarządzania danymi w AWS S3. Termin wiadro jest podobny do „katalogu” w tradycyjnych terminach przechowywania w systemie plików, jest to logiczny pojemnik na obiekty.
Tworzenie nowego zasobnika w S3 jest łatwe, możesz przejść bezpośrednio do menu S3 i utworzyć nowy zasobnik, jak pokazano poniżej:
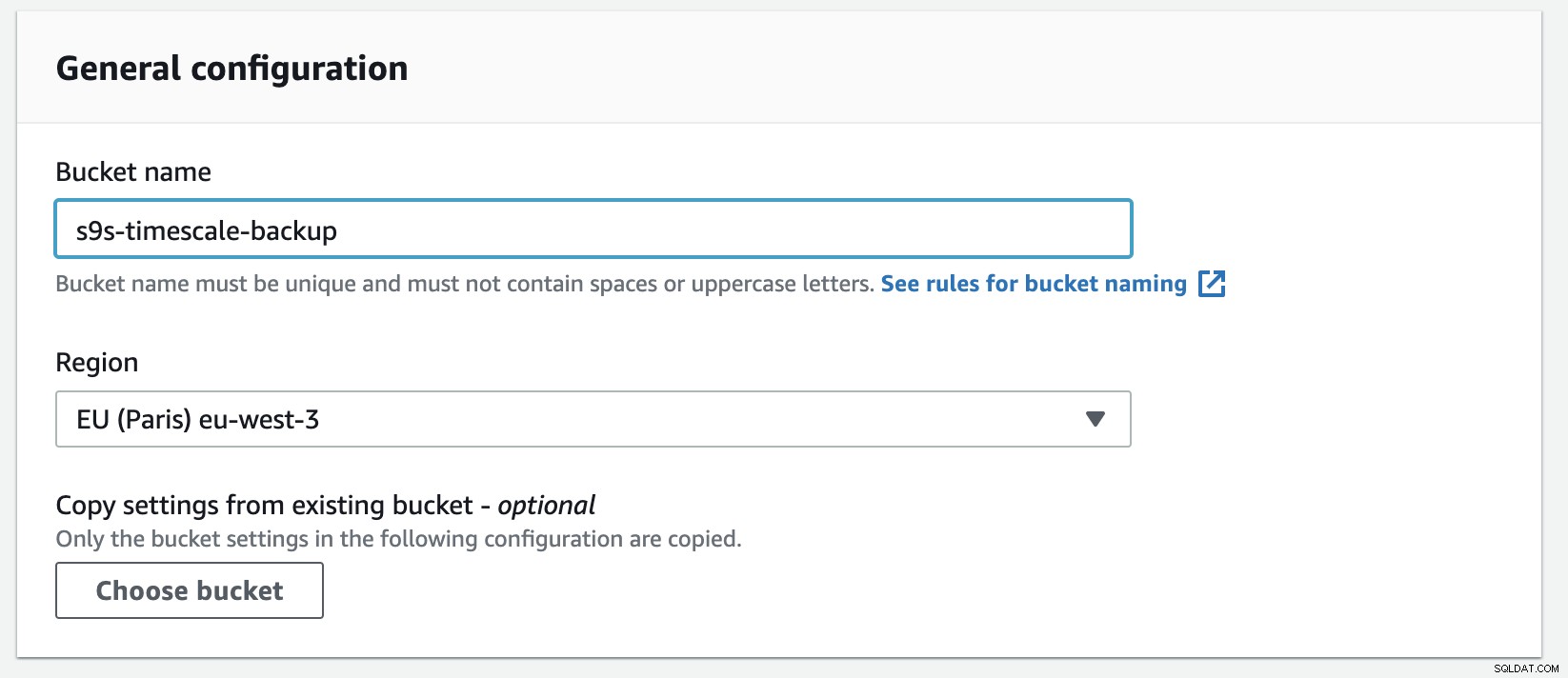
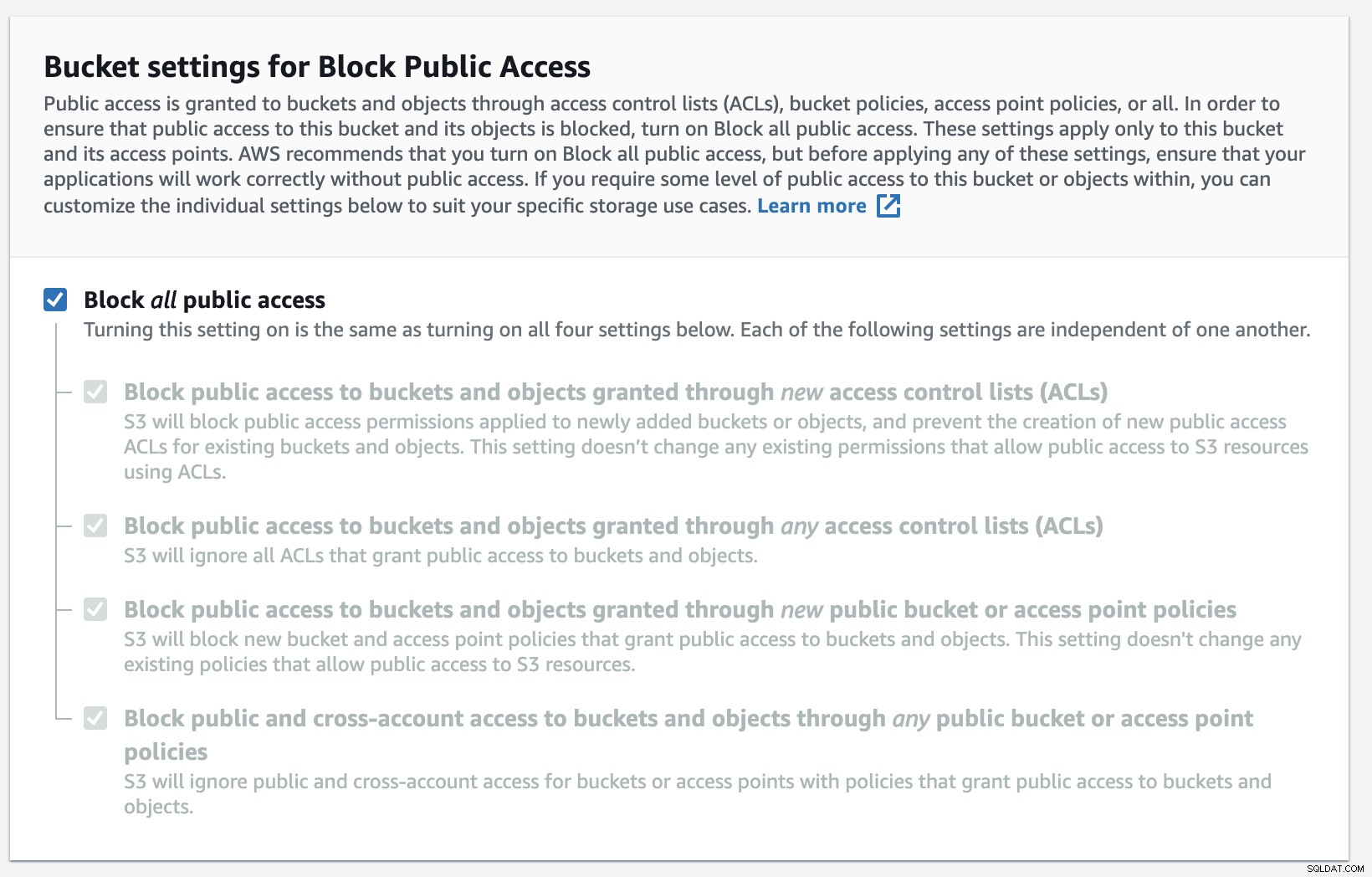
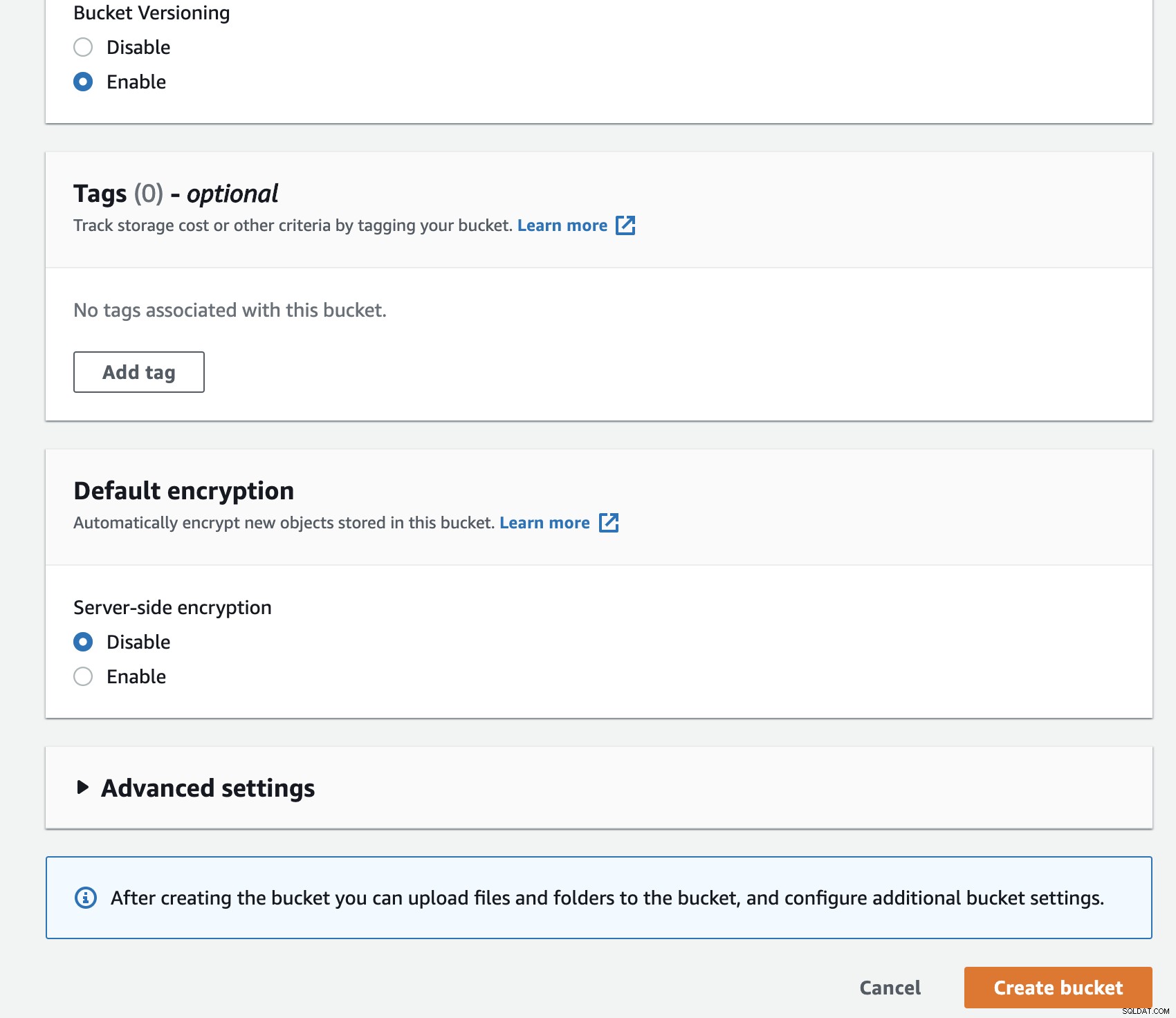
Musisz wypełnić nazwę zasobnika, nazwa jest globalnie unikalna na AWS jako przestrzeń nazw jest współużytkowana przez wszystkie konta AWS. Możesz ograniczyć dostęp do zasobnika z Internetu lub opublikować go z ograniczeniami ACL. Szyfrowanie to ważna praktyka zabezpieczania danych kopii zapasowej.
Przygotowywanie zasobnika Google Cloud Storage
Aby skonfigurować przechowywanie w chmurze w GCP, możesz przejść do kategorii Pamięć i wybrać Pamięć -> Utwórz zasobnik. Wpisz nazwę zasobnika, podobnie jak w Amazon S3, a nazwa zasobnika jest również globalnie unikalna w GCP.
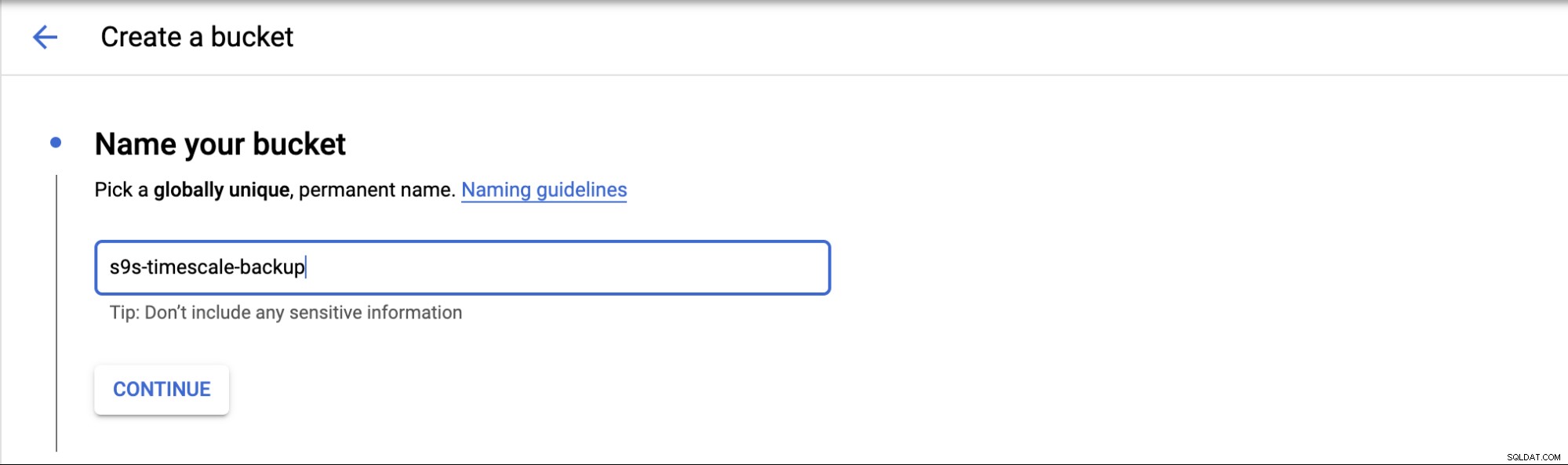
Wybierz, gdzie będziesz przechowywać kopię zapasową, istnieją trzy rodzaje lokalizacji; możesz przechowywać w jednym regionie, podwójnym regionie lub wielu regionach.
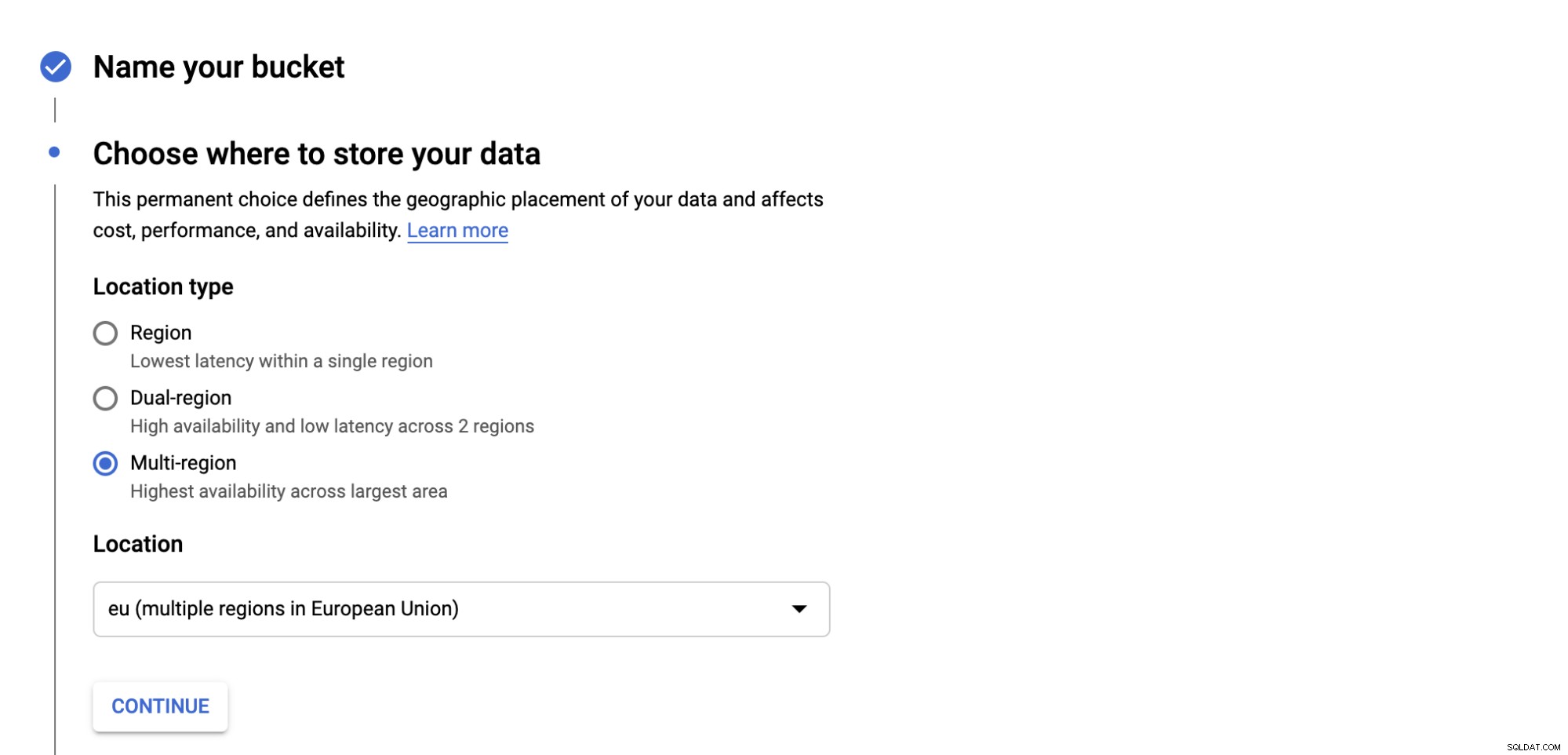
Wybierz typ klasy pamięci dla swojego zasobnika, są cztery kategorie, które są; Standardowe, Nearline, Coldline i Archive. Każda kategoria ma kryteria dotyczące sposobu pobierania danych, a także koszt.

Istnieje kilka zaawansowanych ustawień związanych z szyfrowaniem zasobników, zasadami przechowywania i kontroli dostępu.
Konfiguruj narzędzie do przechowywania w chmurze
AWS CLI to interfejs dostarczany przez AWS do interakcji z usługami AWS, takimi jak S3, EC2, grupy bezpieczeństwa, VPC itp. za pośrednictwem wiersza poleceń. Możesz skonfigurować interfejs AWS CLI w węźle, w którym znajdują się pliki kopii zapasowej, zanim prześlesz pliki do S3. Możesz postępować zgodnie z procedurą instalacji dla AWS CLI tutaj.
Możesz sprawdzić swoją wersję AWS CLI, uruchamiając poniższe polecenie:
example@sqldat.com:~# /usr/local/bin/aws --version
aws-cli/2.1.7 Python/3.7.3 Linux/4.15.0-91-generic exe/x86_64.ubuntu.18 prompt/offNastępnie musisz skonfigurować klucz dostępu i klucz tajny z serwera, jak poniżej:
example@sqldat.com:~# aws configure
AWS Access Key ID [None]: AKIAREF*******AMKYUY
AWS Secret Access Key [None]: 4C6Cjb1zAIMRfYy******1T16DNXE0QJ3gEb
Default region name [None]: ap-southeast-1
Default output format [None]:W takim razie możesz uruchomić i przenieść kopię zapasową do swojego zasobnika.
$ aws s3 cp “/mnt/backups/BACKUP-1/full-backup-20201201.tar.gz” s3://s9s-timescale-backup/Możesz utworzyć skrypt powłoki dla powyższego polecenia i skonfigurować harmonogram do codziennego uruchamiania.
GCP udostępnia narzędzie GSUtil, które umożliwia dostęp do Cloud Storage za pomocą wiersza poleceń. Procedurę instalacji GSUtil można znaleźć tutaj. Po instalacji możesz uruchomić gcloud init, aby skonfigurować dostęp do GCP.
example@sqldat.com:~# gcloud initPoprosi Cię o zalogowanie się do Google Cloud poprzez dostęp do adresu URL i dodanie kodu uwierzytelniającego.
Po skonfigurowaniu możesz uruchomić transfer kopii zapasowej do Cloud Storage, uruchamiając następujące polecenie:
example@sqldat.com:~# gsutil cp /mnt/backups/BACKUP-1/full-backup-20201201.tar.gz gs://s9s-timescale-backup/Zarządzaj kopią zapasową za pomocą ClusterControl
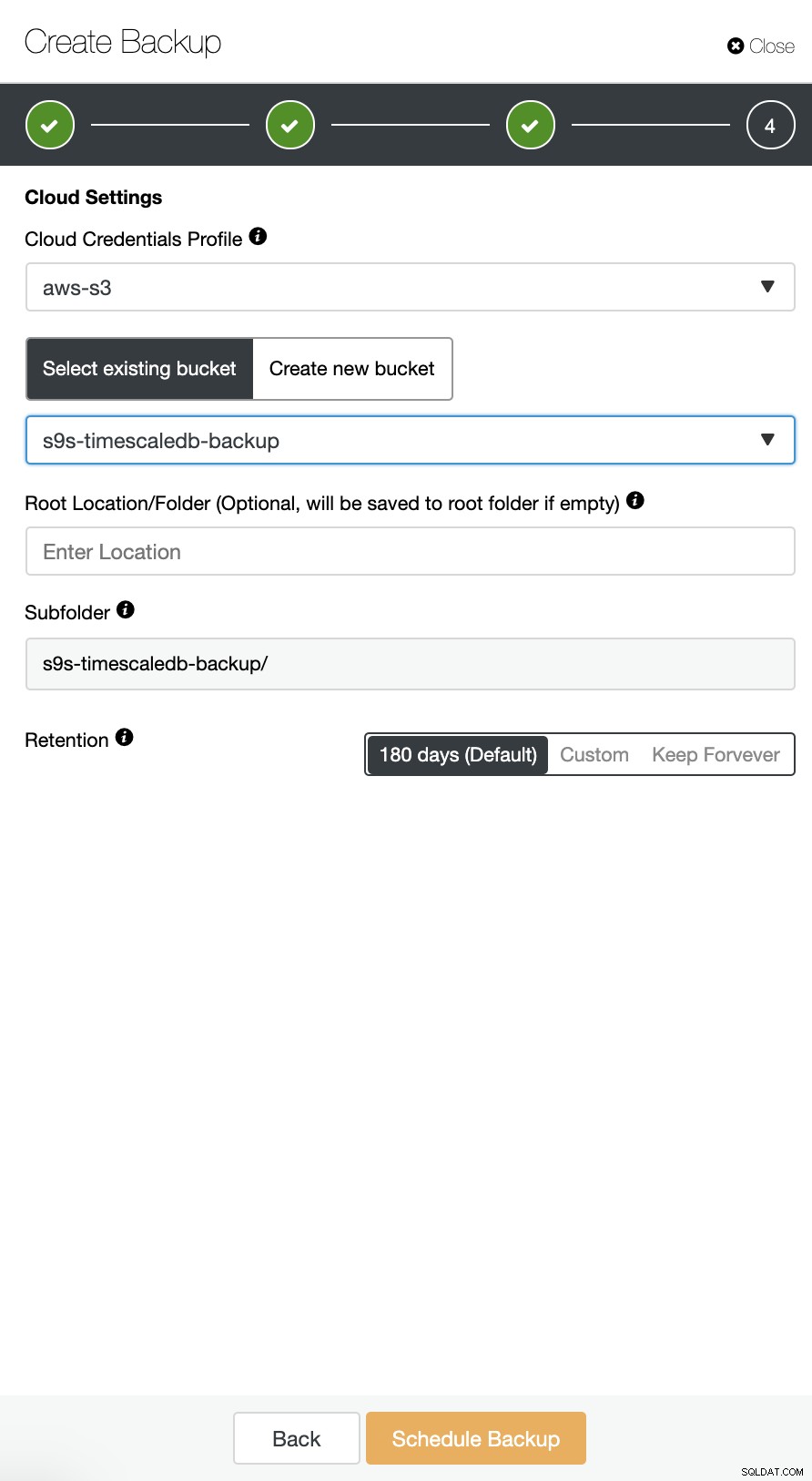
ClusterControl obsługuje przesyłanie kopii zapasowych TimeScaleDB do chmury. Obecnie obsługujemy Amazon AWS, Google Cloud Platform oraz Microsoft Azure. Aby skonfigurować kopię zapasową TimescaleDB w chmurze jest bardzo proste, możesz przejść do kopii zapasowej w klastrze TimescaleDB i utworzyć kopię zapasową, jak pokazano poniżej:
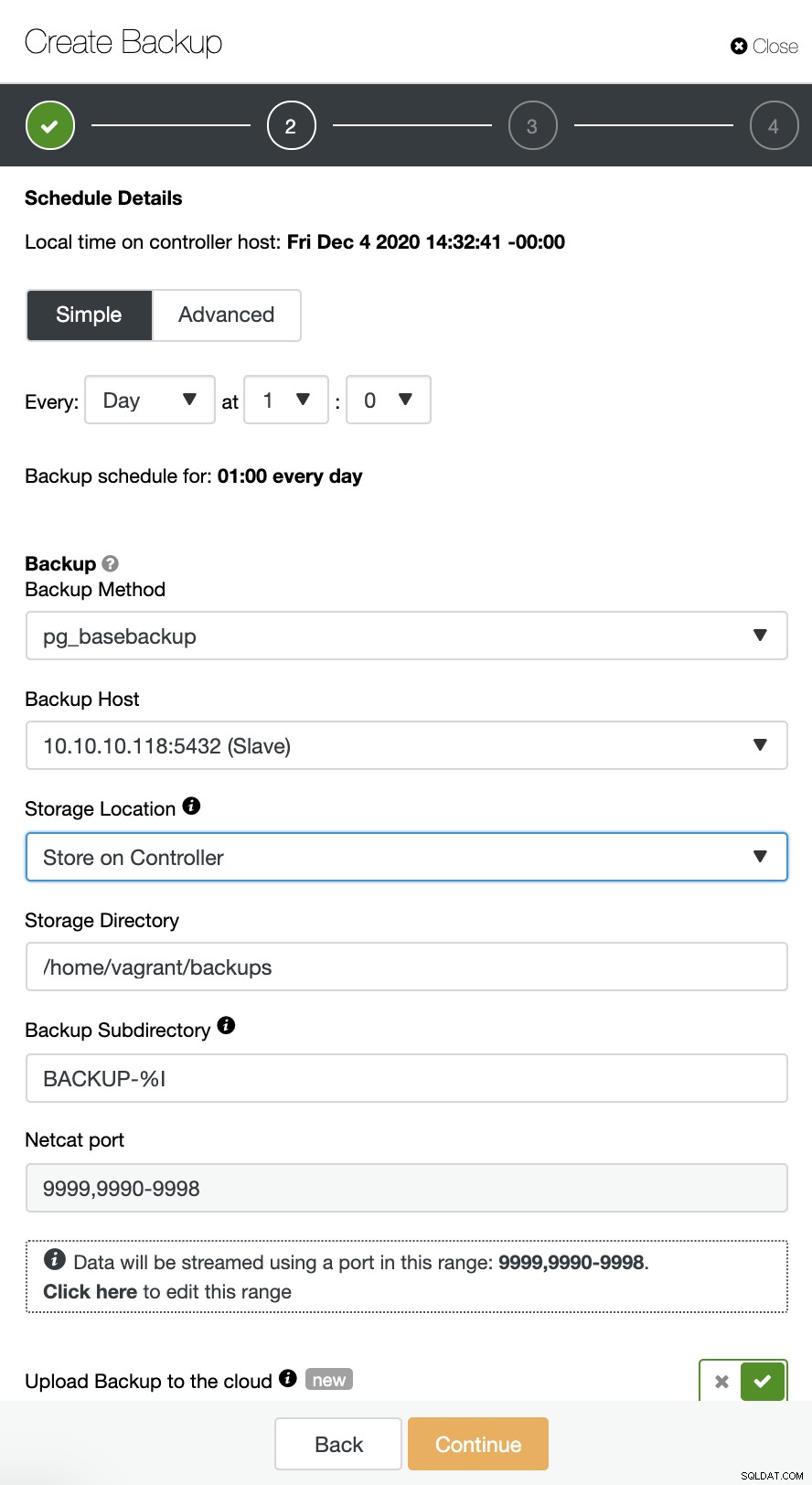
Włącz opcję „Prześlij kopię zapasową do chmury” i kontynuuj. Poprosi Cię o wybranie dostawcy chmury i wypełnienie kluczy dostępu i tajnych. W tym przypadku używam AWS S3 jako dostawcy kopii zapasowych w chmurze.
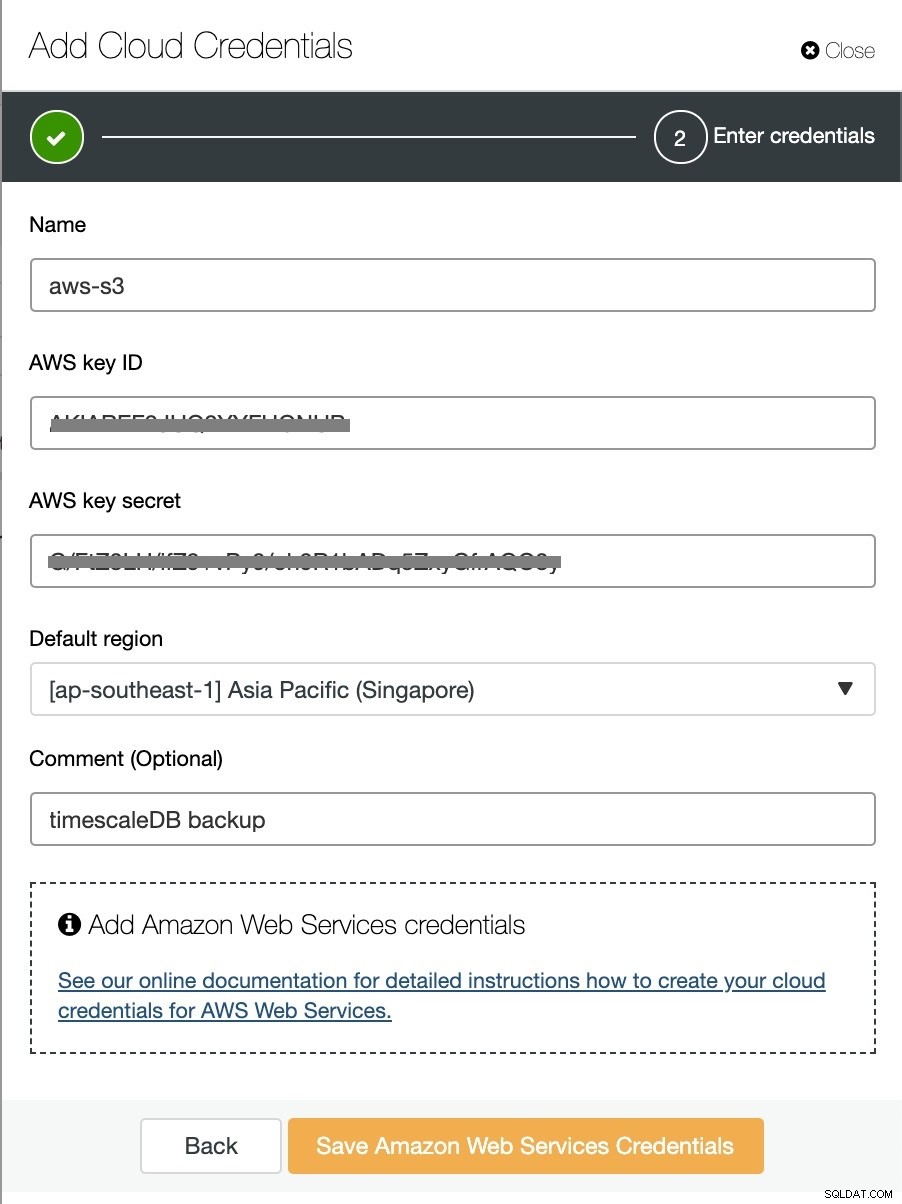
I na koniec wybierz utworzony wcześniej zasobnik. Możesz skonfigurować przechowywanie kopii zapasowej i Zaplanuj tworzenie kopii zapasowej, jak poniżej: