Obecnie Docker jest najpopularniejszym narzędziem do tworzenia, wdrażania i uruchamiania aplikacji przy użyciu kontenerów. Pozwala nam spakować aplikację ze wszystkimi potrzebnymi jej częściami, takimi jak biblioteki i inne zależności, i wysłać to wszystko jako jeden pakiet. Można go uznać za maszynę wirtualną, ale zamiast tworzyć cały wirtualny system operacyjny, Docker umożliwia aplikacjom korzystanie z tego samego jądra systemu Linux, na którym działają, i wymaga jedynie dostarczenia aplikacji z elementami, na których jeszcze nie działają. komputer hosta. Daje to znaczny wzrost wydajności i zmniejsza rozmiar aplikacji.
W przypadku obrazów Docker są dostarczane z predefiniowaną wersją systemu operacyjnego, a pakiety są instalowane w sposób określony przez osobę, która stworzyła obraz. Możliwe, że chcesz użyć innego systemu operacyjnego, a może chcesz zainstalować pakiety w inny sposób. W takich przypadkach należy użyć czystego obrazu Docker systemu operacyjnego i zainstalować oprogramowanie od zera.
Replikacja jest powszechną funkcją w środowisku bazy danych, więc po wdrożeniu obrazów platformy Docker TimescaleDB, jeśli chcesz skonfigurować konfigurację replikacji, musisz to zrobić ręcznie z kontenera, używając pliku Docker lub nawet skryptu. To zadanie może być skomplikowane, jeśli nie masz wiedzy na temat platformy Docker.
W tym blogu zobaczymy, jak możemy wdrożyć TimescaleDB za pośrednictwem platformy Docker, korzystając z obrazu dockera TimescaleDB, a następnie zobaczymy, jak zainstalować go od zera, korzystając z obrazu dockera CentOS i ClusterControl.
Jak wdrożyć bazę danych TimescaleDB za pomocą obrazu Docker
Najpierw zobaczmy, jak wdrożyć TimescaleDB przy użyciu obrazu Docker dostępnego w Docker Hub.
$ docker search timescaledb
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
timescale/timescaledb An open-source time-series database optimize… 52Weźmiemy pierwszy wynik. Musimy więc wyciągnąć ten obraz:
$ docker pull timescale/timescaledbI uruchom kontenery węzłów mapujące port lokalny na port bazy danych w kontenerze:
$ docker run -d --name timescaledb1 -p 7551:5432 timescale/timescaledb
$ docker run -d --name timescaledb2 -p 7552:5432 timescale/timescaledbPo uruchomieniu tych poleceń powinieneś mieć utworzone następujące środowisko Docker:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6d3bfc75fe39 timescale/timescaledb "docker-entrypoint.s…" 15 minutes ago Up 15 minutes 0.0.0.0:7552->5432/tcp timescaledb2
748d5167041f timescale/timescaledb "docker-entrypoint.s…" 16 minutes ago Up 16 minutes 0.0.0.0:7551->5432/tcp timescaledb1Teraz możesz uzyskać dostęp do każdego węzła za pomocą następujących poleceń:
$ docker exec -ti [db-container] bash
$ su postgres
$ psql
psql (9.6.13)
Type "help" for help.
postgres=#Jak widać, ten obraz Dockera zawiera domyślnie wersję TimescaleDB 9.6 i jest zainstalowany w Alpine Linux v3.9. Możesz użyć innej wersji TimescaleDB, zmieniając tag:
$ docker pull timescale/timescaledb:latest-pg11Następnie możesz utworzyć użytkownika bazy danych, zmienić konfigurację zgodnie z własnymi wymaganiami lub ręcznie skonfigurować replikację między węzłami.
Jak wdrożyć bazę danych TimescaleDB za pomocą ClusterControl
Zobaczmy teraz, jak wdrożyć TimescaleDB za pomocą platformy Docker, używając obrazu dockera CentOS (centos) i obrazu dockera ClusterControl (kilkadziesiąt/kontrola klastra).
Najpierw wdrożymy ClusterControl Docker Container przy użyciu najnowszej wersji, więc musimy pobrać kilka dziewiątek/Clustercontrol Docker Image.
$ docker pull severalnines/clustercontrolNastępnie uruchomimy kontener ClusterControl i opublikujemy port 5000, aby uzyskać do niego dostęp.
$ docker run -d --name clustercontrol -p 5000:80 severalnines/clustercontrolTeraz możemy otworzyć interfejs użytkownika ClusterControl pod adresem https://[Docker_Host]:5000/clustercontrol i utworzyć domyślnego użytkownika i hasło administratora.
Oficjalny obraz Docker CentOS jest dostarczany bez usługi SSH, więc zainstalujemy go i zezwolimy na połączenie z węzła ClusterControl bez hasła za pomocą klucza SSH.
$ docker search centos
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 5378 [OK]Dlatego pobierzemy oficjalny obraz platformy Docker CentOS.
$ docker pull centosNastępnie uruchomimy dwa kontenery węzłów, timescale1 i timescale2, połączone z ClusterControl i zmapujemy port lokalny, aby połączyć się z bazą danych (opcjonalnie).
$ docker run -dt --privileged --name timescale1 -p 8551:5432 --link clustercontrol:clustercontrol centos /usr/sbin/init
$ docker run -dt --privileged --name timescale2 -p 8552:5432 --link clustercontrol:clustercontrol centos /usr/sbin/initPonieważ musimy zainstalować i skonfigurować usługę SSH, musimy uruchomić kontener z parametrami uprzywilejowanymi i /usr/sbin/init, aby móc zarządzać usługą wewnątrz kontenera.
Po uruchomieniu tych poleceń powinniśmy mieć utworzone to środowisko Docker:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
230686d8126e centos "/usr/sbin/init" 4 seconds ago Up 3 seconds 0.0.0.0:8552->5432/tcp timescale2
c0e7b245f7fe centos "/usr/sbin/init" 23 seconds ago Up 22 seconds 0.0.0.0:8551->5432/tcp timescale1
7eadb6bb72fb severalnines/clustercontrol "/entrypoint.sh" 2 weeks ago Up About an hour (healthy) 22/tcp, 443/tcp, 3306/tcp, 9500-9501/tcp, 9510-9511/tcp, 9999/tcp, 0.0.0.0:5000->80/tcp clustercontrolMożemy uzyskać dostęp do każdego węzła za pomocą następującego polecenia:
$ docker exec -ti [db-container] bashJak wspomnieliśmy wcześniej, musimy zainstalować usługę SSH, więc zainstalujmy ją, zezwólmy na dostęp roota i ustawmy hasło roota dla każdego kontenera bazy danych:
$ docker exec -ti [db-container] yum update -y
$ docker exec -ti [db-container] yum install -y openssh-server openssh-clients
$ docker exec -it [db-container] sed -i 's|^#PermitRootLogin.*|PermitRootLogin yes|g' /etc/ssh/sshd_config
$ docker exec -it [db-container] systemctl start sshd
$ docker exec -it [db-container] passwdOstatnim krokiem jest skonfigurowanie bezhasłowego SSH do wszystkich kontenerów bazy danych. W tym celu musimy znać adres IP każdego węzła bazy danych. Aby to wiedzieć, możemy uruchomić następujące polecenie dla każdego węzła:
$ docker inspect [db-container] |grep IPAddress
"IPAddress": "172.17.0.5",Następnie podłącz do interaktywnej konsoli kontenera ClusterControl:
$ docker exec -it clustercontrol bashI skopiuj klucz SSH do wszystkich kontenerów bazy danych:
$ ssh-copy-id 172.17.0.5Teraz, gdy mamy już działające węzły serwerów, musimy wdrożyć nasz klaster baz danych. Aby to ułatwić, użyjemy ClusterControl.
Aby przeprowadzić wdrożenie z ClusterControl, otwórz interfejs użytkownika ClusterControl pod adresem https://[Docker_Host]:5000/clustercontrol, a następnie wybierz opcję „Wdróż” i postępuj zgodnie z wyświetlanymi instrukcjami.
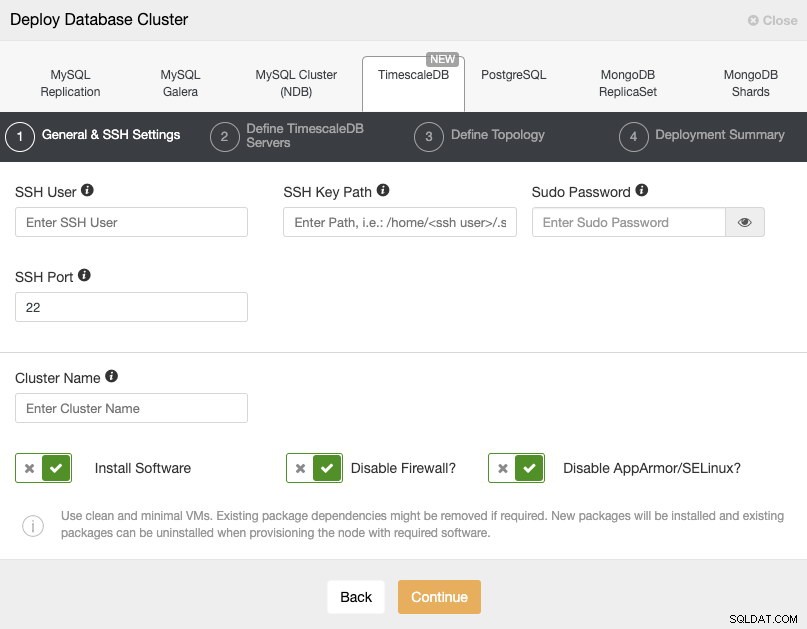
Wybierając TimescaleDB, musimy określić użytkownika, klucz lub hasło i port, aby połączyć się przez SSH z naszymi serwerami. Potrzebujemy również nazwy dla naszego nowego klastra i jeśli chcemy, aby ClusterControl zainstalował dla nas odpowiednie oprogramowanie i konfiguracje.
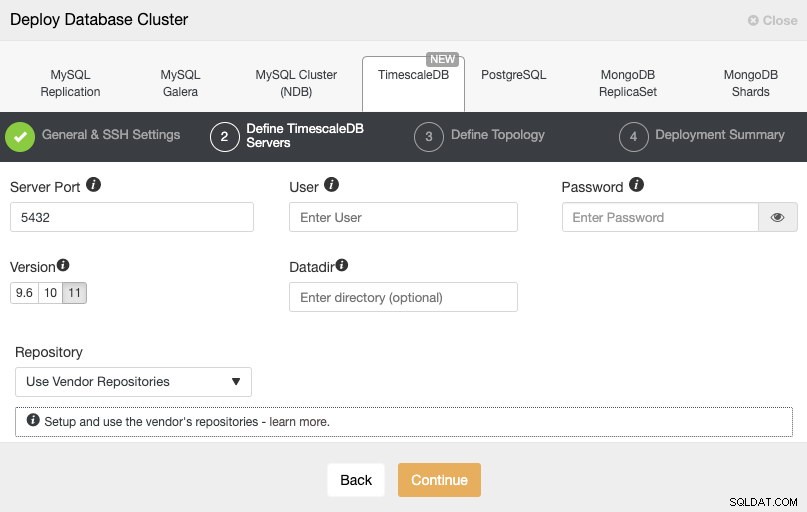
Po skonfigurowaniu informacji dostępowych SSH musimy zdefiniować użytkownika bazy danych, wersję i datadir (opcjonalnie). Możemy również określić, którego repozytorium użyć.
W następnym kroku musimy dodać nasze serwery do klastra, który zamierzamy utworzyć.
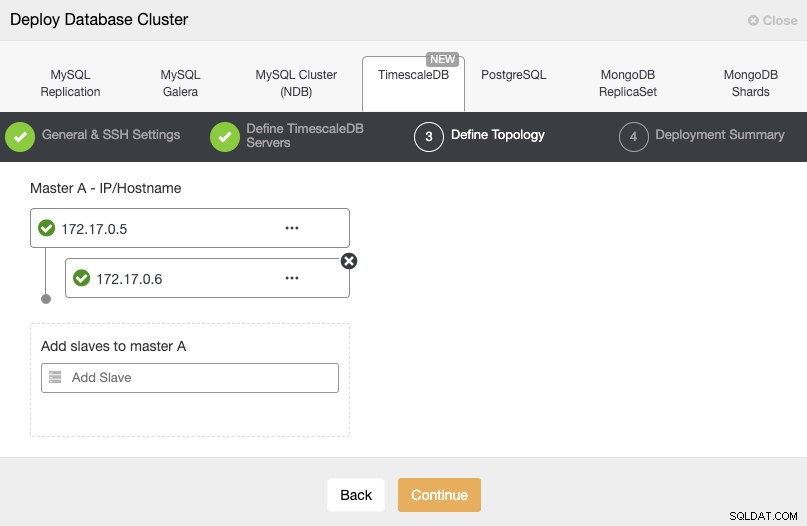
Tutaj musimy użyć adresu IP, który otrzymaliśmy wcześniej z każdego kontenera.
W ostatnim kroku możemy wybrać, czy nasza replikacja będzie synchroniczna czy asynchroniczna.
Możemy monitorować stan tworzenia naszego nowego klastra z monitora aktywności ClusterControl.
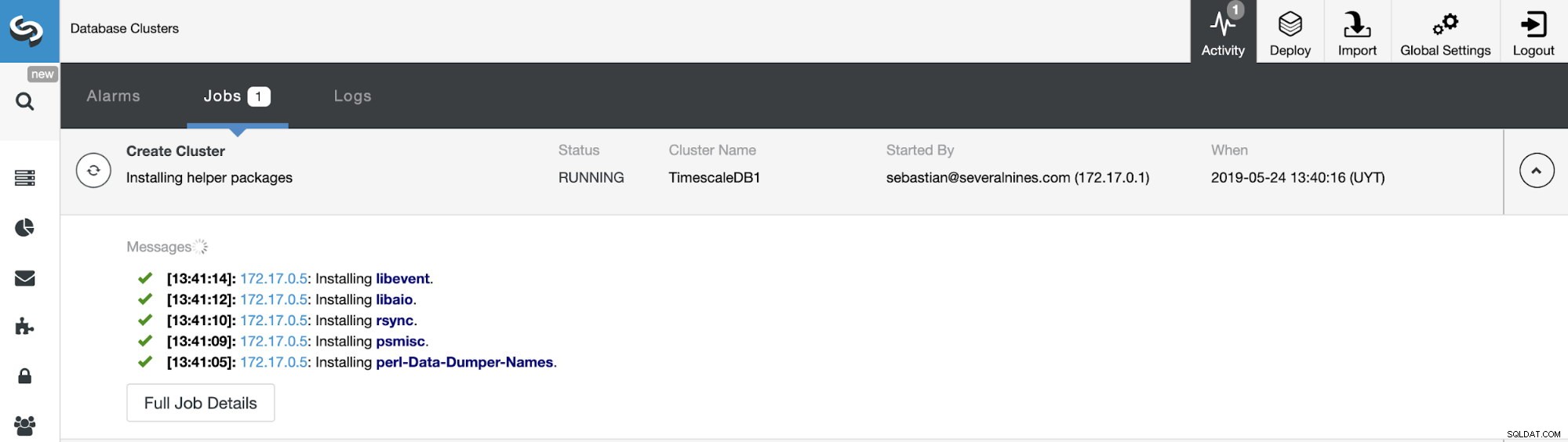
Po zakończeniu zadania możemy zobaczyć nasz klaster na głównym ekranie ClusterControl.

Pamiętaj, że jeśli chcesz dodać więcej węzłów rezerwowych, możesz to zrobić z interfejsu użytkownika ClusterControl w menu Akcje klastra.
W ten sam sposób, jeśli masz klaster TimescaleDB działający na platformie Docker i chcesz, aby ClusterControl zarządzał nim, aby móc korzystać ze wszystkich funkcji tego systemu, takich jak monitorowanie, tworzenie kopii zapasowych, automatyczne przełączanie awaryjne, a nawet więcej, możesz po prostu uruchomić Kontener ClusterControl w tej samej sieci Docker co kontenery bazy danych. Jedynym wymaganiem jest upewnienie się, że kontenery docelowe mają zainstalowane pakiety związane z SSH (openssh-server, openssh-clients). Następnie zezwól na bezhasłowe SSH z ClusterControl do kontenerów bazy danych. Po zakończeniu użyj funkcji „Importuj istniejący serwer/klaster”, a klaster należy zaimportować do ClusterControl.
Jednym z możliwych problemów z uruchamianiem kontenerów jest przypisanie adresu IP lub nazwy hosta. Bez narzędzia do aranżacji, takiego jak Kubernetes, adres IP lub nazwa hosta mogą być inne, jeśli zatrzymasz węzły i utworzysz nowe kontenery przed ponownym uruchomieniem. Będziesz mieć inny adres IP dla starych węzłów, a ClusterControl zakłada, że wszystkie węzły działają w środowisku z dedykowanym adresem IP lub nazwą hosta, więc po zmianie adresu IP powinieneś ponownie zaimportować klaster do ClusterControl. Istnieje wiele obejść tego problemu, możesz sprawdzić ten link, aby używać Kubernetes z StatefulSet, lub ten do uruchamiania kontenerów bez narzędzia do orkiestracji.
Wniosek
Jak widzieliśmy, wdrożenie TimescaleDB za pomocą Dockera powinno być łatwe, jeśli nie chcesz konfigurować środowiska replikacji lub przełączania awaryjnego i jeśli nie chcesz wprowadzać żadnych zmian w wersji systemu operacyjnego lub instalacji pakietów bazy danych.
Dzięki ClusterControl możesz importować lub wdrażać klaster TimescaleDB za pomocą platformy Docker, używając preferowanego obrazu systemu operacyjnego, a także zautomatyzować zadania monitorowania i zarządzania, takie jak tworzenie kopii zapasowych i automatyczne przełączanie awaryjne/odzyskiwanie.



