Platforma zarządzania danymi IRI Voracity (oraz produkt IRI FieldShield do maskowania danych) umożliwia teraz automatyczne definiowanie klas i grup danych na podstawie glosariuszy biznesowych lub ontologii domen oraz stosowanie reguł transformacji do tych klas w wielu źródłach danych i polach. W tym artykule pokażę, jak zastosować reguły ochrony na poziomie pola względem biblioteki klas danych.
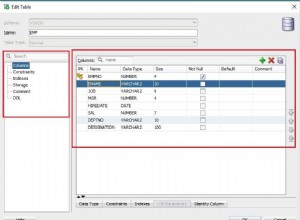
Wykorzystamy bibliotekę klas danych utworzoną w moim pierwszym artykule na temat klasyfikacji danych w środowisku pracy IRI dla żarłoczności i FieldShield. Oto biblioteka klas danych, która będzie używana:

Widać, że użyłem jednego pliku CSV i dwóch tabel Oracle. W tym przykładzie reguł będę przekształcał dane tylko w dwóch tabelach.
Używając Kreatora zadań ochrony wielu tabel FieldShield, wybieram ODBC jako ekstraktor, nic dla modułu ładującego (więc wynik będzie plikiem płaskim) i dwie tabele, o których mowa powyżej. Na stronie Reguły modyfikacji pól klikam Utwórz, aby dodać nową regułę funkcji maskowania dla mojego pola SSN:

Następnie dodaję dopasowywanie reguł, używając klasy danych PIN_US, którą mam w mojej bibliotece:

Mogę dodać tyle dopasowań, ile chcę, używając logiki AND/OR. Należy pamiętać, że AND ma pierwszeństwo. Operator ostatniego dopasowywania reguł nie jest używany w logice.

Tworzę kolejną regułę maskowania, używając predefiniowanego Całościowego Pola i grupy danych NAMES jako dopasowania. Kliknięcie przycisku Test pokazuje, że znaleziono trzy dopasowania pól. Ponieważ grupa klas danych NAMES zawiera klasy danych FIRSTNAME, LAST_NAME i FULL_NAME, są to poprawne dane wyjściowe oparte na powyższej bibliotece klas danych. Istnieją trzy mapy z typem NAME w swojej klasie danych. Klasy i grupy są rozróżniane za pomocą ikon w oknie dialogowym szczegółów dopasowania i na stronach preferencji.

Kliknięcie przycisku Dalej powoduje wyświetlenie ekranu podsumowania zawierającego pola, do których zostanie zastosowana reguła.

Kliknięcie przycisku Zakończ tworzy folder z dołączonymi wynikami zadania.
Oto dwa skrypty zadań (po jednym dla każdej tabeli) pokazujące reguły zastosowane w sekcjach wyjściowych. Cztery pola zostały zamaskowane na dwa różne sposoby:nazwy są całkowicie zamaskowane, a numery SSN mają zamaskowane tylko pięć pierwszych cyfr, z pominięciem myślników.

Gdy te zadania są uruchamiane samodzielnie lub jako część zadania, dają następujące wyniki:

Możliwość używania klas danych jako elementów dopasowujących reguły pozwala wybrać większą liczbę pól przy mniejszej liczbie kroków. W tym przykładzie zamaskowałem cztery pola w dwóch tabelach za pomocą tylko dwóch reguł.
Aby uzyskać więcej informacji lub przekazać opinię na temat stosowania klasyfikacji danych i/lub stosowania zasad, prosimy o kontakt pod adresem voracity@iri.com.