Jest to druga część pięcioczęściowej serii, która szczegółowo omawia sposób uruchamiania planów równoległych w trybie wiersza SQL Server. Pod koniec pierwszej części stworzyliśmy kontekst wykonania zero dla zadania nadrzędnego. Ten kontekst zawiera całe drzewo operatorów wykonywalnych, ale nie są one jeszcze gotowe na iteracyjny model wykonywania silnika przetwarzania zapytań.
Wykonywanie iteracyjne
SQL Server wykonuje zapytanie poprzez proces zwany skanowaniem zapytań . Inicjalizacja planu rozpoczyna się od korzenia przez procesor zapytań wywołujący Open w węźle głównym. Open wywołania przechodzą przez drzewo iteratorów rekurencyjnie wywołując Open na każdym dziecku, aż całe drzewo zostanie otwarte.
Proces zwracania wierszy wyników jest również rekurencyjny, wywoływany przez procesor zapytań wywołujący GetRow u podstaw. Każde wywołanie roota zwraca wiersz na raz. Procesor zapytań kontynuuje wywoływanie GetRow w węźle głównym, aż nie będzie więcej dostępnych wierszy. Wykonywanie kończy się z końcowym rekurencyjnym Close połączenie. Taki układ umożliwia procesorowi zapytań inicjowanie, wykonywanie i zamykanie dowolnego planu przez wywołanie tych samych metod interfejsu w katalogu głównym.
Aby przekształcić drzewo operatorów wykonywalnych w odpowiednie do przetwarzania wiersz po wierszu, SQL Server dodaje skanowanie zapytań opakowanie dla każdego operatora. skanowanie zapytań obiekt zapewnia Open , GetRow i Close metody potrzebne do iteracyjnego wykonania.
Obiekt skanowania zapytania przechowuje również informacje o stanie i udostępnia inne metody specyficzne dla operatora, potrzebne podczas wykonywania. Na przykład obiekt skanowania zapytania dla operatora filtra uruchamiania (CQScanStartupFilterNew ) udostępnia następujące metody:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Dodatkowe metody tego iteratora są najczęściej używane w planach kursora.
Inicjowanie skanowania zapytań
Proces zawijania nazywa się inicjowaniem skanowania zapytania . Jest to wykonywane przez wywołanie z procesora zapytań do CQueryScan::InitQScanRoot . Zadanie nadrzędne wykonuje ten proces dla całego planu (zawarte w kontekście wykonania zero). Proces tłumaczenia sam w sobie ma charakter rekurencyjny, zaczynając od korzenia i przechodząc w dół drzewa.
Podczas tego procesu każdy operator jest odpowiedzialny za inicjowanie własnych danych i tworzenie dowolnych zasobów wykonawczych to potrzebuje. Może to obejmować tworzenie dodatkowych obiektów poza procesorem zapytań, na przykład struktur potrzebnych do komunikacji z silnikiem pamięci masowej w celu pobierania danych z pamięci trwałej.
Przypomnienie o planie wykonania z dodanymi numerami węzłów (kliknij, aby powiększyć):
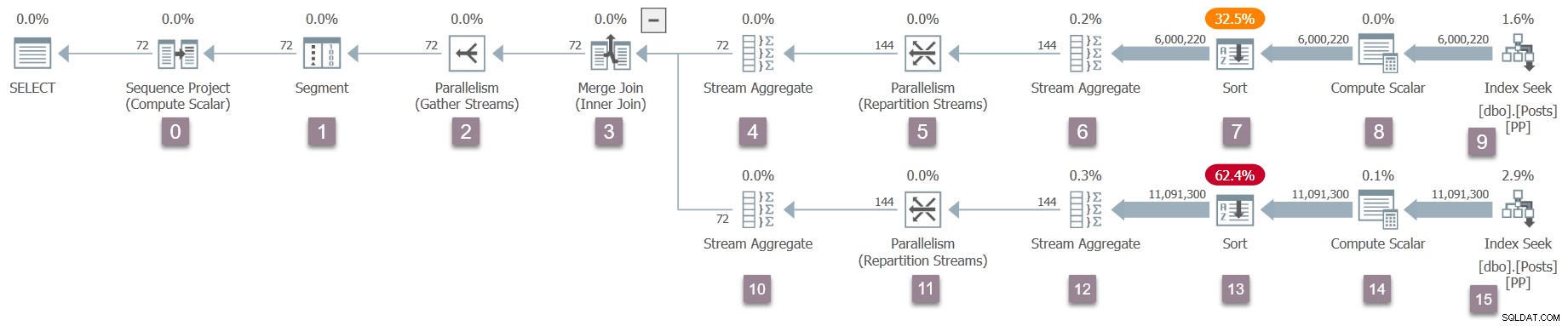
Operator w głównym (węzeł 0) wykonywalnego drzewa planu to projekt sekwencji . Jest reprezentowany przez klasę o nazwie CXteSeqProject . Jak zwykle, tutaj zaczyna się transformacja rekurencyjna.
Opakowania skanowania zapytań
Jak wspomniano, CXteSeqProject obiekt nie jest przystosowany do wzięcia udziału w iteracyjnym skanowaniu zapytań proces — nie ma wymaganego Open , GetRow i Close metody. Procesor zapytań potrzebuje otoki wokół operatora wykonywalnego, aby zapewnić ten interfejs.
Aby uzyskać opakowanie skanowania zapytania, zadanie nadrzędne wywołuje CXteSeqProject::QScanGet aby zwrócić obiekt typu CQScanSeqProjectNew . połączona mapa operatorów utworzonych wcześniej jest aktualizowanych, aby odwoływać się do nowego obiektu skanowania zapytania, a jego metody iteratorów są połączone z katalogiem głównym planu.
Potomkiem projektu sekwencji jest segment operator (węzeł 1). Wywołanie CXteSegment::QScanGet zwraca obiekt opakowania skanu zapytania typu CQScanSegmentNew . Połączona mapa jest ponownie aktualizowana, a wskaźniki funkcji iteratora są połączone ze skanowaniem zapytania projektu sekwencji nadrzędnej.
Połowa wymiany
Następnym operatorem jest wymiana strumieni zbierania (węzeł 2). Wywołanie CXteExchange::QScanGet zwraca CQScanExchangeNew jak możesz się teraz spodziewać.
Jest to pierwszy operator w drzewie, który musi wykonać znaczną dodatkową inicjalizację. Tworzy stronę konsumencką wymiany za pośrednictwem CXTransport::CreateConsumerPart . To tworzy port (CXPort ) — struktura danych w pamięci współdzielonej używana do synchronizacji i wymiany danych — oraz potok (CXPipe ) do transportu pakietów. Zwróć uwagę, że producent strona giełdy nie jest tworzona w tym czasie. Mamy tylko połowę wymiany!
Więcej owijania
Proces konfigurowania skanowania procesora zapytań jest następnie kontynuowany z łączeniem scalającym (węzeł 3). Nie zawsze powtórzę QScanGet i CQScan* od tego momentu, ale postępują zgodnie z ustalonym wzorcem.
Łączenie scalające ma dwoje dzieci. Konfiguracja skanowania zapytań jest kontynuowana jak poprzednio z zewnętrznymi (górnymi) danymi wejściowymi — agregatem strumienia (węzeł 4), a następnie partycjonowanie strumieni wymiana (węzeł 5). Strumienie podziału ponownie tworzą tylko stronę konsumencką wymiany, ale tym razem tworzone są dwa potoki, ponieważ DOP wynosi dwa. Strona konsumencka tego typu wymiany ma połączenia DOP z operatorem nadrzędnym (po jednym na wątek).
Następnie mamy kolejny agregat strumieniowy (węzeł 6) i sortowanie (węzeł 7). Sort ma element podrzędny niewidoczny w planach wykonania — zestaw wierszy aparatu pamięci masowej używany do implementowania rozlewania do tempdb . Oczekiwany CQScanSortNew dlatego towarzyszy mu dziecko CQScanRowsetNew w wewnętrznym drzewie. Nie jest widoczny w wynikach showplanu.
Profilowanie I/O i odroczone operacje
sortowanie Operator jest również pierwszym, którego do tej pory zainicjalizowaliśmy, i który może być odpowiedzialny za I/O . Zakładając, że wykonanie zażądało danych profilowania we/wy (np. żądając „rzeczywistego” planu), sortowanie tworzy obiekt do rejestrowania tych danych profilowania w czasie wykonywania przez CProfileInfo::AllocProfileIO .
Następnym operatorem jest skalar obliczeniowy (węzeł 8), zwany projektem wewnętrznie. Wywołanie konfiguracji skanowania zapytania do CXteProject::QScanGet czy nie zwraca obiekt skanowania zapytania, ponieważ obliczenia wykonywane przez ten skalar obliczeniowy są odroczone do pierwszego operatora nadrzędnego, który potrzebuje wyniku. W tym planie ten operator jest tego rodzaju. Sortowanie wykona całą pracę przypisaną do obliczeń skalarnych, więc projekt w węźle 8 nie stanowi części drzewa skanowania zapytań. Skalar obliczeniowy tak naprawdę nie jest wykonywany w czasie wykonywania. Aby uzyskać więcej informacji na temat odroczonych skalarów obliczeniowych, zobacz Skalary obliczeniowe, wyrażenia i wydajność planu wykonania.
Skanowanie równoległe
Ostatnim operatorem po obliczeniu skalarnym w tej gałęzi planu jest szukanie indeksu (CXteRange ) w węźle 9. Daje to oczekiwany operator skanowania zapytania (CQScanRangeNew ), ale wymaga również złożonej sekwencji inicjalizacji, aby połączyć się z silnikiem pamięci masowej i ułatwić równoległe skanowanie indeksu.
Zajmuję tylko najważniejsze informacje, inicjując wyszukiwanie indeksu:
- Tworzy obiekt profilowania dla we/wy (
CProfileInfo::AllocProfileIO). - Tworzy równoległy zestaw wierszy skanowanie zapytania (
CQScanRowsetNew::ParallelGetRowset). - Konfiguruje synchronizację obiekt do koordynowania skanowania zakresu równoległego środowiska wykonawczego (
CQScanRangeNew::GetSyncInfo). - Tworzy silnik pamięci kursor tabeli i deskryptor transakcji tylko do odczytu .
- Otwiera nadrzędny zestaw wierszy do odczytu (uzyskiwanie dostępu do HoBt i przyjmowanie potrzebnych zatrzasków).
- Ustawia limit czasu blokady.
- Konfiguruje pobieranie wstępne (w tym powiązane bufory pamięci).
Dodawanie operatorów profilowania w trybie wiersza
Osiągnęliśmy teraz poziom liścia tej gałęzi planu (wyszukiwanie indeksu nie ma dziecka). Po utworzeniu obiektu skanowania zapytania dla wyszukiwania indeksu następnym krokiem jest zawinięcie skanowania zapytania z klasą profilowania (zakładając, że poprosiliśmy o rzeczywisty plan). Odbywa się to przez wywołanie sqlmin!PqsWrapQScan . Zwróć uwagę, że profilery są dodawane po utworzeniu skanowania zapytania, gdy zaczynamy w górę drzewa iteratorów.
PqsWrapQScan tworzy nowego operatora profilowania jako rodzica wyszukiwania indeksu poprzez wywołanie CProfileInfo::GetOrCreateProfileInfo . operator profilowania (CQScanProfileNew ) ma zwykłe metody interfejsu skanowania zapytań. Oprócz zbierania danych potrzebnych do rzeczywistych planów, dane profilowania są również udostępniane przez DMV sys.dm_exec_query_profiles .
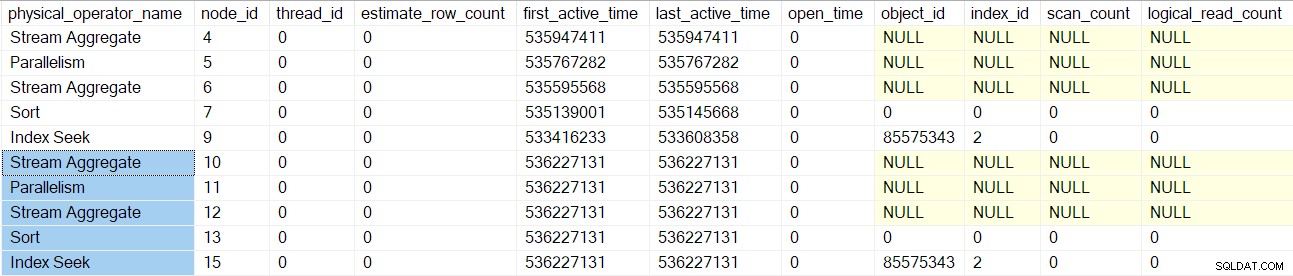
Zapytanie o DMV w tym konkretnym momencie dla bieżącej sesji pokazuje, że istnieje tylko jeden operator planu (węzeł 9) (co oznacza, że jest to jedyny objęty profilem):

Ten zrzut ekranu pokazuje pełny zestaw wyników z DMV w chwili obecnej (nie był edytowany).
Następnie, CQScanProfileNew wywołuje interfejs API licznika wydajności zapytań (KERNEL32!QueryPerformanceCounterStub ) dostarczone przez system operacyjny do rejestrowania pierwszego i ostatniego czasu aktywności profilowanego operatora:

czas ostatniej aktywności zostanie zaktualizowany za pomocą interfejsu API licznika wydajności zapytań za każdym razem, gdy kod dla tego iteratora zostanie uruchomiony.
Profiler następnie ustawia szacowaną liczbę wierszy w tym momencie planu (CProfileInfo::SetCardExpectedRows ), uwzględniając dowolny cel wiersza (CXte::CardGetRowGoal ). Ponieważ jest to plan równoległy, wynik dzieli przez liczbę wątków (CXte::FGetRowGoalDefinedForOneThread ) i zapisuje wynik w kontekście wykonania.
Szacowana liczba wierszy jest niewidoczna za pośrednictwem DMV w tym momencie, ponieważ zadanie nadrzędne nie wykona tego operatora. Zamiast tego oszacowanie na wątek zostanie ujawnione później w kontekstach wykonania równoległego (które nie zostały jeszcze utworzone). Niemniej jednak numer wątku jest zapisywany w profilerze zadania nadrzędnego — po prostu nie jest widoczny przez DMV.
Przyjazna nazwa operatora planu („Index Seek”) jest następnie ustawiany przez wywołanie CXteRange::GetPhysicalOp :

Wcześniej mogłeś zauważyć, że zapytanie DMV pokazało nazwę jako „???”. Jest to stała nazwa wyświetlana dla niewidocznych operatorów (np. zagnieżdżonych pętli wstępnego pobierania, sortowania wsadowego), które nie mają zdefiniowanej przyjaznej nazwy.
Na koniec indeksuj metadane i bieżące statystyki we/wy dla opakowanego indeksu wyszukiwanie są dodawane przez wywołanie CQScanRowsetNew::GetIoCounters :

Liczniki wynoszą obecnie zero, ale zostaną zaktualizowane, gdy wyszukiwanie indeksu wykona operacje wejścia/wyjścia podczas wykonywania zakończonego planu.
Więcej przetwarzania skanowania zapytań
Z operatorem profilowania utworzonym dla wyszukiwania indeksu, przetwarzanie skanowania zapytań przenosi z powrotem w górę drzewa do nadrzędnego sortowania (węzeł 7).
Sortowanie wykonuje następujące zadania inicjalizacji:
- Rejestruje wykorzystanie pamięci za pomocą zapytania menedżer pamięci (
CQryMemManager::RegisterMemUsage) - Oblicza pamięć wymaganą dla danych wejściowych sortowania (
CQScanIndexSortNew::CbufInputMemory) i wyjście (CQScanSortNew::CbufOutputMemory). - Tabela sortowania jest tworzony wraz z powiązanym zestawem wierszy aparatu magazynu (
sqlmin!RowsetSorted). - Samodzielna transakcja systemowa (nieograniczony transakcją użytkownika) jest tworzony w celu sortowania alokacji dysków rozlanych wraz z fałszywą tabelą roboczą (
sqlmin!CreateFakeWorkTable). - Usługa wyrażeń jest inicjowana (
sqlTsEs!CEsRuntime::Startup) aby operator sortowania wykonał obliczenia odroczone z obliczeń skalarnych. - Pobierz z wyprzedzeniem dla dowolnych przebiegów przeniesionych do tempdb jest następnie tworzony przez (
CPrefetchMgr::SetupPrefetch).
Wreszcie skanowanie zapytania sortującego jest otoczone operatorem profilowania (w tym I/O), tak jak widzieliśmy w przypadku wyszukiwania indeksu:

Zauważ, że brakuje skalara obliczeniowego (węzeł 8) z DMV. Dzieje się tak dlatego, że jego praca jest odroczona do sortowania, nie jest częścią drzewa skanowania zapytań, a zatem nie ma obiektu wrappera.
Przechodząc do rodzica tego rodzaju, agregat strumieniowy Operator skanowania zapytań (węzeł 6) inicjuje swoje wyrażenia i liczniki czasu wykonywania (np. bieżąca liczba wierszy grupy). Agregat strumieniowy jest owinięty operatorem profilowania, który rejestruje czasy początkowe:

Nadrzędne strumienie podziału wymieniają się (węzeł 5) jest opakowany przez profilera (pamiętaj, że w tym momencie istnieje tylko strona konsumencka tej wymiany):

To samo dotyczy nadrzędnego agregatu strumienia (węzeł 4), który jest również inicjowany, jak opisano wcześniej:

Przetwarzanie skanowania zapytania powraca do nadrzędnego połączenia scalającego (węzeł 3), ale jeszcze go nie inicjuje. Zamiast tego przesuwamy się w dół wewnętrznej (dolnej) strony łączenia przez scalenie, wykonując te same szczegółowe zadania dla tych operatorów (węzły od 10 do 15), co w przypadku górnej (zewnętrznej) gałęzi:
Po przetworzeniu tych operatorów połączenie scalające skanowanie zapytania jest tworzone, inicjowane i owijane obiektem profilowania. Obejmuje to liczniki we/wy, ponieważ łączenie scalające wiele-wiele wykorzystuje tabelę roboczą (nawet jeśli bieżące łączenie scalające to jeden-wiele):
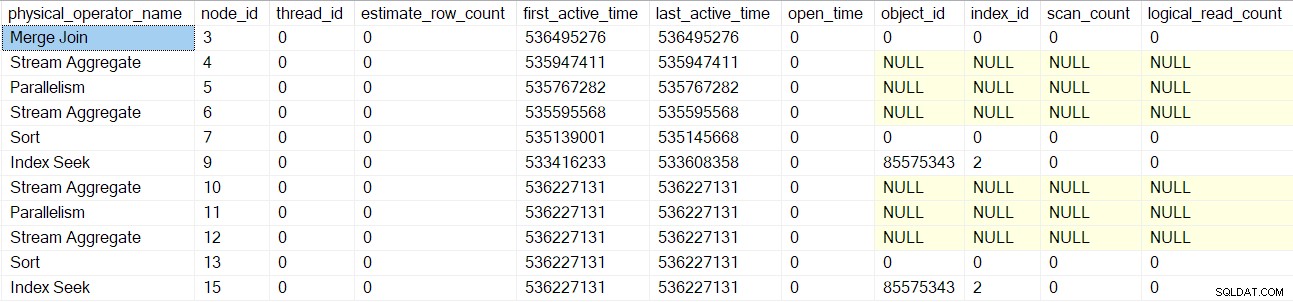
Ten sam proces jest stosowany w przypadku nadrzędnych strumieni zbierania wymiany (węzeł 2) tylko po stronie konsumenta, segment (węzeł 1) i projekt sekwencji (węzeł 0) operatorów. Nie będę ich szczegółowo opisywać.
Profile zapytań DMV zgłasza teraz pełny zestaw węzłów skanowania zapytań owiniętych profilem:
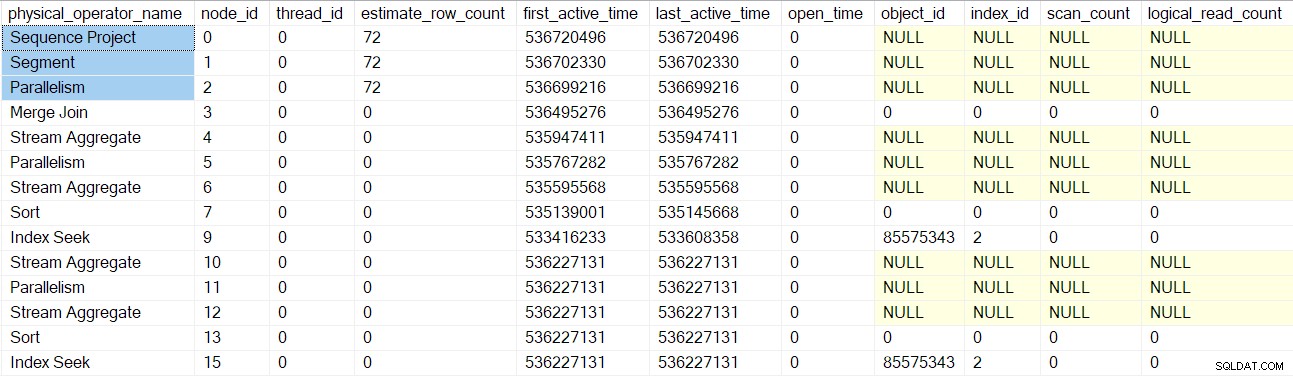
Zwróć uwagę, że konsument strumieni projektu, segmentu i zbierania ma szacowaną liczbę wierszy, ponieważ operatory te będą uruchamiane przez zadanie nadrzędne , a nie przez dodatkowe zadania równoległe (zobacz CXte::FGetRowGoalDefinedForOneThread wcześniej). Zadanie nadrzędne nie ma pracy w równoległych gałęziach, więc koncepcja szacowanej liczby wierszy ma sens tylko w przypadku dodatkowych zadań.
Pokazane powyżej wartości czasu aktywności są nieco zniekształcone, ponieważ musiałem zatrzymać wykonanie i wykonać zrzuty ekranu DMV na każdym kroku. Oddzielne wykonanie (bez sztucznych opóźnień wprowadzanych przez debugger) dało następujące czasy:
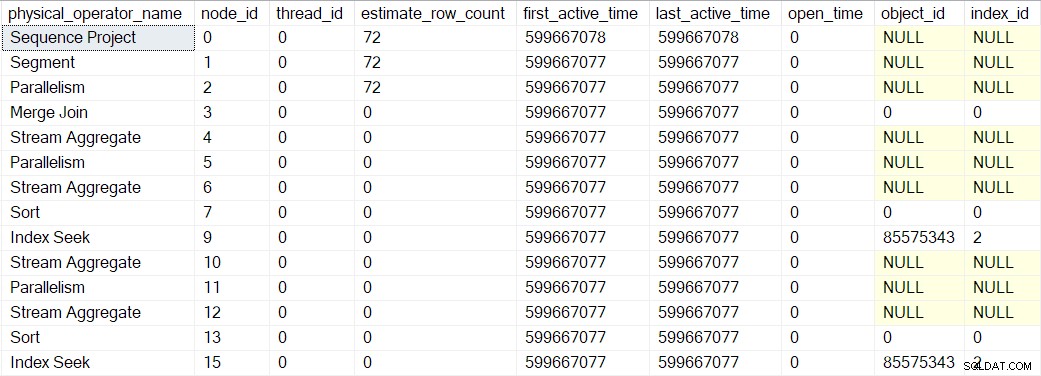
Drzewo jest konstruowane w tej samej kolejności, co opisana wcześniej, ale proces jest tak szybki, że zajmuje tylko 1 mikrosekundę różnica między czasem aktywności pierwszego opakowanego operatora (wyszukiwanie indeksu w węźle 9) a ostatnim (projekt sekwencji w węźle 0).
Koniec części 2
Może się wydawać, że wykonaliśmy dużo pracy, ale pamiętaj, że utworzyliśmy drzewo skanowania zapytań tylko dla zadania nadrzędnego , a giełdy mają tylko stronę konsumencką (jeszcze nie ma producenta). Nasz plan równoległy ma również tylko jeden wątek (jak pokazano na ostatnim zrzucie ekranu). W części 3 zobaczymy tworzenie naszych pierwszych dodatkowych zadań równoległych.