Potrzebujesz modelowania danych, aby zaoszczędzić sobie lub swojej organizacji mnóstwo pieniędzy, godzin i problemów. Czytaj dalej, aby dowiedzieć się, jak modele danych robią swoją magię.
Modelowanie danych to proces tworzenia koncepcyjnego widoku informacji, które zawiera lub powinna zawierać baza danych. W wyniku tego procesu tworzony jest model danych, nadając formę obiektom danych (wszystkie te podmioty, dla których mają być przechowywane informacje), powiązania lub relacje między nimi oraz reguły lub ograniczenia rządzące informacjami wprowadzanymi do bazy danych .
Bardzo fajnie, ale czy naprawdę trzeba pracować z modelami danych? Czy nie możemy po prostu pominąć tego kroku, zaoszczędzić trochę czasu i przejść od razu do tworzenia obiektów w bazie danych? Kurs modelowania baz danych odpowie na te pytania, ale jeśli chcesz podsumować, dam ci wystarczająco dużo powodów, aby mieć pod ręką model danych, gdy będziesz potrzebować pracować z informacjami przechowywanymi w bazie danych. Zanim skończysz czytać ten artykuł, zgodzisz się ze mną, że praca z bazą danych bez odpowiedniego modelu jest równoznaczna z budowaniem domu – a nawet wieżowca – bez odpowiedniego fundamentu.
Zacznijmy od rozważenia dwóch kontekstów, w których odbywa się głównie modelowanie danych:
- Modelowanie strategiczne, które jest przeprowadzane w ramach ogólnej strategii systemów informatycznych w organizacji.
- Projektowanie bazy danych, które jest częścią fazy projektowania w procesie tworzenia oprogramowania.
W obu sytuacjach istnieje wiele powodów do modelowania danych. Najpierw zobaczymy te, które dotyczą strategii systemów informatycznych, a następnie te związane z tworzeniem oprogramowania.
Wyższa jakość informacji
Model danych jest niezbędny do zapewnienia przejrzystości i spójności metadanych , definicje obiektów tworzących bazę danych. Przyczynia się to do podniesienia jakości informacji. Na przykład model danych może zapewnić, że elementy danych, takie jak numery telefonów i kody pocztowe, są używane we właściwych formatach, a w bazie danych, w której przechowywane są dane klienta, może zapewnić, że każdy klient ma co najmniej jeden adres.
Możesz również zapewnić jakość informacji przechowywanych w bazie danych, nakładając reguły, dzięki którym do tabel będą wprowadzane tylko prawidłowe dane. Aby to zrobić podczas projektowania modelu danych, ustaw domenę wartości dla każdego pola i rozróżnij pola, które muszą mieć wartości od tych, które mogą pozostać puste.
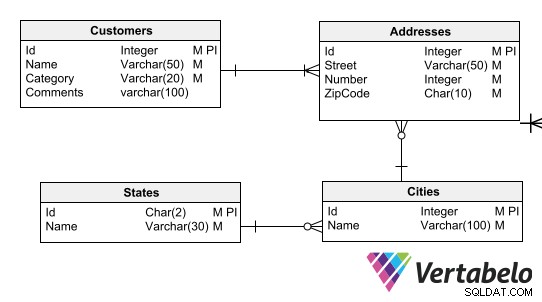
Definicje modelu danych zapewniają zgodność danych z zasady biznesowe. Na przykład możesz chcieć wymusić, aby każdy klient miał adres z prawidłowym formatem kodu pocztowego lub każdy adres był powiązany z miastem, a każde miasto ze stanem.
Jakość informacji poprawia się także poprzez nakładanie ograniczeń, które zapewniają integralność referencyjną i utrzymują zamierzoną kardynalność w relacjach między podmiotami. Te ograniczenia można wyprowadzić tylko z odpowiedniego modelu danych.
Ponowne wykorzystanie zasobów danych
Podczas opracowywania nowego systemu lub dodawania nowych funkcji do istniejącego systemu często zdarza się, że niektóre jednostki danych wymagane przez nowy program już istnieją w bazie danych i dlatego można je ponownie wykorzystać. Jedynym sposobem, aby dowiedzieć się, które podmioty już istnieją, jest przeglądanie aktualnych modeli danych, które odpowiednio opisują struktury baz danych używanych przez organizację.
Koncepcyjne, logiczne i fizyczne modele danych powinny być utrzymywane, aby zapewnić widoki z różnymi poziomami abstrakcji, aby umożliwić łatwe wykrywanie zasobów danych wielokrotnego użytku. Możesz skorzystać ze specjalistycznego narzędzia do projektowania, takiego jak platforma Vertabelo, aby ułatwić tworzenie różnych typów modeli danych, a nawet wyprowadzać je z siebie.
Ta dobra praktyka pozwala uniknąć generowania zbędnych danych w różnych schematach, co wcześniej czy później prowadzi do niespójnych informacji (więcej na ten temat poniżej).
Migracja do środowisk chmurowych
W przypadku infrastruktury DaaS (Data as a Service) lub baz danych w chmurze określone wymagania, takie jak prywatność bazy danych , dynamiczna skalowalność i wydajność w zarządzaniu wieloma najemcami , stań się bardziej krytyczny.
Modele danych są nieocenionym narzędziem do spełnienia tych wymagań, ponieważ ułatwiają weryfikację, czy projekt schematu jest z nimi zgodny. Z kolei pozwalają zdefiniować partycje schematów i ich wymagania dotyczące pamięci, co jest niezbędne do prawidłowego zwymiarowania wymaganego poziomu usług i oczekiwanego wzrostu pamięci, gdy bazy danych znajdują się w chmurach prywatnych lub publicznych.
Artefakty projektowania bazy danych, takie jak diagramy ER, to narzędzia z wyboru podczas przygotowywania się do migracji do środowiska chmury. Przewodnik dotyczący korzystania z diagramów ER może dać wgląd w ich przydatność w migracji bazy danych.
Modelowanie baz danych dla Big Data i NoSQL
Nierelacyjne bazy danych, takie jak NoSQL i schematy wymiarowe, mogą zmusić nas do odłożenia (przynajmniej na chwilę) naszego tradycyjnego, relacyjnego sposobu myślenia. Ale to nie znaczy, że możemy obejść się bez modeli danych. Wręcz przeciwnie, modelowanie danych staje się jeszcze ważniejsze.
Kiedy musisz pracować z Big Data, często napotykasz ogromne silosy informacji, które muszą być podzielone, udoskonalone i ustrukturyzowane w taki sposób, abyś Ty lub analityk danych mogli uzyskać z nich strategiczne informacje. Wymagane jest staranne zaprojektowanie schematu, zarówno w przypadku udoskonalonych repozytoriów informacji lub hurtowni danych, jak i repozytoriów etapowych używanych do czyszczenia danych i procesów strukturyzacji danych.
Istnieje błędne przekonanie, głównie wśród programistów, że bazy danych NoSQL nie używają schematów i dlatego nie wymagają modeli danych. Nic nie może być dalsze od prawdy. Ponieważ technologie NoSQL nie zapewniają standardowego sposobu przeglądania metadanych (coś, co robi każdy RDBMS), modele danych stają się niezbędne, aby umożliwić ludziom korzystanie i udostępnianie informacji przechowywanych w bazie danych.
Fuzje i przejęcia
Każda fuzja dwóch organizacji stanowi gigantyczne wyzwanie dla ich działów IT. Istotną częścią tego wyzwania jest konsolidacja baz danych. Jeśli obie organizacje mają aktualne modele danych, konsolidację tę można przeprowadzić w modelach zamiast bezpośrednio w bazach danych, co znacznie zmniejsza nakład pracy związany z zadaniem.
Do tej pory widzieliśmy korzyści z modelowania danych związane z planowaniem strategicznym IT organizacji. Jeśli te powody nie wystarczą, aby przekonać Cię o znaczeniu modelowania danych, przyjrzyjmy się również korzyściom, jakie przynosi w tworzeniu oprogramowania.
Zredukowane koszty rozwoju
Na wczesnych etapach projektu deweloperskiego, kiedy analizowany jest budżet, można kwestionować potrzebę włożenia wysiłku w budowę modelu danych. Jeśli liderzy projektu i menedżerowie są wystarczająco sprytni, porównają koszty budowy i utrzymania modelu danych z kosztami, które zostaną zaoszczędzone i zdecydują się na zbudowanie modelu.
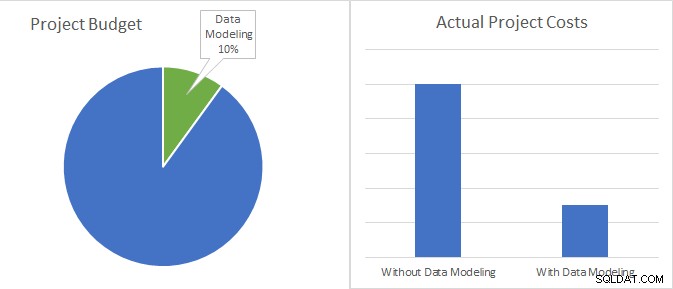
Modelowanie danych to zaledwie 10% budżetu projektu rozwojowego i może obniżyć rzeczywiste koszty projektu do mniej niż jednej trzeciej.
Po prostu rozważ następujące. W większości przypadków koszt modelowania danych (czyli koszt pracy wymaganej do zbudowania i utrzymania modelu) wynosi mniej niż 10% całkowitego budżetu projektu oprogramowania. Dla porównania, oszczędności związane z używaniem modeli danych wynoszą do 70%, a wszystko to dzięki skróceniu godzin kodowania i konserwacji.
Tak więc w tworzeniu oprogramowania pierwszym i najważniejszym powodem modelowania danych jest niekwestionowany zwrot z inwestycji (zwrot z inwestycji), który liderzy projektów muszą wziąć pod uwagę na wczesnych etapach każdego projektu.
Lepsze definicje wymagań
Podczas tworzenia oprogramowania możesz zagwarantować lepsze zrozumienie systemu, który ma być rozwijany, jeśli czynności związane z modelowaniem danych są prowadzone równolegle ze zbieraniem wymagań. Wymagania będą pełniejsze i bardziej poprawne.
Modelowanie danych pomaga odkryć reguły biznesowe i zadawać pytania podczas inżynierii wymagań, zapewniając jednocześnie integralność danych. Jest bardziej skuteczny niż czynności związane z modelowaniem procesów, takie jak projektowanie przypadków użycia lub projektowanie przepływu pracy, i oczywiście bardziej wyrazisty i mniej gadatliwy niż opis reguł biznesowych prozą.
Szybszy rozwój
Gdy programiści mają pod ręką odpowiednie modele danych, mogą wykonywać swoją pracę z mniejszą liczbą błędów. Narzędzia do modelowania danych automatycznie generują i utrzymują schematy baz danych, tworząc skrypty w języku definicji danych (DDL), które są często zbyt długie, złożone i niechlujne, aby programiści mogli je wygenerować ręcznie.
Z kolei te narzędzia wspierają współpracę, umożliwiając udostępnianie modeli między programistami. Gdy potrzebne są zmiany, możesz wprowadzić je w modelu danych, zapewniając, że wszyscy programiści zostaną poinformowani i zostaną zastosowane do baz danych bez naruszania czegokolwiek.
Wszystko to pozwala na szybsze dostarczanie systemów z mniejszą liczbą błędów.
Wzmacnianie metodologii Agile
Metodologie zwinne mają na celu przyspieszenie procesu rozwoju poprzez skupienie wysiłków na dostarczaniu działającego oprogramowania i unikaniu biurokracji, nadmiernej dokumentacji i etapów wykonywanych jedna po drugiej.
Modelowanie baz danych staje przed poważnym wyzwaniem podczas pracy w środowiskach zwinnych, ponieważ projektant musi być w stanie pracować nad „pełnym obrazem”, podczas gdy programiści potrzebują tylko obiektów danych wymaganych dla każdej historyjki użytkownika. Aby osiągnąć konsensus między modelarzami danych a programistami, metodyki zwinne wykorzystują techniki, takie jak sandboxing i rozgałęzianie .
Piaskownica to środowisko pracy każdego programisty. Projektant może pracować z gałęziami głównego modelu danych w piaskownicy każdego programisty, który przekaże informacje zwrotne w celu jego udoskonalenia. Na końcu każdego etapu (lub sprintu) projektant bazy danych łączy różne gałęzie, aby cały model był aktualizowany.
Można by pomyśleć, że modelowanie danych spowalnia zespoły Agile i że programiści muszą czekać, aż modele będą gotowe do rozpoczęcia pracy. Ale w rzeczywistości użycie technik takich jak sandboxing i branching zachowuje zasady zwinności i jednocześnie pozwala na osiągnięcie wspomnianych powyżej usprawnień prędkości.
Co jeśli nie używam modeli danych?
Możesz pomyśleć, że nadal możesz przetrwać bez wymienionych do tej pory modeli danych, aby zaoszczędzić czas. Ale jeśli zrezygnujesz z modelowania danych, ryzykujesz poważne problemy, takie jak:
- Zbędna nadmiarowość:ponieważ nie istnieje model, który pozwalałby wyraźnie widzieć obiekty danych, różne wersje tych samych obiektów będą wyświetlane z różnymi informacjami. Na przykład system inwentaryzacji może zgłosić, że w ostatnim miesiącu sprzedano 500 jednostek towaru, podczas gdy system logistyczny może zgłosić, że w tym samym okresie wysłano 1000 jednostek tego samego towaru. Który jest poprawny? Kto wie.
- Powolne aplikacje:brak modelu danych utrudnia zadania optymalizacyjne, co zmniejsza czas reakcji aplikacji.
- Niezdolność do spełnienia standardów jakości:Jeśli nie ma modelu danych, Twoje bazy danych nie będą udokumentowane, co jest obowiązkowe w scenariuszach takich jak migracje baz danych.
- Słaba jakość oprogramowania:wymagania dotyczące rozwoju oprogramowania będą niskie, a użytkownicy nie będą mieli aplikacji, których potrzebują lub pragną.
- Wyższe koszty rozwoju:Wspomniałem już o znacznych oszczędnościach kosztów, które można osiągnąć w projekcie programistycznym przy użyciu modeli danych. Jeśli zdecydujesz się ich nie używać, będziesz musiał zdecydować, kto płaci za dodatkowe koszty rozwoju i utrzymania. I kto będzie usprawiedliwiał się, gdy terminy nie zostaną dotrzymane.
Wciąż nie jesteś przekonany?
Jeśli to, co do tej pory przeczytałeś, nie wystarcza, aby przekonać Cię o znaczeniu modelowania danych, pamiętaj, że dane stają się coraz cenniejszym zasobem dla wszelkiego rodzaju organizacji. Modelowanie struktur w celu wykorzystania informacji ma dziś bezprecedensowe znaczenie.
Zastanówcie się:podczas gorączki złota ludzie, którzy zarobili najwięcej pieniędzy, nie byli tymi, którzy szukali samorodków złota, ale raczej ci, którzy dostarczyli narzędzia do wydobycia złota. W 2021 r. samorodki złota mają postać wnikliwych informacji, a górnicy, którzy wydobywają tak cenny materiał, muszą otrzymać modele danych.