Zadania luk i wysp to klasyczne wyzwania związane z zapytaniami, w których należy zidentyfikować zakresy brakujących wartości i zakresy istniejących wartości w sekwencji. Sekwencja jest często oparta na jakiejś wartości daty lub daty i godziny, które normalnie powinny pojawiać się w regularnych odstępach czasu, ale brakuje niektórych wpisów. Zadanie przerw wyszukuje brakujące okresy, a zadanie wysp wyszukuje okresy istniejące. W przeszłości omówiłem wiele rozwiązań luk i zadań wysp w moich książkach i artykułach. Niedawno mój przyjaciel Adam Machanic przedstawił mi nowe specjalne wyzwanie wyspowe, a rozwiązanie go wymagało odrobiny kreatywności. W tym artykule przedstawiam wyzwanie i rozwiązanie, które wymyśliłem.
Wyzwanie
W swojej bazie danych śledzisz usługi obsługiwane przez Twoją firmę w tabeli o nazwie CompanyServices, a każda usługa zwykle zgłasza raz na minutę, że jest online w tabeli o nazwie EventLog. Poniższy kod tworzy te tabele i wypełnia je małymi zestawami przykładowych danych:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
Tabela EventLog jest obecnie wypełniona następującymi danymi:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Specjalnym zadaniem wysp jest identyfikacja okresów dostępności (serwisowany, starttime, endtime). Jednym haczykiem jest to, że nie ma pewności, że usługa będzie zgłaszać, że jest online dokładnie co minutę; powinieneś tolerować odstęp do, powiedzmy, 66 sekund od poprzedniego wpisu w dzienniku i nadal uważać, że jest to część tego samego okresu dostępności (wyspa). Po upływie 66 sekund nowy wpis w dzienniku rozpoczyna nowy okres dostępności. Tak więc, dla przykładowych danych wejściowych powyżej, rozwiązanie powinno zwrócić następujący zestaw wyników (niekoniecznie w tej kolejności):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Zauważ na przykład, jak wpis dziennika 5 uruchamia nową wyspę, ponieważ odstęp od poprzedniego wpisu wynosi 120 sekund (> 66), podczas gdy wpis dziennika 6 nie uruchamia nowej wyspy, ponieważ odstęp od poprzedniego wpisu wynosi 62 sekundy ( <=66). Kolejnym haczykiem jest to, że Adam chciał, aby rozwiązanie było kompatybilne ze środowiskami pre-SQL Server 2012, co sprawia, że jest to znacznie trudniejsze wyzwanie, ponieważ nie można używać funkcji agregujących okien z ramką do obliczania bieżących sum i funkcji przesunięcia okien jak LGD i LEAD. Jak zwykle sugeruję samodzielne rozwiązanie problemu, zanim przyjrzę się moim rozwiązaniom. Użyj małych zestawów przykładowych danych, aby sprawdzić poprawność swoich rozwiązań. Użyj poniższego kodu, aby wypełnić tabele dużymi zestawami przykładowych danych (500 usług, ~10 mln wpisów w dzienniku w celu przetestowania wydajności rozwiązań):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Dane wyjściowe, które przedstawię dla etapów moich rozwiązań, przyjmą małe zestawy przykładowych danych, a liczby wydajności, które podam, założą duże zestawy.
Wszystkie rozwiązania, które przedstawię, korzystają z następującego indeksu:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Powodzenia!
Rozwiązanie 1 dla SQL Server 2012+
Zanim omówię rozwiązanie, które jest kompatybilne ze środowiskami poprzedzającymi SQL Server 2012, omówię to, które wymaga minimum SQL Server 2012. Nazwę je Rozwiązaniem 1.
Pierwszym krokiem w rozwiązaniu jest obliczenie flagi o nazwie isstart, która wynosi 0, jeśli zdarzenie nie rozpoczyna nowej wyspy, a 1 w przeciwnym razie. Można to osiągnąć, korzystając z funkcji LAG, aby uzyskać czas rejestrowania poprzedniego zdarzenia i sprawdzając, czy różnica czasu w sekundach między poprzednim a bieżącym zdarzeniem jest mniejsza lub równa dozwolonej przerwie. Oto kod implementujący ten krok:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Ten kod generuje następujące dane wyjściowe:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Następnie prosta suma bieżąca flagi isstart tworzy identyfikator wyspy (nazwę go grp). Oto kod implementujący ten krok:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Ten kod generuje następujące dane wyjściowe:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Na koniec grupujesz wiersze według identyfikatora usługi i identyfikatora wyspy i zwracasz minimalny i maksymalny czas rejestrowania jako czas rozpoczęcia i zakończenia każdej wyspy. Oto kompletne rozwiązanie:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
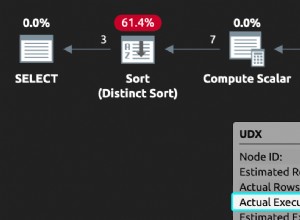
GROUP BY serviceid, grp; To rozwiązanie zajęło 41 sekund w moim systemie i stworzyło plan pokazany na rysunku 1.
 Rysunek 1:Plan rozwiązania 1
Rysunek 1:Plan rozwiązania 1
Jak widać, obie funkcje okna są obliczane na podstawie kolejności indeksów, bez potrzeby jawnego sortowania.
Jeśli używasz SQL Server 2016 lub nowszego, możesz użyć sztuczki, którą tutaj omówię, aby włączyć operator Window Aggregate w trybie wsadowym, tworząc pusty filtrowany indeks magazynu kolumn, na przykład:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
To samo rozwiązanie zajmuje teraz tylko 5 sekund w moim systemie, tworząc plan pokazany na rysunku 2.
 Rysunek 2:Planowanie rozwiązania 1 w trybie wsadowym Operator agregacji okna
Rysunek 2:Planowanie rozwiązania 1 w trybie wsadowym Operator agregacji okna
To wszystko świetnie, ale jak wspomniano, Adam szukał rozwiązania, które może działać w środowiskach sprzed 2012 roku.
Zanim przejdziesz dalej, upewnij się, że upuściłeś indeks magazynu kolumn w celu oczyszczenia:
DROP INDEX idx_cs ON dbo.EventLog;
Rozwiązanie 2 dla środowisk starszych niż SQL Server 2012
Niestety, przed SQL Server 2012 nie mieliśmy obsługi funkcji przesunięcia okna, takich jak LAG, ani nie mieliśmy obsługi obliczania bieżących sum za pomocą funkcji agregujących okna z ramką. Oznacza to, że będziesz musiał pracować znacznie ciężej, aby znaleźć rozsądne rozwiązanie.
Sztuczka, której użyłem, polegała na przekształceniu każdego wpisu w dzienniku w sztuczny interwał, którego godziną rozpoczęcia jest czas rejestracji wpisu, a godziną zakończenia jest czasem dziennika wpisu plus dozwolona przerwa. Następnie możesz potraktować to zadanie jako klasyczne zadanie pakowania interwałowego.
Pierwszym krokiem w rozwiązaniu jest obliczenie sztucznych ograniczników interwałów i numerów wierszy oznaczających pozycje każdego z rodzajów zdarzeń (counteach). Oto kod implementujący ten krok:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Ten kod generuje następujące dane wyjściowe:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Następnym krokiem jest rozłożenie interwałów w chronologiczną sekwencję zdarzeń początkowych i końcowych, identyfikowanych odpowiednio jako typy zdarzeń „s” i „e”. Zauważże wybór liter s i e jest ważny ('s' > 'e' ). W tym kroku obliczane są numery wierszy oznaczające prawidłową kolejność chronologiczną obu rodzajów zdarzeń, które są teraz przeplatane (policzyć oba). W przypadku, gdy jeden interwał kończy się dokładnie tam, gdzie zaczyna się inny, umieszczając wydarzenie początkowe przed wydarzeniem końcowym, spakujesz je razem. Oto kod implementujący ten krok:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Ten kod generuje następujące dane wyjściowe:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Jak wspomniano, counteach oznacza pozycję zdarzenia tylko wśród zdarzeń tego samego rodzaju, a countoba oznacza pozycję zdarzenia wśród połączonych, przeplatanych zdarzeń obu rodzajów.
Magia jest następnie obsługiwana przez następny krok — obliczanie liczby aktywnych interwałów po każdym zdarzeniu w oparciu o counteach i countoba. Liczba aktywnych interwałów to liczba zdarzeń początkowych, które miały miejsce do tej pory, minus liczba zdarzeń końcowych, które miały miejsce do tej pory. W przypadku zdarzeń początkowych counteach informuje, ile zdarzeń początkowych wydarzyło się do tej pory i można obliczyć, ile zakończyło się do tej pory, odejmując counteach od countboth. Zatem pełne wyrażenie mówiące, ile interwałów jest aktywnych, to:
counteach - (countboth - counteach)
W przypadku zdarzeń końcowych counteach mówi, ile zdarzeń końcowych wydarzyło się do tej pory, a można obliczyć, ile rozpoczęło się do tej pory, odejmując counteach od countobath. Zatem pełne wyrażenie mówiące, ile interwałów jest aktywnych, to:
(countboth - counteach) - counteach
Używając następującego wyrażenia CASE, obliczasz kolumnę countactive na podstawie typu zdarzenia:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END W tym samym kroku filtrujesz tylko zdarzenia reprezentujące początki i końce upakowanych interwałów. Początki upakowanych interwałów mają typ 's' i liczności 1. Końce upakowanych interwałów mają typ 'e' i liczności 0.
Po przefiltrowaniu pozostają pary zdarzeń początek-koniec w upakowanych interwałach, ale każda para jest dzielona na dwa wiersze — jeden dla zdarzenia początkowego, a drugi dla zdarzenia końcowego. Dlatego ten sam krok oblicza identyfikator pary przy użyciu numerów wierszy za pomocą formuły (rownum – 1) / 2 + 1.
Oto kod implementujący ten krok:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Ten kod generuje następujące dane wyjściowe:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Ostatni krok przestawia pary zdarzeń w wiersz na interwał i odejmuje dozwoloną przerwę od czasu zakończenia, aby odtworzyć prawidłowy czas zdarzenia. Oto kompletny kod rozwiązania:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; To rozwiązanie zajęło 43 sekundy w moim systemie i wygenerowało plan pokazany na rysunku 3.
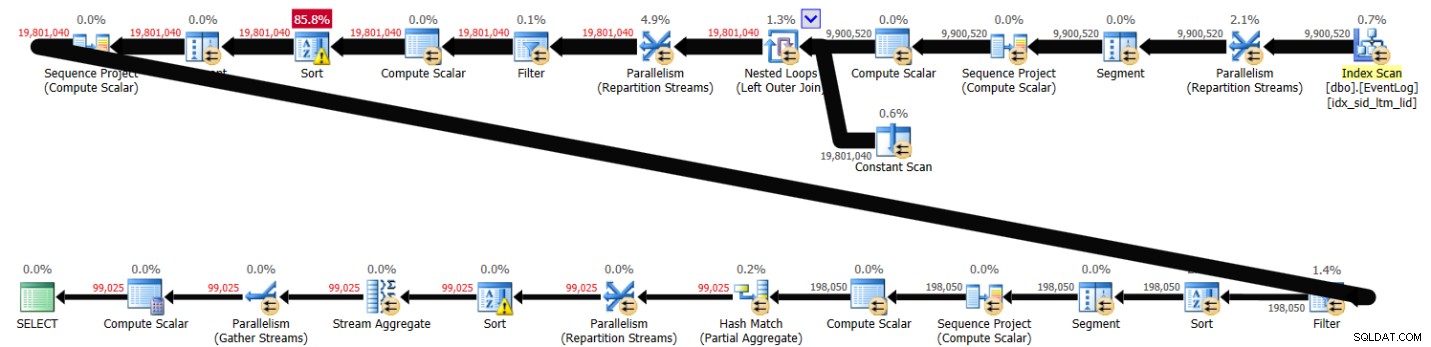 Rysunek 3:Plan rozwiązania 2
Rysunek 3:Plan rozwiązania 2
Jak widać, obliczenie pierwszego numeru wiersza jest obliczane na podstawie kolejności indeksów, ale następne dwa wymagają jawnego sortowania. Mimo to wydajność nie jest taka zła, biorąc pod uwagę około 10 000 000 wierszy.
Chociaż celem tego rozwiązania jest użycie środowiska wcześniejszego niż SQL Server 2012, dla zabawy przetestowałem jego wydajność po utworzeniu filtrowanego indeksu magazynu kolumn, aby zobaczyć, jak to działa z włączonym przetwarzaniem wsadowym:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Po włączeniu przetwarzania wsadowego to rozwiązanie zajęło 29 sekund w moim systemie, tworząc plan pokazany na rysunku 4.
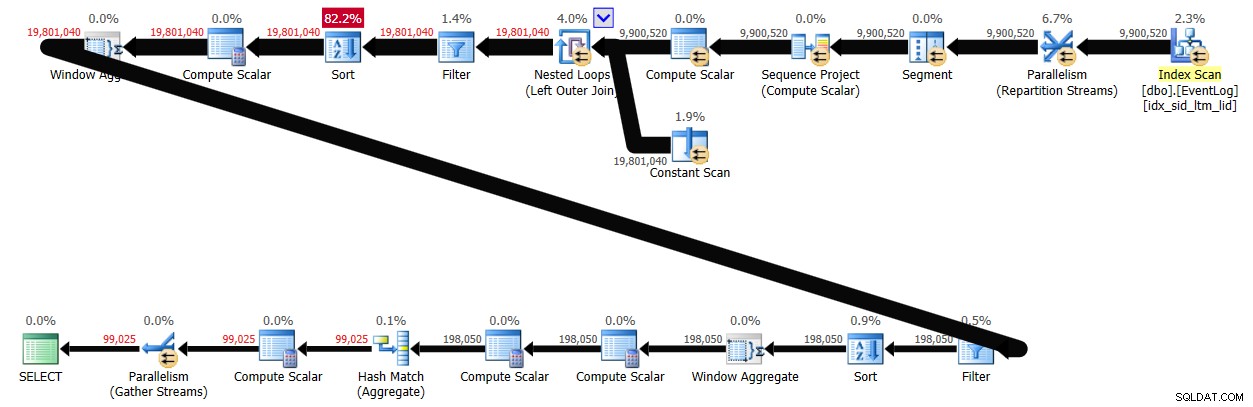
Wniosek
To naturalne, że im bardziej ograniczone jest Twoje środowisko, tym trudniejsze staje się rozwiązywanie zadań związanych z zapytaniami. Specjalne wyzwanie Adama Wyspy jest znacznie łatwiejsze do rozwiązania na nowszych wersjach SQL Server niż na starszych. Ale potem zmuszasz się do użycia bardziej kreatywnych technik. W ramach ćwiczenia, aby poprawić swoje umiejętności zadawania zapytań, możesz stawić czoła wyzwaniom, które już znasz, ale celowo nałożyć pewne ograniczenia. Nigdy nie wiesz, na jakie ciekawe pomysły możesz się natknąć!