Zintegrowany transport to coś, o czym często słyszymy w Internecie lub w wiadomościach. Chociaż nie jest to coś nowego, zdecydowanie jest to ciągły proces, w którym wprowadzane są ciągłe zmiany. Dzisiaj przyjrzymy się modelowi danych, który może obsługiwać informacje o strefie, pasażerach i biletach.
Przejdźmy od razu do naszego zintegrowanego modelu danych transportowych, zaczynając od idei, która za tym wszystkim stoi.
Pomysł
Integracja transportu jest konieczna, aby zmaksymalizować jego efektywność, a dla klientów łatwość jego użytkowania. Integracja wiąże się z kosztami, ale także z czasem, dostępnością, wygodą i bezpieczeństwem. Dotyczy to zarówno większych miast, jak i mniejszych. Chodzi o to, aby wykorzystać istniejącą infrastrukturę transportową i zoptymalizować ją w celu uzyskania lepszych wyników; może to oznaczać wymyślanie nowych rozkładów jazdy, powiadomień, linii lub stacji. Być może samo posiadanie informacji wystarczy, aby zdecydować się poczekać na autobus, wypożyczyć rower lub po prostu dojść do celu.
Wyjaśnijmy to na dwóch przykładach.
W przypadku dużego miasta zazwyczaj dostępnych jest wiele różnych środków transportu:autobusy, taksówki, tramwaje, kolej, metro itp. Może to prowadzić do tego, że wiele różnych prywatnych firm świadczy różne usługi transportowe. Połączenie nawet kilku z tych usług zdecydowanie przyniosłoby korzyści pasażerom i firmom, obniżając koszty, zwiększając wydajność i zapewniając więcej usług na jeden bilet.
Podobne korzyści mają też mniejsze miasta. Może nie być takiej samej liczby opcji do połączenia, ale można je zorganizować w celu osiągnięcia maksymalnej wydajności.
W tym artykule skupimy się głównie na zintegrowanych systemach biletowych w transporcie. Nie będziemy skupiać się na wszystkich aspektach integracji i różnych rodzajach transportu; to byłoby zbyt skomplikowane.
Mając to na uwadze, przejdźmy do naszego modelu.
Model danych
Model składa się z dwóch obszarów tematycznych:
Cities & companiesTickets
Opiszemy je w kolejności, w jakiej są wymienione.
Miasta i firmy
W pierwszym obszarze tematycznym przechowamy wszystkie tabele wymagane do utworzenia stref transportu w miastach.
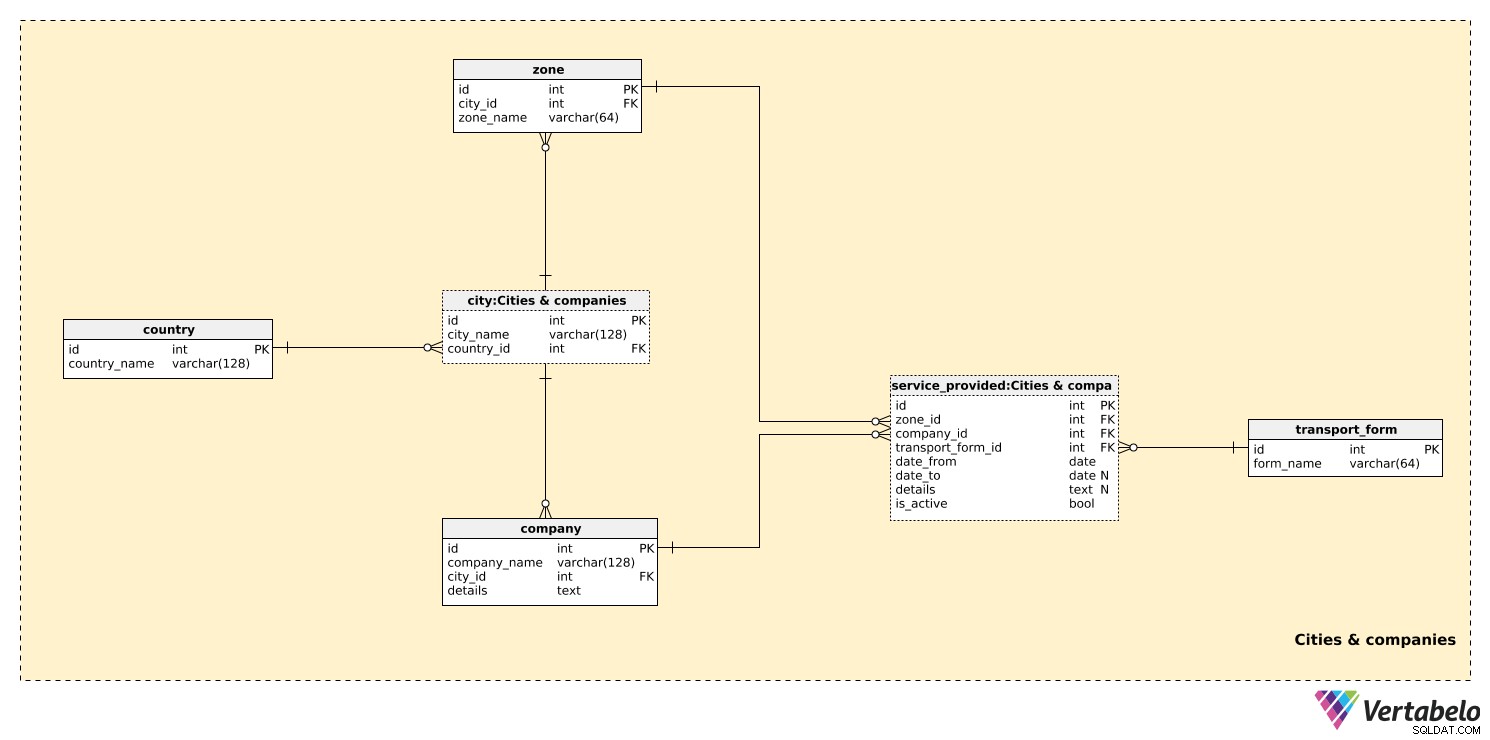
country tabela zawiera listę UNIKATOWYCH country_name wartości. Ta tabela jest używana tylko jako odniesienie w city stół. Chociaż możemy oczekiwać, że nasz model obejmie transport tylko w jednym kraju, chcemy mieć możliwość uwzględnienia wielu krajów. Dla każdego miasta będziemy przechowywać UNIKALNĄ kombinację city_name – country_id .
Mniejsze miasta będą prawdopodobnie miały tylko jedną strefę, podczas gdy większe miasta będą miały wiele stref. Lista wszystkich możliwych stref jest przechowywana w zone stół. Dla każdej strefy zapiszemy jej zone_name oraz odniesienie do odpowiedniego miasta. Ta para tworzy klucz alternatywny tej tabeli.
Możemy oczekiwać, że nasz system będzie przechowywać informacje o wielu firmach transportowych. Firmy będą wystawiać własne bilety, ale będą też mogły wystawiać bilety wspólnie z innymi firmami. Dla każdej company , będziemy przechowywać UNIKALNĄ kombinację company_name i city_id gdzie to się znajduje. Wszelkie potrzebne dodatkowe informacje mogą być przechowywane w tekstowych details pole.
Ostatnią rzeczą, jaką musimy określić, jest forma transportu, jaką zapewnia każda firma. Niektóre oczekiwane wartości to „autobus”, „tramwaj”, „metro” i „kolej”. Dla każdej wartości w transport_form tabeli, przechowamy UNIKALNĄ nazwę formularza.
zone_id– Odwołuje się dozonetabela i oznacza obszar, w którym ta forma transportu jest świadczona przez tę firmę.company_id– Odwołuje się docompanyświadczenie tej usługi w tej strefie.transport_form_id– Odwołuje się dotransport_formtabela i oznacza rodzaj świadczonej usługi.date_fromidate_to– Okres, w którym ta usługa była świadczona przez tę firmę. Zwróć uwagę, żedate_tomoże zawierać wartość NULL, jeśli ta usługa jest nadal dostępna i/lub nie ma oczekiwanej daty wygaśnięcia.details– Wszystkie inne szczegóły w nieustrukturyzowanym formacie tekstowym.is_active– Czy ta usługa jest aktywna (w toku), czy nie. Jest to prosty włącznik/wyłącznik, którego możemy użyć w niektórych przypadkach zamiastdate_from–date_tointerwał czynności serwisowych. Najlepszym zastosowaniem tego atrybutu byłoby uproszczenie zapytań, tj. testowanie tej wartości zamiast testowania interwału dat i „bawy się” wartościami NULL.
Bilety
Poprzedni obszar tematyczny był tylko przygotowaniem do najważniejszego:biletów. I to właśnie obejmie ten obszar tematyczny.
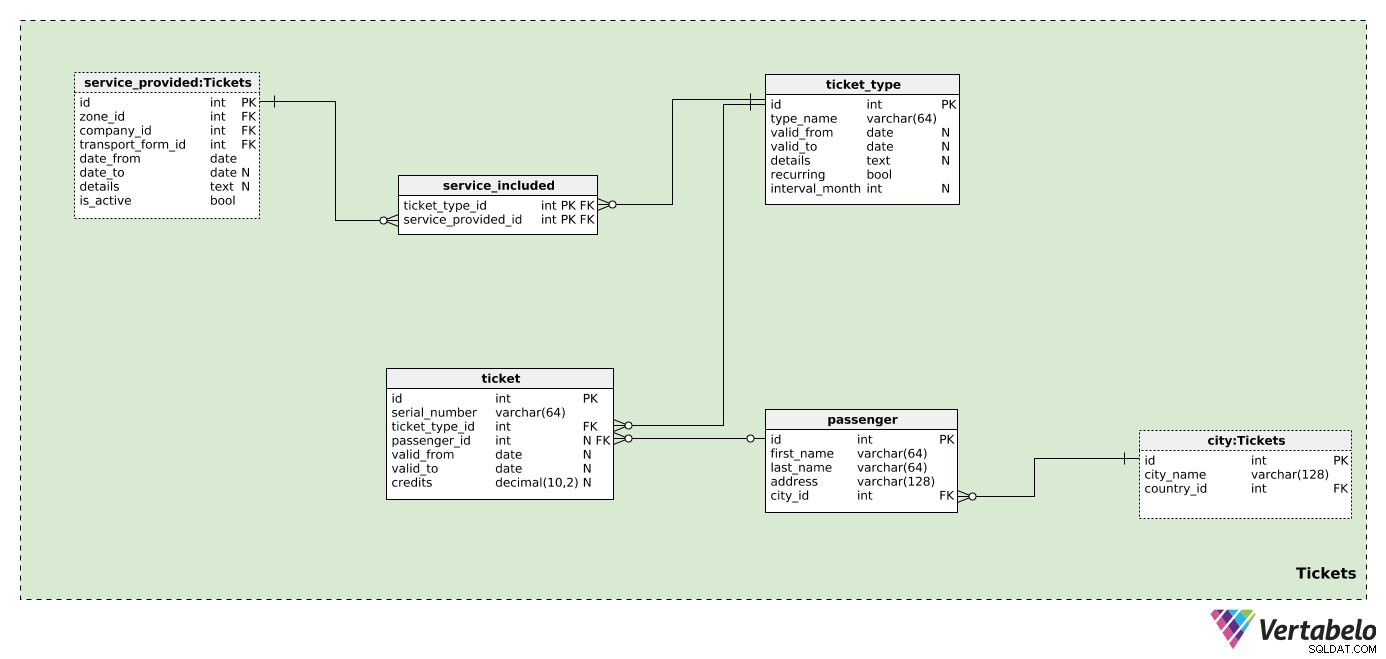
Zdefiniowaliśmy firmy, strefy i formy transportu, ale nie mamy żadnej rezerwy na pasażerów i bilety – sedno tego modelu. Założymy, że jeden bilet może być wykorzystany do jednej lub więcej stref obsługiwanych przez jedną lub więcej firm.
Dlatego najpierw musimy zdefiniować każdy ticket_type . W tej tabeli wymienimy wszystkie możliwe rodzaje biletów sprzedawanych przez firmy z naszej bazy danych. Dla każdego typu będziemy przechowywać następujące wartości:
type_name– Nazwa WYJĄTKOWO oznaczająca ten typ.valid_fromivalid_to– Okres, w którym ten rodzaj biletu jest (lub był) ważny. Oba pola mają wartość null; wartość NULL oznacza, że nie ma daty początkowej (lub końcowej), kiedy to było ważne.details– Wszelkie niezbędne szczegóły w nieustrukturyzowanym formacie tekstowym.recurring– Flaga wskazująca, czy ten typ biletu jest cykliczny (np. roczny, miesięczny), czy nie.interval_month– Jeśli typ biletu jest cykliczny, ten atrybut będzie zawierał interwał w miesiącach, w którym występuje (np. „1” dla biletu miesięcznego, „12” dla biletu rocznego).
Teraz jesteśmy gotowi do zdefiniowania stref objętych każdym typem biletu. W service_included tabeli, będziemy przechowywać tylko UNIKALNĄ parę ticket_type_id – service_available_id . Ten ostatni wskaże również firmę i strefę, w której można wykorzystać ten bilet. Ta tabela pozwala nam zdefiniować wiele stref na bilet; strefy mogą należeć do różnych firm. Ponieważ są to predefiniowane typy biletów, każdy rodzaj biletu będzie miał zdefiniowane tutaj strefy (nie dla każdego pojedynczego pasażera).
W tym modelu nie będziemy przechowywać zbyt wielu danych pasażera. Dla każdego passenger , będziemy przechowywać tylko ich first_name , last_name , address oraz nawiązanie do miasta, w którym mieszkają. Wszystkie te dane zostaną wyświetlone na bilecie.
Ostatnia tabela w naszym modelu to ticket stół. Nie skupimy się tutaj na biletach jednorazowych; raczej zajmiemy się biletami abonamentowymi i przedpłaconymi. Bilety te będą miały saldo, datę ważności lub oba te elementy. Może się to znacznie różnić w zależności od firmy i jej zasad. Jeśli kilka firm zdecyduje się na wystawienie biletu, moglibyśmy poprzeć to w tej tabeli – poznamy wszystkie ważne szczegóły. Dla każdego biletu przechowujemy:
serial_number– UNIKALNE oznaczenie dla każdego biletu. Może to być kombinacja cyfr i liter.ticket_type_id– Odwołuje się do typu tego biletu.passenger_id– Odsyła do pasażera, jeśli taki istnieje, który jest właścicielem tego biletu. W przypadku biletu opłaconego z góry może nie być właściciela.valid_fromivalid_to– Oznacza okres, w którym bilet jest ważny. Wartości NULL oznaczają, że nie ma dolnej ani górnej granicy.credits– Kredyty (jako wartość liczbowa) aktualnie dostępne na tym bilecie. Jeśli jest to bilet przedpłacony, możemy założyć, że pasażerowie kupią dodatkowe kredyty na bilecie. Jeśli bilet jest ważny przez cały miesiąc (lub inny okres) bez żadnych ograniczeń użytkowania, ta wartość może wynosić NULL.
Ulepszenia zintegrowanego modelu danych transportowych
Widać, że model ten został znacznie uproszczony. To dlatego, że transport zintegrowany jest po prostu zbyt duży, by opisać go w jednym artykule. Jest kilka rzeczy, które moim zdaniem można zmienić w tym modelu:
- Strefy są zbyt uproszczone; powinniśmy być w stanie zdefiniować je bardziej dynamicznie.
- Nie pokrywamy linii (np. linii autobusowych). Co się stanie, jeśli przejdą z jednej strefy do drugiej itd.?
- Nie przechowujemy historii wykorzystania biletów.
- Nie ma rejestracji dla firm i pasażerów.
Wszystko to prowadziłoby do tego, że brakowało nam ważnych danych i nie moglibyśmy przeprowadzić głębszej analizy. Więc co o tym myślisz? Czego potrzebuje ten model? Co byś dodał lub usunął? Podziel się swoimi pomysłami w komentarzach.