Model danych płacowych umożliwia łatwe obliczanie wynagrodzenia pracowników. Jak działa ten model?
Bez względu na to, czy prowadzisz małą, czy dużą firmę, potrzebujesz jakiegoś rozwiązania płacowego. Tutaj przydaje się aplikacja płacowa. Co więcej, im większa firma, tym trudniej radzić sobie z naliczaniem wynagrodzeń pracowników; tutaj aplikacja płacowa staje się koniecznością. Aby pomóc Ci zrozumieć wszystkie dane wymagane dla takiej aplikacji, przeprowadzimy Cię przez powiązany model danych.
Zobaczmy, jak działa nasz model danych płacowych!
Model danych
Tworząc ten model danych, starałem się stworzyć model, który będzie ogólnie stosowany dla każdego biznesu. Oczywiście zawsze będą istniały różnice w przepisach, politykach firmy itp., które będą wymagać dostosowania modelu do potrzeb konkretnej listy płac. Jednak zasady określone w tym modelu powinny być odpowiednie dla większości organizacji.
Należy zauważyć, że model ten powstał przy kilku założeniach:
- Wynagrodzenia zgodnie z umową o pracę są roczne.
- Wynagrodzenia netto (tj. z pewnymi kwotami potrącanymi z tytułu podatków itp.) są wypłacane pracownikom.
- Wynagrodzenia są wypłacane co miesiąc.
Model danych składa się z czternastu tabel i jest podzielony na dwa obszary tematyczne:
EmployeesSalaries
Aby lepiej zrozumieć model, konieczne jest dokładne przeanalizowanie każdego obszaru tematycznego.
Pracownicy
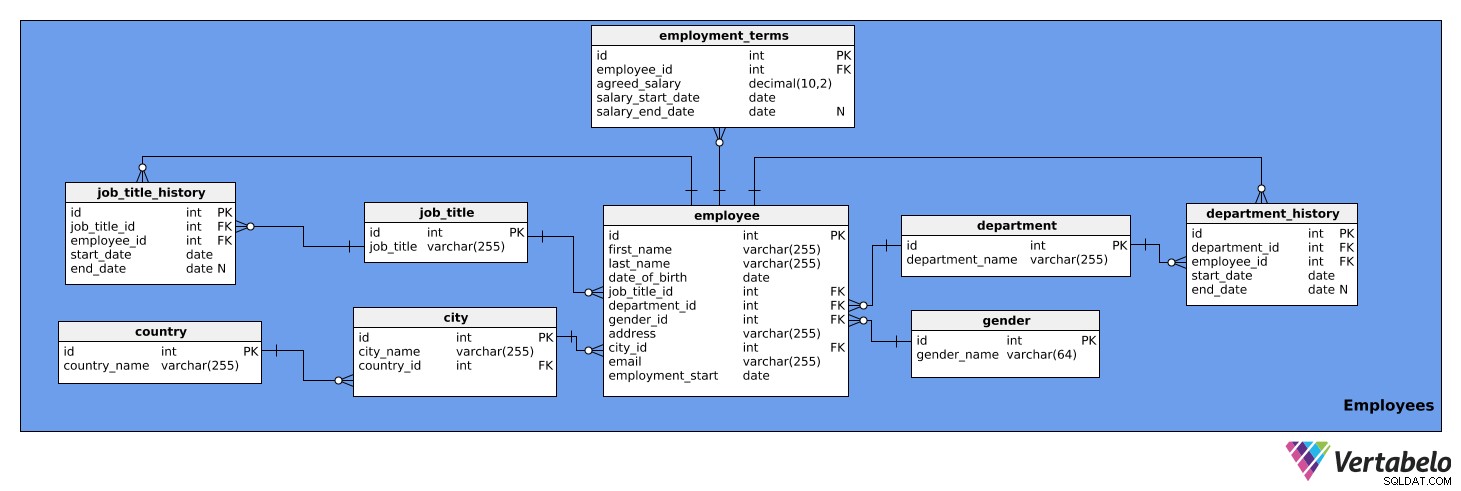
Ten obszar tematyczny zawiera szczegółowe informacje o pracownikach. Składa się z dziewięciu tabel:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
Pierwsza tabela, na którą spojrzymy, to employee stół. Zawiera listę wszystkich pracowników i ich istotne szczegóły. Atrybuty tabeli to:
id– Unikalny identyfikator dla każdego pracownika.first_name– Imię pracownika.last_name– Nazwisko pracownika.job_title_id– Odwołuje się dojob_titlestół.department_id– Odwołuje się dodepartmentstół.gender_id– Odwołuje się dogenderstół.address– Adres pracownika.city_id– Odwołuje się docitystół.email– E-mail pracownika.employment_start– Data rozpoczęcia zatrudnienia tej osoby.
Zwróć uwagę, że kolumny job_title_id i department_id są zbędne, ponieważ informacje o aktualnych stanowiskach i działach można uzyskać z job_title_history i department_history tabele. Jednak zachowamy te dwie kolumny w tej tabeli, aby uzyskać szybszy dostęp do informacji.
Poniżej znajdują się employment_terms stół. Przechowuje dane o wynagrodzeniu każdego pracownika, zgodnie z umową o pracę, oraz o tym, jak zmieniało się ono w czasie. Atrybuty tabeli to:
id– Unikalny identyfikator dla każdego zestawu warunków zatrudnienia.employee_id– Odwołuje się doemployeestół.agreed_salary– Wynagrodzenie określone w umowie o pracę.salary_start_date– Data rozpoczęcia uzgodnionego wynagrodzenia.salary_end_date– Data zakończenia uzgodnionego wynagrodzenia. Może to być NULL, ponieważ wynagrodzenie może nie mieć planowanej zmiany.
job_title tabela to lista tytułów stanowisk, które można przypisać różnym pracownikom firmy, np. analityk, kierowca, sekretarka, dyrektor itp. Tabela ma następujące atrybuty:
id– Unikalny identyfikator dla każdego stanowiska.job_title– Nazwa stanowiska. To jest klucz alternatywny.
Potrzebujemy również tabeli do przechowywania historii tytułów zawodowych każdego pracownika. Potrzebujemy tego, ponieważ pracownicy mogą być awansowani, degradowani lub przenoszeni w firmie. job_title_history tabela będzie zarządzać tymi informacjami i będzie składać się z następujących atrybutów:
id– Unikalny identyfikator wpisu historycznego dotyczącego stanowiska.job_title_id– Odwołuje się dojob_titlestół.employee_id– Odwołuje się doemployeestół.start_date– Data, w której pracownik po raz pierwszy posiadał ten tytuł zawodowy.end_date– Kiedy pracownik przestał mieć ten tytuł zawodowy. Może to być NULL, ponieważ pracownik może obecnie posiadać ten tytuł zawodowy.
Kombinacja job_title_id , employee_id i start_date jest alternatywnym kluczem dla powyższej tabeli. Pracownik może mieć przydzielony tylko jeden tytuł zawodowy w danym dniu.
Następna tabela to department stół. Będzie to po prostu lista wszystkich działów firmy, takich jak IT, Księgowość, Prawny itp. Zawiera dwa atrybuty:
id– Unikalny identyfikator dla każdego działu.department_name– Nazwa każdego działu. To jest klucz alternatywny.
Pracownicy mogą również zmieniać działy w firmie. Dlatego musimy mieć department_history stół. Ta tabela przechowuje następujące informacje:
id– Unikalny identyfikator wpisu historycznego tego działu.department_id– Odwołuje się dodepartmentstół.employee_id– Odwołuje się doemployeestół.start_date– Data rozpoczęcia pracy przez pracownika w dziale.end_date- Data, w której pracownik przestał pracować w tym dziale. Może to być NULL, ponieważ pracownik może nadal tam pracować.
Kombinacja department_id , employee_id i start_date jest kluczem alternatywnym. Pracownik może pracować jednocześnie tylko w jednym dziale.
Następna tabela, o której będziemy mówić, to city stół. To jest lista wszystkich odpowiednich miast. Ma następujące atrybuty:
id– Unikalny identyfikator dla każdego miasta.city_name– Nazwa miasta.country_id– Odwołuje się docountrystół.
country tabela jest następna w naszym modelu. To po prostu lista krajów zawierająca następujące informacje:
id– Unikalny identyfikator dla każdego kraju.country_name– Nazwa kraju. To jest klucz alternatywny.
Ostatnia tabela w tym obszarze tematycznym to gender stół. Ta tabela zawiera listę wszystkich płci. Zawiera następujące atrybuty:
id– Unikalny identyfikator dla każdej płci.gender_name– Nazwa płci.
Przeanalizujmy teraz drugi obszar tematyczny.
Wynagrodzenia
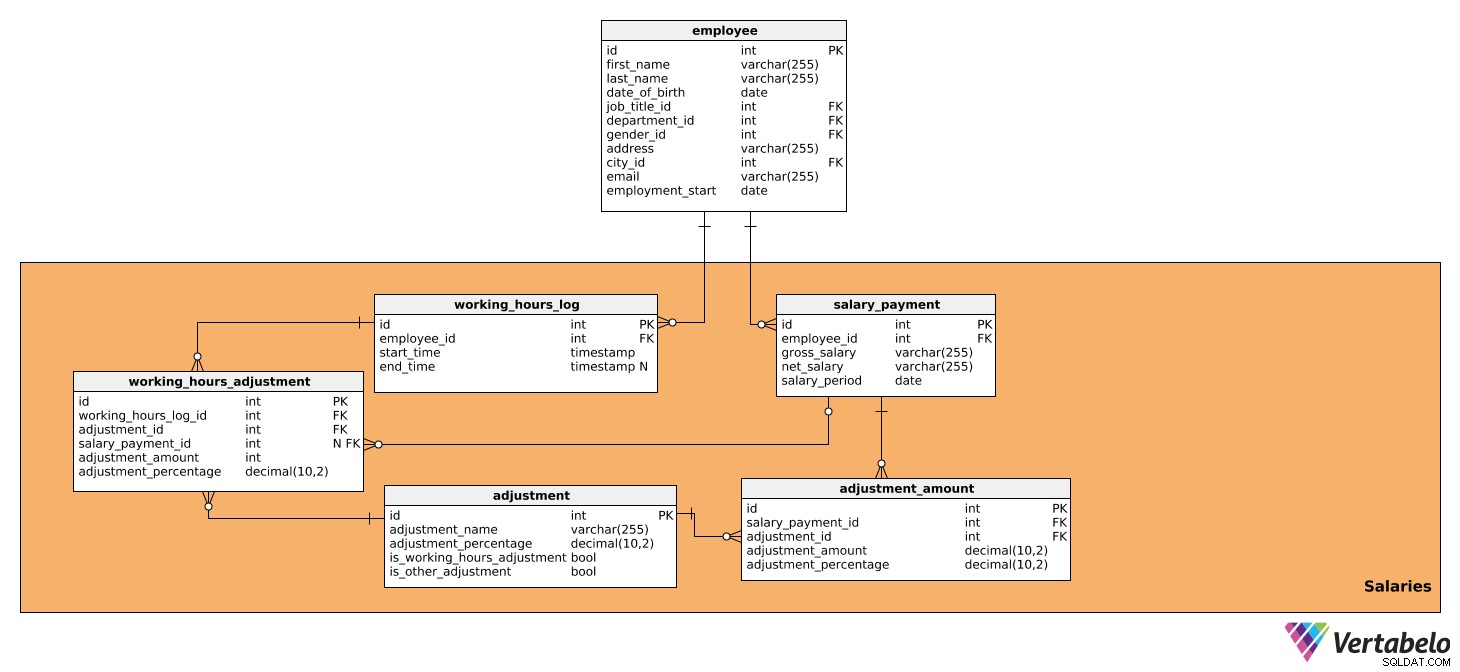
Ten obszar tematyczny składa się z tabel, które zawierają wszystkie dane, które bezpośrednio wpływają na kalkulację wynagrodzenia za każdy okres oraz kwotę do wypłaty. Składa się z pięciu tabel:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Teraz spójrzmy na każdy stół.
Pierwsza tabela to salary_payment . Zawiera wszystkie istotne szczegóły dotyczące wynagrodzenia wypłacanego każdemu pracownikowi i ma następujące atrybuty:
id– Unikalny identyfikator dla każdej pensji.employee_id– Odwołuje się doemployeestół.gross_salary– Wynagrodzenie brutto, które będzie podstawą do dalszych korekt.net_salary– Wynagrodzenie netto (tj. kwota otrzymana przez pracownika po dokonaniu różnych potrąceń).salary_period– Okres, za który jest naliczane i wypłacane wynagrodzenie.
Drugi to working_hours_log stół. Zawiera dane o liczbie godzin przepracowanych przez każdego pracownika, co może mieć wpływ na pewne korekty wynagrodzeń. Ta tabela ma następujące atrybuty:
id– Unikalny identyfikator dla każdego wpisu w dzienniku.employee_id– Odwołuje się doemployeestół.start_time– Godzina zalogowania pracownika, czyli rozpoczęcia pracy na dany dzień.end_time– Kiedy pracownik się wylogował. Może być NULL, ponieważ nie będziemy znać dokładnej godziny, dopóki pracownik się nie wyloguje.
Następna tabela, którą przeanalizujemy, to working_hours_adjustment . Ta tabela będzie używana tylko do obliczania korekt na podstawie przepracowanych godzin, tj. tych, które mają wartość TRUE w is_working_hours_adjustment w adjustment stół. Atrybuty są następujące:
id– Unikalny identyfikator dla każdej regulacji.working_hours_log_id– Odwołuje się doworking_hours_logstół.adjustment_id- Odwołuje się doadjustmentstół.salary_payment_id– Odwołuje się dosalary_paymentstół. Ta wartość może wynosić NULL, ponieważsalary_payment_idbędzie używany tylko raz w miesiącu, kiedy rozpoczniemy naliczanie pensji.adjustment_amount– Kwota korekty.adjustment_percentage– Procentowa kwota korekty. Będzie to wykorzystywane do celów historycznych, ponieważ procent może się zmieniać w czasie.
Następna tabela, o której będziemy mówić, to adjustment stół. Zawiera informacje o wszystkich korektach stosowanych do obliczenia wynagrodzenia, czyli o wszystkich podatkach i składkach, które mają wpływ na wysokość wynagrodzenia. Będzie również zawierał wszystkie korekty, które zależą od przepracowanych i nieprzepracowanych godzin, takie jak premie, nadgodziny, zwolnienia chorobowe i urlopy macierzyńskie/ojcowskie. W tym celu potrzebujemy następujących danych:
id– Unikalny identyfikator dla każdej korekty.adjustment_name– Nazwa opisująca tę regulację.adjustment_percentage– Procentowa kwota określonej korekty.is_working_hours_adjustment– Jest to oznaczenie flagą, jeśli korekta zależy bezpośrednio od godzin pracy, np. nadgodziny, zwolnienia lekarskie itp.is_other_adjustment– To jest flaga oznaczająca korekty, których nie bezpośrednio zależą od przepracowanych godzin, takich jak odliczenia podatkowe, składki na ubezpieczenie społeczne, składki pracodawcy itp.
Następnie potrzebujemy adjustment_amount stół. Będzie on używany do obliczania wszystkich korekt wynagrodzeń z wyjątkiem tych, które już znajdują się w working_hours_adjustment , czyli te, które mają wartość TRUE w is_other_adjustment w adjustment stół. Tabela zawiera następujące atrybuty:
id– Unikalny identyfikator dla każdego wpisu kwoty korekty.salary_payment_id– Odwołuje się dosalary_paymentstół.adjustment_id– Odwołuje się doadjustmentstół.adjustment_amount– Kwota każdej obliczonej korekty.adjustment_percentage- Procentowa kwota korekty. Będzie używany do celów historycznych, ponieważ procent może się zmieniać w czasie.
Podam przykład, w jaki sposób tabele working_hours_log , working_hours_adjustment , adjustment i adjustment_amount współpracować, aby obliczyć wynagrodzenie. Pracownik codziennie rejestruje, kiedy przychodzi do pracy i kiedy wychodzi. Te dane można zobaczyć w working_hours_log stół. Załóżmy, że nasz pracownik przepracował 10 godzin nadliczbowych przez jeden miesiąc i zgodnie z polityką firmy będzie mu płacić 20% więcej za godzinę za każdą nadgodzinę. Odwołując się do adjustment tabeli, będziemy mogli znaleźć wymaganą korektę, czyli nadgodziny, które będą miały określoną wartość procentową (20%). Będziemy też mieć is_working_hours_adjustment ustawiony na PRAWDA. Korzystając z danych z tych dwóch tabel, będziemy mogli obliczyć korektę i zapisać ją w working_hours_adjustment stół.
Teraz możemy obliczyć wszystkie inne dostosowania, których nie zależą od przepracowanych godzin. Zostanie to zrobione w adjustment_amount stół. Tak jak zrobiliśmy powyżej, odniesiemy się do adjustment tabeli i znajdź potrzebne korekty – m.in. odliczenia podatku, składki na ubezpieczenie społeczne lub składki pracodawcy – oraz ich odpowiednich wartości procentowych. is_other_adjustment flaga w adjustment dla tych zmian tabela zostanie ustawiona na PRAWDA.
Na podstawie tych obliczeń możemy przechowywać dane o wynagrodzeniach brutto i netto w salary_payment stół.
Przechodząc przez ten przykład, omówiliśmy wszystko w naszym modelu danych!
Czy podobał Ci się model danych płacowych?
Starałem się stworzyć model, który mógłby być używany w prawie wszystkich sytuacjach. Nie da się jednak zawrzeć w artykule tej długości wszystkich konkretnych parametrów, które wpływają na wyliczenie wynagrodzenia. Omawiając ogólne zasady, starałem się, aby ten model był użyteczny jako solidna podstawa dla Twojego modelu danych płacowych.
Co sądzisz o modelu danych płacowych? Czy ma zastosowanie jako rozwiązanie dla Twoich potrzeb płacowych? Wymyśliłeś coś innego? Czy znalazłeś jakieś konkretne problemy, które mogłyby znacząco zmienić model danych? Wypowiedz się w sekcji komentarzy.