Jak przechowywane są wszystkie te dane opinii publicznej? Sprawdzamy model danych sondaży.
Każdy chce wiedzieć, co myśli opinia publiczna, od polityków i firm po osoby, które chcą wiedzieć, co myślą inni na określony temat. Ten rodzaj pracy jest zwykle wykonywany przez agencje specjalizujące się w tego typu badaniach.
Dzisiaj przyjrzymy się modelowi danych, którego taka agencja mogłaby użyć do przechowywania wszystkich istotnych danych z ankiet, od pytań i wstępnie zdefiniowanych odpowiedzi po rzeczywiste opinie. Te dane będą później wykorzystywane do tworzenia różnych raportów. Więc zacznijmy.
Pomysł
Ankiety można tworzyć w dowolnym miejscu. Mogą być dobrze zaplanowane i obejmować reprezentatywną próbę społeczeństwa (opartą na danych demograficznych). Możesz też zrobić je na miejscu, np. jeśli chcesz przewidzieć wyniki wyborów na podstawie próbki (jak exit poll), prawdopodobnie zapytasz ludzi w lokalu wyborczym, jak głosowali.
Z drugiej strony, jeśli chcesz stworzyć tę samą ankietę przed wyborami, prawdopodobnie wybierzesz próbkę i skontaktujesz się z osobami telefonicznie lub osobiście. Zwykle jest tylko kilka pytań dotyczących tego typu ankiety – niektóre dotyczą danych demograficznych, a inne tego, co naprawdę nas interesuje.
Sondaże mogą być też znacznie bardziej złożone, m.in. jeśli chcesz poznać opinię publiczną na temat określonego produktu, obejmując wszystko, od jego działania po opakowanie.
W tym artykule nie będę omawiał, jak wybrać przykładowy zestaw osób; skupię się raczej na samej ankiecie, jej pytaniach i odpowiedziach.
Model danych
Model danych agencji opinii publicznej
Model składa się z trzech obszarów tematycznych:
PollsQuestions & AnswersResult
Opiszemy każdy obszar tematyczny w kolejności, w jakiej jest wymieniony.
Sondaże
Zanim zaczniemy zadawać pytania, musimy zdefiniować, co nas interesuje. Zdefiniujemy ankiety i kwestionariusze w tej sekcji, a następnie dodamy pytania i odpowiedzi w następnej.
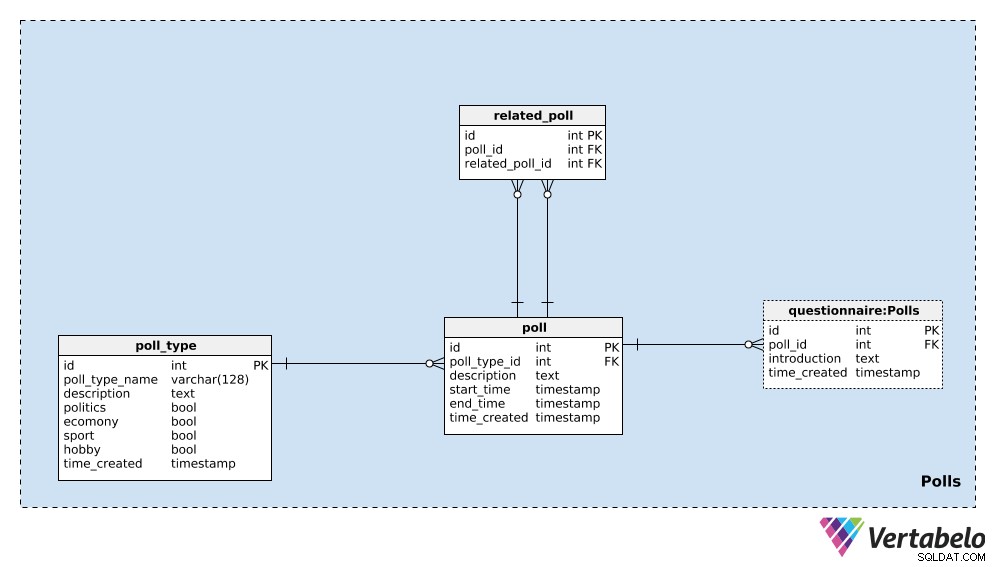
Zaczniemy od poll_type słownik. Możemy się spodziewać, że będziemy w większości powtarzać ankiety tego samego typu. Najpopularniejszym typem są prawdopodobnie sondaże wyborcze, ale chcemy mieć możliwość dodawania nowych typów sondaży po drodze. Dla każdego typu sondy przechowujemy UNIKALNY poll_type_name i użyj description atrybut, aby podać dodatkowe szczegóły.
Cztery flagi – politics , economy , sport i hobby – służą do oznaczenia rodzaju sondy. Sonda może obejmować jeden lub więcej z tych tematów; w razie potrzeby możemy podzielić te kategorie na osobny słownik i mieć relację wiele do wielu między tym słownikiem a poll_type tabela.
Ostatni atrybut w tej tabeli to time_created . Oznacza moment wstawienia wiersza do tej tabeli.
Następną rzeczą, którą musimy zrobić, jest zdefiniowanie pojedynczej poll . To jest pojedynczy przypadek, np. „Wybory prezydenckie w Stanach Zjednoczonych 2020 – sondaż z kwietnia 2020 r.” . Dla każdej ankiety przechowujemy następujące dane:
poll_type_id– Odwołanie dopoll_type.description– Wszystkie szczegóły związane z tą ankietą, w formacie tekstowym.start_timeiend_time– Zdefiniowane godziny rozpoczęcia i zakończenia, w których przeprowadzana jest ankieta.time_created– Faktyczny moment utworzenia tej ankiety.
Sondaże mogą być ze sobą powiązane. Na przykładzie „Wybory prezydenckie w Stanach Zjednoczonych 2020 – sondaż kwiecień 2020” , moglibyśmy przeprowadzić tę samą ankietę w przyszłym miesiącu, aby zobaczyć najbardziej aktualne opinie. Nazwalibyśmy to „Wybory prezydenckie w Stanach Zjednoczonych w 2020 r. – sondaż z maja 2020 r.” . Te dwa sondaże są ze sobą powiązane, ponieważ ich wyniki pokazują trendy. Aby ustalić tę relację, użyjemy related_poll stół w naszym modelu. Zawiera tylko UNIKALNĄ parę poll_id – related_poll_id , oznaczający ankietę i jej poprzednika.
Zauważ, że moglibyśmy użyć tej tabeli do przechowywania wszystkich sond, które są powiązane w jakikolwiek sposób, a nie tylko poprzedników/następców. Gdybyśmy chcieli zdefiniować różne relacje, musielibyśmy dodać kolejny słownik – ale nie będziemy tak postępować w tym artykule.
Ostatnia tabela w tym obszarze tematycznym to questionnaire stół. W większości przypadków każda ankieta będzie zawierała dokładnie jeden kwestionariusz, ale chcę pozostawić opcję, że w razie potrzeby możemy mieć więcej niż jeden. Dlatego skorzystałem z osobnego stołu. W tej tabeli będziemy przechowywać tylko identyfikator powiązanej ankiety (poll_id ), introduction opisujący ten kwestionariusz i sygnaturę czasową wstawienia rekordu (time_created ).
Pytania i odpowiedzi
Teraz jesteśmy gotowi do stworzenia wszystkich szczegółów kwestionariusza. Możemy również wymienić wszystkie pytania, które chcemy zadać, a także wszystkie wstępnie zdefiniowane odpowiedzi.
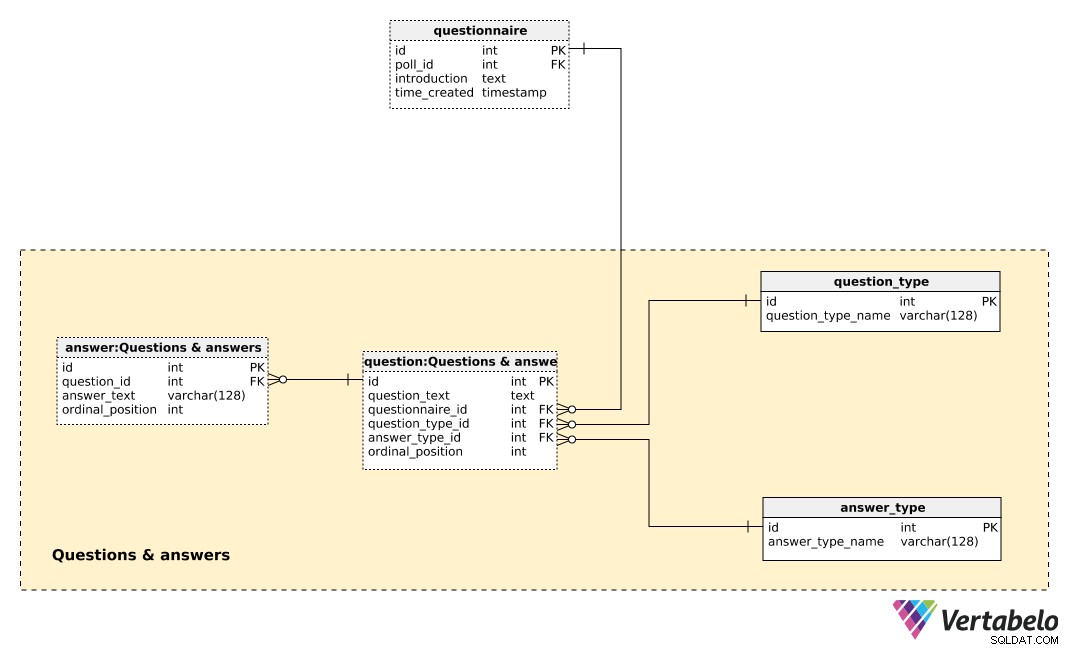
Centralną tabelą w tym obszarze tematycznym jest question stół. Każde pytanie jest określone przez następujące szczegóły:
question_text– Tekst, który będzie wyświetlany każdej osobie badanej.questionnaire_id– Odniesienie oznaczające kwestionariusz tego pytania.question_type_id– Odniesienie oznaczającequestion_type, który jest JEDYNIE oznaczony przezquestion_type_name. Są to w zasadzie kategorie, m.in. „dane demograficzne”, „opinie”, „kontrola” itp. To pozwoliłoby nam oddzielić pytania demograficzne od opinii i znaleźć korelację między nimi.answer_type_id– Odniesienie do rodzaju odpowiedzi, która zostanie użyta na to pytanie. Każdyanswer_typejest JEDYNIE zdefiniowany przezanswer_type_namei oznacza sposób wyświetlania odpowiedzi. Niektóre oczekiwane typy to „otwarty”, „lista”, „pole wyboru” i „wiele”.ordinal_position– Ta wartość oznacza miejsce tego pytania w ankiecie. Wraz zquestionnaire_id, tworzy alternatywny klucz tej tabeli.
Lista wszystkich predefiniowanych odpowiedzi jest przechowywana w answer stół. Jeśli typ pytania nie jest otwarty (tzn. tekst nie zostanie wprowadzony przez osobę), będziemy mieli zestaw predefiniowanych odpowiedzi. Dla każdej odpowiedzi zdefiniujemy pytanie, do którego należy (question_id ), answer_text i ordinal_position tej odpowiedzi w tym pytaniu. Jeszcze raz UNIKALNA para – tym razem question_id – ordinal_position – tworzy alternatywny klucz tej tabeli.
Wynik
W poprzednich dwóch obszarach tematycznych zdefiniowaliśmy wszystko, czego potrzebujemy, aby stworzyć ankietę i zacząć zadawać pytania. Teraz musimy zdefiniować strukturę danych do przechowywania rzeczywistych odpowiedzi.
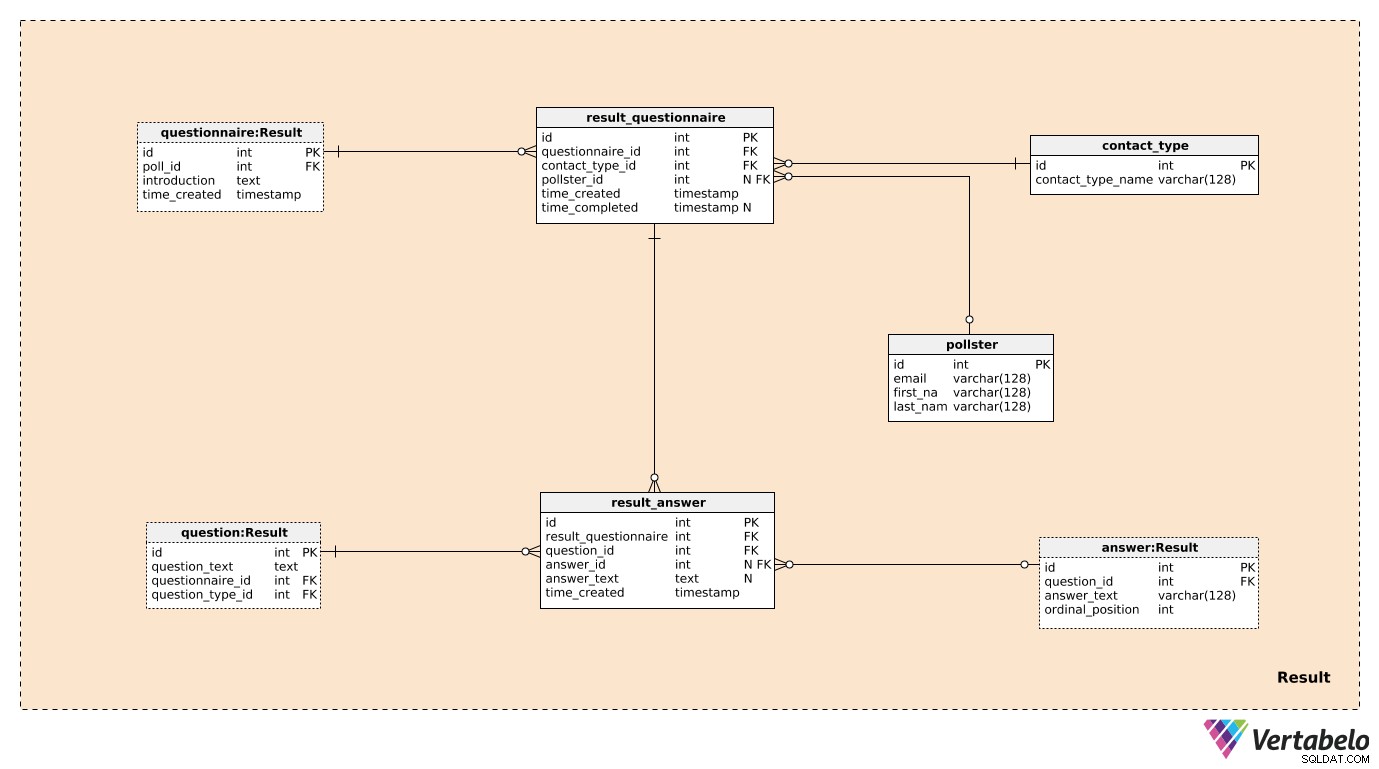
Trzy z siedmiu tabel w Result tematyka została już wcześniej wymieniona i opisana. To są questionnaire , question i answer . Pozostałe cztery tabele służą do przechowywania tego, co nas naprawdę interesuje.
Utworzymy jeden rekord w result_questionnaire tabela dla każdej osoby biorącej udział w ankiecie. questionnaire_id przekaż esusowi wszystkie informacje o odpowiedniej ankiecie. contact_type_id jest odniesieniem do contact_type słownik. Wartości w tej tabeli opisują sposób, w jaki wchodziliśmy w interakcję z tą osobą. Te wartości są JEDYNIE zdefiniowane przez contact_type_name wartość i może być czymś w rodzaju „telefon”, „osobiście”, „e-mail”, „formularz internetowy” itp.
pollster_id atrybut jest odniesieniem do poll tabela, która zawiera informacje o tym, kto przeprowadził tę ankietę. Dla każdego poll , będziemy przechowywać tylko ich UNIKALNE adresy e-mail i ich first_name i last_name . time_created atrybut oznacza rzeczywisty czas utworzenia tego rekordu, podczas gdy time_completed zostanie ustawiony w momencie zakończenia ankiety. (Do tego czasu będzie to NULL).
Ostatnia tabela w modelu to result_answer stół. Jak sama nazwa wskazuje, w tym miejscu będziemy przechowywać rzeczywiste odpowiedzi, które otrzymaliśmy od ankietowanych. Dla każdego rekordu w tej tabeli będziemy mieć:
result_questionnaire_id– Odniesienie do odpowiedniego kwestionariusza.question_id– Odniesienie wskazujące na pytanie, na które udzielono odpowiedzi w tej odpowiedzi.answer_id– Odniesienie do odpowiedzi, która została wykorzystana do udzielenia odpowiedzi na to pytanie. Ten atrybut będzie zawierał wartość NULL, gdy pytanie jest typu „otwartego” (ponieważ nie było wstępnie zdefiniowanych odpowiedzi do wyboru).answer_text– Tekst, który został wstawiony, aby odpowiedzieć na to pytanie. Ten atrybut będzie zawierał wartość, gdy pytanie było „otwarte”; we wszystkich innych przypadkach będzie to NULL.time_created– Rzeczywisty czas, w którym ta odpowiedź została wstawiona do naszego systemu.
Możliwe ulepszenia
Do tej pory omówiliśmy, w jaki sposób możemy przechowywać dane ankietowe. Nie dyskutowaliśmy, co zrobimy z danymi po zamknięciu ankiety. Możemy się spodziewać, że w przyszłości stare dane nie będą nam potrzebne, przynajmniej w naszej operacyjnej bazie danych. Dlatego możemy zrobić dwie rzeczy:
- Przechowuj podsumowanie ankiety w osobnej tabeli w operacyjnej bazie danych. Dzięki temu takie informacje byłyby do naszej dyspozycji, gdybyśmy chcieli zobaczyć, co się stało z podobną ankietą.
- Przechowuj wszystkie dane ankiety w zapasowej bazie danych, która ma taką samą strukturę jak operacyjna baza danych. To pozwoliłoby nam uzyskać dostęp do szczegółów, gdy ich potrzebowaliśmy.
Moglibyśmy również stworzyć hurtownię danych do przechowywania wyników ankiety, ale nie byłoby to konieczne, gdybyśmy wykonali już zadania opisane w dwóch punktach.
Co sądzisz o naszym modelu danych ankiety?
Chcielibyśmy poznać Twoją opinię na temat tego, co możemy zmienić, aby ulepszyć model danych sondaży opinii. Masz doświadczenie w branży? Myślisz, że coś przeoczyliśmy? Czy chcesz coś dodać lub usunąć? Czekamy na Wasze opinie.