Kamery, drzwi obrotowe, windy, czujniki temperatury, alarmy – wszystkie te urządzenia wytwarzają dużą liczbę połączonych ze sobą sygnałów, które są związane z wydarzeniami dziejącymi się wokół nas. Teraz wyobraź sobie, że jesteś osobą, która musi śledzić statusy, tworzyć raporty w czasie rzeczywistym i dokonywać prognoz na podstawie wszystkich tych danych sygnałowych. Aby to zrobić, musisz najpierw przechowywać te dane. Model danych obsługujący takie przetwarzanie sygnałów jest tematem dzisiejszego artykułu.
Najprostszym sposobem przechowywania przychodzących sygnałów byłoby po prostu zapisanie ich tekstowej reprezentacji na jednej ogromnej liście. Takie podejście pozwoliłoby nam na szybkie wykonanie wstawek, ale aktualizacje byłyby problematyczne. Ponadto taki model nie zostałby znormalizowany i dlatego nie pójdziemy w tym kierunku.
Stworzymy znormalizowany model danych, który można wykorzystać do przechowywania danych generowanych przez różne urządzenia, a także określimy, w jaki sposób urządzenia są powiązane. Taki model sprawnie przechowywałby wszystko, czego potrzebujemy, a także mógłby służyć do analiz i analityki predykcyjnej.
Model danych
Model przetwarzania sygnału
Model składa się z trzech obszarów tematycznych:
ComplexesInstallations & DevicesSignals & Events
Opiszemy każdy z tych obszarów tematycznych w kolejności, w jakiej jest wymieniony.
Kompleksy
Tworząc ten model danych wyszedłem z założenia, że wykorzystamy go do śledzenia tego, co dzieje się w większych kompleksach. Kompleksy różnią się wielkością, od pojedynczego pokoju po centrum handlowe. Ważne jest, aby każdy kompleks miał co najmniej jedno urządzenie/czujnik, ale prawdopodobnie będzie miał ich znacznie więcej.
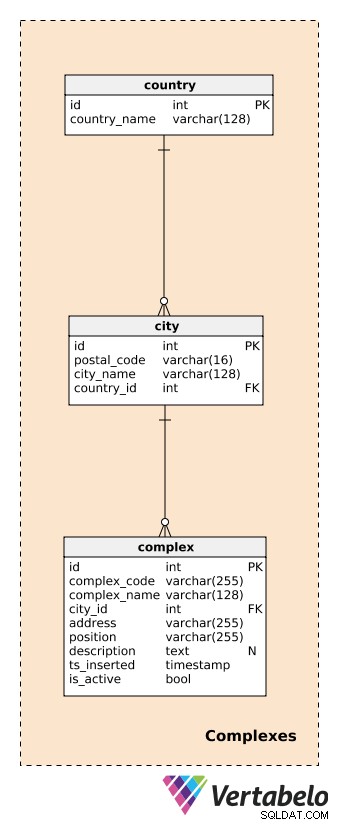
Przed opisaniem kompleksów musimy zdefiniować tabele obsługujące kraje i miasta. Zapewnią one dość szczegółowy opis lokalizacji każdego kompleksu.
Dla każdego country , będziemy przechowywać jego UNIKALNĄ country_name; dla każdego city , będziemy przechowywać UNIKALNĄ kombinację postal_code , city_name i country_id . Nie będę tu wchodzić w szczegóły i założymy, że każde miasto ma tylko jeden kod pocztowy. W rzeczywistości większość miast będzie miała więcej niż jeden kod pocztowy; w takim przypadku możemy użyć głównego kodu dla każdego miasta.
complex to rzeczywisty budynek lub lokalizacja, w której zainstalowane są urządzenia do generowania danych. Jak wspomniano wcześniej, kompleksy mogą się różnić od pojedynczego pomieszczenia czy stacji pomiarowej po znacznie większe miejsca, takie jak parkingi, galerie handlowe, kina itp. Są one przedmiotem naszej analizy. Chcemy móc w czasie rzeczywistym śledzić, co się dzieje na złożonym poziomie, a później tworzyć raporty i analizy. Dla każdego kompleksu zdefiniujemy:
complex_code– UNIKALNY identyfikator dla każdego kompleksu. Chociaż mamy osobny atrybut klucza głównego (id) dla tej tabeli możemy oczekiwać, że odziedziczymy inny kod identyfikacyjny dla każdego kompleksu z innego systemu.complex_name– Nazwa używana do opisania tego kompleksu. W przypadku galerii handlowych i kin może to być ich rzeczywista i znana nazwa; dla stacji pomiarowej moglibyśmy użyć ogólnej nazwy.city_id– Nawiązanie do miasta, w którym znajduje się kompleks.address– Fizyczny adres tego kompleksu.position– Położenie kompleksu (tj. współrzędne geograficzne) określone w formacie tekstowym.description– Tekstowy opis, który dokładniej opisuje ten kompleks.ts_inserted– Znacznik czasu wstawienia tego rekordu.is_active– Wartość logiczna oznaczająca, czy ten kompleks jest nadal aktywny, czy nie.
Instalacje i urządzenia
Teraz zbliżamy się do serca naszego modelu. W każdym kompleksie prawdopodobnie będziemy mieć zainstalowanych kilka urządzeń. Niemal na pewno też pogrupujemy te urządzenia ze względu na ich przeznaczenie – np. moglibyśmy umieścić kamery, czujniki drzwi i silnik używany do otwierania i zamykania drzwi w grupie, ponieważ współpracują ze sobą.
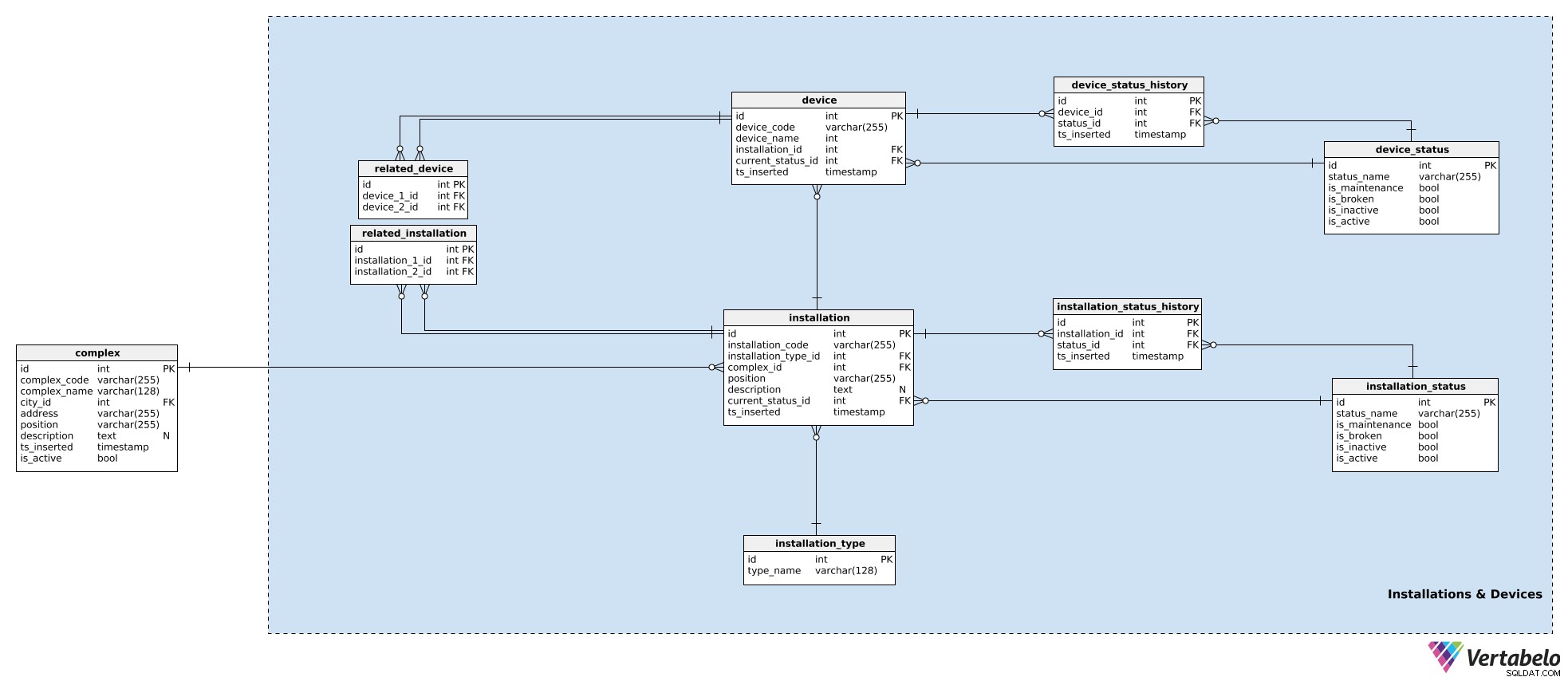
W naszym modelu urządzenia współpracujące w jednym kompleksie pogrupowane są w instalacje. Mogą to być drzwi wejściowe, schody ruchome, czujniki temperatury itp. W przypadku każdej instalacji będziemy przechowywać następujące szczegóły w installation tabela:
installation_code– UNIKALNY kod używany do oznaczenia tej instalacji.installation type_id– Odniesienie doinstallation_typesłownik. Ten słownik przechowuje tylko UNIKALNYtype_nameatrybut opisujący typ, np. schody ruchome, winda.complex_id– Odniesienie docomplexdo której należy instalacja.position– Współrzędne w formacie tekstowym tej instalacji wewnątrz kompleksu.description– Tekstowy opis tej instalacji.current_status_id– Odniesienie do aktualnego stanu (zinstallation_statustabeli) tej instalacji.ts_inserted– Znacznik czasu, kiedy ten rekord został wstawiony do naszego systemu.
Wspomnieliśmy już o statusach instalacji. Lista wszystkich możliwych stanów jest przechowywana w installation_status słownik. Każdy status jest JEDYNIE zdefiniowany przez jego status_name . Poza tym będziemy przechowywać flagi wskazujące, czy ten stan, gdy zostanie użyty, sugeruje, że instalacja is_broken , is_inactive , is_maintenance lub is_active . Tylko jedna z tych flag powinna być ustawiona na raz.
Przypisaliśmy już aktualny status instalacji. Jeśli mamy śledzić, co dzieje się z urządzeniem, musimy również przechowywać jego historię. Aby to zrobić, użyjemy jeszcze jednej tabeli, installation_status_history . Dla każdego rekordu w tym miejscu będziemy przechowywać odniesienia do powiązanej instalacji i statusu, a także momentu (ts_inserted ) kiedy ten status został nadany.
Instalacje są częścią naszych kompleksów. Chociaż każda instalacja jest pojedynczym podmiotem, nadal może być powiązana z innymi instalacjami. (Np. system wideo przy wejściu do centrum handlowego jest oczywiście powiązany z drzwiami wejściowymi do centrum handlowego – najpierw kamera zobaczy ludzi, a potem drzwi się otworzą.) Jeśli chcemy śledzić te relacje, przechowamy je w related_installation stół. Proszę zauważyć, że ta tabela zawiera tylko UNIKALNE pary dwóch kluczy, oba odnoszą się do installation stół.
Ta sama logika jest używana do przechowywania urządzeń. Urządzenia to pojedyncze elementy sprzętowe, które wytwarzają interesujące nas sygnały. Podczas gdy instalacje należą do kompleksów, urządzenia należą do instalacji. Dla każdego device , będziemy przechowywać:
device_code– UNIKALNY sposób oznaczania każdego urządzenia.device_name– Nazwa tego urządzenia.installation_id– Odniesienie do instalacji, do której należy to urządzenie.current_status_id– Aktualny stan urządzenia.ts_inserted– Znacznik czasu wstawienia tego rekordu.
Statusy są obsługiwane w ten sam sposób. Użyjemy device_status tabela do przechowywania listy wszystkich możliwych stanów urządzenia. Ta tabela ma taką samą strukturę jak installation_status a atrybuty są używane w ten sam sposób. Powodem posiadania dwóch oddzielnych słowników statusu jest to, że urządzenia i ich instalacje mogą mieć różne statusy – przynajmniej z nazwy.
Aktualny stan jest przechowywany w device.current_status_id atrybut, a historia statusu jest przechowywana w device_status_history stół. Dla każdego rekordu tutaj będziemy przechowywać relacje z urządzeniem i stanem, a także moment, w którym ten rekord został wstawiony.
Ostatnia tabela w tym obszarze tematycznym to related_device stół. Chociaż jest dość oczywiste, że wszystkie urządzenia w tej samej instalacji są ściśle powiązane, chcę mieć możliwość powiązania dowolnych dwóch urządzeń należących do dowolnej instalacji. Zrobimy to, przechowując ich dwa identyfikatory urządzeń w tej tabeli.
Sygnały i zdarzenia
Teraz jesteśmy gotowi na serce całego modelu.
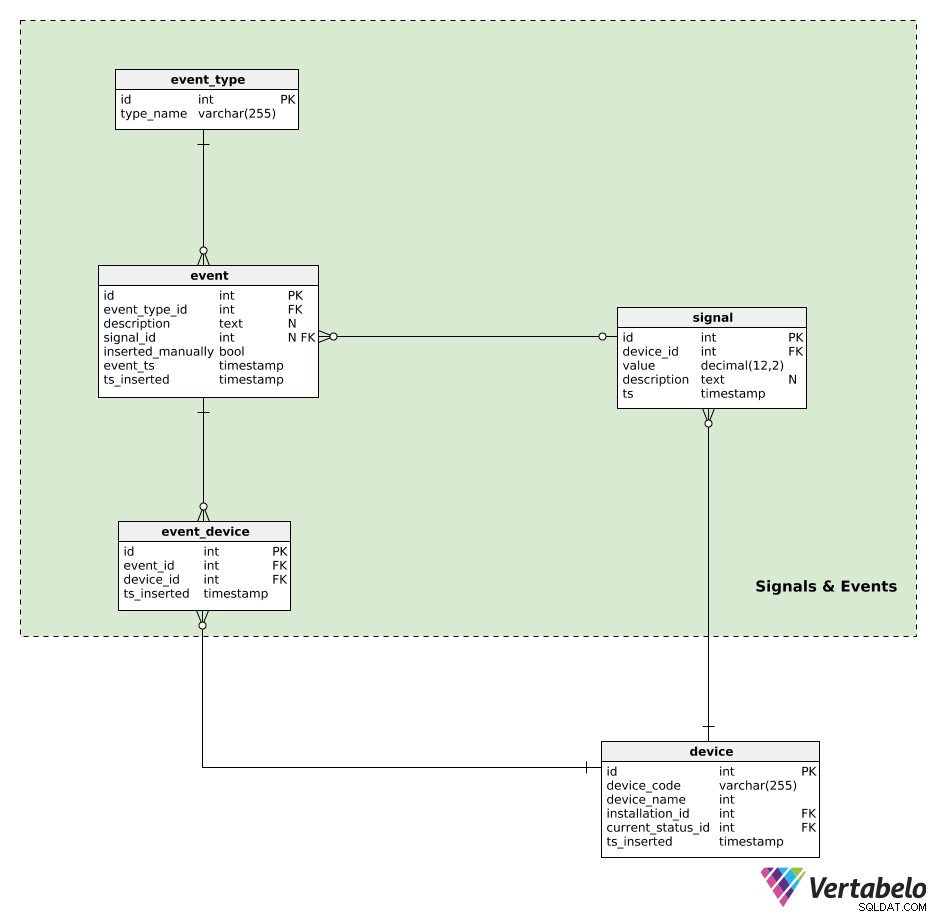
Urządzenia generują sygnały. Wszystkie dane sygnału są przechowywane w signal stół. Dla każdego sygnału zapiszemy:
device_id– Odniesienie do urządzenia, które wygenerowało ten sygnał.value– Wartość liczbowa tego sygnału.description– Wartość tekstowa, która może zawierać dodatkowe parametry (np. typ sygnału, wartości, używana jednostka miary) związane z tym pojedynczym sygnałem. Te dane są przechowywane w formacie podobnym do JSON.ts– Znacznik czasu, kiedy ten sygnał został wstawiony do tabeli.
Możemy się spodziewać, że stół ten będzie bardzo intensywnie użytkowany, z dużą liczbą wstawek wykonywanych na sekundę. Dlatego konserwacja bazy danych powinna skupiać się na śledzeniu rozmiaru tej tabeli.
Ostatnią rzeczą, jaką chcę zrobić, to dodać zdarzenia do naszego modelu danych. Zdarzenia mogą być generowane automatycznie przez sygnał lub wprowadzane ręcznie. Jednym automatycznie wygenerowanym zdarzeniem może być „drzwi otwarte przez 5 minut”, podczas gdy zdarzeniem wstawionym ręcznie może być „urządzenie musiało zostać wyłączone z powodu tego sygnału”. Cała idea polega na przechowywaniu działań, które nastąpiły w wyniku zachowania urządzenia. Później moglibyśmy wykorzystać te zdarzenia podczas przeprowadzania analizy zachowania urządzenia.
Zdarzenia będą granulowane według event_type . Każdy typ jest JEDYNIE zdefiniowany przez jego type_name .
Wszystkie automatycznie generowane lub ręcznie wstawiane zdarzenia są rejestrowane w event stół. Dla każdego rekordu tutaj zapiszemy:
event_type_id– Odniesienie do powiązanego typu zdarzenia.description– Tekstowy opis tego wydarzenia.signal_id– Odniesienie do sygnału, jeśli taki istnieje, który spowodował zdarzenie.inserted_manually– Flaga wskazująca, czy ten rekord został wstawiony ręcznie, czy nie.event_tsits_inserted– Sygnatury czasowe, kiedy to zdarzenie rzeczywiście miało miejsce i kiedy wstawiono jego zapis. Te dwa elementy mogą się różnić, zwłaszcza gdy zapisy zdarzeń są wstawiane ręcznie.
Ostatnia tabela w naszym modelu to event_device stół. Ta tabela służy do powiązania zdarzeń ze wszystkimi zaangażowanymi urządzeniami. Dla każdego rekordu będziemy przechowywać UNIKALNĄ parę event_id – device_id i sygnaturę czasową wstawienia rekordu.
Co sądzisz o naszym modelu danych przetwarzania sygnałów?
Dzisiaj przeanalizowaliśmy uproszczony model danych, którego moglibyśmy użyć do śledzenia sygnałów z zestawu urządzeń zainstalowanych w różnych lokalizacjach. Sam model powinien wystarczyć do przechowywania wszystkiego, czego potrzebujemy do śledzenia statusów i wykonywania analiz. Mimo to możliwe jest wiele ulepszeń. Co moglibyśmy dodać? Powiedz nam w komentarzach poniżej.