Chcesz dowiedzieć się, jak zaprojektować system bazodanowy i odwzorować proces biznesowy na model danych? W takim razie ten post jest dla Ciebie.
W tym artykule dowiesz się, jak zaprojektować prosty schemat bazy danych dla firmy rekrutacyjnej. Po przeczytaniu tego samouczka będziesz w stanie zrozumieć, w jaki sposób schematy baz danych są projektowane dla aplikacji w świecie rzeczywistym.
Proces biznesowy systemu rekrutacji
Przed zaprojektowaniem jakiejkolwiek bazy danych lub modelu danych konieczne jest zrozumienie podstawowego procesu biznesowego dla tego systemu. Schemat bazy danych, który stworzymy, jest przeznaczony dla wyimaginowanej firmy lub zespołu rekrutacyjnego. Zobaczmy najpierw kroki związane z zatrudnianiem nowych pracowników:
- Firmy kontaktują się z agencjami rekrutacyjnymi, aby zatrudniać w ich imieniu. W niektórych przypadkach firmy bezpośrednio rekrutują pracowników.
- Osoba odpowiedzialna za rekrutację rozpoczyna proces rekrutacji. Proces ten może składać się z wielu etapów, takich jak wstępna selekcja, test pisemny, pierwsza rozmowa kwalifikacyjna, rozmowa uzupełniająca, faktyczna decyzja o zatrudnieniu itp.
- Gdy rekruterzy uzgodnią konkretny proces – a to może się zmienić w zależności od klienta, firmy lub danej pracy – wakat jest ogłaszany na różnych platformach.
- Kandydaci zaczynają aplikować o pracę.
- Kandydaci są wybierani i zapraszani na test lub wstępną rozmowę kwalifikacyjną.
- Kandydaci pojawiają się na test/rozmowę.
- Testy są oceniane przez osoby rekrutujące. W niektórych przypadkach testy są przekazywane specjalistom do oceny.
- Rozmowy kwalifikacyjne z kandydatami są oceniane przez jednego lub więcej rekruterów.
- Kandydaci są oceniani na podstawie testów i rozmów kwalifikacyjnych.
- Podjęto decyzję o zatrudnieniu.
Schemat bazy danych systemu rekrutacyjnego
W związku z powyższym procesem, nasz schemat bazy danych jest podzielony na pięć obszarów tematycznych:
ProcessJobsApplication, Applicant, and DocumentsTest and InterviewsRecruiters and Application Evaluation
Omówimy szczegółowo każdy z tych obszarów, w kolejności, w jakiej są wymienione. Poniżej możesz zobaczyć cały model danych.
Proces
Kategoria procesu zawiera informacje związane z procesami rekrutacyjnymi. Zawiera trzy tabele:process , step i process_step . Przyjrzymy się każdemu z nich.
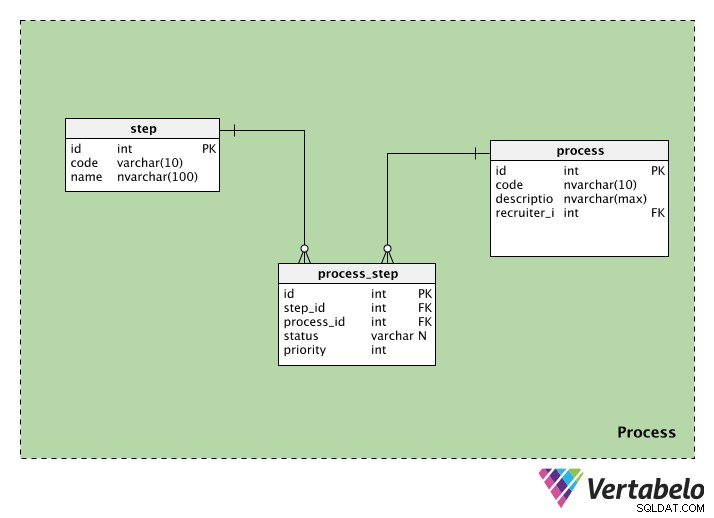
process tabela przechowuje informacje o każdym procesie rekrutacyjnym. Każdy proces będzie miał specjalny identyfikator, kod i description tego procesu. Będziemy mieć również recruiter_id osoby, która inicjuje proces.
step tabela zawiera informacje o krokach podjętych w trakcie tego procesu rekrutacji. Każdy krok ma id i code nazwać. Kolumna z nazwą może zawierać wartości takie jak „wstępna kontrola”, „test pisemny”, „wywiad HR” itp.
Ponieważ jeden proces może mieć wiele kroków, a jeden krok może być częścią wielu procesów, potrzebujemy tabeli przeglądowej. process_step tabela zawiera informacje o każdym kroku (w step_id ) i proces, do którego należy (w process_id ). Mamy również status, który mówi nam o statusie tego kroku w tym procesie; może to być NULL, jeśli krok nie został jeszcze uruchomiony. Wreszcie mamy priority , który mówi nam, w jakiej kolejności wykonać kroki. Kroki o najwyższym priority wartość zostanie wykonana jako pierwsza.
Praca
Dalej mamy Jobs obszar tematyczny, w którym przechowywane są wszystkie informacje związane ze stanowiskiem, na które rekrutujemy. Schemat dla tej kategorii wygląda tak:
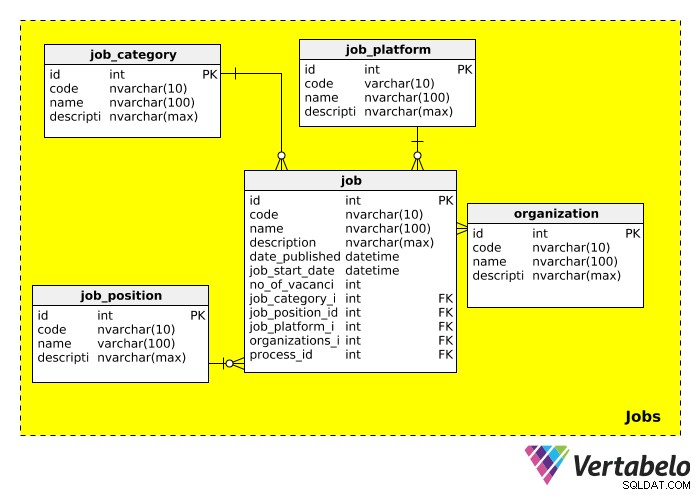
Wyjaśnijmy szczegółowo każdą z tabel.
job_category tabela ogólnie opisuje rodzaj pracy. Możemy spodziewać się takich kategorii stanowisk, jak „IT”, „zarządzanie”, „finanse”, „edukacja” itp.
job_position tabela zawiera faktyczną nazwę stanowiska. Ponieważ jeden tytuł może być reklamowany na wiele stanowisk (np. „Kierownik IT”, „Kierownik sprzedaży”), stworzyliśmy osobną tabelę dla stanowisk. Moglibyśmy spodziewać się w tej tabeli wartości takich jak „Kierownik zespołu IT”, „Wiceprezes” i „Menedżer”.
job_platform tabela odnosi się do medium używanego do ogłoszenia oferty pracy. Na przykład praca może być opublikowana na Facebooku, internetowej tablicy ogłoszeń lub w lokalnej gazecie. Link do tej oferty pracy można dodać w description pole.
organization tabela przechowuje informacje o wszystkich firmach, które kiedykolwiek korzystały z tej bazy danych w ramach procesu zatrudniania. Oczywiście ta tabela jest ważna, gdy rekrutacja prowadzona jest dla innej firmy.
Ostatnia tabela w tym obszarze tematycznym, job , zawiera rzeczywisty opis stanowiska. Większość atrybutów nie wymaga wyjaśnień. Należy zauważyć, że tabela ta ma wiele kluczy obcych, co oznacza, że można jej użyć do wyszukania kategorii, stanowiska, platformy, organizacji zatrudniającej oraz procesu rekrutacji związanego z danym stanowiskiem.
Wniosek, wnioskodawca i dokumenty
Trzecia część schematu składa się z tabel, które przechowują informacje o kandydatach do pracy, ich aplikacjach i wszelkich dokumentach dołączonych do aplikacji.
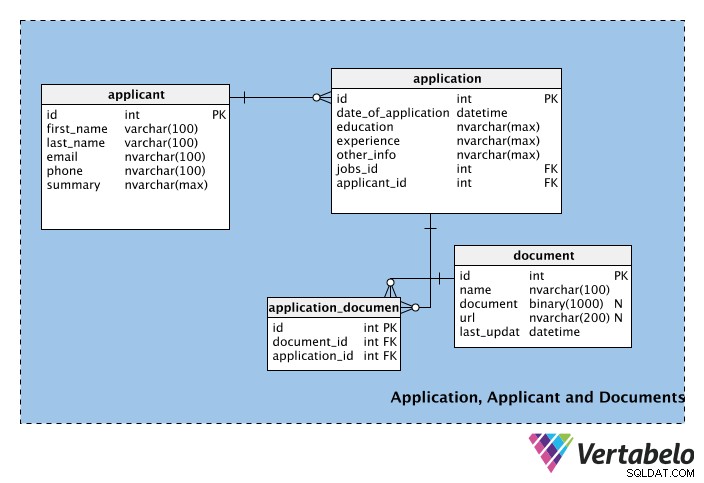
Pierwsza tabela, applicant , przechowuje dane osobowe kandydatów, takie jak imię, nazwisko, adres e-mail, numer telefonu itp. Pole podsumowania może służyć do przechowywania krótkiego profilu kandydata (tj. akapitu).
Następna tabela zawiera informacje dla każdej application , łącznie z datą. Tabela zawiera również experience i education kolumny. Te kolumny mogą być częścią applicant tabeli, ale wnioskodawca może, ale nie musi, chcieć przedstawiać określone kwalifikacje edukacyjne lub doświadczenie zawodowe w każdym składanym wniosku. Dlatego te kolumny są częścią application stół. other_info kolumna przechowuje wszelkie inne informacje związane z aplikacją. W application W tabeli jobs_id i application_id są kluczami obcymi odpowiednio z tabel job i application .
Ponieważ może być wiele aplikacji dla każdej pracy, ale każda aplikacja dotyczy tylko jednej pracy, będzie istnieć relacja jeden-do-wielu między jobs i applications tabele. Podobnie jeden kandydat może złożyć wiele wniosków (tj. na różne stanowiska), ale każdy wniosek pochodzi tylko od jednego uczestnika; wdrożyliśmy kolejną relację jeden-do-wielu między applicants i applications tabele do obsługi tego.
document tabela zarządza dokumentami uzupełniającymi, które wnioskodawcy mogą dołączyć do swojego wniosku. Mogą to być życiorysy, życiorysy, listy referencyjne, listy motywacyjne itp. Zauważ, że ta tabela zawiera kolumnę binarną o nazwie document, w której plik będzie przechowywany w formacie binarnym. Link do dokumentu może być przechowywany w url pole; kolumna name przechowuje nazwę dokumentu, a last_update oznacza najnowszą wersję przesłaną przez wnioskodawcę. Zwróć uwagę, że oba document i url są null; żadna z nich nie jest obowiązkowa, a wnioskodawca może wybrać jedną lub obie metody w celu dodania informacji do swojego wniosku.
Nie do każdego wniosku będzie dołączony dokument. Jeden dokument może być dołączony do wielu wniosków, a jeden wniosek może zawierać wiele dokumentów uzupełniających. Oznacza to, że istnieje relacja wiele do wielu między application i document tabele. Aby zarządzać tą relacją, tabela wyszukiwania application_document został utworzony.
Testy i wywiady
Teraz przejdziemy do tabel, w których przechowywane są informacje o testach i rozmowach kwalifikacyjnych związanych z procesem rekrutacji.
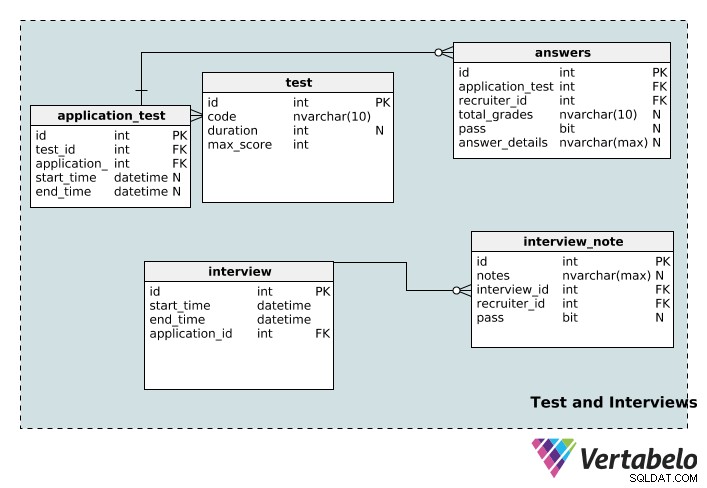
test tabela przechowuje szczegóły testu, w tym jego unikalny id , code nazwa, jego duration w minutach, a maximum wynik możliwy dla tego testu.
Jedna aplikacja może być powiązana z wieloma testami, a jeden test z wieloma aplikacjami. Po raz kolejny mamy tabelę przeglądową do zaimplementowania tej relacji:application_test . start_time i end_time kolumny mogą mieć wartość null, ponieważ test może nie mieć określonego czasu trwania, czasu rozpoczęcia ani zakończenia.
Test może być oceniany przez wielu rekruterów, a jeden rekruter może oceniać wiele testów. answers stół to stół, który to umożliwia. total_grades kolumna rejestruje, jak dobrze kandydat zrobił na teście, a kolumna zaliczenia po prostu wskazuje, czy ta osoba zdała, czy nie. Specyfika każdego testu jest rejestrowana w answer_details kolumna. Zauważ, że te trzy kolumny mogą mieć wartość null; test aplikacyjny może zostać przypisany do rekrutera, który jeszcze go nie ocenił. Co więcej, rekruterowi można przypisać test przed jego faktycznym przystąpieniem.
interview tabela przechowuje podstawowe informacje (start_time , end_time , unikalny id i odpowiedni application_id ) dla każdego wywiadu. Jedna rozmowa kwalifikacyjna może być powiązana tylko z jedną aplikacją. Z drugiej strony jedna aplikacja może mieć kilka rozmów kwalifikacyjnych. W związku z tym istnieje relacja jeden-do-wielu między aplikacją a tabelą wywiadów.
Jedna rozmowa kwalifikacyjna może być przeprowadzona przez wielu recenzentów, a jeden recenzent może odbyć kilka rozmów kwalifikacyjnych. To kolejna relacja wiele do wielu, dlatego stworzyliśmy tabelę przeglądową interview_note . Przechowuje informacje o rozmowie kwalifikacyjnej (w interview_id ), rekruter (w recruiter_id ) oraz notatki rekrutera dotyczące rozmowy kwalifikacyjnej. Rekruterzy mogą również odnotować, czy kandydat zdał rozmowę kwalifikacyjną w kolumnie z przepustką, co nie pozwala na unieważnienie.
Ocena i status rekrutacji
Ostatnia część naszego modelu rekrutacji przechowuje informacje o rekruterach, statusach aplikacji i ocenach aplikacji.
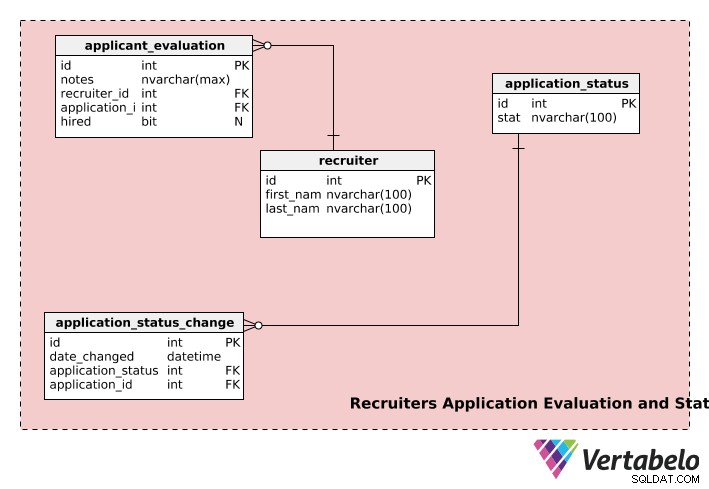
recruiters tabela przechowuje first_name każdego rekrutera , last_name i unikalny id numer.
application_evaluation tabela zawiera informacje o ocenach wniosków. Oprócz application_id i recruiter_id , zawiera opinię rekrutera (w notes ) i ostateczną decyzję o zatrudnieniu, jeśli taka istnieje, w hired . Jedno zgłoszenie może zostać ocenione przez wielu rekruterów, a jeden rekruter może ocenić wiele zgłoszeń, więc zarówno recruiter i application tabela ma związek jeden-do-wielu z application_evaluation stół.
Aplikacja może przechodzić przez wiele etapów w procesie rekrutacji, m.in. „nieprzesłane”, „w trakcie przeglądu”, „oczekiwanie na decyzję”, „podjęta decyzja” itp. Zgłoszenie będzie miało status „nie_przesłane”, gdy użytkownik rozpoczął aplikację, ale nie przesłał jej do weryfikacji przez rekruterów. Po przesłaniu wniosku status zmienia się na „w trakcie sprawdzania” i tak dalej. application_status tabela służy do przechowywania takich informacji.
application_status_change tabela służy do prowadzenia ewidencji zmian statusu dla wszystkich złożonych wniosków. date_changed kolumna przechowuje datę zmiany statusu. Ta tabela może być przydatna, jeśli chcesz przeanalizować czas przetwarzania dla każdego etapu różnych aplikacji. Ponadto status dowolnej konkretnej kolumny można pobrać za pomocą application_id kolumna z application_status_change stół.
Prosty przypadek użycia rekrutacji
Zobaczmy, jak nasza baza danych może wspomóc proces rekrutacji.
Załóżmy, że firma zleciła Ci zatrudnienie menedżera IT z doświadczeniem w programowaniu. Nasza baza danych może nam pomóc zatrudnić taką osobę, wykonując następujące kroki:
- Pierwszym krokiem jest rozpoczęcie nowego procesu rekrutacji. W tym celu dane są wprowadzane do
processistepstabele. Rekruter może dodać tyle kroków, ile potrzebuje. - Podczas powyższego zadania rekruter może utworzyć nową pracę i wprowadzić szczegóły w
job,job_category,job_positioniorganizationtabele. Wreszcie ogłoszenie o pracę zostanie umieszczone na jednej z platform przechowywanych najob_platformstół. - Następnie kandydaci utworzą profil, przesyłając swoje dane do
applicantstół. Następnie uruchomi nową aplikację, wprowadzając więcej danych doapplicationstół. - Wnioskodawcy mogą również dołączyć dokumenty do swoich wniosków. Te dane będą przechowywane w
documentiapplication_documentstoły. - Jeśli użytkownik chce aplikować do więcej niż jednej pracy, powtórzy kroki 3 i 4.
- Po przesłaniu aplikacji status aplikacji zostanie ustawiony na „przesłane” (lub inną nazwę statusu wybraną przez osobę rekrutującą).
- Rekruter oceni aplikację i wprowadzi swoją opinię w
application_evaluationstół. Na tym etapie wynajęta kolumna nie będzie zawierać żadnych informacji. - Po otrzymaniu odpowiedniej liczby aplikacji rekruter wykona kolejny krok pokazany w
process_stepstół. - Jeśli następnym krokiem jest przeprowadzenie jakiegoś testu, osoba rekrutująca utworzy test, dodając dane do
teststół. - Test(y) utworzone w kroku 9 zostaną przypisane do określonej aplikacji. Informacje, które przypisują każdy test do każdej aplikacji, będą przechowywane w
application_teststół. Pamiętaj, że na każdym etapie status aplikacji będzie się zmieniał. Zostanie to zapisane wapplication_status_changestół. - Gdy kandydat ukończy test, oceny z każdego testu aplikacyjnego zostaną ocenione przez osobę rekrutującą i wpisane do
answersstół. - Po wykonaniu testu, kolejny krok z
process_steptabela zostanie wykonana. Powiedzmy, że następnym krokiem jest rozmowa kwalifikacyjna. - Dane rozmowy kwalifikacyjnej zostaną wprowadzone w
interviewstół. Rekruter wprowadzi swoje komentarze i powie, czy osoba zdała rozmowę kwalifikacyjną, czy nie. Będzie on przechowywany winterview_notestół. - Jeśli
processtabela zawiera dalsze kroki wywiadu i testu, będą one wykonywane aż do osiągnięcia ostatniego kroku. - Ostatni krok w
process_stepstół jest zwykle decyzją o zatrudnieniu. Jeśli kandydat przejdzie testy i rozmowy kwalifikacyjne, a firma zdecyduje się go zatrudnić, dane są wprowadzane w kolumnie zatrudnieniaapplication_evaluationstolik i osoba jest zatrudniona.
Co myślisz o naszym modelu danych systemu rekrutacji?
W tym artykule zobaczyliśmy, jak stworzyć bardzo prosty schemat bazy danych dla systemu rekrutacyjnego. Schemat podzieliliśmy na cztery kategorie, a następnie szczegółowo wyjaśniliśmy każdą z nich. Na koniec przeprowadziliśmy przypadek użycia, aby pokazać, że nasz schemat może rzeczywiście pomóc w rekrutacji pracownika.
Prace związane z projektowaniem baz danych rozwijają się dynamicznie. Chcesz poszerzyć swoje umiejętności związane z bazą danych? Niezależnie od tego, czy jesteś nowicjuszem, który chce nauczyć się podstaw SQL, czy doświadczonym profesjonalistą, który chce rozwinąć skrzydła w Tworzenie tabel w SQL | Kurs interaktywny | Vertabelo Academy" target="_blank">projektowanie baz danych, zapoznaj się z kursami do samodzielnego prowadzenia LearnSQL.com.