Jaki model danych umożliwiłby wygodne wyszukiwanie książek i wypożyczanie ich w lokalnej bibliotece?
Czy kiedykolwiek poszedłeś do biblioteki i pożyczyłeś książkę? Może wydaje się to staromodne w dzisiejszym świecie natychmiastowej wiedzy internetowej i e-booków. Ale jestem pewien, że wciąż jest w tobie ta analogowa część, która nadal lubi wąchać, dotykać i czytać książki. A może zostałeś zmuszony do skorzystania z biblioteki, gdy nie mogłeś znaleźć czegoś w Internecie! Tak, nie wszystko jest online.
Jak więc model danych mógłby organizować książki i wypożyczenia biblioteczne? Zanurzmy się w ten model i zobaczmy, jak to działa!
Model danych
Kiedy tworzyłem ten model danych, miałem na myśli biblioteki publiczne. Zakłada się, że każda biblioteka w sieci bibliotek publicznych korzysta z tego samego modelu/systemu. Jest scentralizowany i umożliwia członkom przeglądanie kolekcji każdej biblioteki w sieci. Ponadto członkowie mogą wypożyczać książki z dowolnej biblioteki w sieci.
Model danych bibliotecznych składa się z trzynastu tabel podzielonych na dwa obszary tematyczne. Te obszary to:
Books & LibrariesMembers & Loans
Omówimy każdy obszar tematyczny osobno i przeanalizujemy wszystkie szczegóły.
Książki i biblioteki
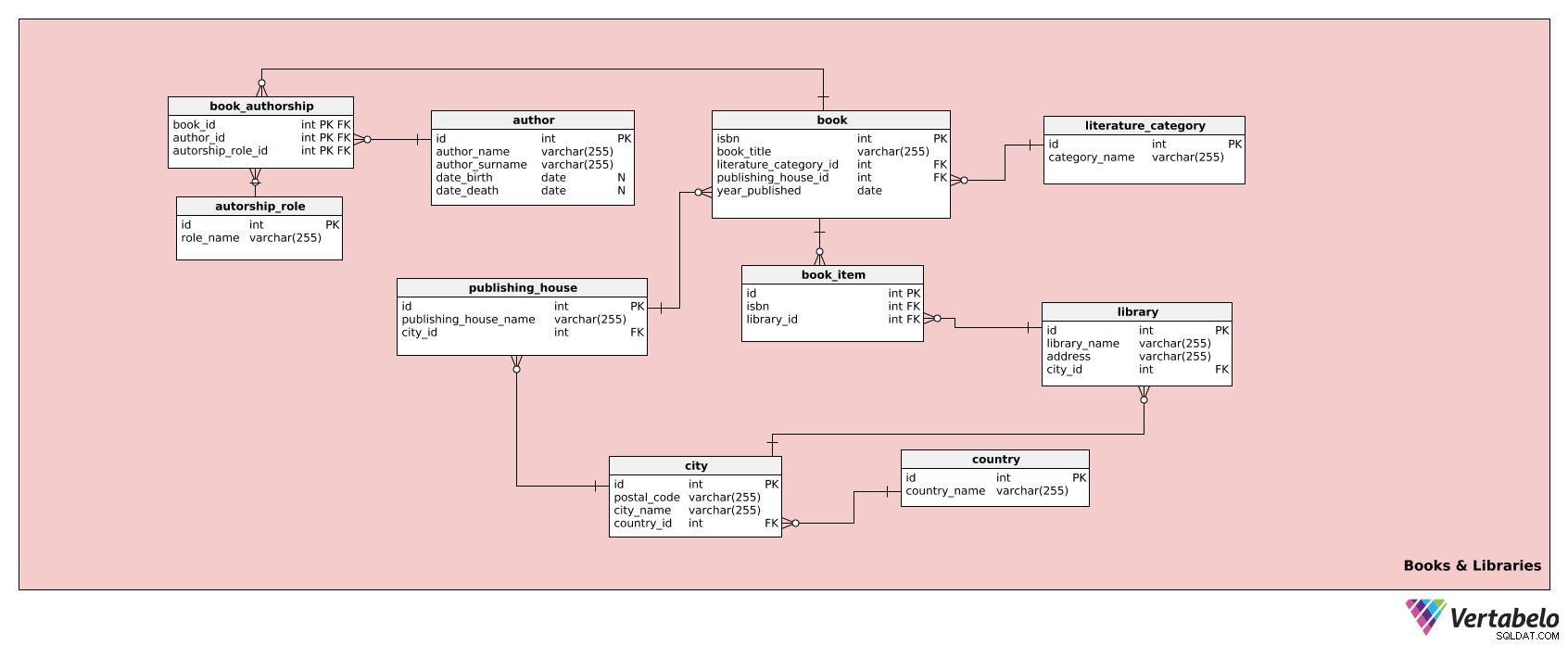
Ten obszar tematyczny przechowuje informacje o książkach i bibliotekach. Składa się z dziesięciu stołów:
authorauthorship_roleliterature_categorybookbook_authorshipbook_itempublishing_houselibrarycitycountry
Pierwsza tabela to author stół. Wymienia wszystkich autorów (wraz z odpowiednimi danymi) książek, które biblioteka posiada w swoich zbiorach. Dla każdego autora będziemy mieć:
id– Unikalny identyfikator tego autora.author_name– Imię autora.author_surname– Nazwisko autora.date_birth– Data urodzenia autora.date_death– Data śmierci autora.
authorship_role tabela zawiera wszystkie role, jakie może pełnić autor, np. autor, współautor itp. Ta tabela ma następujące atrybuty:
id– Unikalny identyfikator dla każdej roli.role_name– nazwa tej roli, m.in. "współautor". To jest alternatywny klucz tabeli.
Tabela literature_category wymienia wszystkie kategorie książek, m.in. thriller, literatura francuska, rosyjski realizm, filozofia itp. Tabela zawiera następujące atrybuty:
id– Unikalny identyfikator dla tej kategorii.category_name– Nazwa kategorii, np. "tajemnica". To jest alternatywny klucz tabeli.
Następnie mamy book stół. Ta tabela przechowuje wszystkie istotne szczegóły każdego tytułu, który biblioteka ma w swojej kolekcji. Należy pamiętać, że nie jest to tabela używana dla każdej książki jako przedmiotu. W tym celu użyjemy innej tabeli, a mianowicie book_item stół. book tabela składa się z atrybutów:
isbn– Unikalny identyfikator dla każdego tytułu książki, którym w branży wydawniczej jest Międzynarodowy Standardowy Numer Książki (ISBN).book_title– Tytuł książki.literature_category_id– Odwołuje się doliterature_categorystół.publishing_house_id– Odwołuje się dopublishing_housestół.year_published– Rok wydania książki.
Kolejna tabela w naszym modelu to book_authorship stół. Jest to tabela przecięcia, która zostanie połączona z book , author i authorship_role tabele. Zawiera następujące atrybuty:
book_id– Odwołuje się dobookstół.author_id– Odwołuje się doauthorstół.authorship_role_id– Odwołuje się doauthorship_rolestół.
Te trzy atrybuty razem tworzą złożony klucz podstawowy tabeli. Złożony klucz podstawowy oznacza, że dowolna kombinacja wszystkich trzech atrybutów musi być unikatowa; każda kombinacja może wystąpić tylko raz.
Teraz spójrzmy na book_item tabela, o której wspomnieliśmy wcześniej jako przechowująca informacje o każdej fizycznej książce w bibliotece. Będzie zawierać następujące informacje:
id– Unikalny identyfikator dla każdej książki jako przedmiotu.isbn– Odwołuje się dobookstół.library_id– Odwołuje się dolibrarystół.
The publishing_house table is the next one in our model. It lists the publishers of all the books that the library has in its collection. The attributes in the table are as follows: stół jest kolejnym w naszym modelu. Wymienia wydawców wszystkich książek, które biblioteka posiada w swoich zbiorach. Atrybuty w tabeli są następujące:
id– Unikalny identyfikator dla każdego wydawnictwa.publishing_house_name– Nazwa wydawnictwa (np. Penguin Books, McGraw-Hill, Simon &Schuster itp.).city_id– Odwołuje się docitystół. To powiązanie pozwoli nam również określić zarówno miasto, jak i kraj wydawnictwa.publishing_house_name–city_idpara jest kluczem alternatywnym tej tabeli.
OK, przejdźmy do library stół. Ta tabela jest wymieniona w book_item tabeli, gdzie określa bibliotekę, w której znajduje się każdy egzemplarz książki. Jest to potrzebne, ponieważ te same tytuły książek można znaleźć w więcej niż jednej bibliotece w sieci (np. każda biblioteka prawdopodobnie ma co najmniej jeden egzemplarz Władcy Pierścieni ). Dlatego musimy wiedzieć, która książka jest w której bibliotece. Aby to osiągnąć, potrzebujemy następujących atrybutów:
id– Unikalny identyfikator biblioteki.library_name– Nazwa tej biblioteki.address– Adres tej biblioteki.city_id– Odwołuje się docitystół.library_name-city_idpara jest kluczem alternatywnym tej tabeli.
Kolejna tabela w tym modelu to city stół. Jest to prosta lista miast, z których będziemy korzystać w celu uzyskania informacji o wydawcach, bibliotekach i członkach bibliotek. Atrybuty to:
id– Unikalny identyfikator miasta.postal_code– Kod pocztowy dla tego miasta.city_name– Nazwa tego miasta.country_id– Odwołuje się docountrystół.
Po tym pozostaje tylko jedna tabela w tym obszarze tematycznym:country stół. To jest lista wszystkich krajów, w których znajdują się nasze biblioteki i/lub wydawcy książek. Składa się z następujących atrybutów:
id– Unikalny identyfikator dla każdego kraju.country_name– Nazwa kraju. To jest klucz alternatywny dla tabeli.
Następnie przyjrzyjmy się drugiemu obszarowi tematycznemu.
Członkowie i pożyczki
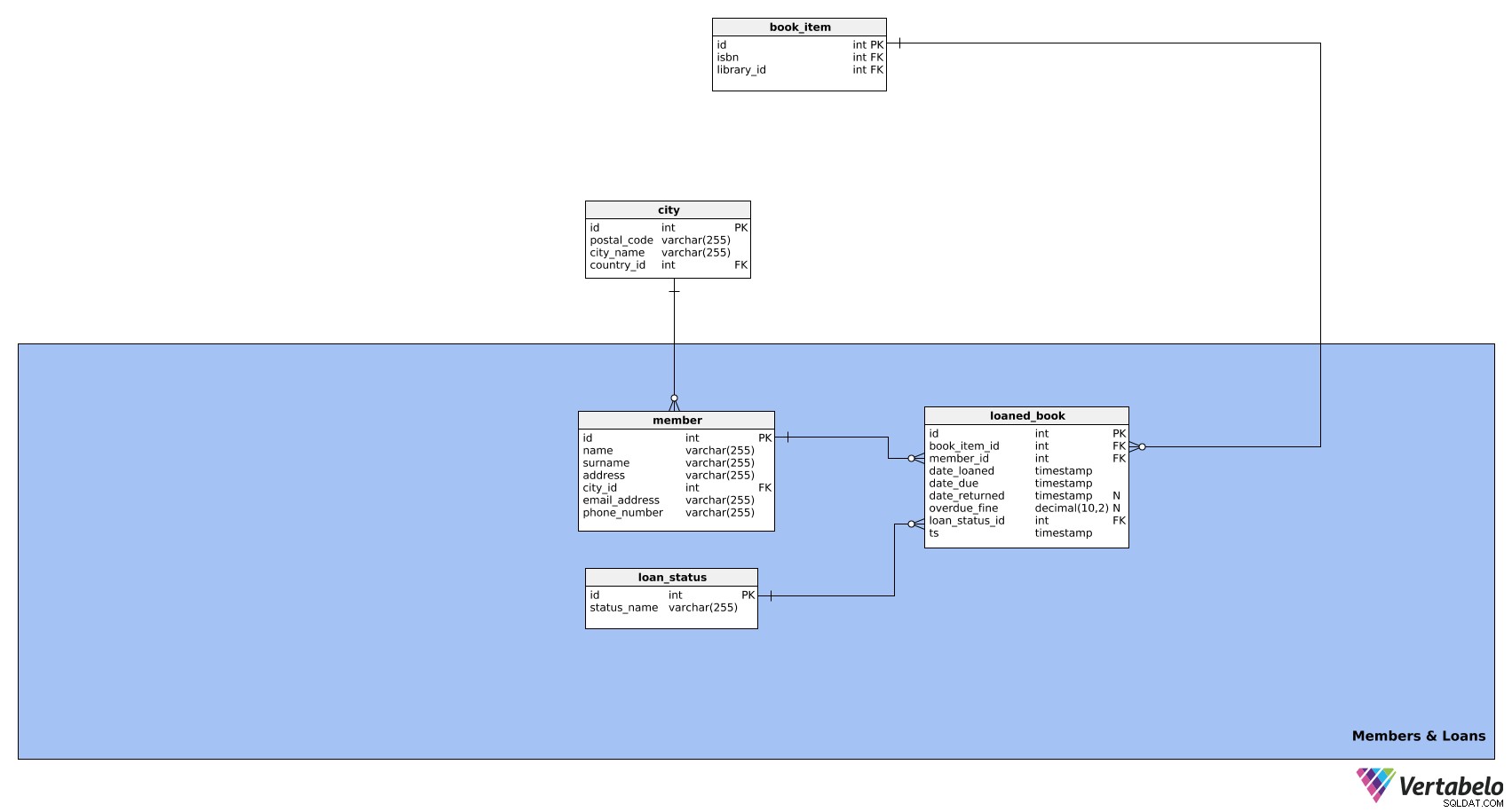
Celem tego obszaru tematycznego jest zarządzanie informacjami o członkach biblioteki i wypożyczanych przez nich książkach. Składa się z trzech tabel:
memberloaned_bookloan_status
Porozmawiajmy teraz o stołach.
Pierwsza tabela w tym obszarze to member stół. Zawiera wszystkie istotne informacje o członkach biblioteki. Jego atrybuty są następujące:
id– Unikalny identyfikator dla każdego członka.name– Imię członka.surname– Nazwisko członka.address– Adres członka.city_id– Odwołuje się docitystół.email_address– Adres e-mail członka.phone_number– Numer telefonu członka.
Następna tabela to loaned_book stół. Przechowuje informacje o wszystkich wypożyczonych książkach. W ten sposób możemy śledzić stan inwentarza biblioteki oraz stan wypożyczonych książek. Ta tabela składa się z następujących atrybutów:
id– Unikalny identyfikator dla każdej wypożyczonej książki.book_item_id– Odwołuje się dobook_itemstół.member_id– Odwołuje się domemberstół.date_loaned– Data wypożyczenia tej książki.date_due– Data, kiedy ta książka powinna zostać zwrócona.date_returned– data faktycznego zwrotu książki do biblioteki; może to być NULL, ponieważ nie będziemy znać daty, dopóki książka nie zostanie zwrócona.overdue_fine– Opłata za spóźnienie (jeśli istnieje) uiszczona przez członka, która jest zwykle obliczana na podstawie różnicy międzydate_returnedidate_due. Może to być NULL, ponieważ książka, która zostanie zwrócona na czas, nie ma mandatu.loan_status_id– Odwołuje się doloan_statusstół.ts– Znacznik czasu, w którym wprowadzono ten status pożyczki.
loan_status tabela jest ostatnią w naszym modelu danych. To po prostu lista wszystkich możliwych stanów kredytu, m.in. aktywny, przeterminowany, zwrócony itp. Ta tabela będzie składać się z następujących atrybutów:
id– Unikalny identyfikator dla każdego statusu pożyczki.status_name– Nazwa opisująca stan pożyczki. To jest klucz alternatywny dla tabeli.
To wszystko – omówiliśmy wszystkie szczegóły naszego modelu danych!
Co myślisz o modelu danych bibliotecznych?
Omówiliśmy ogólne zasady w tym modelu, więc powinno być (z kilkoma poprawkami) dla każdej biblioteki. Czy znasz jakieś specyfikacje biblioteki, które przegapiliśmy? A może uważasz, że model jest przydatny i łatwy do zastosowania? Wypowiedz się w sekcji komentarzy.