Arkusze kalkulacyjne – Excel, Arkusze Google lub arkusz o dowolnej innej nazwie – to naprawdę fajne i potężne narzędzia. Ale tak samo są z bazami danych. Kiedy należy trzymać się arkusza kalkulacyjnego? Kiedy należy przejść do bazy danych?
Jest to kontynuacja mojego poprzedniego artykułu „Arkusze kalkulacyjne a bazy danych:czy nadszedł czas na zmianę?” gdzie omówiliśmy najczęstsze wady korzystania z arkuszy kalkulacyjnych do organizowania dużej ilości danych. W tym artykule dowiemy się, jak baza danych rozwiązuje te problemy.
Korzystanie z bazy danych do organizowania danych
Moje motto to „wykorzystaj odpowiednią technologię do swoich potrzeb”. Jeśli potrafisz prowadzić swój biznes za pomocą arkuszy, to świetnie! Jeśli potrzebujesz prostej bazy danych, MS Access nie jest złą opcją. Ale jeśli te produkty nie działają dla Ciebie, prawdopodobnie będziesz potrzebować dostosowanej bazy danych i aplikacji internetowej. Baza danych będzie przechowywać Twoje dane; aplikacja internetowa będzie przyjaznym dla użytkownika sposobem interakcji z bazą danych i komunikowania się z warstwą danych.
Nasza fikcyjna działalność usługowa nie była zbyt skomplikowana, więc mogliśmy ją zasilać za pomocą dość prostego modelu danych. Jeśli spojrzysz na poniższy obraz, zobaczysz, że wszystko, czego potrzebujemy, jest przechowywane w zaledwie pięciu tabelach:client_type , client , service , replacement i has_service .
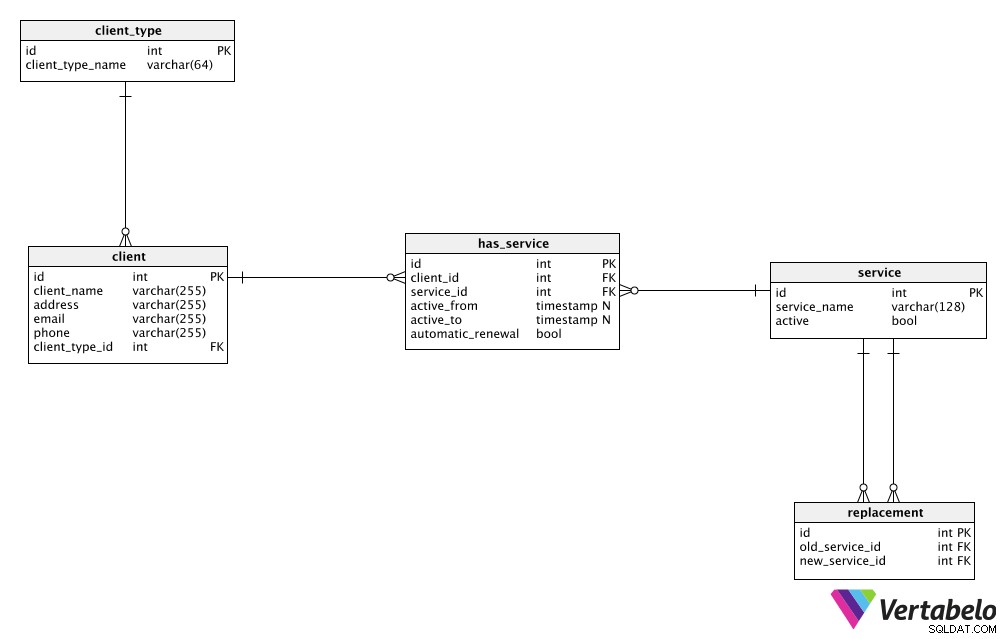
Kluczową zasadą projektowania baz danych jest utrzymywanie powiązanych danych ze świata rzeczywistego w jednym miejscu . W takim przypadku zachowamy całego naszego client dane w tabeli klienta. W ten sposób unikniemy przechowywania tych samych danych w wielu lokalizacjach (wspomniany wcześniej zły rodzaj nadmiarowości). Jeśli zmienimy coś związanego z klientem, zrobimy to tylko raz, w tej tabeli. To znacznie poprawi jakość danych i poprawi wydajność.
Następna tabela zawierająca dane ze świata rzeczywistego to service stół. Ponownie możemy tutaj przechowywać wszystkie szczegóły związane z naszymi usługami i możemy dość sprawnie wprowadzać zmiany w danych.
client tabela i service tabela to rzeczywiste byty, które mogłyby istnieć bez drugiego. Jednak tworzenie bazy danych z niepowiązanymi podmiotami nie ma większego sensu – to jak posiadanie klientów bez produktów lub usług bez kupujących. Dlatego połączymy te dwie tabele za pomocą has_service stół. Aby przechowywać informacje o tym, którzy klienci mają jaką usługę, użyjemy kluczy obcych, które działają jako odniesienia do tego klienta i usługi. Te klucze obce wskazują z powrotem do rekordów w tabelach usług i klientów. W tej tabeli możemy również przechowywać wszelkie dodatkowe informacje związane z każdą relacją klient-usługa.
client_type table jest używana jak słownik, który przechowuje każdy możliwy typ klienta. Najlepiej przechowywać różne segmentacje w osobnych tabelach słownikowych (np. gdybyśmy mieli typy klientów i typy ról pracowników, przechowywalibyśmy je w różnych tabelach). Jednak potrzebujemy tylko jednej tabeli, ponieważ jest to prosty model.
Ostatnia tabela w naszym modelu to replacement stół. Użyjemy go do powiązania dwóch usług:usługi, którą chcemy wymienić, i usługi zastępczej. Daje nam to elastyczność w oferowaniu klientom zamienników istniejących usług (podobnie jak zmiana z jednego planu taryfowego na inny).
Zalety bazy danych
Bazy danych są bardziej skomplikowane w konfiguracji niż arkusze kalkulacyjne, ale w rzeczywistości daje im to pewne znaczące korzyści pod względem integralności i bezpieczeństwa danych:
Klucze i ograniczenia
Bazy danych mają wbudowane reguły i kontrole, które, jeśli są używane prawidłowo, zapobiegają większości problemów z jakością i wydajnością danych. Klucze podstawowe (kolumny, które jednoznacznie identyfikują każdy rekord w tabeli) i klucze obce (kolumny, które odwołują się do rekordu w innej tabeli) są krytyczne dla bezpieczeństwa danych, ale definiują klucze alternatywne lub UNIKALNE (zawierające dane unikalne dla każdego rekordu w tabeli ) jest również bardzo pomocny.
W relacyjnych bazach danych klucze wiążą dane z różnych tabel. Klucz podstawowy tabeli jest zawsze UNIKATOWY, podczas gdy klucz obcy odwołuje się do klucza podstawowego z innej tabeli. To odniesienie dotyczy danych z tych dwóch tabel (np. kluczy obcych w has_service tabela powiązać dane klientów z usługami, które mają). Ostrzeże nas również, jeśli zamierzamy usunąć klucz podstawowy, do którego odwołuje się inna tabela. Uniemożliwi nam to usunięcie rekordów, które są nadal potrzebne (jako referencje) w innej tabeli.
Ograniczenia definiują rodzaj danych, które można wprowadzić do pola. Możemy określić, że dane muszą mieć wartość (NOT NULL), zdefiniować format numerów telefonów, zawierać tylko litery i tak dalej. Oznacza to, że możemy uniknąć problemów z danymi od osób wprowadzających niewłaściwe dane w polu.
Bezpieczeństwo i uprawnienia
Inną bardzo ważną funkcją bazy danych jest kontrola dostępu do swoich danych . Daje to możliwość określenia nie tylko, kto może uzyskać dostęp do Twojej bazy danych, ale także kontrolowania tego, co może zobaczyć lub zmodyfikować. To ogromna część bezpieczeństwa danych. Na przykład możesz zdefiniować rolę użytkownika, która pozwoliłaby pracownikowi zmieniać dane klienta, ale nie szczegóły usługi. Możesz także ustawić reguły, na których pracownicy mogą zmieniać lub usuwać dane. Dobrą standardową praktyką jest upewnienie się, że ludzie mają dostęp tylko do tych danych, których potrzebują do wykonywania swojej pracy.
Oczywiście moglibyśmy spróbować odtworzyć te funkcje w arkuszach (przynajmniej w jakiś sposób), ale to z pewnością byłoby „wymyśleniem koła na nowo”.
Czy nie moglibyśmy po prostu użyć arkusza kalkulacyjnego?
Oczywiście, że mogliśmy. Moglibyśmy tworzyć arkusze zgodne z tym samym wzorcem, który zastosowano w modelu danych. To rozwiązałoby wiele problemów z danymi, ale…
Replikacja modelu danych w arkuszach zdecydowanie nie jest idealną opcją. Stracilibyśmy wszystkie korzyści, jakie zapewnia nam system baz danych, wszystkie reguły i ograniczenia, które utrzymują dane w „zdrowym” stanie, wszystko, co zapobiega przypadkowemu usunięciu i innym błędom. Stracilibyśmy na optymalizacji, a jeśli zestaw danych byłby wystarczająco duży, wydajność spadłaby.
Nawet gdybyśmy to rozwiązali, to co z udostępnianiem danych, m.in. wielu użytkowników korzysta jednocześnie z tego samego arkusza? Jakie problemy z integralnością danych i wydajnością by to spowodowało? Byłoby to przeciwieństwem prostoty.
Jeśli więc uważasz, że arkusze nie poradzą sobie z Twoimi potrzebami biznesowymi, prawdopodobnie już zmierzasz w kierunku bazy danych. Jeśli utkniesz z danymi przechowywanymi w arkuszach i chcesz przenieść się do bazy danych, powinieneś:
- Stwórz model bazy danych, który optymalnie przechowuje Twoje dane.
- Zbuduj aplikację z bazą danych w tle.
- Wyczyść swoje dane, przekształć je (w razie potrzeby) i zaimportuj do bazy danych.
- Kontynuuj pracę tylko z bazą danych.
Który wybór — arkusz kalkulacyjny czy baza danych?
W dzisiejszym artykule dowiedzieliśmy się, jak baza danych rozwiązuje problemy z wykorzystaniem arkuszy do organizowania dużej ilości danych. Moja rada to zawsze wybieraj najprostsze rozwiązanie swojego problemu . Jeśli arkusze kalkulacyjne wykonają swoją pracę prawidłowo, użyj ich. Ale jeśli jesteś firmą opartą na danych, powinieneś zacząć korzystać z bazy danych JAK NAJSZYBCIEJ. Im dłużej czekasz na wyczyszczenie i migrację danych, tym bardziej bolesny będzie proces.