Wszyscy mamy nadzieję, że ubezpieczenie na życie nie będzie nam potrzebne, ale jak wiemy, życie jest nieprzewidywalne. W tym artykule skupimy się na sformułowaniu modelu danych, który firma ubezpieczeniowa na życie może wykorzystać do przechowywania swoich informacji.
Ubezpieczenie na życie jako koncepcja
Zanim zaczniemy omawiać rzeczywisty model danych dla firmy ubezpieczeniowej na życie, krótko przypomnimy sobie, czym jest ubezpieczenie i jak ono działa, abyśmy mieli lepsze pojęcie o tym, z czym pracujemy.
Ubezpieczenia to dość stara koncepcja, która sięga jeszcze przed średniowieczem, kiedy wiele gildii oferowało polisy chroniące swoich członków w nieoczekiwanych sytuacjach. Nawet słynny astronom, matematyk, naukowiec i wynalazca Edmund Halley parał się ubezpieczeniami, pracując nad statystykami i wskaźnikami śmiertelności, które stanowiły podstawę nowoczesnych modeli ubezpieczeniowych.
Dlaczego miałbyś płacić za ubezpieczenie? Pomysł jest dość prosty – płacisz określoną kwotę (składkę) w zamian za gwarancję firmy ubezpieczeniowej, że Ty lub Twoja rodzina otrzymacie rekompensatę finansową, jeśli coś nieoczekiwanego stanie się z Tobą lub Twoją własnością. W przypadku polisy na życie wyznaczasz beneficjenta, który na wypadek Twojej śmierci otrzyma pewną sumę pieniężną (świadczenie). Chodzi o to, że te pieniądze pomogą im odzyskać siły po stracie, zwłaszcza jeśli twoja śmierć spowoduje jakiekolwiek problemy finansowe.
Oczywiście firmy ubezpieczeniowe zazwyczaj wypłacają znacznie mniej świadczeń niż zarabiają na składkach i na inwestowaniu pieniędzy, powiedzmy, na giełdzie. W przeciwnym razie zbankrutują, a cały system się rozpadnie!
To w zasadzie sedno tego. Teraz, gdy mamy to na uboczu, przejdźmy dalej i przyjrzyjmy się modelowi danych dla typowej firmy ubezpieczeniowej na życie.
Model danych:omówienie
Model danych, z którym będziemy pracować, składa się z pięciu obszarów tematycznych:
- Pracownicy
- Produkty
- Klienci
- Oferty
- Płatności
Omówimy każdą z tych sekcji bardziej szczegółowo, w kolejności wymienionej powyżej.
Obszar tematyczny nr 1:Pracownicy
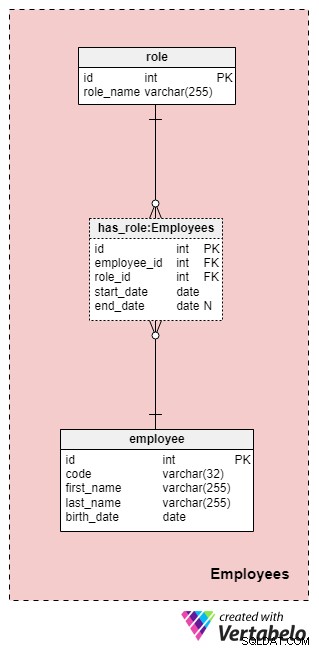
Ten obszar niekoniecznie jest specyficzny dla tego modelu danych, ale nadal jest bardzo ważny, ponieważ do tabel zawartych w tym miejscu będą się odwoływać inne obszary tematyczne. Na potrzeby naszego modelu danych firmy ubezpieczeniowej musimy oczywiście wiedzieć, kto wykonał jaką czynność (np. kto reprezentował naszą firmę podczas współpracy z klientem/klientem, kto podpisał polisę itd.).
Lista wszystkich pracowników firmy jest przechowywana w employee stół. Dla każdego pracownika przechowujemy następujące informacje:
code— unikalny klucz, który identyfikuje pojedynczego pracownika. Ponieważ kod będzie używany jako atrybut w innych tabelach, będzie służył jako klucz alternatywny w tej tabeli.first_nameilast_name— odpowiednio imię i nazwisko pracownika.birth_date— data urodzenia pracownika.
Oczywiście moglibyśmy z pewnością uwzględnić w tej tabeli wiele innych atrybutów związanych z pracownikami, ale na razie te cztery są więcej niż wystarczające. Będziemy postępować zgodnie z tym wzorcem w całym artykule i starać się, aby wszystko było tak proste, jak to możliwe, ale pamiętaj, że zdecydowanie możesz rozszerzyć ten model danych o dodatkowe informacje.
Ponieważ pracownicy mogą w każdej chwili zmienić swoje role w naszej firmie, będziemy potrzebować tabeli słownikowej do reprezentowania ról w firmie oraz tabeli do przechowywania wartości. Lista wszystkich możliwych ról, które pracownicy mogą pełnić w naszej firmie ubezpieczeniowej na życie, jest przechowywana w role słownik. Ma tylko jeden atrybut o nazwie role_name który zawiera jednoznacznie identyfikujące wartości.
Powiążemy pracowników i role za pomocą has_role stół. Oprócz kluczy obcych employee_id i role_id , będziemy przechowywać dwie wartości:start_date i end_date . Te dwie wartości oznaczają zakres, w jakim ta rola firmy była aktywna dla danego pracownika. end_date będzie zawierać wartość null do czasu ustalenia daty zakończenia roli tego pracownika. Alternatywnym kluczem dla tej tabeli jest kombinacja employee_id , role_id i start_date . Aby uniknąć powielania tej samej roli dla tego samego pracownika, za każdym razem, gdy dodajemy nowy rekord do tabeli lub aktualizujemy istniejący, musimy programowo sprawdzać, czy nie nakładają się one na siebie.
Obszar tematyczny #2:Produkty
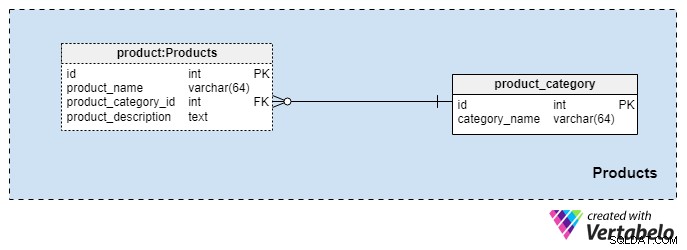
Ten obszar tematyczny jest dość mały i zawiera tylko dwie tabele. Wartości z tych tabel są warunkiem wstępnym dla naszych innych obszarów tematycznych, więc omówimy je pokrótce.
product_category słownik przechowuje najbardziej ogólne kategorie produktów, które planujemy zaoferować naszym klientom. Jedyną wartością, jaką będziemy przechowywać w tej tabeli, jest unikalna category_name w celu oznaczenia rodzaju oferowanego przez nas ubezpieczenia, które może być ubezpieczeniem osobistym na życie, ubezpieczeniem rodzinnym na życie itd.
Będziemy jeszcze bardziej kategoryzować nasze produkty za pomocą product stół. Ta tabela przedstawia rzeczywiste produkty, które sprzedajemy, a nie ich kategorie. Jak możesz sobie wyobrazić, możemy pogrupować produkty według czasu trwania (np. 10 lub 20 lat, a nawet życie). Jeśli zdecydujemy się to zrobić, prawdopodobnie będziemy mieć produkty z tym samym product_category_id ale różne nazwy i opisy. Dla każdego produktu przechowujemy następujące podstawowe informacje:
product_name— nazwa tego produktu. Jest używany jako klucz alternatywny dla tej tabeli w połączeniu zproduct_category_idatrybut. Jest mało prawdopodobne, abyśmy mieli dwa produkty o tej samej nazwie, które należą do różnych kategorii, ale jest to jednak możliwość.product_category_id— identyfikuje kategorię, do której należy ten produkt.product_description— opis tekstowy tego produktu.
Obszar tematyczny 3:Klienci
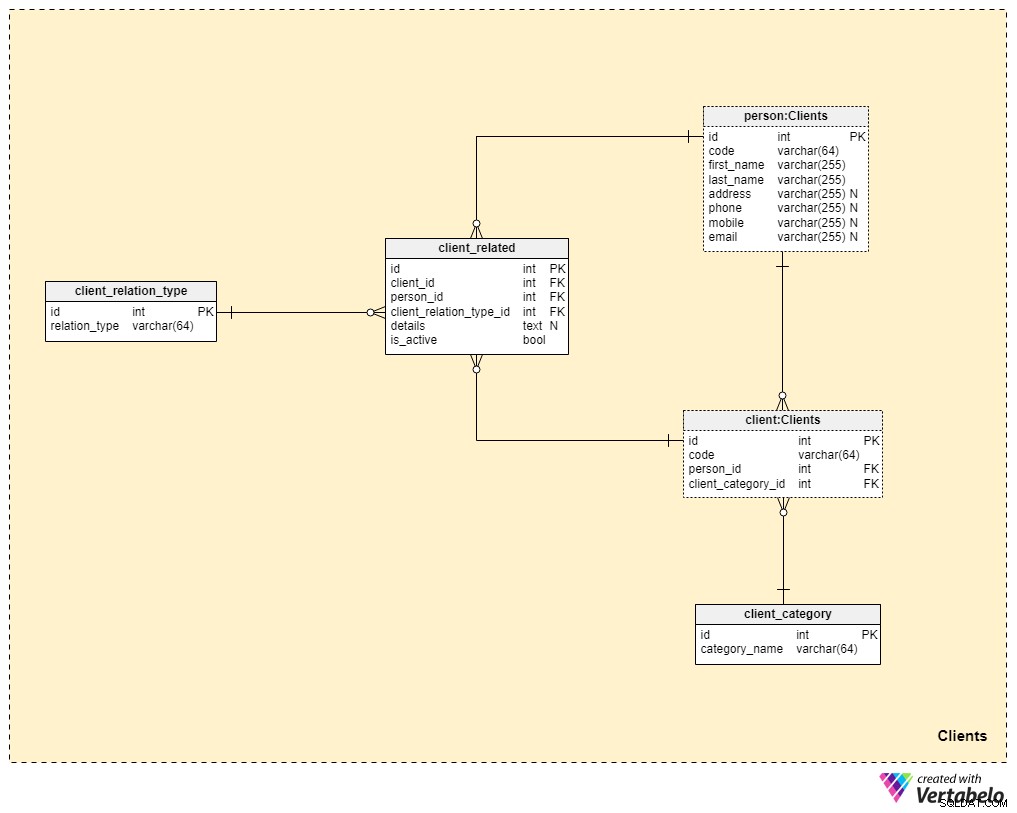
Teraz zbliżamy się znacznie do rdzenia naszego modelu danych, ale jeszcze do tego nie doszliśmy. Ubezpieczenie na życie jest wyjątkowe, ponieważ polisę można przenieść na członka rodziny lub kogoś innego, podczas gdy polisy na inne formy ubezpieczenia (takie jak ubezpieczenie zdrowotne lub ubezpieczenie samochodu) należą do jednego klienta i nie można ich przenieść. Z tego powodu musimy przechowywać nie tylko informacje o kliencie, do którego należy polityka, ale także informacje o wszelkich powiązanych osobach i ich relacjach z klientem.
Zaczniemy od client stół. Dla każdego klienta będziemy przechowywać unikalny kod wygenerowany lub wstawiony ręcznie dla tego klienta, a także klucze obce odwołujące się do tabeli z ich danymi osobowymi (person_id ) oraz tabelę zawierającą naszą wewnętrzną kategoryzację (client_category_id ).
client_category słownik pozwala nam grupować klientów na podstawie ich danych demograficznych i danych finansowych. Kategorie klientów zostaną następnie wykorzystane do określenia polisy ubezpieczeniowej, którą jesteśmy gotowi zaoferować danemu klientowi. Tutaj będziemy przechowywać tylko listę unikalnych wartości, które następnie przypiszemy klientom.
Skoro mówimy o ubezpieczeniu na życie, to zakładamy, że klient to pojedyncza osoba. Jednak, jak wspomnieliśmy wcześniej, mogą istnieć inne osoby powiązane z klientem, na które może zostać przeniesiona polisa lub które mogą otrzymać świadczenie z polisy po śmierci klienta. Z tego powodu stworzyliśmy osobną person stół. Dla każdego rekordu w tej tabeli będziemy przechowywać następujące informacje:
code— automatycznie wygenerowana lub ręcznie wstawiona wartość używana do jednoznacznej identyfikacji powiązanej osoby.first_nameilast_name— odpowiednio imię i nazwisko osoby.address,phone,mobileiemail— dane kontaktowe tej osoby, z których wszystkie zawierają dowolne wartości.
Pozostałe dwie tabele w tym obszarze tematycznym są potrzebne do opisania charakteru relacji między klientami a innymi ludźmi.
Lista wszystkich możliwych typów relacji jest przechowywana w client_relation_type słownik. Podobnie jak w przypadku innych słowników, będzie on zawierał listę unikalnych nazw, których będziemy później używać przy opisywaniu relacji między konkretnym klientem a inną osobą.
Rzeczywiste dane relacji są przechowywane w client_related stół. Dla każdego rekordu w tej tabeli będziemy przechowywać odniesienia do klienta (client_id ), powiązana osoba (person_id ), charakter tej relacji (client_relation_type_id ), wszystkie szczegóły dodawania (details ), jeśli istnieje, oraz flagę wskazującą, czy relacja jest aktualnie aktywna (is_active ). Klucz alternatywny w tej tabeli jest zdefiniowany przez kombinację client_id , person_id i client_relation_type_id .
Obszar tematyczny 4:Oferty
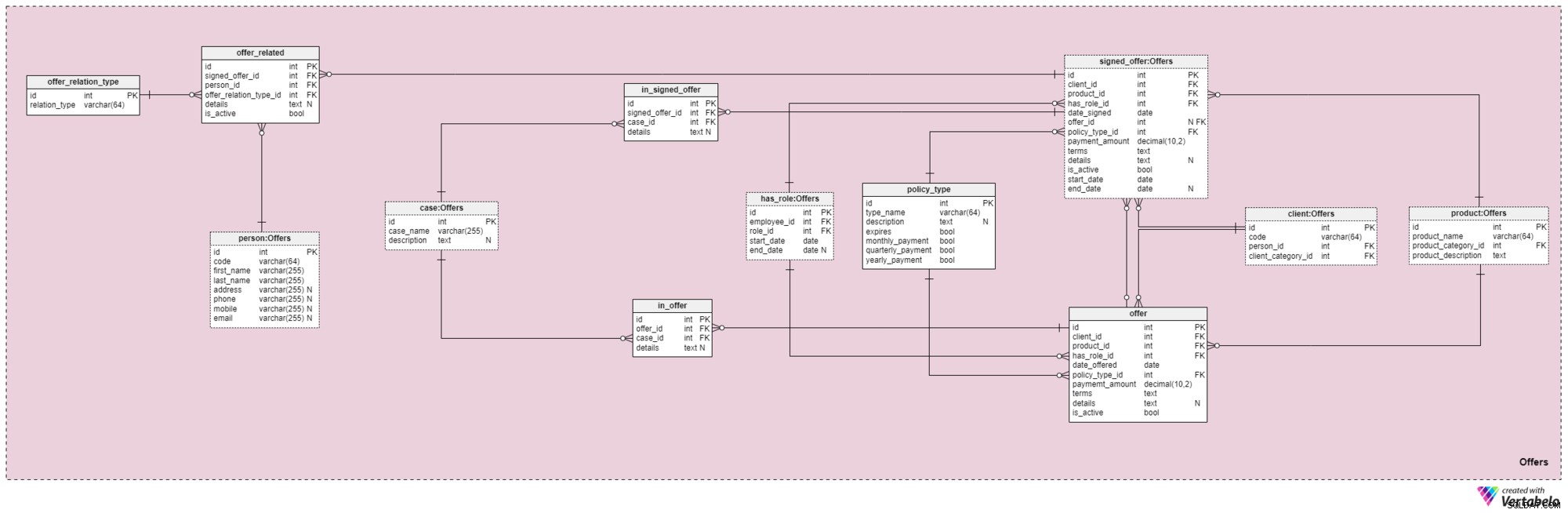
Ten i następny obszar tematyczny jest sercem tego modelu danych. Obejmują oferty i podpisane polisy, a także płatności związane z ofertami. Najpierw opiszemy obszar tematyczny Oferty. Może wydawać się skomplikowany, ponieważ zawiera 12 tabel. Jednak cztery z tych 12 (has_role , product , client i person ) zostały opisane w poprzednich obszarach tematycznych, więc nie będziemy tutaj powtarzać naszej dyskusji.
offer i signed_offer tabele mają podobną strukturę, ponieważ będą używane do przechowywania bardzo podobnych danych w naszym modelu. Jednak podczas gdy offer będzie używany głównie do przechowywania wszelkich zasad (i ich szczegółów), które zaoferowaliśmy naszym klientom, signed_offer tabela będzie służyła wyłącznie do przechowywania informacji o klientach, którzy faktycznie podpisali polisy z naszą firmą. Omówimy te tabele razem, zwracając uwagę na wszelkie różnice tam, gdzie się pojawiają. Atrybuty w tych dwóch tabelach są następujące:
client_id— odniesienie do unikalnego identyfikatora klienta, który podpisał daną ofertę.product_id— odniesienie do unikalnego identyfikatora produktu, który był zawarty w podpisanej ofercie.has_role_id— odniesienie do identyfikatora pracownika i roli, jaką pełnił w momencie przedstawienia/podpisania oferty.date_offeredidate_signed— rzeczywiste daty oznaczające, odpowiednio, kiedy ta oferta została przedstawiona klientowi i kiedy została podpisana.offer_id— nawiązanie do poprzedniej oferty dla tego klienta. Może zawierać wartość null, ponieważ klient mógł podpisać polisę bez wcześniejszej oferty firmy, tak jakby sam zwrócił się do nas. Ten atrybut należy wyłącznie dosigned_offerstół.policy_type_id— odniesienie do słownika typów polis, określającego typ polisy, którą zaoferowaliśmy klientowi lub zleciliśmy jego podpisanie.payment_amount— kwota, którą klient musi regularnie płacić za polisę.terms— wszystkie warunki umowy w formacie tekstowym (XML). Chodzi o to, aby w tym atrybucie przechowywać wszystkie ważne szczegóły dotyczące finansowej części polisy. Przykładami tekstów, które możemy przechowywać, są całkowita kwota polisy, liczba płatności, które klient musi dokonać itd.details— wszelkie dodatkowe szczegóły w formacie tekstowym.is_active— flaga informująca, czy rekord jest nadal aktywny.start_dateiend_date— należy wskazać przedział czasowy, w którym ta polityka jest/była aktywna. Jeśli polityka została podpisana na całe życie, data_końcowa będzie zawierać wartość null.
Istnieje również policy_type słownik, o którym pokrótce wspomnieliśmy wcześniej. Potrzebujemy pewnego stopnia elastyczności w oferowaniu tego samego produktu różnym klientom, w oparciu o takie czynniki, jak wiek, stan zdrowia, stan cywilny, ryzyko kredytowe i tak dalej. Dla każdego typu zasad będziemy przechowywać type_name identyfikator, dodatkowy tekstowy description , flaga o nazwie wygasa, oznaczająca, czy polisa może wygasnąć, oraz inna flaga wskazująca, czy składki tego rodzaju polisy muszą być opłacane miesięcznie, kwartalnie czy rocznie. Niektóre oczekiwane typy polis to:Terminowe życie, Całe życie, Uniwersalne życie, Gwarantowane uniwersalne życie, Zmienne życie, Zmienne uniwersalne życie i Ubezpieczenie na życie po przejściu na emeryturę.
Idąc dalej, musimy teraz zdefiniować wszystkie przypadki i sytuacje, które może obejmować dana polisa. Musimy powiązać te przypadki z konkretnymi ofertami i podpisanymi ofertami.
Lista wszystkich możliwych przypadków, których dotyczą nasze zasady, jest przechowywana w case słownik. Każdy rekord w tej tabeli może być jednoznacznie zidentyfikowany przez jego case_name i ma dodatkowy description , jeśli jest to potrzebne.
in_offer i in_signed_offer tabele mają tę samą strukturę, ponieważ przechowują te same dane. Jedyna różnica między nimi polega na tym, że pierwsza przechowuje sprawy objęte polisą, która została jedynie zaoferowana klientowi, podczas gdy druga przechowuje sprawy w polisie podpisanej przez klienta. Dla każdego rekordu w tych dwóch tabelach przechowamy unikalną parę offer_id /signed_offer_id i case_id , z których ostatnia oznacza przypadek lub incydent objęty polisą. Wszystkie inne szczegóły zostaną w razie potrzeby zapisane w atrybucie tekstowym.
Jak wspomnieliśmy wcześniej, polisy na życie prawie zawsze dotyczą nie tylko klientów, ale także członków ich rodzin lub krewnych. Także w tym obszarze musimy przechowywać te relacje. Zostaną one zdefiniowane w momencie podpisania polityki, ale mogą być również zmieniane w trakcie jej trwania.
Pierwszą rzeczą, którą musimy zrobić, to stworzyć słownik zawierający wszystkie możliwe wartości, które można przypisać do relacji. W naszym modelu jest to offer_relation_type słownik. Oprócz klucza podstawowego, ta tabela zawiera tylko jeden atrybut — relation_type – które mogą posiadać tylko unikalne wartości.
Prawie jesteśmy na miejscu! Ostatnia tabela w tym obszarze tematycznym nosi tytuł offer_related . Dotyczy podpisanej oferty każdemu, kto jest spokrewniony z klientem. Dlatego musimy przechowywać odniesienia do podpisanej polityki (signed_offer_id ) i powiązaną osobę (person_id ), a także określ charakter tej relacji (offer_relation_type_id ). Dodatkowo będziemy musieli przechowywać details powiązane z tym rekordem i utwórz flagę, aby sprawdzić, czy jest on nadal ważny w naszym systemie.
Obszar tematyczny 5:Płatności
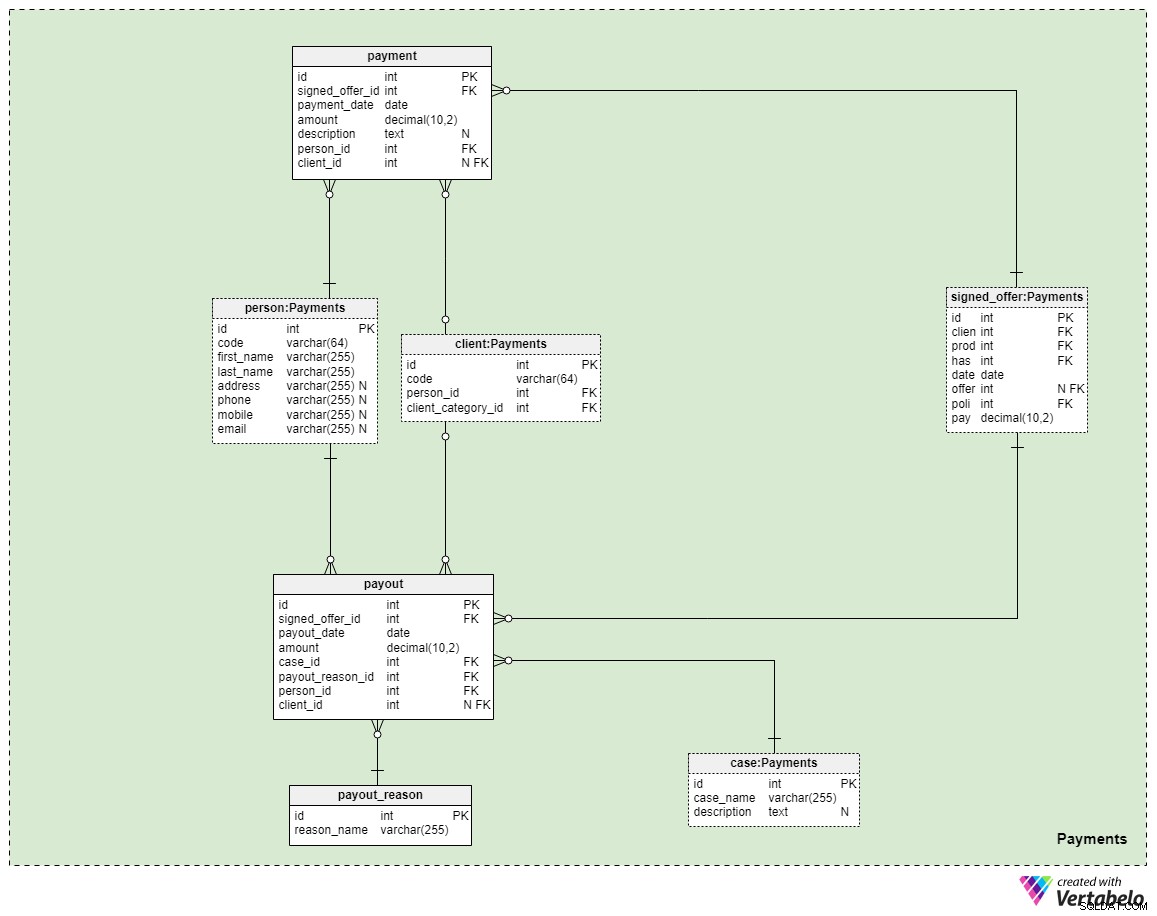
Ostatni obszar tematyczny w naszym modelu dotyczy płatności. Tutaj wprowadzamy tylko trzy nowe tabele:payment , payout_reason i payout .
Wszystkie płatności związane z zasadami są przechowywane w payment stół. Zawarliśmy tutaj tylko najważniejsze atrybuty:
signed_offer_id— odniesienie do unikalnego identyfikatora podpisanej oferty (polityki).payment_date— data dokonania tej płatności.amount— rzeczywista kwota, która została zapłacona.description— opcjonalny opis płatności w formacie tekstowym.person_id— odniesienie do niepowtarzalnego identyfikatora osoby, która dokonała płatności. Zauważ, że klient, który podpisał ofertę, niekoniecznie jest jedyną osobą, która może dokonać płatności.client_id— odniesienie do unikalnego identyfikatora klienta, który dokonał płatności. Ten atrybut będzie zawierał wartość tylko wtedy, gdy klient sam dokonał płatności.
Pozostałe dwie tabele przedstawiają być może najważniejszy powód, dla którego płacimy za ubezpieczenie na życie — że w przypadku, gdyby coś nam się stało, wypłaty zostaną wypłacone członkom naszej rodziny lub partnerom życiowym/biznesowym. Jak to się dzieje, wszystko zależy od Twojej sytuacji i warunków podpisanej przez Ciebie konkretnej polisy. Do omówienia tych przypadków użyjemy dwóch prostych tabel.
Pierwszy to słownik zatytułowany payout_reason i posiada klasyczną strukturę słownikową. Oprócz podstawowego atrybutu klucza, mamy tylko jeden atrybut – reason_name – który będzie przechowywać listę unikalnych wartości wskazujących, dlaczego ta wypłata została dokonana.
Ostatnia tabela w modelu to payout stół. Jest bardzo podobny do payment tabeli, ale najważniejsze różnice są wymienione poniżej:
payout_date— data dokonania wypłaty.case_id— odniesienie do niepowtarzalnego identyfikatora powiązanej sprawy lub incydentu, który spowodował płatność. Powinno to pasować do jednego z identyfikatorów zawartych w zasadach.payout_reason_id— odniesienie do słownika, który bardziej szczegółowo opisuje powód wypłaty. Chociaż sprawa wypłaty jest krótsza i bardziej ogólna, powód wypłaty będzie zawierał bardziej szczegółowe informacje na temat tego, co się stało.person_idiclient_id— odnosi się odpowiednio do osoby i klienta związanych z wypłatą.
Podsumowanie
Niesamowite! Z powodzeniem zbudowaliśmy nasz model danych dotyczących ubezpieczeń na życie. Zanim zakończymy naszą dyskusję, warto zauważyć, że w tym modelu można omówić znacznie więcej. W tym artykule chcieliśmy głównie omówić podstawy modelu, aby dać wyobrażenie o jego wyglądzie i działaniu. Oto kilka dodatkowych szczegółów, które można włączyć do takiego modelu danych:
- Dodatkowe aktualizacje polis nie są objęte naszym obecnym modelem (np. jeśli chcesz składać coroczne oferty dla istniejących polis, nie możesz tego zrobić w tej strukturze). Powinniśmy dodać kilka dodatkowych tabel, aby przechowywać wszystkie zmiany zasad dla przedstawionych/podpisanych ofert.
- Cała dokumentacja jest celowo pomijana. Oczywiście będzie sporo papierkowej roboty związanej z konkretną polisą na życie, zwłaszcza w zakresie procesu podpisywania i wypłat. Możemy dołączyć dokumenty opisujące status klienta w momencie podpisania polisy oraz wszelkie zmiany po drodze, a także wszelkie dokumenty związane z wypłatami.
- Ten model nie zawiera struktury potrzebnej do obliczenia ryzyka polisy. Powinniśmy mieć wszystkie parametry, które musimy przetestować i wszelkie zakresy, które określają, jak wartość klienta wpływa na ogólne obliczenia. Wyniki tych obliczeń musiałyby być przechowywane dla każdej oferty i podpisanej polisy.
- Struktura faktury w rzeczywistości jest znacznie bardziej złożona niż to, co omówiliśmy w obszarze płatności. W naszym modelu nawet nie wspomnieliśmy o kontach finansowych.
Oczywiście branża ubezpieczeniowa jest dość złożona. W tym artykule omówiliśmy tylko model danych dla ubezpieczeń na życie — czy możesz sobie wyobrazić, jak ewoluowałby ten model danych, gdybyśmy mieli prowadzić firmę, która oferuje wiele różnych rodzajów ubezpieczeń? Przedstawienie zorganizowanego modelu danych dla takiej firmy z pewnością wymagałoby dużo planowania i przemyśleń.
Jeśli masz jakieś sugestie lub pomysły dotyczące ulepszenia naszego modelu danych, daj nam znać w komentarzach poniżej!