W moim poprzednim poście omówiłem LCK_M_XX, ASYNC_NETWORK_IO i OLEDB waits oraz odruchowe reakcje na nie. W tym poście zamierzam kontynuować temat statystyk oczekiwania i omówić oczekiwanie SOS_SCHEDULER_YIELD.
Kiedy SOS_SCHEDULER_YIELD jest najbardziej rozpowszechniony na serwerze, często obserwuje się ciągłe, wysokie użycie procesora. Odruchową reakcją jest to, że serwer musi być pod obciążeniem procesora lub że problemem jest blokada spina.
Potrzebujemy trochę tła, aby zrozumieć te dwie reakcje.
Planowanie wątków
Planowanie wątków w SQL Server jest zarządzane przez sam SQL Server, a nie przez Windows (tzn. nie jest to wywłaszczające). Część silnika pamięci masowej dotycząca systemu operacyjnego SQL zapewnia funkcje planowania i przejście wątków z działania na procesorze (gdzie stan wątku to URUCHOMIONY) do przebywania na liście oczekujących na udostępnienie zasobu (stan ZAWIESZONY) do stanu Runnable Kolejka, gdy zasób stanie się dostępny (stan jest URUCHOMIONY), czeka na przejście na początek kolejki i powrót do procesora (powrót do stanu URUCHOMIENIA). Zapisałem wielką literę Procesor, Lista kelnerów i Kolejka do uruchomienia, aby zidentyfikować je jako części harmonogramu.
Za każdym razem, gdy wątek potrzebuje zasobu, którego nie może natychmiast pozyskać, zostaje zawieszony i czeka na liście oczekujących na powiadomienie (zasygnalizowanie), że jego zasób jest dostępny. Czas spędzony na liście oczekujących to czas oczekiwania zasobu, a czas spędzony w kolejce do uruchomienia to czas oczekiwania na sygnał. Razem składają się na ogólny czas oczekiwania. SQL OS śledzi czas oczekiwania i czas oczekiwania na sygnał, więc musimy wykonać trochę matematyki na danych wyjściowych z sys.dm_os_wait_stats, aby uzyskać czas oczekiwania na zasoby (zobacz mój skrypt tutaj).
Lista kelnerów jest nieuporządkowana (każdy wątek na niej może zostać zasygnalizowany w dowolnym momencie i przejść do kolejki do uruchomienia), a kolejka do uruchomienia to kolejka pierwsza na wejściu (FIFO) prawie w 100% przypadków. Jedynym wyjątkiem od Runnable Queue, który jest FIFO, jest sytuacja, w której wiele grup obciążenia usługi Resource Governor zostało skonfigurowanych w tej samej puli zasobów i mają różne priorytety względem siebie. Nigdy nie widziałem tego z powodzeniem w produkcji, więc nie będę o tym dalej omawiać.
Jest jeszcze jeden powód, dla którego wątek może wymagać odejścia od procesora – wyczerpuje jego kwant. Kwant wątków w systemie operacyjnym SQL jest ustalony na 4 milisekundy. Sam wątek jest odpowiedzialny za ustalenie, czy jego kwant został wyczerpany (poprzez wywołanie procedur pomocniczych w systemie operacyjnym SQL) i dobrowolną rezygnację z procesora (tzw. plonowanie). Gdy tak się stanie, wątek przesuwa się bezpośrednio na dół Runnable Queue, ponieważ nie ma na co czekać. SQL OS musi jednak zarejestrować typ oczekiwania dla tego przejścia z procesora i rejestruje SOS_SCHEDULER_YIELD.
To zachowanie jest często mylone z obciążeniem procesora, ale tak nie jest – jest to po prostu ciągłe użycie procesora. Ciśnienie procesora i rozpoznawanie go to zupełnie inny temat na przyszły post. Jeśli chodzi o ten post, o ile średni czas oczekiwania na sygnał jest niski (0-0,1-0,2 ms), można dość bezpiecznie założyć, że ciśnienie procesora nie stanowi problemu.
Spinlocki
Spinlock to prymityw synchronizacji bardzo niskiego poziomu, który służy do zapewniania bezpiecznego wątkowo dostępu do struktur danych w SQL Server, które są bardzo gorące (bardzo niestabilne, dostępne i zmieniane niezwykle często przez wiele wątków). Przykładami takich struktur są lista wolnych od buforów w każdej części puli buforów i tablica wag proporcjonalnych dla plików danych w grupie plików.
Gdy wątek musi uzyskać blokadę spinlock, sprawdza, czy blokada ta jest wolna, a jeśli tak, natychmiast ją uzyskuje (przy użyciu zablokowanego prymitywu języka asemblera, takiego jak „test bit clear and set”). Jeśli nie można uzyskać spinlocka, wątek natychmiast próbuje go uzyskać ponownie, i znowu, i znowu, aż do tysiąca iteracji, aż się wycofa (na chwilę śpi). Nie jest to rejestrowane jako jakikolwiek typ oczekiwania, ponieważ wątek po prostu wywołuje funkcję sleep() systemu Windows, ale może sprawić, że inne oczekujące wątki będą miały długi (10-20 ms+) czas oczekiwania na sygnał, ponieważ uśpiony wątek pozostaje na procesorze, dopóki nie dostaje spinlock.
Dlaczego mówię o spinlockach? Ponieważ mogą one również być przyczyną dużego obciążenia procesora i istnieje błędne przekonanie, że blokady spinlock są przyczyną oczekiwania SOS_SCHEDULER_YIELD. Nie są.
Przyczyny SOS_SCHEDULER_YIELD
Jest więc jedna przyczyna SOS_SCHEDULER_YIELD:wątek wyczerpujący swoją kwantowość planowania i mocno powtarzające się instancje może prowadzić do tego, że SOS_SCHEDULER_YIELD będzie najbardziej rozpowszechnionym oczekiwaniem wraz z wysokim obciążeniem procesora.
Nie zobaczysz SOS_SCHEDULER_YIELD waitów w danych wyjściowych z sys.dm_os_waiting_tasks, ponieważ wątek nie czeka. Możesz zobaczyć, które zapytanie generuje oczekiwania SOS_SCHEDULER_YIELD, odpytując sys.dm_exec_requests i filtrując w kolumnie last_wait_type.
Oznacza to również, że gdy zobaczysz SOS_SCHEDULER_YIELD w danych wyjściowych sys.dm_os_wait_stats, czas oczekiwania na zasób będzie wynosił zero, ponieważ w rzeczywistości nie czekał. Pamiętaj jednak, że każde z tych „oczekiwań” to 4 ms czasu procesora naliczonego dla zapytania.
Jedynym sposobem udowodnienia, co powoduje oczekiwanie SOS_SCHEDULER_YIELD, jest przechwycenie stosów wywołań programu SQL Server, gdy wystąpi ten typ oczekiwania, przy użyciu rozszerzonych zdarzeń i symboli debugowania firmy Microsoft. Mam post na blogu, który opisuje i pokazuje, jak przeprowadzić to dochodzenie, a także świetny dokument na temat blokad i dochodzeń związanych z blokadą spin-lock, który warto przeczytać, jeśli interesuje Cię ta głębia informacji wewnętrznych.
W przypadku wyczerpania kwantowego nie jest to główna przyczyna. To kolejny objaw. Teraz musimy zastanowić się, dlaczego wątek może wielokrotnie wyczerpywać swój kwant.
Wątek może wyczerpać swój kwant tylko wtedy, gdy może kontynuować przetwarzanie kodu SQL Server przez 4 ms bez konieczności posiadania zasobu, który posiada inny wątek — bez czekania na blokady, zatrzaskiwanie stron, strony plików danych do odczytania z dysku, alokacje pamięci, przyrosty plików, rejestrowanie lub mnóstwo innych zasobów, których może potrzebować wątek.
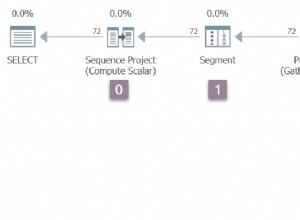
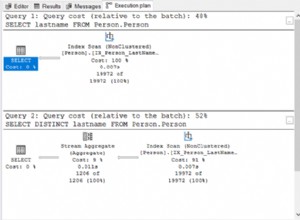
Najczęstszym fragmentem kodu, w którym może wystąpić wyczerpanie kwantowe i skutkować dużymi oczekiwaniem na SOS_SCHEDULER_YIELD, jest skanowanie indeksu/tabeli, w której wszystkie niezbędne strony plików danych znajdują się w pamięci i nie ma rywalizacji o dostęp do tych stron, i to właśnie Zachęcam do szukania w planach zapytań, gdy widzisz SOS_SCHEDULER_YIELD jako najwyższy typ oczekiwania – duże i/lub powtarzające się skany indeksu/tabeli.
Nie oznacza to, że mówię, że duże skany są złe, ponieważ może się okazać, że najskuteczniejszym sposobem przetwarzania obciążenia jest skanowanie. Jeśli jednak oczekiwania SOS_SCHEDULER_YIELD są nowe i nietypowe oraz są spowodowane dużymi skanami, należy zbadać, dlaczego plany kwerend używają skanów. Być może ktoś upuścił krytyczny indeks nieklastrowany lub statystyki są nieaktualne i dlatego wybrano nieprawidłowy plan zapytania, albo może do procedury składowanej została przekazana nietypowa wartość parametru, a plan zapytania wywołał skanowanie lub zmianę kodu wystąpiły bez obsługi dodawania indeksów.
Podsumowanie
Podobnie jak w przypadku innych typów oczekiwania, dokładne zrozumienie, co oznacza SOS_SCHEDULER_YIELD, jest kluczem do zrozumienia, jak go rozwiązywać i czy zachowanie jest oczekiwane z powodu przetwarzanego obciążenia.
Jeśli chodzi o ogólne statystyki oczekiwania, więcej informacji na temat ich używania do rozwiązywania problemów z wydajnością znajdziesz w:
- Moja seria wpisów na blogu SQLskills, zaczynająca się od statystyk Wait lub proszę powiedz mi, gdzie to boli
- Moja biblioteka typów Wait Types i Latch Classes tutaj
- Mój kurs szkoleniowy online Pluralsight SQL Server:Rozwiązywanie problemów z wydajnością za pomocą statystyk oczekiwania
- Doradca wydajności SQL Sentry
W następnym artykule z tej serii omówię inny typ oczekiwania, który jest częstą przyczyną odruchowych reakcji. Do tego czasu życzę miłego rozwiązywania problemów!