Ogólnie rzecz biorąc, ludzie nie lubią otrzymywać niechcianych wiadomości e-mail. Niemniej jednak czasami subskrybują biuletyny, aby uzyskać zniżkę lub być na bieżąco z nowymi produktami. W tym artykule przedstawimy jedno podejście do projektowania bazy danych biuletynów.
Po co martwić się wiadomościami e-mail z biuletynami?
Subskrybenci newslettera stanowią niezwykle cenną grupę klientów – są zainteresowani naszymi produktami, ufają nam, poświęcają czas na przeglądanie naszych ofert i promocji. Co więcej, wysyłanie e-maili do klientów to jedno z najtańszych narzędzi w marketingu internetowym. Jednak należy to robić ostrożnie – dane muszą być aktualizowane codziennie (ponieważ ludzie subskrybują i rezygnują z subskrypcji) i być wysokiej jakości (nie chcemy wysyłać niechcianych wiadomości e-mail, ponieważ negatywnie wpływa to na wizerunek marki).
Powstaje więc pytanie, jak zarządzać tym procesem uzyskiwania wysokiej jakości danych i codziennego ich aktualizowania. Istnieje wiele opcji ...
A zwycięzcą jest...
Analityka klientów! W dzisiejszych czasach najważniejszym czynnikiem pozwalającym wyprzedzić konkurencję jest znajdowanie spostrzeżeń z danych i podejmowanie na ich podstawie decyzji biznesowych. Czy nie byłoby wspaniale przejrzeć historię wysyłek newsletterów i przeanalizować ich intensywność i skuteczność? Dla każdego klienta? A potem połączyć go z danymi zakupowymi, odkryć zainteresowania klienta, przygotować indywidualne rekomendacje i wysłać je na spersonalizowane maile?
Takie podejście z pewnością zwiększyłoby nasz współczynnik konwersji (CR). Współczynnik konwersji jest jednym z najważniejszych kluczowych wskaźników wydajności marketingu internetowego; pokazuje, ile osób dokonuje zakupu po obejrzeniu niektórych naszych materiałów promocyjnych (reklam, biuletynów itp.). Wysoki CR oznacza zwiększoną efektywność biznesową.
Teraz, gdy rozumiemy część działań marketingowych, przejdźmy do modelu danych!
Zacznijmy modelować bazę danych biuletynów!
Zagłębiając się, widzimy, że dwie główne tabele w modelu to client i newsletter tabele.
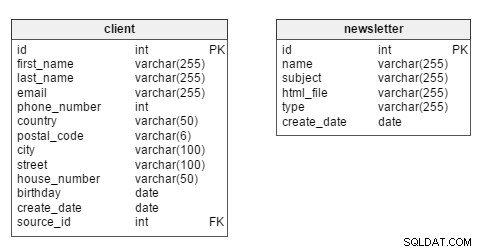
Ponieważ najbardziej interesuje nas analiza klienta, client stół powinien pozostać na środku modelu. W tej tabeli każdy klient ma swój unikalny id . Przechowujemy również takie informacje, jak first_name klienta i last_name , informacje kontaktowe (email , phone_number , adres), birthday , create_date (kiedy rekord klienta został wprowadzony do bazy danych) i jego source_id – tj. czy zarejestrowali się na naszej stronie, czy jakiś partner biznesowy przekazał nam swoje dane.
newsletter tabela przechowuje dane dotyczące każdego stworzenia newslettera. Biuletyny można zidentyfikować na podstawie ich unikalnego id . Każdy jest opisany przez name (np. „Nowa kolekcja odzieży damskiej – jesień 2016”), e-mail subject („Najmodniejsze ubrania dla niej – kup teraz!”), html_file (plik zawierający kod HTML dla tego konkretnego biuletynu), newsletter type (np. „nowa kolekcja”, „biuletyn urodzinowy”) i create_date .
Zgody marketingowe
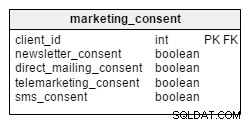
Aby wysłać informacje marketingowe (pocztą, telefonem, e-mailem lub SMS-em), firma musi uzyskać zgodę swoich klientów. W naszym modelu zgody są przechowywane w osobnej tabeli o nazwie marketing_consent . Przechowuje informację o aktualnym zestawie zgód marketingowych dla wszystkich naszych klientów. Zgody są kodowane jako zmienne logiczne – PRAWDA (zgadza się na komunikację marketingową) lub FAŁSZ (nie zgadza się).
Bardzo ważne jest przechowywanie informacji o tym, kiedy klient wyraził zgodę na otrzymywanie reklam każdym kanałem komunikacji. Warto również odnotować, kiedy wycofali zgodę na każdy kanał. W tym celu consent_change stół został zaprojektowany.
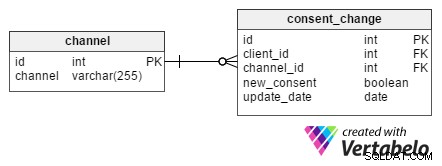
Każda zmiana ma unikalny id i jest przypisany do konkretnego klienta przez jego client_id . Gdy klient zażąda usunięcia z wiadomości e-mail z biuletynem, biuletyn id z channel tabela będzie również przechowywana w consent_change channel_id tabeli atrybut. new_consent atrybut jest wartością logiczną (PRAWDA lub FAŁSZ) i reprezentuje nowe zgody marketingowe.
update_date kolumna zawiera datę, kiedy klient zażądał zmiany. Taka struktura pozwala nam wydobyć komplet zgód dla wszystkich klientów w danym dniu. Jest to niezwykle przydatne, gdy klient skarży się na otrzymanie wiadomości e-mail po tym, jak wypisał się już z naszego newslettera. Dzięki tym informacjom możemy sprawdzić, kiedy anulowano subskrypcję i mamy nadzieję, że zostało to zrobione po wysłaniu biuletynu e-mail.
Utrzymywanie porządku w wysyłkach
Zaprojektowanie idealnego modelu bazy danych do wysyłki biuletynów to nie bułka z masłem. Czemu? Cóż, oczywiście musimy być w stanie zidentyfikować każdy pojedynczy biuletyn (czyli układ, grafika, produkty, linki itp.). Wiemy też, że jedną kreację można wysłać wielokrotnie:menedżerowie mogą zdecydować, że rano jedno wiadro e-maili zostanie wysłane do połowy klientów, a wieczorem do drugiej połowy. Dlatego ważne jest, aby rejestrować, którzy klienci otrzymali jaki biuletyn i kiedy. Dlatego ta część modelu składa się z trzech tabel:
newslettertabela – którą opisaliśmy wcześniej.newsletter_sendouttabela – identyfikująca pojedynczą wysyłkę. Na przykład biuletyn bożonarodzeniowy (id =„2512”) został wysłany 10 grudnia o godzinie 18:00. Ta ewidencja umożliwia marketerom wysyłanie tego samego biuletynu do oddzielnych grup klientów w różnym czasie.- Odbiorniki
sendout_receiverstabela – zbierająca dane o odbiorcach każdej wysyłki. Dla każdego e-maila z każdego rozesłania będzie jeden rekord. Każdy wiersz ma trzy kolumny:id(identyfikujący zdarzenie wysłania e-maila do klienta),client_id(identyfikujący klientów z naszej bazy danych) inl_sendout_id(identyfikacja wysyłki biuletynu).
Oto kompletny model biuletynu:
Masz pomysły, jak ulepszyć ten model?
Jednym z możliwych sposobów jest dodanie response stół. W ten sposób przechowywane byłyby reakcje klientów – niezależnie od tego, czy otworzyli wiadomość e-mail, kliknęli reklamę, czy też nigdy nie zobaczyli wiadomości, ponieważ została ona oznaczona jako spam. Gdzie powinniśmy dodać response tabeli do naszego modelu i jaką relację zastosować? Podziel się swoimi przemyśleniami w sekcji komentarzy poniżej.