Zdarzenie cykliczne z definicji jest zdarzeniem powtarzającym się w określonych odstępach czasu; nazywa się to również wydarzeniem okresowym. Istnieje wiele aplikacji, które umożliwiają swoim użytkownikom konfigurowanie powtarzających się wydarzeń. Jak system baz danych zarządza zdarzeniami cyklicznymi? W tym artykule omówimy jeden ze sposobów ich obsługi.
Aplikacje nie są łatwe do radzenia sobie z nawrotami. Może stać się zadaniem huraganu, zwłaszcza jeśli chodzi o pokrycie każdego możliwego powtarzającego się scenariusza – w tym tworzenie wydarzeń dwutygodniowych lub kwartalnych lub umożliwienie zmiany harmonogramu wszystkich przyszłych wystąpień wydarzeń.
Dwa sposoby zarządzania powtarzającymi się wydarzeniami
Przychodzą mi do głowy co najmniej dwa sposoby obsługi zadań okresowych w modelu danych. Zanim je omówimy, przejrzyjmy szybko wymagania tego zadania. Krótko mówiąc, skuteczne zarządzanie oznacza:
- Użytkownicy mogą tworzyć regularne i cykliczne wydarzenia.
- Dzienne, tygodniowe, dwutygodniowe, miesięczne, kwartalne, dwuletnie i roczne wydarzenia można tworzyć bez ograniczeń dotyczących daty zakończenia.
- Użytkownicy mogą przełożyć lub anulować wystąpienie wydarzenia lub wszystkie przyszłe wystąpienia wydarzenia.
Biorąc pod uwagę te parametry, przychodzą na myśl dwa sposoby zarządzania powtarzającymi się zdarzeniami w modelu danych. Nazwiemy je naiwnym i eksperckim sposobem.
Naiwny sposób: Przechowywanie wszystkich możliwych powtarzających się wystąpień zdarzenia jako oddzielnych wierszy w tabeli. W tym rozwiązaniu potrzebujemy tylko jednej tabeli, a mianowicie event . Ta tabela zawiera kolumny, takie jak event_title , start_date , end_date , is_full_day_event itp. start_date i end_date kolumny są typami danych znaczników czasu; w ten sposób mogą pomieścić wydarzenia, które nie trwają cały dzień.
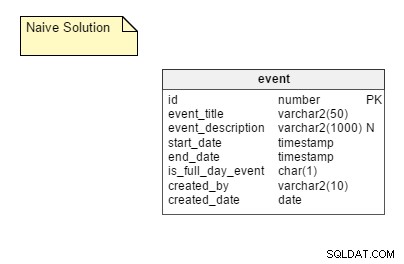
Zalety: Jest to dość proste podejście i najprostsze do wdrożenia.
Wady: Naiwny sposób ma kilka istotnych wad, w tym:
- Konieczność przechowywania wszystkich możliwych wystąpień wydarzenia. Jeśli bierzesz pod uwagę potrzeby dużej bazy użytkowników, wymagana jest duża ilość miejsca. Jednak przestrzeń jest dość tania, więc ten punkt nie ma większego wpływu.
- Bardzo brudny proces aktualizacji. Załóżmy, że wydarzenie zostało przełożone. W takim przypadku ktoś musi zaktualizować wszystkie jego wystąpienia. Podczas zmiany harmonogramu należy wykonać ogromną liczbę operacji DML, co ma negatywny wpływ na wydajność aplikacji.
- Obsługa wyjątków. Wszystkie wyjątki muszą być obsługiwane z wdziękiem, zwłaszcza jeśli musisz wrócić i edytować pierwotne spotkanie po dokonaniu wyjątku. Załóżmy na przykład, że przesuniesz trzecie wystąpienie wydarzenia cyklicznego do przodu o jeden dzień. Co się stanie, jeśli później zmienisz czas oryginalnego wydarzenia? Czy wstawiasz ponownie inne wydarzenie z pierwotnego dnia i zostawiasz to, które przyniosłeś? Odłączyć wyjątek? Spróbuj to odpowiednio zmienić?
Event_id– Ta kolumna pochodzi zeventtabeli i działa jako klucz podstawowy w tej tabeli. Pokazuje identyfikującą relację międzyeventirecurring_patterntabele. Ta kolumna zapewni również, że dla każdego zdarzenia istnieje maksymalnie jeden powtarzający się wzorzec.Recurring_type_id– Ta kolumna oznacza rodzaj nawrotu, niezależnie od tego, czy jest to dzień, tydzień, miesiąc czy rok.Max_num_of_occurrances– Są chwile, kiedy nie znamy dokładnej daty zakończenia wydarzenia, ale wiemy, ile wystąpień (spotkań) jest potrzebnych do jego zakończenia. Ta kolumna przechowuje dowolną liczbę, która definiuje logiczny koniec zdarzenia.Separation_count– Być może zastanawiasz się, jak można skonfigurować wydarzenie dwutygodniowe lub dwuletnie, jeśli istnieją tylko cztery możliwe wartości typu cyklicznego (dzienne, tygodniowe, miesięczne, roczne). Odpowiedzią jestseparation_countkolumna. Ta kolumna oznacza interwał (w dniach, tygodniach lub miesiącach) przed dopuszczeniem następnej instancji zdarzenia. Na przykład, jeśli wydarzenie musi być skonfigurowane co drugi tydzień, to separation_count =„1” aby spełnić ten wymóg. Domyślna wartość tej kolumny to „0”.recurring_type_idbyłoby „co tydzień”.separation_countbyłoby „1”.day_of_weekbyłoby „2”.Week_of_month– Ta kolumna dotyczy wydarzeń, które są zaplanowane na określony tydzień miesiąca – tj. pierwszy, drugi, ostatni, przedostatni itd. Możemy przechowywać te wartości jako 1,2,3, 4,.. (licząc od początku miesiąca) lub -1,-2,-3,... (licząc od końca miesiąca).Day_of_month– Zdarzają się przypadki, kiedy impreza jest zaplanowana na konkretny dzień miesiąca, powiedzmy 25. Ta kolumna spełnia ten wymóg. Jakweek_of_month, może być wypełniony liczbami dodatnimi („7” dla siódmego dnia od początku miesiąca) lub liczbami ujemnymi („-7” dla siódmego dnia od końca miesiąca).recurring_type_idbyłoby „comiesięczne”.separation_countbyłoby „2”.day_of_monthbyłoby „11”.- Wszystkie pozostałe kolumny byłyby puste.
- Wydarzenia, które mają miejsce w święta. Kiedy dana instancja zdarzenia ma miejsce w dzień ustawowo wolny od pracy, czy powinna być automatycznie przeniesiona na dzień roboczy następujący bezpośrednio po tym święcie? A może powinna zostać automatycznie anulowana? W jakich okolicznościach miałoby zastosowanie którekolwiek z tych warunków?
- Konflikty między wydarzeniami. Co się stanie, jeśli pewne wydarzenia (które wzajemnie się wykluczają) przypadają tego samego dnia?
Ekspercki sposób: Przechowywanie powtarzającego się wzorca i programowe generowanie przeszłych i przyszłych wystąpień zdarzeń. To rozwiązanie rozwiązuje wady naiwnego rozwiązania. Szczegółowo wyjaśnimy rozwiązanie eksperckie w tym artykule.
Proponowany model
Tworzenie wydarzeń
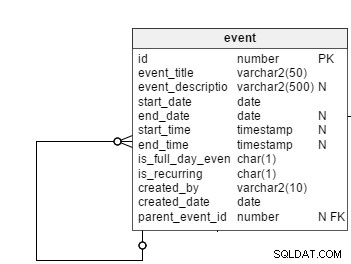
Wszystkie zaplanowane wydarzenia, niezależnie od ich regularnego lub cyklicznego charakteru, są rejestrowane w event stół. Nie wszystkie wydarzenia są wydarzeniami cyklicznymi, więc będziemy potrzebować kolumny z flagą, is_recurring , w tej tabeli, aby jawnie określić zdarzenia cykliczne. event_title i event_description kolumny przechowują temat i krótkie podsumowanie wydarzeń. Opisy zdarzeń są opcjonalne, dlatego ta kolumna dopuszcza wartość null.
Jak sugerują ich nazwy, start_date i end_date kolumny przechowują daty rozpoczęcia i zakończenia wydarzeń. W przypadku wydarzeń regularnych w tych kolumnach przechowywane są rzeczywiste daty rozpoczęcia i zakończenia. Przechowują jednak również daty pierwszego i ostatniego wystąpienia zdarzeń okresowych. Zachowamy end_date jako dopuszczalną wartość null, ponieważ użytkownicy mogą konfigurować zdarzenia cykliczne bez daty zakończenia. W takim przypadku przyszłe zdarzenia do hipotetycznej daty zakończenia (np. dla roku) będą wyświetlane w interfejsie użytkownika.
is_full_date_event kolumna wskazuje, czy wydarzenie jest wydarzeniem całodniowym. W przypadku wydarzenia całodniowego start_time i end_time kolumny byłyby puste; to jest powód, aby obie te kolumny mogły mieć wartość null.
created_by i created_date kolumny przechowują informację, który użytkownik utworzył wydarzenie i datę utworzenia wydarzenia.
Dalej jest parent_event_id kolumna. Odgrywa to główną rolę w naszym modelu danych. Jego znaczenie wyjaśnię później.
Zarządzanie nawrotami
Teraz przechodzimy od razu do głównego stwierdzenia problemu:Co się stanie, jeśli wydarzenie cykliczne zostanie utworzone w event tabela – czyli is_recurring flagą wydarzenia jest „Y”?
Jak wyjaśniono wcześniej, będziemy przechowywać powtarzający się wzór zdarzeń, abyśmy mogli skonstruować wszystkie jego przyszłe wystąpienia. Zacznijmy od utworzenia recurring_pattern stół. Ta tabela zawiera następujące kolumny:
Rozważmy znaczenie pozostałych kolumn pod względem różnych typów nawrotów.
Codzienny cykl
Czy naprawdę musimy uchwycić wzór na codzienne powtarzające się wydarzenie? Nie, ponieważ wszystkie szczegóły wymagane do wygenerowania dziennego wzorca powtarzalności są już zarejestrowane w event tabela.
Jedynym scenariuszem, który wymaga wzorca, jest planowanie wydarzeń na kolejne dni lub co X dni. W tym przypadku separation_count kolumna pomoże nam zrozumieć wzorzec powtarzania i wyprowadzić dalsze instancje.
Cotygodniowy cykl
Wymagamy tylko jednej dodatkowej kolumny, day_of_week , aby zapisać, w którym dniu tygodnia odbędzie się to wydarzenie. Zakładając, że poniedziałek jest pierwszym dniem tygodnia, a niedziela ostatnim, możliwe wartości to 1,2,3,4,5,6 i 7. W razie potrzeby należy wprowadzić odpowiednie zmiany w kodzie generującym poszczególne zdarzenia. Wszystkie pozostałe kolumny miałyby wartość NULL dla wydarzeń cotygodniowych.
Weźmy klasyczny typ cotygodniowego wydarzenia:co dwa tygodnie. W tym przypadku powiemy, że dzieje się to co drugi tydzień we wtorek, drugiego dnia tygodnia. A więc:

Powtórka miesięczna
Poza day_of_week , potrzebujemy dwóch dodatkowych kolumn, aby spełnić dowolny scenariusz miesięcznych cykli. W skrócie, te kolumny to:
Rozważmy teraz bardziej skomplikowany przykład – wydarzenie kwartalne. Załóżmy, że firma planuje kwartalną projekcję wyników na 11 dzień pierwszego miesiąca w każdym kwartale (zwykle w styczniu, kwietniu, lipcu i październiku). Więc w tym przypadku:
W powyższym przykładzie zakładamy, że użytkownik tworzy projekcję wyników kwartalnych w styczniu. Pamiętaj, że ta logika separacji zacznie odliczać od miesiąca, tygodnia lub dnia, w którym wydarzenie zostało utworzone.
Na podobnych liniach wydarzenia półroczne mogą być rejestrowane jako wydarzenia miesięczne z
Nawrót roczny jest dość prosty. Mamy kolumny dla poszczególnych dni tygodnia i miesiąca, więc potrzebujemy tylko jednej dodatkowej kolumny dla miesiąca roku. Nazwaliśmy tę kolumnę
Przejdźmy teraz do wyjątków. Co się stanie, jeśli określone wystąpienie wydarzenia cyklicznego zostanie anulowane lub przełożone? Wszystkie takie przypadki są rejestrowane osobno w
Przyjrzyjmy się dwóm kolumnom,
Oprócz tych dwóch kolumn, wszystkie pozostałe kolumny działają tak samo, jak w
Istnieją aplikacje, które pozwalają użytkownikom na zmianę harmonogramu wszystkich przyszłych wystąpień cyklicznego wydarzenia. W takich przypadkach mamy dwie możliwości. Wszystkie przyszłe instancje możemy przechowywać w
Dzięki temu rozwiązaniu możemy uzyskać wszystkie przeszłe wystąpienia zdarzenia, nawet jeśli jego wzorzec powtarzalności został zmieniony.
Istnieje kilka bardziej złożonych obszarów związanych z powtarzającymi się wydarzeniami, których nie omawialiśmy. Oto dwa:
Jakie zmiany musimy wprowadzić, aby wbudować te zdolności? Podziel się z nami swoimi opiniami w sekcji komentarzy.separation_count z „5”.
Nawrót roczny
month_of_year .
Obsługa wyjątków powtarzających się wydarzeń
event_instance_exception stół. Is_rescheduled i is_cancelled . Kolumny te wskazują, czy ta instancja została przesunięta na późniejszą datę/godzinę, czy też została całkowicie anulowana. Dlaczego mam do tego dwie oddzielne kolumny? Pomyśl tylko o wydarzeniach, które najpierw zostały przełożone, a potem całkowicie odwołane. Tak się dzieje, a my mamy sposób na zapisanie tego za pomocą tych kolumn. event tabela.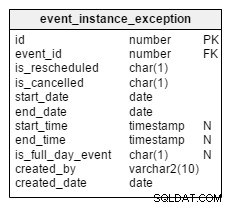
Po co łączyć dwa zdarzenia za pomocą
parent_event_id ?event_instance_exception (wskazówka:rozwiązanie nie do przyjęcia). Lub możemy utworzyć nowe wydarzenie z nowymi parametrami daty/czasu w event tabeli i powiązać ją z jej wcześniejszym zdarzeniem (zdarzeniem nadrzędnym) za pomocą id_parent_event kolumna. Jak poprawić obsługę zdarzeń cyklicznych?