Od dawna jestem zwolennikiem wyboru właściwego typu danych. Mówiłem o kilku przykładach w poprzednim poście na blogu „Bad Habits”, ale w ten weekend na SQL Saturday #162 (Cambridge, Wielka Brytania), temat używania DATETIME domyślnie pojawił się. W rozmowie po mojej prezentacji T-SQL :Bad Habits and Best Practices, użytkownik stwierdził, że po prostu używa DATETIME nawet jeśli potrzebują tylko dokładności co do minuty lub dnia, w ten sposób kolumny daty/godziny w całym przedsiębiorstwie mają zawsze ten sam typ danych. Zasugerowałem, że to może być marnotrawstwo i że spójność może nie być tego warta, ale dzisiaj postanowiłem udowodnić swoją teorię.
TL;DR wersja
Moje testy poniżej pokazują, że z pewnością istnieją scenariusze, w których warto rozważyć użycie cieńszego typu danych zamiast trzymać się DATETIME wszędzie. Ale ważne jest, aby zobaczyć, gdzie moje testy w tym kierunku wskazywały w drugą stronę, a także ważne jest, aby przetestować te scenariusze na schemacie, w swoim środowisku, przy użyciu sprzętu i danych, które są jak najbardziej zgodne z produkcją. Twoje wyniki mogą i prawie na pewno będą się różnić.
Tabele docelowe
Rozważmy przypadek, w którym ziarnistość jest ważna tylko do dnia (nie interesują nas godziny, minuty, sekundy). W tym celu możemy wybrać DATETIME (jak zaproponowany przez użytkownika) lub SMALLDATETIME lub DATE na SQL Server 2008+. Istnieją również dwa różne typy danych, które chciałem wziąć pod uwagę:
- Dane, które byłyby wstawiane z grubsza sekwencyjnie w czasie rzeczywistym (np. wydarzenia, które mają miejsce w tej chwili);
- Dane, które byłyby wstawiane losowo (np. daty urodzin nowych członków).
Zacząłem od 2 tabel takich jak poniżej, a następnie utworzyłem 4 kolejne (2 dla SMALLDATETIME, 2 dla DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime(ID INT IDENTITY(1,1) KLUCZ PODSTAWOWY, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime(ID INT IDENTITY(1,1) KLUCZ PODSTAWOWY, dt DATETIME NOT NULL); UTWÓRZ INDEKS d NA dbo.BirthDatesRandom_Datetime(dt); UTWÓRZ INDEKS d NA dbo.EventsSequential_Datetime(dt); -- Następnie powtórz dla DATE i SMALLDATETIME.
Moim celem było przetestowanie wydajności wstawiania wsadowego na te dwa różne sposoby, a także wpływu na ogólny rozmiar i fragmentację pamięci masowej, a wreszcie na wydajność zapytań o zakres.
Przykładowe dane
Aby wygenerować przykładowe dane, użyłem jednej z moich przydatnych technik generowania czegoś znaczącego z czegoś, co nie jest:widoków katalogu. W moim systemie zwróciło to 971 odrębnych wartości daty/czasu (łącznie 1 000 000 wierszy) w ciągu około 12 sekund:
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) SELECT DISTINCT d FROM y;
Umieściłem te miliony wierszy w tabeli, aby móc symulować sekwencyjne/losowe wstawianie przy użyciu różnych metod dostępu dla dokładnie tych samych danych z trzech różnych okien sesji:
CREATE TABLE dbo.Staging(ID INT IDENTITY(1,1) PRIMARY KEY, data_źródłowa DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID()) INSERT dbo.Staging(source_data) SELECT dt FROM y ORDER BY dt;
Ten proces trwał nieco dłużej (20 sekund). Następnie utworzyłem drugą tabelę do przechowywania tych samych danych, ale dystrybuowanych losowo (abym mógł powtórzyć ten sam rozkład we wszystkich wstawkach).
CREATE TABLE dbo.Staging_Random(ID INT IDENTITY(1,1) PRIMARY KEY, data_źródła DATETIME NOT NULL); INSERT dbo.Staging_Random(data_źródłowa) SELECT data_źródłowa FROM dbo.Staging ORDER BY NEWID();
Zapytania do wypełnienia tabel
Następnie napisałem zestaw zapytań, aby wypełnić inne tabele tymi danymi, używając trzech okien zapytań, aby zasymulować przynajmniej odrobinę współbieżności:
CZAS OCZEKIWANIA '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{nazwa_tabeli}(dt) -- w zależności od metody / typu danych SELECT data_źródłowa FROM dbo.Staging[_Random] -- w zależności od celu WHERE ID % 3 =<0,1,2> -- w zależności od okna zapytania ORDER WEDŁUG ID; SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Podobnie jak w moim ostatnim poście, wstępnie rozszerzyłem bazę danych, aby zapobiec zakłócaniu wyników przez wszelkiego rodzaju zdarzenia związane z automatycznym wzrostem plików danych. Zdaję sobie sprawę, że wykonywanie wstawiania milionów wierszy w jednym przebiegu nie jest całkowicie realistyczne, ponieważ nie mogę zapobiec zakłócaniu aktywności dziennika dla tak dużej transakcji, ale powinno to robić konsekwentnie w każdej metodzie. Biorąc pod uwagę, że sprzęt, na którym testuję, jest zupełnie inny niż sprzęt, którego używasz, bezwzględne wyniki nie powinny być kluczową kwestią, a jedynie względne porównanie.
(W przyszłym teście wypróbuję to również z prawdziwymi partiami pochodzącymi z plików dziennika ze stosunkowo mieszanymi danymi i używając fragmentów tabeli źródłowej w pętlach – myślę, że to również byłyby interesujące eksperymenty. I oczywiście dodanie kompresja do miksu).
Wyniki:
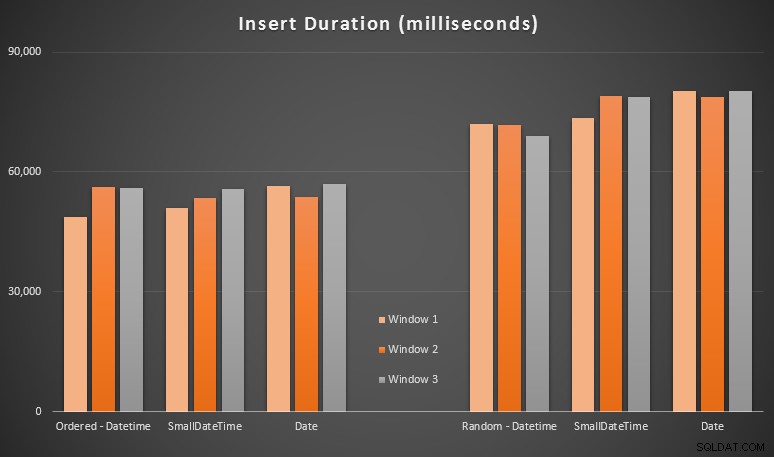
Te wyniki nie były dla mnie aż tak zaskakujące – wstawianie w losowej kolejności prowadziło do dłuższych czasów działania niż wstawianie sekwencyjne, co wszyscy możemy cofnąć do naszych korzeni zrozumienia, jak działają indeksy w SQL Server i jak więcej „złych” podziałów stron może się zdarzyć w ten scenariusz (w tym ćwiczeniu nie monitorowałem specjalnie podziałów stron, ale rozważę to w przyszłych testach).
Zauważyłem, że po stronie losowej niejawne konwersje przychodzących danych mogły mieć wpływ na czasy, ponieważ wydawały się nieco wyższe niż natywne DATETIME -> DATETIME wstawki. Postanowiłem więc zbudować dwie nowe tabele zawierające dane źródłowe:jedną za pomocą DATE i jeden używający SMALLDATETIME . Do pewnego stopnia symulowałoby to poprawną konwersję typu danych przed przekazaniem go do instrukcji INSERT, tak że niejawna konwersja nie jest wymagana podczas wstawiania. Oto nowe tabele i sposób ich wypełnienia:
CREATE TABLE dbo.Staging_Random_SmallDatetime(ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date (ID INT IDENTITY (1,1) KLUCZ PODSTAWOWY, data_źródłowa DATA NIE NULL); INSERT dbo.Staging_Random_SmallDatetime(data_źródłowa) SELECT CONVERT (SMALLDATETIME, source_data) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(data_źródłowa) SELECT CONVERT(DATA,data_źródłowa) FROM dbo.Staging_Random ORDER BY ID;
Nie przyniosło to efektu, na który liczyłem – czasy były podobne we wszystkich przypadkach. Więc to była pogoń za dziką gęsią.
Wykorzystana przestrzeń i fragmentacja
Uruchomiłem następujące zapytanie, aby określić, ile stron zostało zarezerwowanych dla każdej tabeli:
WYBIERZ nazwa ='dbo.' + OBJECT_NAME([object_id]), strony =SUMA(reserved_page_count)FROM sys.dm_db_partition_stats GRUPA WG OBJECT_NAME([object_id])ORDER WG stron;
Wyniki:
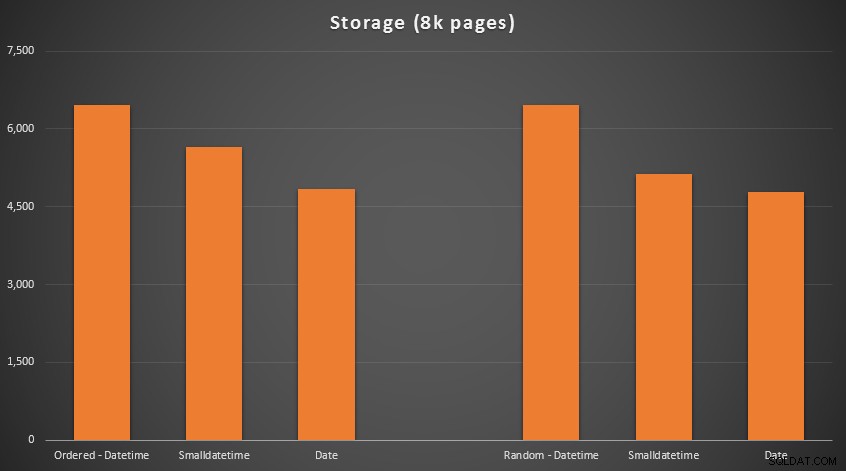
Nie ma tu nauki o rakietach; użyj mniejszego typu danych, powinieneś użyć mniejszej liczby stron. Przełączanie z DATETIME do DATE konsekwentnie przyniósł 25% zmniejszenie liczby używanych stron, podczas gdy SMALLDATETIME zmniejszyło zapotrzebowanie o 13-20%.
Teraz dla fragmentacji i zagęszczenia stron w indeksach nieklastrowych (w przypadku indeksów klastrowych była bardzo niewielka różnica):
SELECT '{nazwa_tabeli}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILED_ID =0; I indeks_id =2 /pre>
Wyniki:
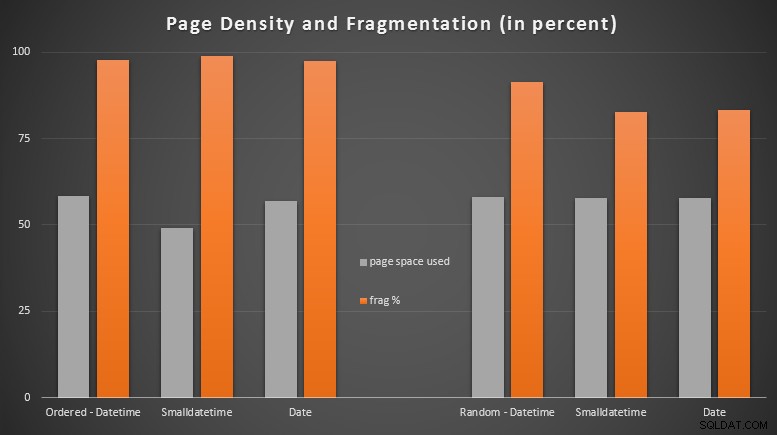
Byłem dość zaskoczony, widząc, że uporządkowane dane stają się prawie całkowicie pofragmentowane, podczas gdy dane wstawiane losowo faktycznie kończyły się nieco lepszym wykorzystaniem strony. Zauważyłem, że gwarantuje to dalsze badania poza zakresem tych konkretnych testów, ale może to być coś, co warto sprawdzić, jeśli masz indeksy nieklastrowane, które opierają się w dużej mierze na wstawkach sekwencyjnych.
[Przebudowa online indeksów nieklastrowanych we wszystkich 6 tabelach przebiegła w ciągu 7 sekund, przywracając gęstość stron z powrotem do zakresu 99,5% i zmniejszając fragmentację do poniżej 1%. Ale nie uruchomiłem tego, dopóki nie wykonałem poniższych testów zapytań…]
Test zapytania o zakres
Na koniec chciałem zobaczyć wpływ na czasy wykonywania prostych zapytań o zakres dat względem różnych indeksów, zarówno z nieodłączną fragmentacją spowodowaną aktywnością zapisu typu OLTP, jak i czystym indeksem, który jest odbudowywany. Samo zapytanie jest dość proste:
SELECT TOP (200000) dt FROM dbo.{nazwa_tabeli} WHERE dt>='20110101' ORDER BY dt;
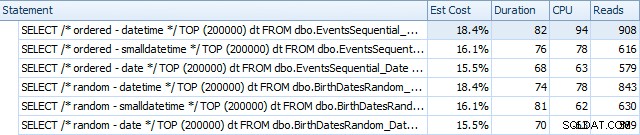
Oto wyniki przed przebudowaniem indeksów za pomocą programu SQL Sentry Plan Explorer:
I różnią się nieco po przebudowach:
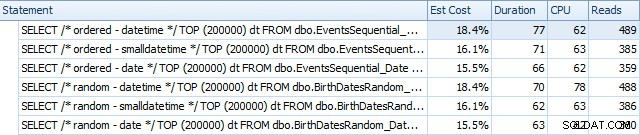
Zasadniczo widzimy nieco dłuższy czas trwania i odczyty dla wersji DATETIME, ale bardzo małą różnicę w CPU. A różnice między SMALLDATETIME i DATE są w porównaniu znikome. Wszystkie zapytania miały uproszczone plany zapytań, takie jak:

(Wyszukiwanie jest oczywiście uporządkowanym skanowaniem zakresu).
Wniosek
Chociaż wprawdzie te testy są dość sfabrykowane i mogłyby skorzystać na większej liczbie permutacji, pokazują z grubsza to, co spodziewałem się zobaczyć:największy wpływ na ten konkretny wybór ma miejsce zajmowane przez indeks nieklastrowany (gdzie wybór cieńszego typu danych będzie z pewnością korzyści) oraz na czas wymagany do wykonania wstawiania w dowolnej, a nie sekwencyjnej kolejności (gdzie DATETIME ma tylko marginalną krawędź).
Chętnie poznam twoje pomysły, jak wprowadzić takie wybory typu danych do bardziej dokładnych i wyczerpujących testów. Planuję omówić więcej szczegółów w przyszłych postach.