Najczęstszą potrzebą usunięcia czasu z wartości daty i godziny jest pobranie wszystkich wierszy reprezentujących zamówienia (lub wizyty lub wypadki), które miały miejsce w danym dniu. Jednak nie wszystkie techniki, które są do tego wykorzystywane, są skuteczne, a nawet bezpieczne.
TL;DR wersja
Jeśli chcesz, aby zapytanie o bezpieczny zakres działało dobrze, użyj zakresu otwartego lub, w przypadku zapytań jednodniowych w SQL Server 2008 i nowszych, użyj CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Niektóre zastrzeżenia:
- Uważaj na
DATEDIFFpodejście, ponieważ mogą wystąpić pewne anomalie szacowania kardynalności (zobacz ten wpis na blogu i pytanie o przepełnienie stosu, które go zachęciło, aby uzyskać więcej informacji). - Podczas gdy ostatnie z nich nadal potencjalnie będzie korzystać z wyszukiwania indeksu (w przeciwieństwie do każdego innego wyrażenia, które nie jest argowalne), przed porównaniem należy zachować ostrożność przy konwersji kolumny na datę. Takie podejście również może prowadzić do fundamentalnie błędnych szacunków kardynalności. Zobacz odpowiedź Martina Smitha, aby uzyskać więcej informacji.
W każdym razie czytaj dalej, aby zrozumieć, dlaczego są to jedyne dwa podejścia, jakie kiedykolwiek polecam.
Nie wszystkie podejścia są bezpieczne
Jako niebezpieczny przykład widzę, że ten był często używany:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Jest kilka problemów z tym podejściem, ale najbardziej zauważalnym jest obliczenie „końca” dnia dzisiejszego – jeśli bazowym typem danych jest SMALLDATETIME , ten zakres końcowy zostanie zaokrąglony w górę; jeśli jest DATETIME2 , teoretycznie możesz przegapić dane na koniec dnia. Jeśli wybierzesz minuty, nanosekundy lub jakąkolwiek inną przerwę, aby uwzględnić bieżący typ danych, Twoje zapytanie zacznie zachowywać się dziwnie, jeśli typ danych zmieni się później (i bądźmy szczerzy, jeśli ktoś zmieni typ tej kolumny, aby był bardziej lub mniej szczegółowy, nie biegają, sprawdzając każde zapytanie, które uzyskuje do niego dostęp). Konieczność kodowania w ten sposób w zależności od typu danych daty/godziny w podstawowej kolumnie jest pofragmentowana i podatna na błędy. W tym celu znacznie lepiej jest używać nieograniczonych zakresów dat:
Mówię o tym dużo więcej w kilku starych postach na blogu:
- Co łączy MIĘDZY i diabła?
- Złe nawyki do wyrzucenia:niewłaściwa obsługa zapytań o datę/zakres
Ale chciałem porównać wydajność niektórych z bardziej powszechnych podejść, które tam widzę. Zawsze używałem zakresów otwartych, a od SQL Server 2008 możemy używać CONVERT(DATE) i nadal używa indeksu w tej kolumnie, co jest dość potężne.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Prosty test wydajności
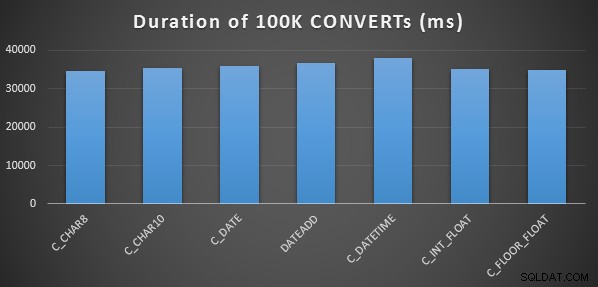
Aby przeprowadzić bardzo prosty wstępny test wydajności, dla każdego z powyższych stwierdzeń wykonałem następujące czynności, ustawiając zmienną na wynik obliczeń 100 000 razy:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Zrobiłem to trzy razy dla każdej metody i wszystkie przebiegły w zakresie 34-38 sekund. Tak więc ściśle mówiąc, różnice w tych metodach przy wykonywaniu operacji w pamięci są bardzo nieistotne:
Bardziej złożony test wydajności
Chciałem również porównać te metody z różnymi typami danych (DATETIME , SMALLDATETIME i DATETIME2 ), zarówno względem indeksu klastrowego, jak i sterty oraz z kompresją danych i bez niej. Więc najpierw stworzyłem prostą bazę danych. Poprzez eksperymenty ustaliłem, że optymalny rozmiar do obsługi 120 milionów wierszy i całej aktywności dziennika, która może się pojawić (i aby zapobiec zakłócaniu testów przez zdarzenia automatycznego wzrostu), to plik danych o wielkości 20 GB i dziennik o pojemności 3 GB:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Następnie utworzyłem 12 tabel:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Następnie powtórz ponownie dla DATETIME i DATETIME2.]
Następnie wstawiłem 10 000 000 wierszy do każdej tabeli. Zrobiłem to, tworząc widok, który za każdym razem generowałby te same 10 000 000 dat:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
To pozwoliło mi wypełnić tabele w ten sposób:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Następnie powtórz ponownie dla stert i nieskompresowanego indeksu klastrowego. Wstawiłem CHECKPOINT między każdą wstawką, aby zapewnić ponowne wykorzystanie dziennika (model odzyskiwania jest prosty).]
WSTAW czasy i wykorzystane miejsce
Oto czasy dla każdej wstawki (zgodnie z zarejestrowaniem w Eksploratorze planów):
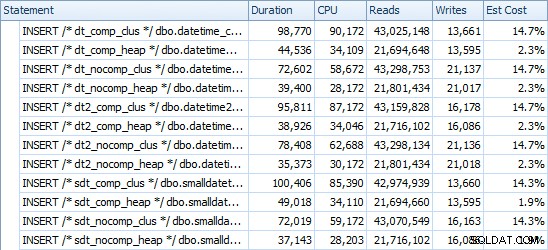
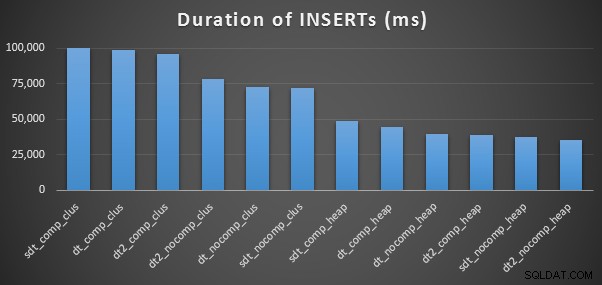
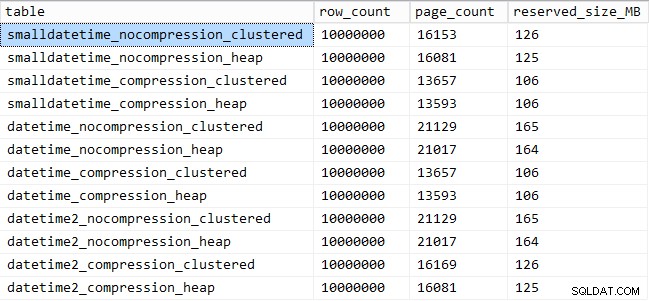
A oto ilość miejsca zajmowanego przez każdy stół:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Wydajność wzorca zapytania
Następnie postanowiłem przetestować dwa różne wzorce zapytań pod kątem wydajności:
- Liczenie wierszy dla określonego dnia, przy użyciu powyższych siedmiu podejść, a także otwartego zakresu dat
- Konwertowanie wszystkich 10 000 000 wierszy przy użyciu powyższych siedmiu podejść, a także zwracanie surowych danych (ponieważ formatowanie po stronie klienta może być lepsze)
[Z wyjątkiem FLOAT metody i DATETIME2 kolumna, ponieważ ta konwersja jest niedozwolona.]
W przypadku pierwszego pytania zapytania wyglądają tak (powtarzane dla każdego typu tabeli):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Wyniki względem indeksu klastrowego wyglądają tak (kliknij, aby powiększyć):
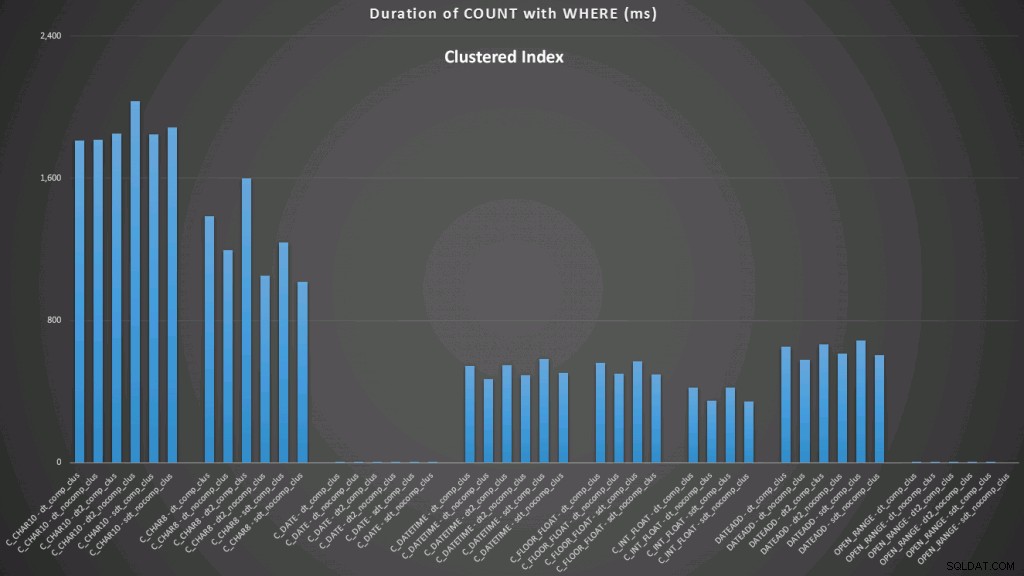
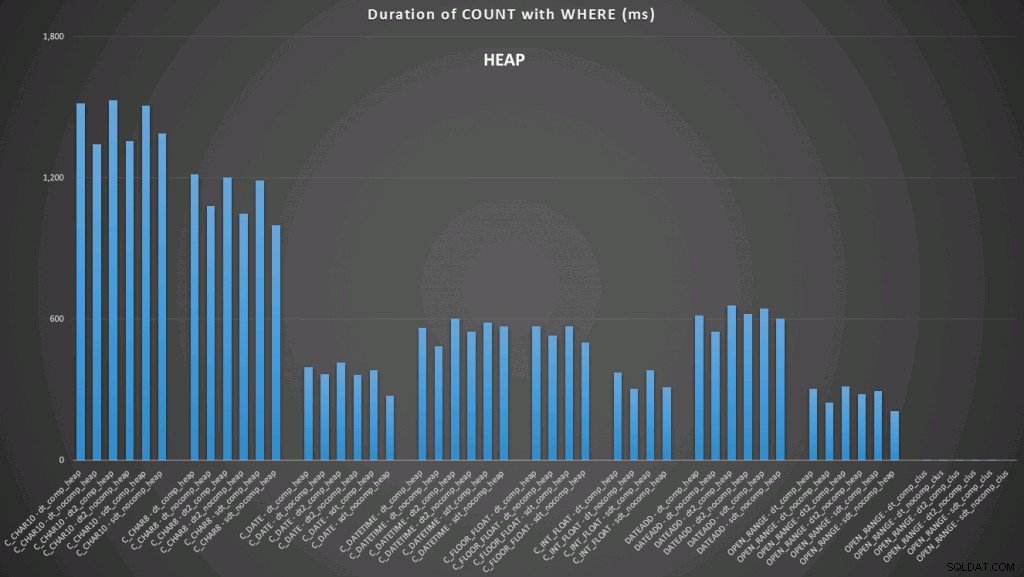
Tutaj widzimy, że konwersja do daty i zakres otwarty przy użyciu indeksu są najlepsze. Jednak w porównaniu ze stosem konwersja do tej pory zajmuje trochę czasu, dzięki czemu zakres otwarty jest optymalnym wyborem (kliknij, aby powiększyć):
A oto drugi zestaw zapytań (znowu powtarzających się dla każdego typu tabeli):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Skupiając się na wynikach dla tabel z indeksem klastrowym, jasne jest, że konwersja do tej pory była bardzo zbliżona do wyboru surowych danych (kliknij, aby powiększyć):
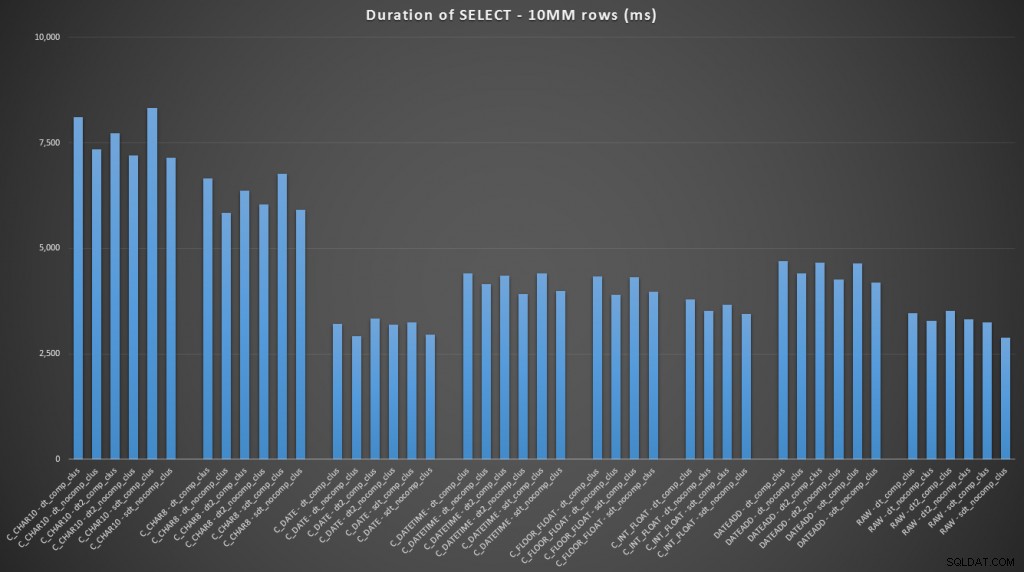
(Dla tego zestawu zapytań stos pokazał bardzo podobne wyniki – praktycznie nie do odróżnienia).
Wniosek
Jeśli chcesz przejść do puenty, wyniki te pokazują, że konwersje w pamięci nie są ważne, ale jeśli konwertujesz dane po wyjściu z tabeli (lub jako część predykatu wyszukiwania), wybrana metoda może mieć dramatyczny wpływ na wydajność. Konwersja na DATE (na jeden dzień) lub użycie nieograniczonego zakresu dat w każdym przypadku zapewni najlepszą wydajność, podczas gdy najpopularniejsza metoda – konwersja na ciąg – jest absolutnie beznadziejna.
Widzimy również, że kompresja może mieć przyzwoity wpływ na przestrzeń dyskową, z bardzo niewielkim wpływem na wydajność zapytań. Wydaje się, że wpływ na wydajność wstawiania zależy od tego, czy tabela ma indeks klastrowy, a nie od tego, czy kompresja jest włączona. Jednak po wstawieniu indeksu klastrowego wystąpił zauważalny wzrost czasu potrzebnego na wstawienie 10 milionów wierszy. Coś, o czym należy pamiętać i zrównoważyć oszczędność miejsca na dysku.
Oczywiście może być o wiele więcej testów, z większymi i bardziej zróżnicowanymi obciążeniami, które omówię dalej w przyszłym poście.