SQL Server tradycyjnie unikał dostarczania natywnych rozwiązań dla niektórych z bardziej powszechnych pytań statystycznych, takich jak obliczanie mediany. Według WikiPedii „mediana jest opisana jako wartość liczbowa oddzielająca wyższą połowę próbki, populacji lub rozkład prawdopodobieństwa od dolnej połowy. Medianę skończonej listy liczb można znaleźć, układając wszystkie obserwacje z od najniższej wartości do najwyższej wartości i wybranie średniej. Jeśli liczba obserwacji jest parzysta, nie ma jednej średniej wartości; mediana jest wtedy zwykle definiowana jako średnia z dwóch średnich wartości."
Jeśli chodzi o zapytanie SQL Server, kluczową rzeczą, którą z tego wyjdziesz, jest to, że musisz „uporządkować” (posortować) wszystkie wartości. Sortowanie w SQL Server jest zazwyczaj dość kosztowną operacją, jeśli nie ma indeksu pomocniczego, a dodanie indeksu do obsługi operacji, która prawdopodobnie nie jest wymagana, co często może nie być opłacalne.
Przyjrzyjmy się, jak zwykle rozwiązywaliśmy ten problem w poprzednich wersjach SQL Server. Najpierw stwórzmy bardzo prostą tabelę, abyśmy mogli stwierdzić, że nasza logika jest poprawna i wyprowadza dokładną medianę. Możemy przetestować następujące dwie tabele, jedną z parzystą liczbą wierszy, a drugą z nieparzystą liczbą wierszy:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Już z pobieżnej obserwacji widzimy, że mediana dla tabeli z nieparzystymi rzędami powinna wynosić 6, a dla tabeli parzystej powinna wynosić 7,5 ((6+9)/2). Zobaczmy teraz kilka rozwiązań, które były używane przez lata:
SQL Server 2000
W SQL Server 2000 byliśmy ograniczeni do bardzo ograniczonego dialektu T-SQL. Badam te opcje dla porównania, ponieważ niektórzy ludzie nadal używają SQL Server 2000, a inni mogli je zaktualizować, ale ponieważ ich średnie obliczenia zostały napisane „w dawnych czasach”, kod może nadal wyglądać tak dzisiaj.
2000_A – max jednej połowy, min drugiej
To podejście bierze najwyższą wartość z pierwszych 50 procent, najniższą wartość z ostatnich 50 procent, a następnie dzieli je przez dwa. Działa to w przypadku parzystych lub nieparzystych wierszy, ponieważ w przypadku parzystym dwie wartości są dwoma środkowymi wierszami, a w przypadku nieparzystym obie wartości pochodzą w rzeczywistości z tego samego wiersza.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #tabela temp
Ten przykład najpierw tworzy tabelę #temp i używając tego samego typu matematyki, co powyżej, określa dwa "środkowe" wiersze z pomocą ciągłej IDENTITY kolumna uporządkowana według kolumny val. (Kolejność przypisywania IDENTITY na wartościach można polegać tylko ze względu na MAXDOP ustawienie.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 wprowadził kilka interesujących nowych funkcji okien, takich jak ROW_NUMBER() , co może pomóc w rozwiązaniu problemów statystycznych, takich jak mediana, nieco łatwiej niż w SQL Server 2000. Wszystkie te podejścia działają w SQL Server 2005 i nowszych:
2005_A – pojedynkowe numery rzędów
W tym przykładzie użyto ROW_NUMBER() chodzić w górę i w dół wartości raz w każdym kierunku, a następnie na podstawie tego obliczenia znajduje „środkowy” jeden lub dwa wiersze. Jest to bardzo podobne do pierwszego przykładu powyżej, z łatwiejszą składnią:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – numer wiersza + liczba
Ten jest dość podobny do powyższego, używając pojedynczego obliczenia ROW_NUMBER() a następnie używając sumy COUNT() aby znaleźć „środkowy” jeden lub dwa wiersze:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – wariacja na temat numeru wiersza + liczba
Kolega MVP Itzik Ben-Gan pokazał mi tę metodę, która daje taką samą odpowiedź jak powyższe dwie metody, ale w bardzo nieco inny sposób:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
Serwer SQL 2012
W SQL Server 2012 mamy nowe możliwości okienkowania w T-SQL, które pozwalają na bardziej bezpośrednie wyrażanie obliczeń statystycznych, takich jak mediana. Aby obliczyć medianę dla zbioru wartości, możemy użyć PERCENTILE_CONT() . Możemy również użyć nowego rozszerzenia „stronicowania” do ORDER BY klauzula (OFFSET / FETCH ).
2012_A – nowa funkcjonalność dystrybucji
To rozwiązanie wykorzystuje bardzo proste obliczenia przy użyciu rozkładu (jeśli nie chcesz średniej między dwiema środkowymi wartościami w przypadku parzystej liczby wierszy).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – sztuczka ze stronicowaniem
Ten przykład implementuje sprytne użycie OFFSET / FETCH (a nie dokładnie taki, do którego był przeznaczony) – po prostu przechodzimy do rzędu, który jest jeden przed połową liczenia, a następnie bierzemy kolejny jeden lub dwa rzędy w zależności od tego, czy liczenie było parzyste czy nieparzyste. Dziękuję Itzikowi Ben-Ganowi za wskazanie tego podejścia.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Ale który z nich działa lepiej?
Sprawdziliśmy, że wszystkie powyższe metody dają oczekiwane rezultaty na naszym małym stoliku i wiemy, że wersja SQL Server 2012 ma najczystszą i najbardziej logiczną składnię. Ale którego z nich powinieneś używać w swoim ruchliwym środowisku produkcyjnym? Z metadanych systemowych możemy zbudować znacznie większą tabelę, upewniając się, że mamy dużo zduplikowanych wartości. Ten skrypt wygeneruje tabelę zawierającą 10 000 000 nieunikalnych liczb całkowitych:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
W moim systemie mediana dla tej tabeli powinna wynosić 146 099 561. Mogę to dość szybko obliczyć bez ręcznego sprawdzania 10 000 000 wierszy za pomocą następującego zapytania:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Wyniki:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Teraz możemy stworzyć procedurę składowaną dla każdej metody, sprawdzić, czy każda z nich generuje prawidłowe dane wyjściowe, a następnie zmierzyć metryki wydajności, takie jak czas trwania, procesor i odczyty. Wszystkie te kroki wykonamy z istniejącą tabelą, a także z kopią tabeli, która nie korzysta z indeksu klastrowego (usuniemy ją i ponownie utworzymy tabelę jako stertę).
Stworzyłem siedem procedur implementujących powyższe metody zapytań. Dla zwięzłości nie wymienię ich tutaj, ale każdy z nich ma nazwę dbo.Median_<version> , np. dbo.Median_2000_A , dbo.Median_2000_B , itp. odpowiadające podejściom opisanym powyżej. Jeśli uruchomimy te siedem procedur za pomocą bezpłatnego Eksploratora planów SQL Sentry, oto, co obserwujemy pod względem czasu trwania, procesora i odczytów (zauważ, że między wykonaniami uruchamiamy DBCC FREEPROCCACHE i DBCC DROPCLEANBUFFERS):
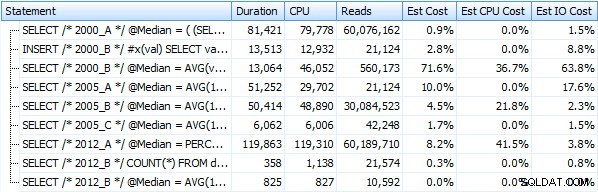
A te metryki nie zmieniają się zbytnio, jeśli zamiast tego działamy na stosie. Największą zmianą procentową była metoda, która nadal okazała się najszybsza:sztuczka ze stronicowaniem przy użyciu OFFSET / FETCH:
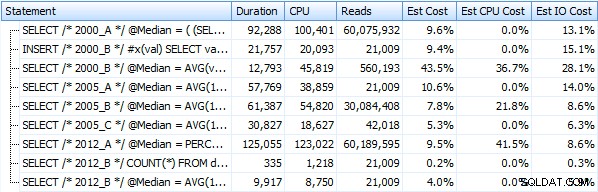
Oto graficzna reprezentacja wyników. Aby było to jaśniejsze, zaznaczyłem najwolniejszego wykonawcę na czerwono, a najszybsze podejście na zielono.
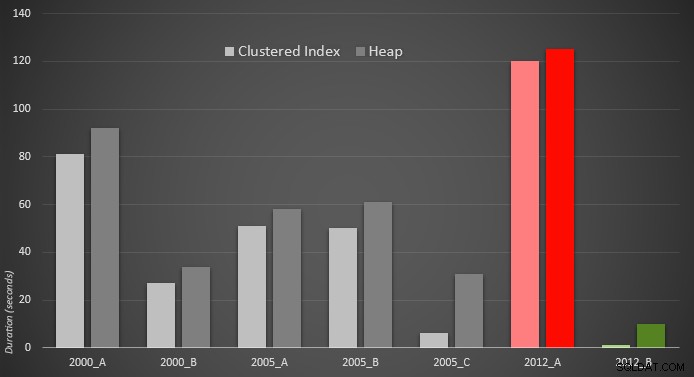
Byłem zaskoczony, widząc, że w obu przypadkach PERCENTILE_CONT() – który został zaprojektowany do tego typu obliczeń – jest w rzeczywistości gorszy od wszystkich innych wcześniejszych rozwiązań. Myślę, że to tylko pokazuje, że chociaż czasami nowsza składnia może ułatwić nam kodowanie, nie zawsze gwarantuje to poprawę wydajności. Byłem również zaskoczony, gdy zobaczyłem OFFSET / FETCH okazują się tak przydatne w scenariuszach, które zwykle nie pasują do swojego celu – paginacji.
W każdym razie mam nadzieję, że zademonstrowałem, jakiego podejścia należy użyć, w zależności od wersji SQL Server (i że wybór powinien być taki sam, niezależnie od tego, czy masz indeks pomocniczy do obliczeń).