Jestem w trakcie porządkowania mojego domu (za późno latem, aby spróbować zaliczyć to do wiosennych porządków). Wiesz, sprzątanie szaf, przeglądanie dziecięcych zabawek i porządkowanie piwnicy. To bolesny proces. Kiedy przeprowadziliśmy się do naszego domu 10 lat temu, mieliśmy tak dużo miejsca. Teraz czuję, że rzeczy są wszędzie i utrudnia to znalezienie tego, czego naprawdę szukam, a sprzątanie i porządkowanie zajmuje coraz więcej czasu.
Czy to brzmi jak każda baza danych, którą zarządzasz?
Wielu klientów, z którymi pracowałem, zajmuje się czyszczeniem danych po namyśle. W momencie wdrożenia każdy chce wszystko uratować. „Nigdy nie wiemy, kiedy możemy tego potrzebować”. Po roku lub dwóch ktoś zdaje sobie sprawę, że w bazie danych jest dużo dodatkowych rzeczy, ale teraz ludzie boją się tego pozbyć. „Musimy skontaktować się z działem prawnym, aby sprawdzić, czy możemy go usunąć”. Ale nikt nie sprawdza w dziale prawnym, a jeśli ktoś to robi, dział prawny wraca do właścicieli firm, aby zapytać, co zatrzymać, a potem projekt się zatrzymuje. „Nie możemy dojść do konsensusu co do tego, co można usunąć”. Projekt został zapomniany, a potem dwa lub cztery lata później baza danych nagle staje się terabajtem, trudna w zarządzaniu, a ludzie obwiniają za wszystkie problemy z wydajnością rozmiar bazy danych. Słyszysz słowa „partycjonowanie” i „baza danych archiwum”, a czasami po prostu możesz usunąć kilka danych, co ma swoje własne problemy.
Najlepiej byłoby, gdybyś zdecydował się na strategię oczyszczania przed wdrożeniem lub w ciągu pierwszych sześciu do dwunastu miesięcy od uruchomienia. Ale skoro już ten etap minął, spójrzmy, jaki wpływ mogą mieć te dodatkowe dane.
Metodologia testów
Aby przygotować scenę, wziąłem kopię bazy danych Credit i przywróciłem ją do mojej instancji SQL Server 2012. Upuściłem trzy istniejące indeksy nieklastrowe i dodałem dwa własne:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Następnie zwiększyłem liczbę wierszy w tabeli do 14,4 miliona, wielokrotnie wstawiając oryginalny zestaw wierszy, nieznacznie modyfikując daty:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Na koniec skonfigurowałem zestaw testowy do wykonywania serii instrukcji w bazie danych po cztery razy. Oświadczenia są poniżej:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Przed każdą instrukcją wykonałem
DBCC DROPCLEANBUFFERS; GO
aby wyczyścić pulę buforów. Oczywiście nie jest to coś do wykonania w środowisku produkcyjnym. Zrobiłem to tutaj, aby zapewnić spójny punkt wyjścia dla każdego testu.
Po każdym wykonaniu zwiększyłem rozmiar tabeli dbo.charge, wstawiając 14,4 miliona wierszy, od których zacząłem, ale zwiększyłem charge_dt o jeden rok dla każdego wykonania. Na przykład:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Po dodaniu 14,4 miliona rzędów ponownie uruchomiłem uprząż testową. Powtórzyłem to sześć razy, w zasadzie dodając sześć „lat” danych. Tabela dbo.charge zaczynała się od danych z 1999 r., a po wielokrotnych wstawkach zawierała dane do 2005 r.
Wyniki
Wyniki egzekucji można zobaczyć tutaj:
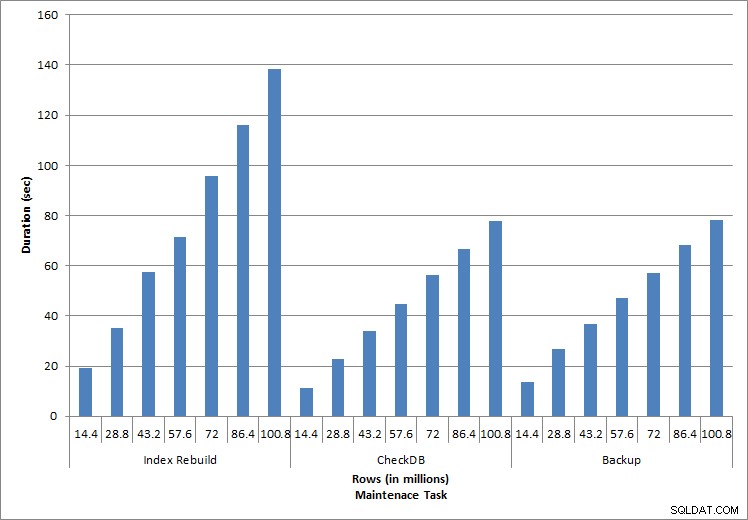
Czas trwania zadań konserwacyjnych
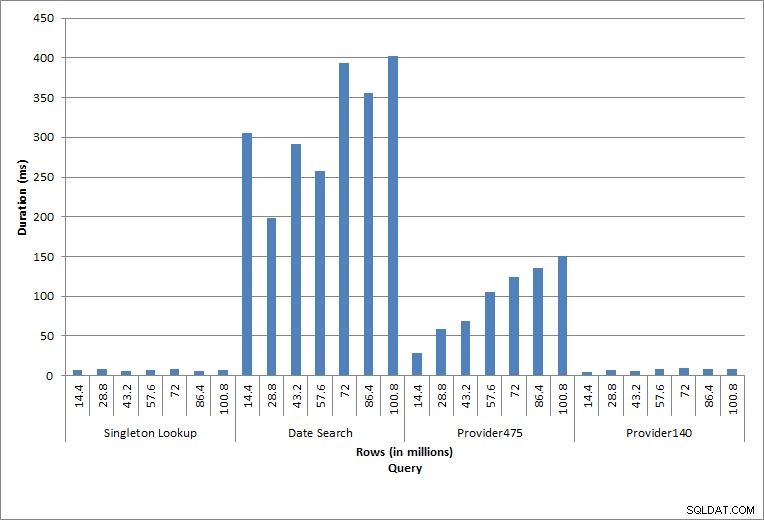
Czas trwania zapytań
Wykonywane poszczególne instrukcje odzwierciedlają typową aktywność bazy danych. Odbudowywanie indeksów, sprawdzanie integralności i tworzenie kopii zapasowych są częścią regularnej konserwacji bazy danych. Zapytania w tabeli opłat reprezentują wyszukiwanie singleton, a także trzy odmiany skanowania zakresu specyficzne dla danych w tabeli.
Przebudowa indeksu, CHECKDB i kopie zapasowe
Zgodnie z oczekiwaniami dla zadań konserwacyjnych, czas trwania i wartości we/wy wzrosły wraz z dodawaniem kolejnych wierszy do bazy danych. Rozmiar bazy danych wzrósł dziesięciokrotnie i chociaż czasy trwania nie rosły w tym samym tempie, zaobserwowano stały wzrost. Każde zadanie konserwacji początkowo trwało mniej niż 20 sekund, ale w miarę dodawania kolejnych wierszy czas trwania zadań wzrósł do prawie 1 minuty i 20 sekund w przypadku 100 milionów wierszy (i do ponad 2 minut w przypadku przebudowy indeksu). Odzwierciedla to dodatkowy czas wymagany przez SQL Server do wykonania zadania ze względu na dodatkowe dane.
Wyszukiwanie pojedynczej
Zapytanie przeciwko dbo.charge dla określonego charge_no zawsze generowało jeden wiersz – i wytworzyłoby jeden wiersz niezależnie od użytej wartości, ponieważ charge_no jest unikalną tożsamością. W tym wyszukiwaniu występuje minimalna zmienność. Ponieważ wiersze są stale dodawane do tabeli, indeks może wzrosnąć w głąb o jeden lub dwa poziomy (więcej, gdy tabela staje się szersza), co powoduje dodanie kilku operacji we/wy, ale jest to wyszukiwanie singletonowe z bardzo małą liczbą operacji we/wy.
Skanowanie zasięgu
Zapytanie o zakres dat (charge_dt) zostało zmodyfikowane po każdym wstawieniu, aby wyszukać najnowsze dane roku za lipiec (np. „2005-07-01” do „2005-07-01” w przypadku ostatniego zestawu testów), ale zwrócono za każdym razem nieco ponad 1,2 miliona wierszy. W rzeczywistym scenariuszu nie spodziewalibyśmy się, że zostanie zwrócona taka sama liczba wierszy dla tego samego miesiąca, rok do roku, ani nie oczekiwalibyśmy, że zostanie zwrócona taka sama liczba wierszy dla każdego miesiąca w roku. Jednak liczba wierszy może pozostać w tym samym zakresie między miesiącami, z niewielkim wzrostem w czasie. Występują wahania czasu trwania tego zapytania, ale przegląd danych we/wy przechwyconych z sys.dm_io_virtual_file_stats pokazuje spójność w liczbie odczytów.
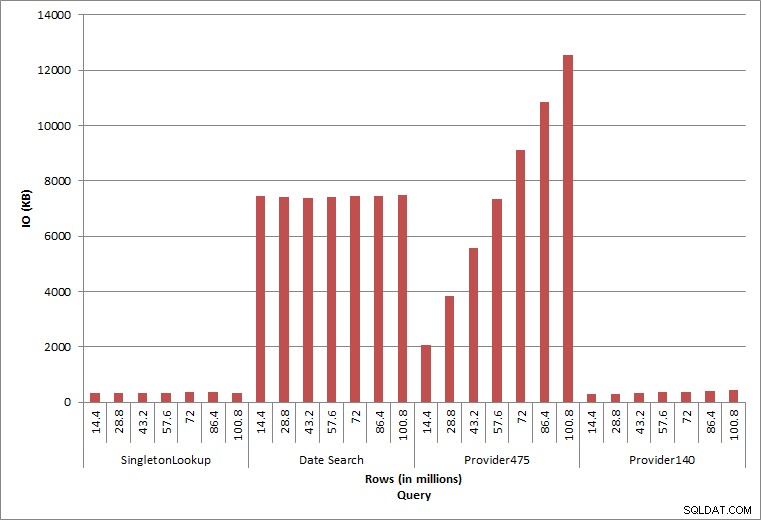
Zapytanie IO
Ostatnie dwa zapytania dla dwóch różnych wartości provider_no pokazują prawdziwy efekt przechowywania danych. W początkowej tabeli dbo.charge provider_no 475 miał ponad 126 000 wierszy, a provider_no 140 miał ponad 1700 wierszy. Dla każdego 14,4 miliona wierszy, które zostały dodane, dodano w przybliżeniu taką samą liczbę wierszy dla każdego dostawcy_no. W środowisku produkcyjnym ten rodzaj dystrybucji danych nie jest rzadkością, a zapytania o te dane mogą działać dobrze w pierwszych latach rozwiązania, ale mogą z czasem ulec degradacji w miarę dodawania kolejnych wierszy. Czas trwania zapytania zwiększa się pięciokrotnie (z 31 ms do 153 ms) między początkowym i końcowym wykonaniem dla provider_no 475. Chociaż ten wpływ może nie wydawać się znaczący, zwróć uwagę na równoległy wzrost liczby operacji we/wy (powyżej). Gdyby było to zapytanie wykonywane z dużą częstotliwością i/lub podobne zapytania wykonywane z regularną częstotliwością, dodatkowe obciążenie może się sumować i wpływać na ogólne wykorzystanie zasobów. Ponadto należy wziąć pod uwagę wpływ pracy z tabelami, które mają miliardy wierszy i są używane w zapytaniach ze złożonymi sprzężeniami, oraz wpływ na regularne — i niezwykle krytyczne — zadania konserwacji. Na koniec weź pod uwagę czas odzyskiwania. Plan odzyskiwania po awarii powinien opierać się na czasach przywracania, a wraz ze wzrostem rozmiaru bazy danych przywrócenie całej bazy danych będzie trwało dłużej. Jeśli nie testujesz regularnie i nie synchronizujesz przywracania, odzyskiwanie po awarii może potrwać dłużej, niż myślałeś.
Podsumowanie
Przedstawione tutaj przykłady są prostymi ilustracjami tego, co może się zdarzyć, gdy strategia archiwizacji danych nie zostanie określona podczas implementacji bazy danych, a istnieje wiele innych scenariuszy do zbadania i przetestowania. Stare dane, do których rzadko się sięga, jeśli w ogóle, mają wpływ nie tylko na miejsce na dysku. Może wpływać na wydajność zapytań i czas trwania zadań konserwacyjnych. Jako administrator zarządzający wieloma bazami danych w instancji, jedna baza danych zawierająca dane historyczne może wpływać na wydajność i konserwację innych baz danych. Co więcej, jeśli raporty są wykonywane na danych historycznych, może to siać spustoszenie w już zajętym środowisku OLTP.
Od samego początku ważne jest, aby określić żywotność danych w bazie danych i wdrożyć plan działania. W przypadku niektórych rozwiązań wymagane jest przechowywanie wszystkich danych na zawsze. W takim przypadku zastosuj strategie pozwalające na zarządzanie rozmiarem bazy danych, na przykład:regularnie archiwizuj dane w oddzielnej tabeli lub oddzielnej bazie danych. W przypadku, gdy dane nie muszą być przechowywane przez wiele lat, należy wdrożyć strategię czyszczenia, która regularnie usuwa dane. W ten sposób możesz wyrzucić zabawki, którymi się już nie bawisz, ubrania, które już nie pasują i losowe śmieci, których po prostu nie używasz co trzy miesiące… a nie raz na 10 lat.