Pracujesz z programistą, który zgłasza niską wydajność następującego wywołania procedury składowanej:
EXEC [dbo].[charge_by_date] '2/28/2013';
Pytasz, jaki problem widzi programista, ale jedyną dodatkową informacją, którą słyszysz, jest to, że „działa powoli”. Wskocz więc na instancję SQL Server i spójrz na rzeczywistą plan wykonania. Robisz to, ponieważ interesuje Cię nie tylko wygląd planu wykonania, ale także szacunkowa i rzeczywista liczba wierszy dla planu:
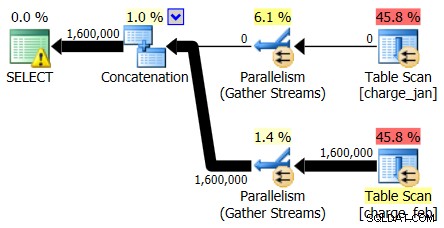
Patrząc najpierw tylko na operatorów planu, możesz zobaczyć kilka godnych uwagi szczegółów:
- W operatorze głównym znajduje się ostrzeżenie
- Istnieje skanowanie tabeli dla obu tabel, do których odwołuje się na poziomie liścia (charge_jan i charge_feb) i zastanawiasz się, dlaczego obie są nadal stosami i nie mają indeksów klastrowych
- Widzisz, że przez tabelę charge_feb przepływają tylko wiersze, a nie przez tabelę charge_jan
- Widzisz równoległe strefy na planie
Jeśli chodzi o ostrzeżenie w iteratorze głównym, najedź na nie kursorem i zobaczysz, że brakuje ostrzeżeń indeksu z zaleceniem dla następujących indeksów:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Pytasz oryginalnego programistę bazy danych, dlaczego nie ma indeksu klastrowego, a odpowiedź brzmi „Nie wiem”.
Kontynuując badanie przed wprowadzeniem jakichkolwiek zmian, patrzysz na kartę Drzewo planów w Eksploratorze planów SQL Sentry i rzeczywiście widzisz, że istnieją znaczne odchylenia między szacowanymi a rzeczywistymi wierszami dla jednej z tabel:

Wydaje się, że istnieją dwa problemy:
- Niedoszacowanie wierszy w skanowaniu tabeli charge_jan
- Przeszacowanie wierszy w skanowaniu tabeli charge_feb
Tak więc szacunki kardynalności są przekrzywiony i zastanawiasz się, czy ma to związek z podsłuchiwaniem parametrów. Decydujesz się sprawdzić skompilowaną wartość parametru i porównać ją z wartością parametru runtime, którą możesz zobaczyć w zakładce Parametry:

Rzeczywiście istnieją różnice między wartością środowiska wykonawczego a wartością skompilowaną. Kopiujesz bazę danych do środowiska testowego podobnego do prod, a następnie testujesz wykonanie procedury składowanej z wartością runtime najpierw 2/28/2013, a następnie 31/01/2013.
Plany 28.02.2013 i 31.01.2013 mają identyczne kształty, ale różne rzeczywiste przepływy danych. Plan i szacunki dotyczące kardynalności z dnia 28.02.2013 r. przedstawiały się następująco:
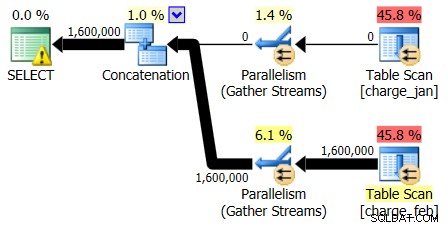

I chociaż plan z 28.02.2013 nie wykazuje problemu z oszacowaniem kardynalności, plan z 31.01.2013:
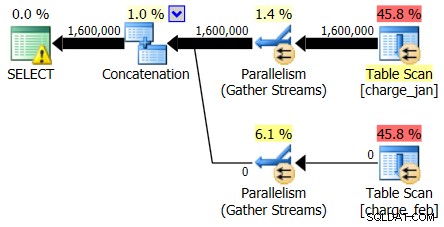

Tak więc drugi plan pokazuje te same przeszacowania i niedoszacowania, po prostu odwrócone od pierwotnego planu, na który patrzyłeś.
Decydujesz się dodać sugerowane indeksy do środowiska testowego podobnego do prod dla obu tabel charge_jan i charge_feb i sprawdź, czy to w ogóle pomaga. Wykonując procedury składowane w kolejności styczeń/luty, zobaczysz następujące nowe kształty planów i powiązane szacunki liczności:
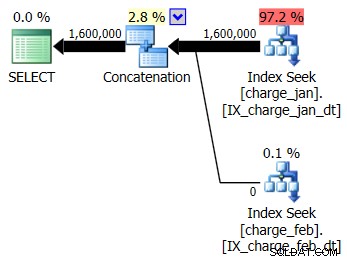

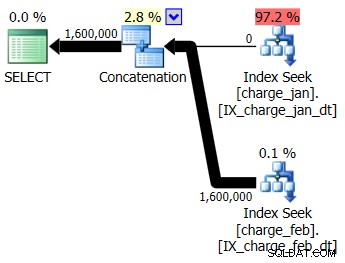

Nowy plan korzysta z operacji Index Seek z każdej tabeli, ale nadal widzisz zero wierszy płynących z jednej tabeli, a nie z drugiej, i nadal widzisz pochylenie oszacowania kardynalności na podstawie wąchania parametrów, gdy wartość środowiska wykonawczego jest w innym miesiącu niż kompilacja wartość czasu.
Twój zespół ma zasadę nie dodawania indeksów bez dowodu wystarczających korzyści i powiązanych testów regresji. Decydujesz na razie usunąć indeksy nieklastrowane, które właśnie utworzyłeś. Chociaż nie zajmujesz się od razu brakującym zgrupowaniem indeks, decydujesz, że zajmiesz się tym później.
W tym momencie zdajesz sobie sprawę, że musisz dokładniej przyjrzeć się definicji procedury składowanej, która wygląda następująco:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Następnie spójrz na definicję obiektu charge_view:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
Widok odwołuje się do danych dotyczących opłat, które są podzielone na różne tabele według daty. A potem zastanawiasz się, czy można zapobiec przekrzywieniu planu wykonania drugiego zapytania, zmieniając definicję procedury składowanej.
Być może, jeśli optymalizator wie w czasie wykonywania, jaka jest wartość, problem z szacowaną kardynalnością zniknie i poprawi ogólną wydajność?
Kontynuujesz i ponownie definiujesz wywołanie procedury składowanej w następujący sposób, dodając wskazówkę RECOMPILE (wiedząc, że słyszałeś również, że może to zwiększyć użycie procesora, ale ponieważ jest to środowisko testowe, czujesz się bezpiecznie, próbując):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Następnie ponownie wykonujesz procedurę składowaną, używając wartości 1/31/2013, a następnie 2/28/2013.
Kształt planu pozostaje taki sam, ale teraz problem z oszacowaniem kardynalności został usunięty.
Dane szacunkowe dotyczące kardynalności z 31.01.2013 pokazują:

Szacunkowe dane dotyczące kardynalności z 28.02.2013 pokazują:

To sprawia, że jesteś przez chwilę szczęśliwy, ale potem zdajesz sobie sprawę, że czas trwania całego zapytania wydaje się być taki sam jak wcześniej. Zaczynasz mieć wątpliwości, czy programista będzie zadowolony z Twoich wyników. Rozwiązałeś pochylenie oszacowania kardynalności, ale bez oczekiwanego wzrostu wydajności nie masz pewności, czy pomogłeś w jakikolwiek znaczący sposób.
W tym momencie zdajesz sobie sprawę, że plan wykonania zapytania jest tylko podzbiorem informacji, których możesz potrzebować, więc możesz dalej rozwijać swoją eksplorację, patrząc na kartę Table I/O. Zobaczysz następujące dane wyjściowe dla wykonania 31.01.2013:

A dla wykonania 28.02.2013 widzisz podobne dane:

W tym momencie zastanawiasz się, czy operacje dostępu do danych dla obu tabele są niezbędne w każdym planie. Jeśli optymalizator wie, że potrzebujesz tylko wierszy ze stycznia, po co w ogóle mieć dostęp do lutego i na odwrót? Należy również pamiętać, że optymalizator zapytań nie gwarantuje, że nie rzeczywiste wiersze z innych miesięcy w „niewłaściwej” tabeli, chyba że takie gwarancje zostały wyraźnie udzielone przez ograniczenia samej tabeli.
Sprawdzasz definicje tabeli za pomocą sp_help dla każdej tabeli i nie widzisz żadnych ograniczeń zdefiniowanych dla żadnej tabeli.
W ramach testu dodajesz następujące dwa ograniczenia:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Ponownie wykonujesz procedury składowane i widzisz następujące kształty planu i szacunkowe liczności.
Wykonanie 31.01.2013:
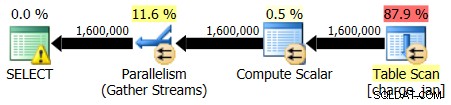

28.02.2013 wykonanie:


Patrząc ponownie na tabelę I/O, zobaczysz następujące dane wyjściowe dla wykonania 31.01.2013:

A dla wykonania 28.02.2013 widzisz podobne dane, ale dla tabeli charge_feb:

Pamiętając, że nadal masz RECOMPILE w definicji procedury składowanej, spróbuj go usunąć i zobaczyć, czy widzisz ten sam efekt. Po wykonaniu tej czynności zobaczysz zwrot dostępu do dwóch tabel, ale bez rzeczywistych odczytów logicznych dla tabeli, która nie zawiera wierszy (w porównaniu z pierwotnym planem bez ograniczeń). Na przykład wykonanie 31.01.2013 pokazało następujące dane wyjściowe tabeli I/O:

Decydujesz się przejść do przodu z testowaniem obciążenia nowych ograniczeń CHECK i rozwiązania RECOMPILE, całkowicie usuwając dostęp do tabeli z planu (i powiązanych operatorów planu). Przygotowujesz się również do debaty na temat klucza indeksu klastrowego i odpowiedniego pomocniczego indeksu nieklastrowego, który pomieści szerszy zestaw obciążeń, które obecnie uzyskują dostęp do powiązanych tabel.



