W moim ostatnim poście widzieliśmy, jak zapytanie zawierające agregację skalarną może zostać przekształcone przez optymalizator do bardziej wydajnej postaci. Przypominamy, oto schemat ponownie:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Wybory planu
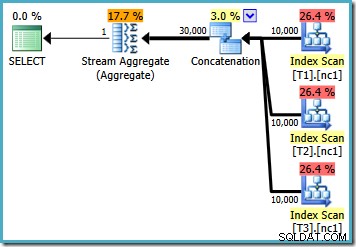
Z 10 000 wierszy w każdej z tabel podstawowych, optymalizator opracowuje prosty plan, który oblicza maksimum, odczytując wszystkie 30 000 wierszy do agregacji:
Z 50 000 wierszami w każdej tabeli, optymalizator poświęca trochę więcej czasu na problem i znajduje sprytniejszy plan. Odczytuje tylko górny wiersz (w porządku malejącym) z każdego indeksu, a następnie oblicza maksimum tylko z tych 3 wierszy:
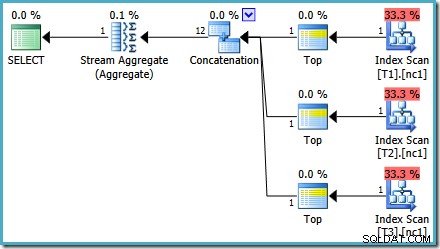
Błąd Optymalizatora
Możesz zauważyć coś dziwnego w tej szacowanej plan. Operator konkatenacji odczytuje jeden wiersz z trzech tabel i jakoś tworzy dwanaście wierszy! Jest to błąd spowodowany błędem w szacowaniu kardynalności, który zgłosiłem w maju 2011. Nadal nie został naprawiony w SQL Server 2014 CTP 1 (nawet jeśli używany jest nowy estymator kardynalności), ale mam nadzieję, że zostanie rozwiązany dla wersja ostateczna.
Aby zobaczyć, jak pojawia się błąd, przypomnij sobie, że jedna z alternatyw rozważanych przez optymalizator dla przypadku 50 000 wierszy zawiera częściowe agregaty poniżej operatora konkatenacji:
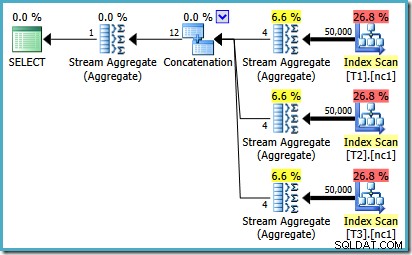
Jest to oszacowanie kardynalności dla tych częściowych MAX agregaty, które są winne. Szacują cztery wiersze, w których wynik jest gwarantowany jako jeden wiersz. Możesz zobaczyć liczbę inną niż cztery – zależy to od tego, ile procesorów logicznych jest dostępnych dla optymalizatora w czasie kompilacji planu (więcej szczegółów znajdziesz w linku powyżej).
Optymalizator później zastępuje agregaty częściowe operatorami Top (1), które poprawnie obliczają ponownie oszacowanie liczności. Niestety, operator konkatenacji nadal odzwierciedla szacunki dla zastąpionych agregatów częściowych (3 * 4 =12). W rezultacie otrzymujemy konkatenację, która odczytuje 3 wiersze i daje 12.
Używanie TOP zamiast MAX
Patrząc ponownie na plan 50 000 wierszy, wydaje się, że największym ulepszeniem znalezionym przez optymalizator jest użycie operatorów Top (1) zamiast odczytywania wszystkich wierszy i obliczania maksymalnej wartości przy użyciu siły brutalnej. Co się stanie, jeśli spróbujemy czegoś podobnego i przepiszemy zapytanie, używając jawnie Top?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Plan wykonania nowego zapytania to:
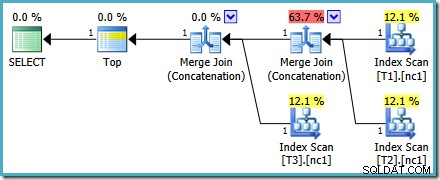
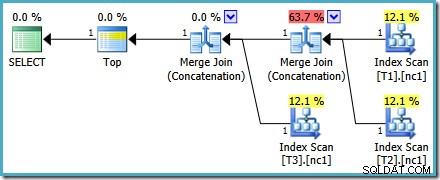
Ten plan jest zupełnie inny niż ten wybrany przez optymalizator dla MAX zapytanie. Zawiera trzy uporządkowane skany indeksu, dwa łączenia scalające działające w trybie konkatenacji oraz jeden operator górny. Ten nowy plan zapytań ma kilka interesujących funkcji, które warto zbadać szczegółowo.
Analiza planu
Pierwszy wiersz (w malejącej kolejności indeksów) jest odczytywany z nieklastrowego indeksu każdej tabeli i używane jest łączenie scalające działające w trybie konkatenacji. Chociaż operator Merge Join nie wykonuje łączenia w normalnym sensie, algorytm przetwarzania tego operatora można łatwo dostosować do łączenia danych wejściowych zamiast stosowania kryteriów łączenia.
Zaletą korzystania z tego operatora w nowym planie jest to, że łączenie łączenia zachowuje porządek sortowania we wszystkich wejściach. W przeciwieństwie do tego zwykły operator konkatenacji odczytuje kolejno ze swoich danych wejściowych. Poniższy diagram ilustruje różnicę (kliknij, aby rozwinąć):
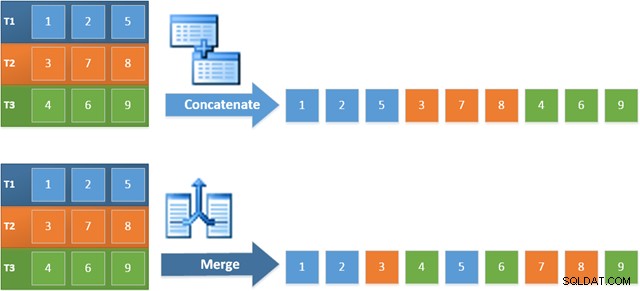
Zachowanie z zachowaniem kolejności łączenia scalania oznacza, że pierwszy wiersz utworzony przez skrajny lewy operator scalania w nowym planie na pewno będzie wierszem o najwyższej wartości w kolumnie c1 we wszystkich trzech tabelach. Dokładniej, plan działa w następujący sposób:
- Jeden wiersz jest odczytywany z każdej tabeli (w porządku malejącym indeksu); i
- Każde scalenie wykonuje jeden test aby zobaczyć, który z jego wierszy wejściowych ma wyższą wartość
Wydaje się to bardzo wydajną strategią, więc może wydawać się dziwne, że MAX . optymalizatora plan ma szacunkowy koszt mniej niż połowę nowego planu. W dużej mierze powodem jest to, że zakłada się, że konkatenacja scalająca z zachowaniem kolejności jest droższa niż zwykła konkatenacja. Optymalizator nie zdaje sobie sprawy, że w przypadku każdego scalania można zobaczyć maksymalnie jeden wiersz iw rezultacie przeszacowuje jego koszt.
Więcej problemów z kosztami
Ściśle mówiąc, nie porównujemy tutaj jabłek z jabłkami, ponieważ oba plany dotyczą różnych zapytań. Porównywanie kosztów w ten sposób zazwyczaj nie jest właściwą czynnością, chociaż program SSMS robi dokładnie to, wyświetlając wartości procentowe kosztów dla różnych zestawień w partii. Ale dygresja.
Jeśli spojrzysz na nowy plan w SSMS zamiast w SQL Sentry Plan Explorer, zobaczysz coś takiego:
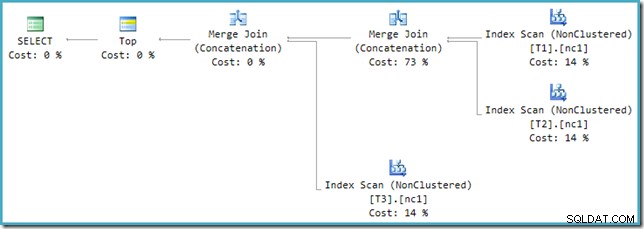
Jeden z operatorów Merge Join Concatenation ma szacunkowy koszt 73%, podczas gdy drugi (działający na dokładnie tej samej liczbie wierszy) jest pokazany jako nic nie kosztujący. Inną oznaką, że coś jest nie tak, jest to, że procent kosztów operatora w tym planie nie sumuje się do 100%.
Optymalizator a silnik wykonawczy
Problem tkwi w niezgodności między optymalizatorem a silnikiem wykonawczym. W optymalizatorze Union i Union All mogą mieć 2 lub więcej wejść. W silniku wykonawczym tylko operator konkatenacji może zaakceptować 2 lub więcej wejścia; Połączenie scalające wymaga dokładnie dwa wejścia, nawet jeśli są skonfigurowane do wykonywania konkatenacji, a nie łączenia.
Aby rozwiązać tę niezgodność, stosuje się ponowne zapisywanie po optymalizacji w celu przetłumaczenia drzewa wyjściowego optymalizatora na postać, którą może obsłużyć silnik wykonawczy. W przypadku, gdy Unia lub Unia Wszystkie z więcej niż dwoma danymi wejściowymi jest wdrażana za pomocą łączenia, potrzebny jest łańcuch operatorów. Z trzema danymi wejściowymi do Zjednoczenia Wszystkich w niniejszym przypadku potrzebne są dwie Zjednoczenia Związków:
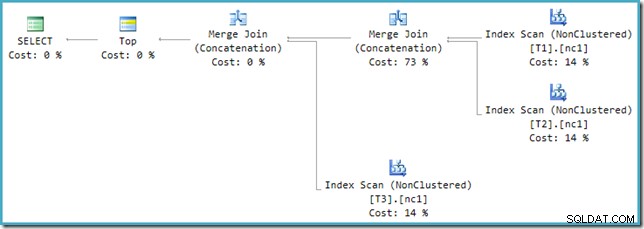
Możemy zobaczyć drzewo wyjściowe optymalizatora (z trzema danymi wejściowymi do fizycznej unii scalania) za pomocą flagi śledzenia 8607:
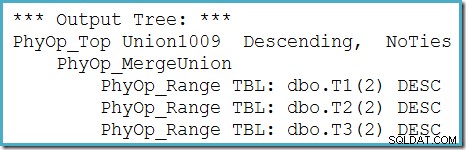
Niekompletna poprawka
Niestety, przepisywanie po optymalizacji nie jest doskonale zaimplementowane. To powoduje trochę bałaganu w liczbach kosztorysowych. Pomijając kwestie zaokrąglania, koszty planu wynoszą do 114%, a dodatkowe 14% pochodzi z danych wejściowych do dodatkowej konkatenacji łączenia łączenia generowanej przez przepisanie:
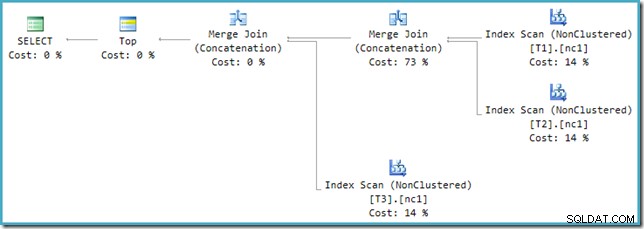
Scal najbardziej z prawej strony w tym planie jest pierwotnym operatorem w drzewie wyjściowym optymalizatora. Jest przypisany do pełnego kosztu operacji Union All. Drugie scalenie jest dodawane przez przepisanie i otrzymuje zerowy koszt.
Niezależnie od tego, w jaki sposób na to spojrzymy (a są różne problemy, które wpływają na zwykłą konkatenację), liczby wyglądają dziwnie. Plan Explorer dokłada wszelkich starań, aby obejść uszkodzone informacje w planie XML, zapewniając przynajmniej, że liczby sumują się do 100%:
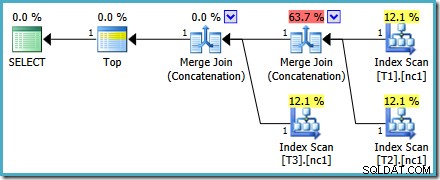
Ten konkretny problem z kosztami został rozwiązany w SQL Server 2014 CTP 1:
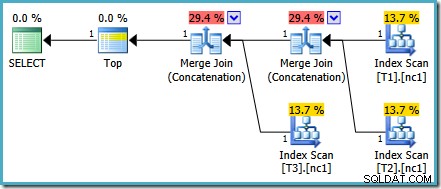
Koszty łączenia łączenia są teraz równo podzielone między dwóch operatorów, a wartości procentowe sumują się do 100%. Ponieważ podstawowy kod XML został naprawiony, SSMS również wyświetla te same liczby.
Który plan jest lepszy?
Jeśli napiszemy zapytanie za pomocą MAX , musimy polegać na tym, że optymalizator wybierze wykonanie dodatkowej pracy potrzebnej do znalezienia wydajnego planu. Jeśli optymalizator wcześnie znajdzie pozornie wystarczająco dobry plan, może stworzyć stosunkowo nieefektywny plan, który odczytuje każdy wiersz z każdej tabeli bazowej:
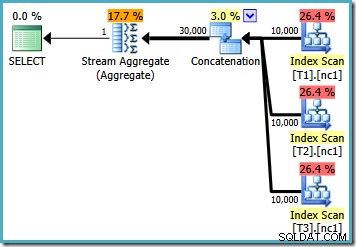
Jeśli korzystasz z programu SQL Server 2008 lub SQL Server 2008 R2, optymalizator nadal wybierze nieefektywny plan, niezależnie od liczby wierszy w tabelach podstawowych. Poniższy plan został utworzony na SQL Server 2008 R2 z 50 000 wierszy:
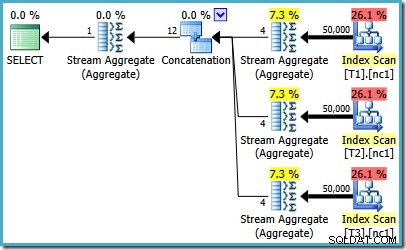
Nawet z 50 milionami wierszy w każdej tabeli, optymalizator 2008 i 2008 R2 dodaje tylko równoległość, nie wprowadza operatorów Top:
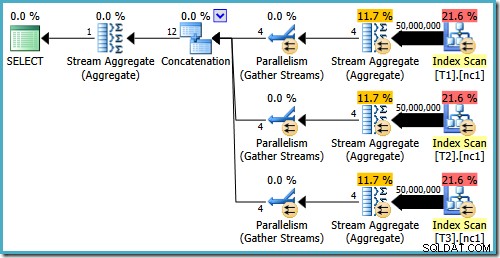
Jak wspomniano w moim poprzednim poście, flaga śledzenia 4199 jest wymagana, aby uzyskać SQL Server 2008 i 2008 R2 w celu utworzenia planu z najlepszymi operatorami. SQL Server 2005 i 2012 i nowsze nie wymagają flagi śledzenia:
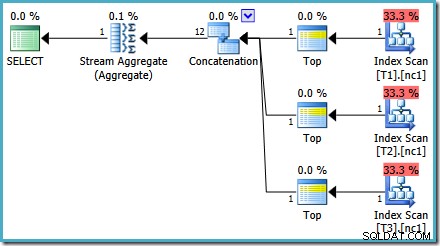
TOP z ORDER BY
Kiedy już zrozumiemy, co się dzieje w poprzednich planach wykonania, możemy dokonać świadomego (i świadomego) wyboru przepisania zapytania za pomocą jawnego TOP z ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Wynikowy plan wykonania może mieć wartości procentowe kosztów, które wyglądają dziwnie w niektórych wersjach programu SQL Server, ale podstawowy plan jest solidny. Przepisywanie po optymalizacji, które powoduje, że liczby wyglądają dziwnie, jest stosowane po zakończeniu optymalizacji zapytania, więc możemy być pewni, że ten problem nie miał wpływu na wybór planu optymalizatora.
Ten plan nie zmienia się w zależności od liczby wierszy w tabeli podstawowej i nie wymaga generowania żadnych flag śledzenia. Niewielką dodatkową zaletą jest to, że ten plan jest znajdowany przez optymalizatora podczas pierwszej fazy optymalizacji opartej na kosztach (wyszukiwanie 0):
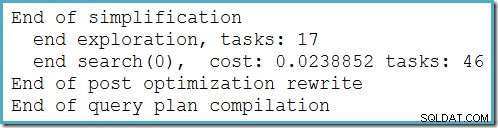
Najlepszy plan wybrany przez optymalizator dla MAX zapytanie wymagało uruchomienia dwóch etapów optymalizacji opartej na kosztach (wyszukaj 0 i szukaj 1)).
Istnieje niewielka różnica semantyczna między TOP zapytanie i oryginalny MAX forma, o której powinienem wspomnieć. Jeśli żadna z tabel nie zawiera wiersza, oryginalne zapytanie wygeneruje pojedynczy NULL wynik. Zastępczy TOP (1) zapytanie nie generuje żadnych danych wyjściowych w tych samych okolicznościach. Ta różnica nie jest często istotna w zapytaniach w świecie rzeczywistym, ale jest to coś, o czym należy pamiętać. Możemy powielić zachowanie TOP używając MAX w SQL Server 2008 i nowszych przez dodanie pustego zestawu GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Ta zmiana nie wpływa na plany wykonania wygenerowane dla MAX zapytanie w sposób widoczny dla użytkowników końcowych.
MAX z konkatenacją scalania
Biorąc pod uwagę sukces łączenia łączenia łączenia w TOP (1) plan wykonania, naturalne jest zastanawianie się, czy ten sam optymalny plan można wygenerować dla oryginalnego MAX zapytaj, czy wymusimy na optymalizatorze użycie łączenia scalania zamiast zwykłego łączenia dla UNION ALL operacja.
W tym celu dostępna jest wskazówka do zapytania — MERGE UNION – ale niestety działa poprawnie tylko w SQL Server 2012 i nowszych. We wcześniejszych wersjach UNION wskazówka dotyczy tylko UNION zapytania, a nie UNION ALL . W SQL Server 2012 i nowszych możemy spróbować tego:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
W nagrodę otrzymujemy plan, który zawiera funkcję łączenia łączenia. Niestety to nie wszystko, na co mogliśmy liczyć:
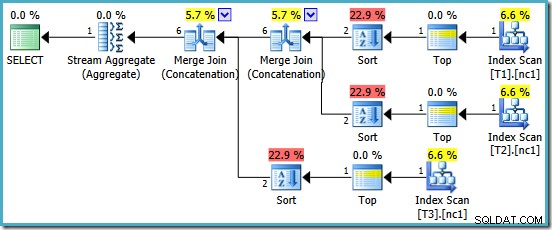
Interesujący operatorzy w tym planie są tego rodzaju. Zwróć uwagę na estymację liczności wejściowej dla 1 wiersza i estymację dla 4 wierszy na wyjściu. Przyczyna powinna być Ci już znana:jest to ten sam błąd oszacowania częściowej zbiorczej kardynalności, który omawialiśmy wcześniej.
Obecność rodzajów ujawnia jeszcze jeden problem z agregatami częściowymi. Nie tylko generują niepoprawne oszacowanie kardynalności, ale także nie zachowują kolejności indeksów, która sprawiłaby, że sortowanie byłoby niepotrzebne (konkatenacja łączenia wymaga posortowanych danych wejściowych). Agregaty częściowe są skalarne MAX agregaty, gwarantowane wyprodukowanie jednego rzędu, więc kwestia porządkowania i tak powinna być dyskusyjna (jest tylko jeden sposób na posortowanie jednego rzędu!)
Szkoda, bo bez tego byłby to przyzwoity plan egzekucji. Jeśli częściowe agregaty zostały zaimplementowane poprawnie, a MAX napisane za pomocą GROUP BY () klauzuli, możemy nawet mieć nadzieję, że optymalizator wykryje, że trzy Tops i końcowy Stream Aggregate można zastąpić jednym końcowym operatorem Top, co daje dokładnie taki sam plan jak jawny TOP (1) zapytanie. Optymalizator nie zawiera tej transformacji na dzień dzisiejszy i nie sądzę, aby był wystarczająco przydatny, aby jego włączenie było opłacalne w przyszłości.
Końcowe słowa
Korzystanie z TOP nie zawsze będzie lepsze niż MIN lub MAX . W niektórych przypadkach da to znacznie mniej optymalny plan. Celem tego postu jest to, że zrozumienie transformacji zastosowanych przez optymalizator może zasugerować sposoby przepisania oryginalnego zapytania, które mogą okazać się pomocne.