Wiele osób używa statystyk oczekiwania jako części ogólnej metodologii rozwiązywania problemów z wydajnością, podobnie jak ja, więc pytanie, które chciałem zbadać w tym poście, dotyczy typów oczekiwania związanych z obciążeniem obserwatora. Przez obciążenie obserwatora rozumiem wpływ na przepustowość obciążenia SQL Server powodowany przez SQL Profiler, śledzenie po stronie serwera lub sesje Extended Event. Więcej informacji na temat narzutu obserwatora można znaleźć w następujących dwóch postach mojego kolegi Jonathana Kehayiasa :
Tak więc w tym poście chciałbym przejść przez kilka odmian obserwatora narzutu i zobaczyć, czy możemy znaleźć spójne typy oczekiwania związane z mierzoną degradacją. Istnieje wiele sposobów, w jakie użytkownicy SQL Server implementują śledzenie w swoich środowiskach produkcyjnych, więc wyniki mogą się różnić, ale chciałem omówić kilka ogólnych kategorii i zrelacjonować to, co znalazłem:
- Użycie sesji SQL Profiler
- Użycie śledzenia po stronie serwera
- Użycie śledzenia po stronie serwera, zapis do wolnej ścieżki we/wy
- Rozszerzone użycie zdarzeń z celem bufora pierścieniowego
- Rozszerzone użycie zdarzeń z plikiem docelowym
- Rozszerzone użycie zdarzeń z plikiem docelowym na wolnej ścieżce we/wy
- Rozszerzone użycie zdarzeń z plikiem docelowym na wolnej ścieżce we/wy bez utraty zdarzeń
Prawdopodobnie możesz wymyślić inne wariacje na ten temat. Zapraszam Cię do podzielenia się interesującymi odkryciami dotyczącymi ogólnych obserwatorów i statystykami oczekiwania jako komentarz w tym poście.
Podstawa
Do testu użyłem maszyny wirtualnej VMware z czterema vCPU i 4 GB pamięci RAM. Mój gość maszyny wirtualnej był na dyskach SSD firmy OCZ Vertex. System operacyjny to Windows Server 2008 R2 Enterprise, a wersja SQL Server to 2012, SP1 CU4.
Jeśli chodzi o „obciążenie”, używam zapytania tylko do odczytu w pętli względem przykładowej bazy danych kredytów 2008, ustawionej na GO 10 000 000 razy.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Wykonuję również to zapytanie przez 16 równoległych sesji. Końcowym wynikiem w moim systemie testowym jest 100% wykorzystanie procesora we wszystkich procesorach wirtualnych na wirtualnym gościu i średnio 14 492 żądań wsadowych na sekundę w okresie 2 minut.
Jeśli chodzi o śledzenie zdarzeń, w każdym teście używałem Showplan XML Statistics Profile dla testów SQL Profiler i śledzenia po stronie serwera – oraz query_post_execution_showplan dla sesji Extended Event. Zdarzenia planu wykonania są bardzo drogie, właśnie dlatego wybrałem je, aby sprawdzić, czy w ekstremalnych okolicznościach mogę wyprowadzić motywy typu oczekiwania.
Do testowania akumulacji typu oczekiwania w okresie testowym użyłem następującego zapytania. Nic nadzwyczajnego — wystarczy wyczyścić statystyki, odczekać 2 minuty, a następnie zebrać 10 największych akumulacji oczekiwania dla instancji SQL Server w okresie testu degradacji:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Zauważ, że nie odfiltrowywanie typów oczekiwania w tle, które zwykle są odfiltrowywane, a to dlatego, że nie chciałem eliminować czegoś, co zwykle jest łagodne – ale w tej sytuacji wskazuje na rzeczywisty obszar do dalszego zbadania.
Sesja programu SQL Profiler
W poniższej tabeli przedstawiono żądania wsadowe przed i po na sekundę podczas włączania śledzenia śledzenia lokalnego programu SQL Profiler Showplan XML Statistics Profile (działa na tej samej maszynie wirtualnej, co instancja SQL Server):
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe sesji programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 1416 |
Widać, że ślad programu SQL Profiler powoduje znaczny spadek przepustowości.
Jeśli chodzi o skumulowany czas oczekiwania w tym samym okresie, najważniejsze typy oczekiwania były następujące (podobnie jak w przypadku pozostałych testów w tym artykule, wykonałem kilka przebiegów testowych i wynik był ogólnie spójny):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWPISZ | 67 142 | 1149 824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237003 |
| SLEEP_TASK | 313 | 180 449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 086 |
| LAZYWRITER_SLEEP | 120 | 120 059 |
| DIRTY_PAGE_POLL | 1198 | 120 038 |
| HADR_WORK_QUEUE | 12 | 120 015 |
| LOGMGR_QUEUE | 937 | 120 011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,006 |
Typ oczekiwania, który mi wyskakuje, to TRACEWRITE — który jest zdefiniowany przez Books Online jako typ oczekiwania, który „występuje, gdy dostawca śledzenia zestawu wierszy SQL Trace czeka na wolny bufor lub bufor ze zdarzeniami do przetworzenia”. Pozostałe typy oczekiwania wyglądają jak standardowe typy oczekiwania w tle, które zwykle są odfiltrowywane z zestawu wyników. Co więcej, mówiłem o podobnym problemie z nadmiernym śledzeniem w artykule z 2011 roku zatytułowanym Obciążenie obserwatora — niebezpieczeństwa związane ze zbyt dużym śledzeniem — więc znałem ten typ oczekiwania czasami prawidłowo wskazując na ogólne problemy obserwatora. Teraz w tym konkretnym przypadku, o którym pisałem na blogu, nie był to SQL Profiler, ale inna aplikacja korzystająca z dostawcy śledzenia zestawu wierszy (nieefektywnie).
Śledzenie po stronie serwera
To było w przypadku programu SQL Profiler, ale co z obciążeniem śledzenia po stronie serwera? Poniższa tabela przedstawia żądania wsadowe przed i po na sekundę podczas włączania lokalnego śledzenia po stronie serwera zapisywania do pliku:
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 4015 |
Najczęstsze typy oczekiwania były następujące (zrobiłem kilka przebiegów testowych i wynik był spójny):
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| SLEEP_TASK | 253 | 180 871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 046 |
| HADR_WORK_QUEUE | 12 | 120 042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 021 |
| XE_DISPATCHER_WAIT | 3 | 120,006 |
| CZEKAJ NA | 1 | 120 000 |
| LOGMGR_QUEUE | 931 | 119 993 |
| DIRTY_PAGE_POLL | 1193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Tym razem nie widzimy TRACEWRITE (teraz używamy dostawcy plików) i innego typu oczekiwania związanego ze śledzeniem, nieudokumentowanego SQLTRACE_INCREMENTAL_FLUSH_SLEEP wspiął się w górę – ale w porównaniu do pierwszego testu, ma bardzo podobny skumulowany czas oczekiwania (120 046 vs 120 006) – a moja koleżanka Erin Stellato (@erinstellato) mówiła o tym konkretnym typie oczekiwania w swoim poście Jak ustalić, kiedy statystyki oczekiwania zostały ostatnio wyczyszczone . Więc patrząc na inne typy czekania, żaden nie wyskakuje jako niezawodny sygnał ostrzegawczy.
Zapis śledzenia po stronie serwera do wolnej ścieżki we/wy
Co jeśli umieścimy plik śledzenia po stronie serwera na wolnym dysku? Poniższa tabela przedstawia żądania wsadowe przed i po na sekundę podczas włączania lokalnego śledzenia po stronie serwera, które zapisuje do pliku na pamięci USB:
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 260 |
Jak widać – wydajność jest znacznie obniżona – nawet w porównaniu z poprzednim testem.
Najczęstsze typy oczekiwania były następujące:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2273 | 299995 |
| SLEEP_TASK | 240 | 194 264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181 458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125 007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120 559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120 516 |
| CZEKAJ NA | 1 | 120 515 |
| DIRTY_PAGE_POLL | 1204 | 120 513 |
Jednym z typów oczekiwania, który wyskakuje w tym teście, jest nieudokumentowany SQLTRACE_FILE_BUFFER . Niewiele udokumentowane na ten temat, ale na podstawie nazwy możemy zgadywać (szczególnie biorąc pod uwagę konfigurację tego konkretnego testu).
Rozszerzone zdarzenia do celu bufora pierścieniowego
Następnie przejrzyjmy wyniki dotyczące odpowiedników sesji Extended Event. Użyłem następującej definicji sesji:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
W poniższej tabeli przedstawiono żądania wsadowe przed i po na sekundę podczas włączania sesji XE z docelowym buforem pierścieniowym (przechwytywanie query_post_execution_showplan wydarzenie):
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 4737 |
Najczęstsze typy oczekiwania były następujące:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| SLEEP_TASK | 240 | 181 739 |
| LAZYWRITER_SLEEP | 120 | 120 219 |
| HADR_WORK_QUEUE | 12 | 120 038 |
| DIRTY_PAGE_POLL | 1198 | 120 035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 011 |
| LOGMGR_QUEUE | 936 | 120,008 |
| CZEKAJ NA | 1 | 120,001 |
Nic nie wyskoczyło jako związane z XE, tylko „hałas” zadania w tle.
Rozszerzone zdarzenia do pliku docelowego
Co powiesz na zmianę sesji, aby używała pliku docelowego zamiast docelowego bufora pierścieniowego? Poniższa tabela przedstawia żądania wsadowe przed i po na sekundę podczas włączania sesji XE z plikiem docelowym zamiast docelowym buforem pierścieniowym:
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 4299 |
Najczęstsze typy oczekiwania były następujące:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2103 | 299996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237003 |
| SLEEP_TASK | 253 | 180 663 |
| LAZYWRITER_SLEEP | 120 | 120 187 |
| HADR_WORK_QUEUE | 12 | 120 029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| CZEKAJ NA | 1 | 120,001 |
| XE_TIMER_EVENT | 59 | 119 966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Nic, z wyjątkiem XE_TIMER_EVENT , wyskoczył jako związany z XE. Repozytorium typu oczekiwania Boba Warda odnosi się do tego jako bezpiecznego do zignorowania, chyba że coś jest możliwe nie tak – ale realistycznie, czy zauważyłbyś ten zwykle łagodny typ oczekiwania, gdyby znajdował się na 9 miejscu w twoim systemie podczas spadku wydajności? A co, jeśli już to odfiltrowujesz ze względu na jego zwykle łagodny charakter?
Rozszerzone zdarzenia do powolnego docelowego pliku ścieżki we/wy
A co, jeśli umieszczę plik na wolnej ścieżce we/wy? Poniższa tabela przedstawia żądania wsadowe przed i po na sekundę podczas włączania sesji XE z plikiem docelowym na pamięci USB:
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 4386 |
Najczęstsze typy oczekiwania były następujące:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| SLEEP_TASK | 253 | 180 719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 427 |
| LAZYWRITER_SLEEP | 120 | 120 190 |
| HADR_WORK_QUEUE | 12 | 120 025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| CZEKAJ NA | 1 | 120,002 |
| DIRTY_PAGE_POLL | 1197 | 119 977 |
| XE_TIMER_EVENT | 59 | 119 949 |
Ponownie, nic związanego z XE nie wyskakuje z wyjątkiem XE_TIMER_EVENT .
Rozszerzone zdarzenia do docelowego pliku ścieżki we/wy, bez utraty zdarzeń
Poniższa tabela przedstawia żądania wsadowe przed i po na sekundę podczas włączania sesji XE z obiektem docelowym pliku na pamięci USB, ale tym razem bez zezwolenia na utratę zdarzeń (EVENT_RETENTION_MODE=NO_EVENT_LOSS) — co nie jest zalecane, a zobaczysz w wynikach, dlaczego może to być:
| Podstawowe żądania partii na sekundę (średnia z 2 minut) | Żądania wsadowe programu SQL Profiler na sekundę (średnia z 2 minut) |
|---|---|
| 14 492 | 539 |
Najczęstsze typy oczekiwania były następujące:
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8773 | 1707,845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237003 |
| SLEEP_TASK | 337 | 180 446 |
| LAZYWRITER_SLEEP | 120 | 120 032 |
| DIRTY_PAGE_POLL | 1198 | 120 026 |
| HADR_WORK_QUEUE | 12 | 120 0009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120,007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120,006 |
| CZEKAJ NA | 1 | 120 000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Dzięki ekstremalnej redukcji przepustowości widzimy XE_BUFFERMGR_FREEBUF_EVENT przejdź na pozycję numer jeden w naszych wynikach skumulowanego czasu oczekiwania. Ten jest udokumentowane w Books Online, a Microsoft mówi nam, że to zdarzenie jest powiązane z sesjami XE skonfigurowanymi na brak utraty zdarzeń i gdzie wszystkie bufory w sesji są pełne.
Wpływ obserwatora
Pomijając typy oczekiwania, warto było zauważyć, jaki wpływ każda metoda obserwacji miała na zdolność przetwarzania żądań wsadowych przez obciążenie:
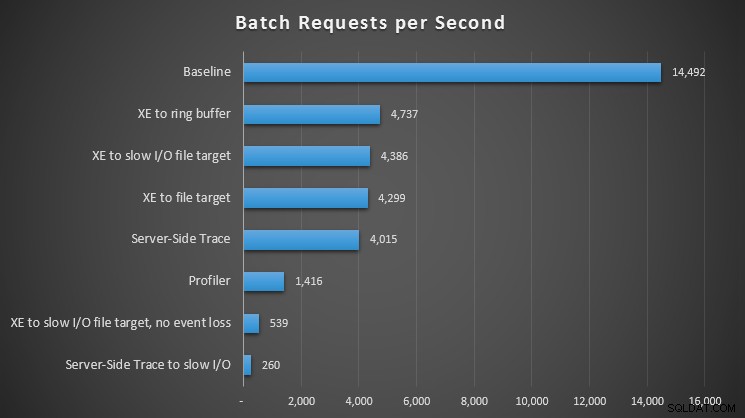
Wpływ różnych metod obserwacji na żądania grupowe na sekundę
W przypadku wszystkich podejść wystąpiło znaczące – ale nie szokujące – trafienie w porównaniu z naszą linią bazową (brak obserwacji); jednak najwięcej bólu odczuwano podczas korzystania z programu Profiler, śledzenia po stronie serwera do wolnej ścieżki we/wy lub zdarzeń rozszerzonych do obiektu docelowego pliku na wolnej ścieżce we/wy — ale tylko wtedy, gdy skonfigurowano brak utraty zdarzeń. W przypadku utraty zdarzeń ta konfiguracja faktycznie działała na równi z docelowym plikiem do szybkiej ścieżki we/wy, prawdopodobnie dlatego, że była w stanie odrzucić znacznie więcej zdarzeń.
Podsumowanie
Nie testowałem każdego możliwego scenariusza i na pewno są inne ciekawe kombinacje (nie wspominając o różnych zachowaniach opartych na wersji SQL Server), ale kluczowy wniosek, który wyciągam z tej eksploracji jest taki, że nie zawsze można polegać na oczywistej kumulacji typu wait wskaźnik w obliczu ogólnego scenariusza obserwatora. Na podstawie testów przedstawionych w tym poście tylko trzy z siedmiu scenariuszy wykazywały określony typ oczekiwania, który potencjalnie może pomóc wskazać właściwy kierunek. Nawet wtedy – te testy były prowadzone w kontrolowanym systemie – i często ludzie odfiltrowują wyżej wymienione typy oczekiwania jako łagodne typy tła – więc możesz ich w ogóle nie widzieć.
Biorąc to pod uwagę, co możesz zrobić? W przypadku pogorszenia wydajności bez wyraźnych lub oczywistych objawów, zalecam poszerzenie zakresu, aby zapytać o ślady i sesje XE (na marginesie – zalecam również poszerzenie zakresu, jeśli system jest zwirtualizowany lub może mieć nieprawidłowe opcje zasilania). Na przykład, w ramach rozwiązywania problemów z systemem, sprawdź sys.[traces] i sys.[dm_xe_sessions] aby sprawdzić, czy w systemie działa coś, co jest nieoczekiwane. Jest to dodatkowa warstwa do tego, o co musisz się martwić, ale wykonanie kilku szybkich walidacji może zaoszczędzić znaczną ilość czasu.