W ostatnim wątku na StackExchange użytkownik miał następujący problem:
Chcę, aby zapytanie zwracało pierwszą osobę w tabeli o identyfikatorze GroupID =2. Jeśli nikt z GroupID =2 nie istnieje, chcę, aby pierwsza osoba miała identyfikator roli =2.
Odrzućmy na razie fakt, że „pierwszy” jest strasznie zdefiniowany. W rzeczywistości użytkownik nie dbał o to, którą osobę otrzyma, niezależnie od tego, czy przyszło to losowo, arbitralnie, czy też poprzez jakąś wyraźną logikę oprócz głównych kryteriów. Ignorując to, załóżmy, że masz podstawową tabelę:
CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT );
W świecie rzeczywistym prawdopodobnie są inne kolumny, dodatkowe ograniczenia, może klucze obce do innych tabel, a na pewno inne indeksy. Ale zachowajmy to prosto i wymyślmy zapytanie.
Prawdopodobne rozwiązania
Przy takim projekcie stołu rozwiązanie problemu wydaje się proste, prawda? Pierwsza próba, którą prawdopodobnie podjąłbyś, to:
SELECT TOP (1) UserID, GroupID, RoleID FROM dbo.Users WHERE GroupID = 2 OR RoleID = 2 ORDER BY CASE GroupID WHEN 2 THEN 1 ELSE 2 END;
To używa TOP i warunkowe ORDER BY traktować tych użytkowników z GroupID =2 jako wyższy priorytet. Plan dla tego zapytania jest dość prosty, a większość kosztów przypada na operację sortowania. Oto metryki czasu wykonywania dla pustej tabeli:
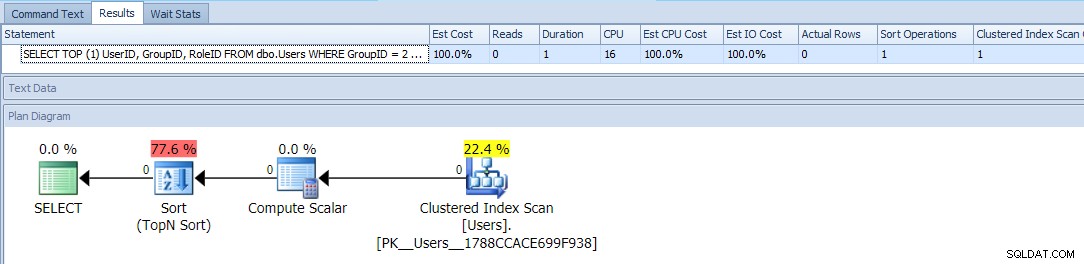
Wygląda na to, że jest to tak dobre, jak tylko możesz – prosty plan, który skanuje tabelę tylko raz, i poza nieznośnym rodzajem, z którym powinieneś być w stanie żyć, nie ma problemu, prawda?
Cóż, inna odpowiedź w wątku dotyczyła tej bardziej złożonej odmiany:
SELECT TOP (1) UserID, GroupID, RoleID FROM ( SELECT TOP (1) UserID, GroupID, RoleID, o = 1 FROM dbo.Users WHERE GroupId = 2 UNION ALL SELECT TOP (1) UserID, GroupID, RoleID, o = 2 FROM dbo.Users WHERE RoleID = 2 ) AS x ORDER BY o;
Na pierwszy rzut oka można by pomyśleć, że to zapytanie jest wyjątkowo mniej wydajne, ponieważ wymaga dwóch skanów indeksu klastrowego. Na pewno miałbyś rację; oto metryki planu i czasu działania w pustej tabeli:
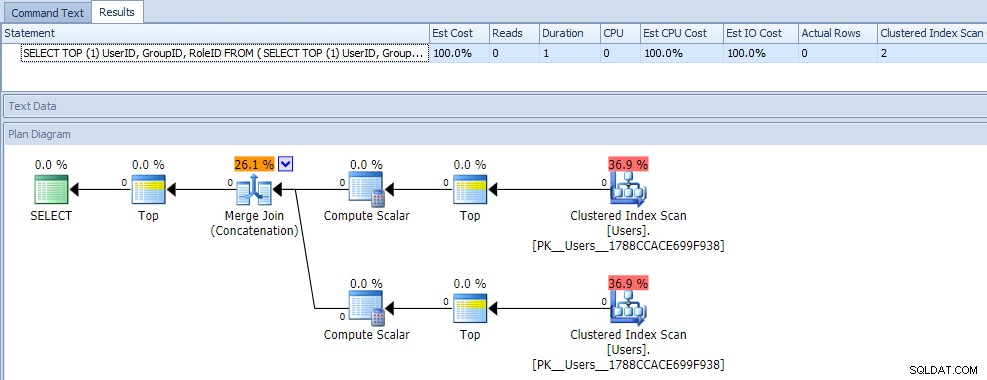
Ale teraz dodajmy dane
Aby przetestować te zapytania, chciałem użyć realistycznych danych. Więc najpierw wypełniłem 1000 wierszy z sys.all_objects operacjami modulo na object_id, aby uzyskać przyzwoitą dystrybucję:
INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 7, ABS([object_id]) % 4 FROM sys.all_objects ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 126 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 248 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 26 overlap
Teraz, gdy uruchamiam te dwa zapytania, oto metryki czasu wykonywania:

Wersja UNION ALL zawiera nieco mniej operacji we/wy (4 odczyty w porównaniu z 5), krótszy czas trwania i niższy szacowany całkowity koszt, podczas gdy warunkowa wersja ORDER BY ma niższy szacowany koszt procesora. Dane tutaj są dość małe, aby wyciągnąć jakiekolwiek wnioski; Chciałem tylko, żeby to był kołek w ziemi. Teraz zmieńmy rozkład tak, aby większość wierszy spełniała co najmniej jedno z kryteriów (a czasami oba):
DROP TABLE dbo.Users; GO CREATE TABLE dbo.Users ( UserID INT PRIMARY KEY, GroupID INT, RoleID INT ); GO INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000) ABS([object_id]), ABS([object_id]) % 2 + 1, SUBSTRING(RTRIM([object_id]),7,1) % 2 + 1 FROM sys.all_objects WHERE ABS([object_id]) > 9999999 ORDER BY [object_id]; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 500 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 475 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 221 overlap
Tym razem kolejność warunkowa według ma najwyższe szacowane koszty zarówno w procesorze, jak i we/wy:

Ale znowu, przy tym rozmiarze danych, jest stosunkowo nieistotny wpływ na czas trwania i odczyty, a poza szacowanymi kosztami (które i tak są w dużej mierze wymyślone), trudno tutaj ogłosić zwycięzcę.
Dodajmy więc dużo więcej danych
Chociaż lubię budować przykładowe dane z widoków katalogu, ponieważ każdy je ma, tym razem narysuję tabelę Sales.SalesOrderHeaderEnlarged z AdventureWorks2012, rozszerzoną za pomocą tego skryptu autorstwa Jonathana Kehayiasa. W moim systemie ta tabela ma 1 258 600 wierszy. Poniższy skrypt wstawi milion tych wierszy do naszej tabeli dbo.Users:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (1000000) SalesOrderID, SalesOrderID % 7, SalesOrderID % 4 FROM Sales.SalesOrderHeaderEnlarged; SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 142,857 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 250,000 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 35,714 overlap
OK, teraz, gdy uruchamiamy zapytania, widzimy problem:wariacja ORDER BY działała równolegle i zatarła zarówno odczyty, jak i procesor, dając prawie 120-krotną różnicę w czasie trwania:
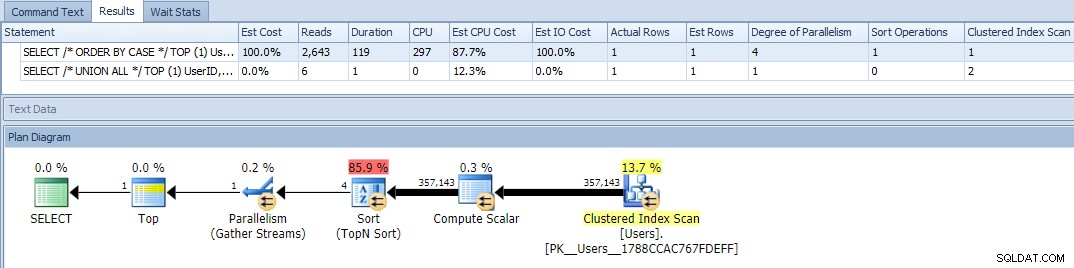
Wyeliminowanie równoległości (przy użyciu MAXDOP) nie pomogło:
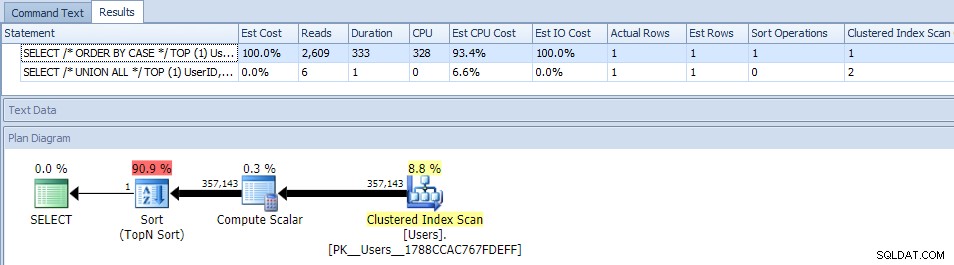
(Plan UNION ALL nadal wygląda tak samo.)
A jeśli zmienimy pochylenie na równe, gdzie 95% wierszy spełnia co najmniej jedno kryterium:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (475000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 1 UNION ALL SELECT TOP (475000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged WHERE SalesOrderID % 2 = 0; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, 1, 1 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 542,851 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 135,702 overlap
Zapytania nadal pokazują, że sortowanie jest zbyt drogie:

A przy MAXDOP =1 było znacznie gorzej (spójrz tylko na czas trwania):

Wreszcie, jak około 95% pochylenia w dowolnym kierunku (np. większość wierszy spełnia kryteria GroupID lub większość wierszy spełnia kryteria RoleID)? Ten skrypt zapewni, że co najmniej 95% danych będzie miało GroupID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Wyniki są dość podobne (od teraz przestanę próbować MAXDOP):

A potem, jeśli przekrzywimy się w drugą stronę, gdzie co najmniej 95% danych ma RoleID =2:
-- DROP and CREATE, as before INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (950000) SalesOrderID, 2, SalesOrderID % 7 FROM Sales.SalesOrderHeaderEnlarged; INSERT dbo.Users(UserID, GroupID, RoleID) SELECT TOP (50000) SalesOrderID, SalesOrderID % 7, 2 FROM Sales.SalesOrderHeaderEnlarged AS h WHERE NOT EXISTS (SELECT 1 FROM dbo.Users WHERE UserID = h.SalesOrderID); SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2; -- 185,714 SELECT COUNT(*) FROM dbo.Users WHERE RoleID = 2; -- 957,143 SELECT COUNT(*) FROM dbo.Users WHERE GroupID = 2 AND RoleID = 2; -- 142,857 overlap
Wyniki:

Wniosek
W żadnym przypadku, który mógłbym wyprodukować, „prostsze” zapytanie ORDER BY – nawet przy jednym mniej zgrupowanym skanowaniu indeksu – nie przewyższyło bardziej złożonego zapytania UNION ALL. Czasami musisz być bardzo ostrożny co do tego, co SQL Server ma do zrobienia, kiedy wprowadzasz operacje takie jak sortowanie do semantyki zapytań i nie polegać na prostocie samego planu (nieważne, jakie masz uprzedzenia, które możesz mieć na podstawie poprzednich scenariuszy).
Twój pierwszy instynkt często może być słuszny, ale założę się, że są chwile, kiedy istnieje lepsza opcja, która na pierwszy rzut oka wygląda, jakby nie mogła lepiej działać. Jak w tym przykładzie. Jestem coraz lepszy w kwestionowaniu założeń, które poczyniłem na podstawie obserwacji, i nie wygłaszam ogólnych stwierdzeń, takich jak „skanowanie nigdy nie działa dobrze” i „prostsze zapytania zawsze działają szybciej”. Jeśli wyeliminujesz słowa „nigdy i zawsze” ze swojego słownika, może się okazać, że sprawdzisz więcej z tych założeń i stwierdzeń ogólnych i skończysz na znacznie lepszych warunkach.



