Każdy produkt ma błędy, a SQL Server nie jest wyjątkiem. Korzystanie z funkcji produktu w nieco nietypowy sposób (lub łączenie ze sobą stosunkowo nowych funkcji) to świetny sposób na ich znalezienie. Błędy mogą być interesujące, a nawet pouczające, ale być może część radości zostanie utracona, gdy odkrycie skutkuje uruchomieniem pagera o 4 nad ranem, być może po szczególnie towarzyskim wieczorze z przyjaciółmi…
Błąd, który jest tematem tego posta, jest prawdopodobnie dość rzadki w środowisku naturalnym, ale nie jest to klasyczny przypadek. Znam przynajmniej jednego konsultanta, który spotkał się z nim w systemie produkcyjnym. W zupełnie niezwiązanym temacie powinienem skorzystać z okazji, aby przywitać się ze zrzędliwym starym DBA (blog).
Zacznę od pewnego istotnego tła na temat łączenia przez scalanie. Jeśli jesteś pewien, że wiesz już wszystko o łączeniu przez scalanie lub po prostu chcesz przejść do sedna, przewiń w dół do sekcji zatytułowanej „Błąd”.
Scal Dołącz
Połączenie scalające nie jest strasznie skomplikowaną rzeczą i może być bardzo skuteczne w odpowiednich okolicznościach. Wymaga, aby jego dane wejściowe były posortowane według kluczy łączenia i działa najlepiej w trybie jeden-do-wielu (gdzie przynajmniej jego dane wejściowe są unikatowe w kluczach łączenia). W przypadku łączeń jeden-do-wielu o średniej wielkości, łączenie szeregowe nie jest wcale złym wyborem, pod warunkiem, że można spełnić wymagania sortowania danych wejściowych bez przeprowadzania sortowania jawnego.
Unikanie sortowania jest najczęściej osiągane przez wykorzystanie kolejności zapewnianej przez indeks. Sprzężenie scalające może również korzystać z zachowanej kolejności sortowania z wcześniejszego, nieuniknionego sortowania. Fajną rzeczą w łączeniu przez scalanie jest to, że może przestać przetwarzać wiersze wejściowe, gdy tylko jeden z nich zabraknie wierszy. Ostatnia rzecz:merge join nie ma znaczenia, czy kolejność sortowania danych wejściowych jest rosnąca czy malejąca (chociaż oba dane wejściowe muszą być takie same). Poniższy przykład wykorzystuje standardową tabelę liczb do zilustrowania większości powyższych punktów:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Zauważ, że indeksy wymuszające klucze podstawowe w tych dwóch tabelach są zdefiniowane jako malejące. Plan zapytań dla INSERT ma wiele interesujących funkcji:
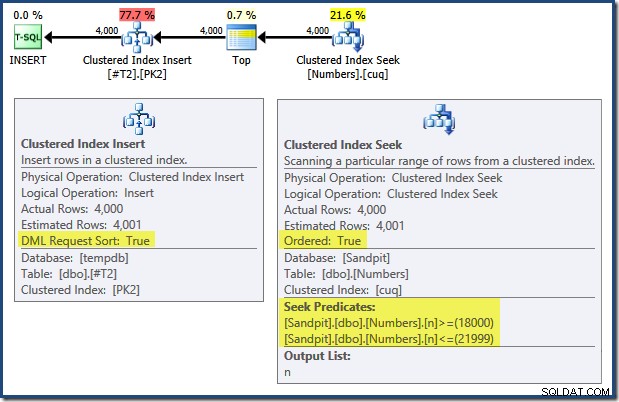
Czytając od lewej do prawej (co jest tylko rozsądne!) Wstawka indeksu klastrowego ma ustawioną właściwość „Sortowanie żądań DML”. Oznacza to, że operator wymaga wierszy w kolejności klucza Clustered Index. Indeks klastrowy (wymuszanie w tym przypadku klucza podstawowego) jest zdefiniowany jako DESC , więc wiersze z wyższymi wartościami muszą dotrzeć jako pierwsze. Indeks klastrowy w mojej tabeli Numbers to ASC , dzięki czemu optymalizator zapytań unika jawnego sortowania, szukając najpierw najwyższego dopasowania w tabeli Numbers (21 999), a następnie skanując w kierunku najniższego dopasowania (18 000) w odwrotnej kolejności indeksów. Widok „Drzewo planów” w SQL Sentry Plan Explorer wyraźnie pokazuje odwrotne (do tyłu) skanowanie:
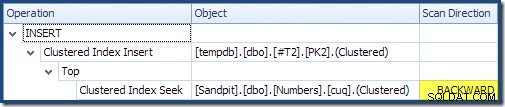
Skanowanie wstecz odwraca naturalną kolejność indeksu. Skanowanie wstecz ASC klucz indeksu zwraca wiersze w malejącej kolejności kluczy; skanowanie wstecz DESC klucz indeksu zwraca wiersze w rosnącej kolejności kluczy. „Kierunek skanowania” nie wskazuje sam w sobie kolejności zwracanych kluczy – musisz wiedzieć, czy indeks to ASC lub DESC aby podjąć tę decyzję.
Korzystanie z tych tabel testowych i danych (T1 ma 10 000 wierszy ponumerowanych od 10 000 do 19 999 włącznie; T2 ma 4000 wierszy ponumerowanych od 18 000 do 21 999) następujące zapytanie łączy ze sobą dwie tabele i zwraca wyniki w kolejności malejącej obu kluczy:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Zapytanie zwraca prawidłowe pasujące 2000 wierszy, zgodnie z oczekiwaniami. Plan powykonawczy jest następujący:
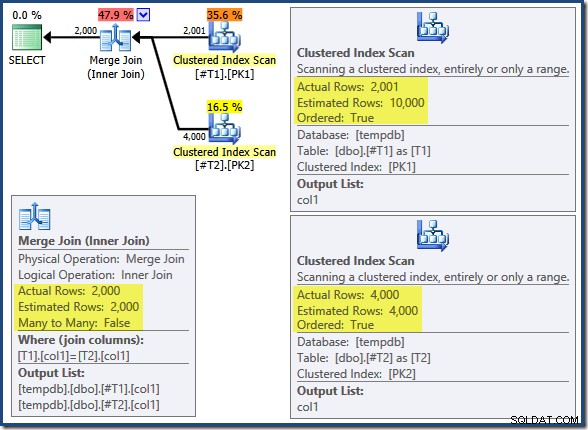
Łączenie scalające nie działa w trybie wiele do wielu (górne dane wejściowe są unikatowe w kluczach łączenia), a oszacowanie kardynalności 2000 wierszy jest dokładnie poprawne. Skanowanie indeksu klastrowego tabeli T2 jest uporządkowana (chociaż musimy chwilę poczekać, aby dowiedzieć się, czy jest to kolejność do przodu, czy do tyłu), a oszacowanie kardynalności na 4000 wierszy jest również dokładne. Skanowanie indeksu klastrowego tabeli T1 jest również uporządkowany, ale odczytano tylko 2001 wierszy, podczas gdy oszacowano 10 tys. Widok drzewa planu pokazuje, że oba skanowania indeksów klastrowych są uporządkowane do przodu:
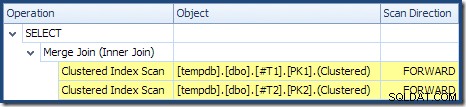
Przypomnij sobie czytanie DESC index FORWARD utworzy wiersze w odwrotnej kolejności kluczy. Dokładnie tego wymaga ORDER BY T1.col DESC, T2.col1 DESC klauzula, więc nie jest konieczne jawne sortowanie. Pseudo-kod dla łączenia scalania jeden-do-wielu (odtworzony z bloga Craig Freedman's Merge Join) to:

Skanowanie w kolejności malejącej T1 zwraca wiersze zaczynające się od 19 999 i pracujące w dół do 10 000. Skanowanie malejącej kolejności T2 zwraca wiersze zaczynające się od 21 999 i pracujące w dół do 18 000. Wszystkie 4000 wierszy w T2 zostaną ostatecznie odczytane, ale iteracyjny proces scalania zatrzymuje się, gdy wartość klucza 17,999 zostanie odczytana z T1 , ponieważ T2 zabraknie rzędów. Przetwarzanie scalania kończy się zatem bez pełnego odczytu T1 . Czyta wiersze od 19999 do 17999 włącznie; łącznie 2001 wierszy, jak pokazano w powyższym planie wykonania.
Zachęcamy do ponownego uruchomienia testu za pomocą ASC zamiast tego indeksy, zmieniając także ORDER BY klauzula z DESC do ASC . Opracowany plan wykonania będzie bardzo podobny i nie będą potrzebne żadne rodzaje.
Podsumowując punkty, które będą ważne za chwilę, Merge Join wymaga danych wejściowych posortowanych według klucza łączenia, ale nie ma znaczenia, czy klucze są posortowane rosnąco czy malejąco.
Błąd
Aby odtworzyć błąd, przynajmniej jedna z naszych tabel musi zostać podzielona na partycje. Aby utrzymać wyniki w zarządzaniu, ten przykład użyje tylko niewielkiej liczby wierszy, więc funkcja partycjonowania również potrzebuje małych granic:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
Pierwsza tabela zawiera dwie kolumny i jest podzielona na partycje według klucza podstawowego:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Druga tabela nie jest podzielona na partycje. Zawiera klucz podstawowy i kolumnę, która zostanie dołączona do pierwszej tabeli:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Przykładowe dane
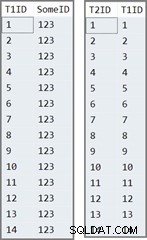
Pierwsza tabela ma 14 wierszy, wszystkie z tą samą wartością w SomeID kolumna. SQL Server przypisuje IDENTITY wartości kolumn, ponumerowane od 1 do 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Druga tabela jest po prostu wypełniona IDENTITY wartości z pierwszej tabeli:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Dane w dwóch tabelach wyglądają tak:
Zapytanie testowe
Pierwsze zapytanie po prostu łączy obie tabele, stosując pojedynczy predykat klauzuli WHERE (co w tym bardzo uproszczonym przykładzie pasuje do wszystkich wierszy):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Wynik zawiera wszystkie 14 wierszy, zgodnie z oczekiwaniami:

Ze względu na małą liczbę wierszy optymalizator wybiera plan łączenia zagnieżdżonych pętli dla tego zapytania:
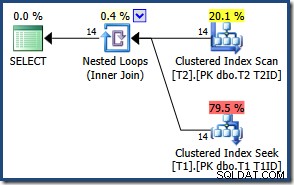
Wyniki są takie same (i nadal poprawne), jeśli wymusimy połączenie haszujące lub scalające:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
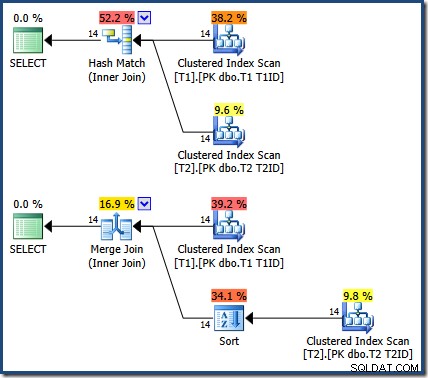
Połączenie scalające istnieje od jednego do wielu, z jawnym sortowaniem według T1ID wymagane dla tabeli T2 .
Problem malejącego indeksu
Wszystko jest w porządku, aż pewnego dnia (z ważnych powodów, które nie muszą nas tutaj dotyczyć) inny administrator doda malejący indeks do SomeID kolumna tabeli 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Nasze zapytanie nadal daje poprawne wyniki, gdy optymalizator wybiera zagnieżdżone pętle lub sprzężenie haszujące, ale to zupełnie inna historia, gdy używane jest sprzężenie scalające. W poniższym przykładzie nadal zastosowano wskazówkę dotyczącą zapytania, aby wymusić sprzężenie scalające, ale jest to tylko konsekwencja małej liczby wierszy w przykładzie. Optymalizator naturalnie wybrałby ten sam plan łączenia łączenia z różnymi danymi tabeli.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Plan wykonania to:
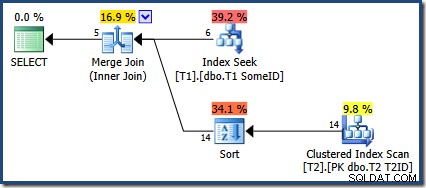
Optymalizator zdecydował się na użycie nowego indeksu, ale zapytanie generuje teraz tylko pięć wierszy danych wyjściowych:

Co się stało z pozostałymi 9 rzędami? Żeby było jasne, ten wynik jest błędny. Dane się nie zmieniły, więc wszystkie 14 wierszy powinno zostać zwróconych (ponieważ nadal są z planem zagnieżdżonych pętli lub Hash Join).
Przyczyna i wyjaśnienie
Nowy indeks nieklastrowy w SomeID nie jest zadeklarowana jako unikatowa, więc klucz indeksu klastrowego jest dyskretnie dodawany do wszystkich poziomów indeksu nieklastrowanego. SQL Server dodaje T1ID kolumna (klucz klastrowy) do indeksu nieklastrowanego, tak jakbyśmy utworzyli indeks w następujący sposób:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Zwróć uwagę na brak DESC kwalifikator na dodanym dyskretnie T1ID klucz. Klucze indeksu to ASC domyślnie. To nie jest problem sam w sobie (choć przyczynia się). Drugą rzeczą, która dzieje się automatycznie z naszym indeksem, jest to, że jest on podzielony na partycje w taki sam sposób, jak tabela podstawowa. Tak więc pełna specyfikacja indeksu, gdybyśmy mieli napisać to wprost, wyglądałaby następująco:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Teraz jest to dość złożona struktura z kluczami w różnych porządkach. Jest to wystarczająco skomplikowane, aby optymalizator zapytań popełnił błąd podczas wnioskowania o kolejności sortowania zapewnianej przez indeks. Aby to zilustrować, rozważ następujące proste zapytanie:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Dodatkowa kolumna pokaże nam, do której partycji należy bieżący wiersz. W przeciwnym razie jest to po prostu proste zapytanie, które zwraca T1ID wartości w porządku rosnącym, WHERE SomeID = 123 . Niestety wyniki nie są zgodne z zapytaniem:
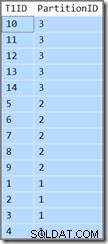
Zapytanie wymaga, aby T1ID wartości powinny być zwracane w porządku rosnącym, ale to nie jest to, co otrzymujemy. Otrzymujemy wartości w kolejności rosnącej na partycję , ale same partycje są zwracane w odwrotnej kolejności! Jeśli partycje zostały zwrócone w kolejności rosnącej (oraz T1ID wartości pozostały posortowane w ramach każdej partycji, jak pokazano), wynik byłby poprawny.
Plan zapytania pokazuje, że optymalizator został zdezorientowany przez wiodący DESC klucza indeksu i pomyślał, że aby uzyskać poprawne wyniki, należy odczytać partycje w odwrotnej kolejności:
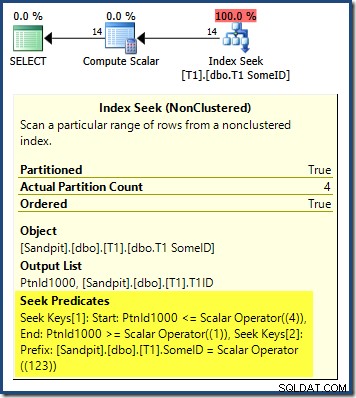
Wyszukiwanie partycji rozpoczyna się od skrajnej prawej partycji (4) i przechodzi wstecz do partycji 1. Można by pomyśleć, że możemy rozwiązać problem przez jawne sortowanie według numeru partycji ASC w ORDER BY klauzula:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; To zapytanie zwraca te same wyniki (to nie jest błąd drukarski ani błąd kopiowania/wklejania):
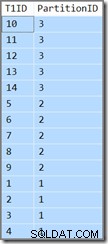
Identyfikator partycji jest nadal malejący kolejność (nie rosnąca, jak określono) i T1ID jest sortowane tylko rosnąco w obrębie każdej partycji. Takie jest zamieszanie optymalizatora, naprawdę myśli (weź głęboki oddech), że skanowanie indeksu z kluczem wiodącym i malejącym podzielonym na partycje w kierunku do przodu, ale z odwróconymi partycjami, da w wyniku kolejność określoną przez zapytanie.
Nie obwiniam tego, żeby być szczerym, różne względy porządku sortowania również sprawiają, że boli mnie głowa.
Jako ostatni przykład rozważ:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Wyniki to:

Ponownie T1ID porządek sortowania w każdej partycji prawidłowo maleje, ale same partycje są wymienione od tyłu (przechodzą od 1 do 3 w dół rzędów). Gdyby partycje zostały zwrócone w odwrotnej kolejności, wyniki byłyby prawidłowe:14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Powrót do połączenia scalającego
Przyczyna nieprawidłowych wyników z zapytaniem Merge Join jest teraz oczywista:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
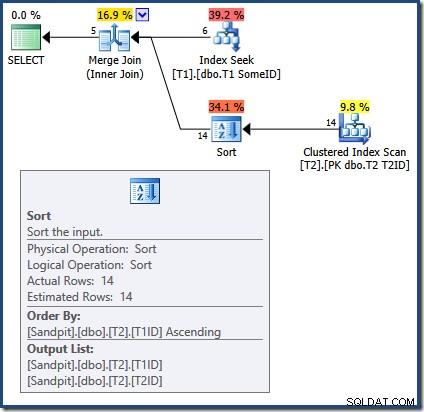
Połączenie scalające wymaga posortowanych danych wejściowych. Dane wejściowe z T2 jest jawnie posortowany według T1TD więc to jest w porządku. Optymalizator błędnie twierdzi, że indeks na T1 może dostarczyć wiersze w T1ID zamówienie. Jak widzieliśmy, tak nie jest. Wyszukiwanie indeksu daje takie same wyniki, jak zapytanie, które już widzieliśmy:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Tylko pierwszych 5 wierszy znajduje się w T1ID zamówienie. Następna wartość (5) z pewnością nie jest w porządku rosnącym, a łączenie scalające interpretuje to jako koniec strumienia, a nie powoduje błąd (osobiście spodziewałem się tutaj potwierdzenia sprzedaży detalicznej). W każdym razie efekt jest taki, że scalanie łączenia nieprawidłowo kończy przetwarzanie wcześnie. Przypominamy, że (niepełne) wyniki to:

Wniosek
Moim zdaniem jest to bardzo poważny błąd. Proste wyszukiwanie indeksu może zwrócić wyniki, które nie przestrzegają ORDER BY klauzula. Co więcej, wewnętrzne rozumowanie optymalizatora jest całkowicie zepsute dla partycjonowanych nieunikalnych indeksów nieklastrowanych z malejącym kluczem wiodącym.
Tak, to jest nieco nietypowa aranżacja. Ale, jak widzieliśmy, prawidłowe wyniki mogą zostać nagle zastąpione nieprawidłowymi wynikami tylko dlatego, że ktoś dodał malejący indeks. Pamiętaj, że dodany indeks wyglądał wystarczająco niewinnie:brak wyraźnego ASC/DESC niezgodność kluczy i brak wyraźnego partycjonowania.
Błąd nie ogranicza się do łączenia połączeń. Ofiarą może paść potencjalnie każde zapytanie, które obejmuje tabelę podzieloną na partycje i które opiera się na kolejności sortowania indeksu (jawne lub niejawne). Ten błąd występuje we wszystkich wersjach SQL Server od 2008 do 2014 CTP 1 włącznie. Baza danych Windows SQL Azure nie obsługuje partycjonowania, więc problem nie występuje. SQL Server 2005 używał innego modelu implementacji partycjonowania (na podstawie APPLY ) i nie cierpi z tego powodu.
Jeśli masz chwilę, rozważ zagłosowanie na mój element Connect w związku z tym błędem.
Rozdzielczość
Rozwiązanie tego problemu jest teraz dostępne i udokumentowane w artykule z bazy wiedzy. Pamiętaj, że poprawka wymaga aktualizacji kodu i flagi śledzenia 4199 , który umożliwia szereg innych zmian procesora zapytań. Rzadko zdarza się, aby błąd dotyczący nieprawidłowych wyników był naprawiany pod 4199. Poprosiłem o wyjaśnienie tego i odpowiedź brzmiała:
Mimo że ten problem dotyczy nieprawidłowych wyników, takich jak inne poprawki dotyczące procesora zapytań, włączono tę poprawkę tylko pod flagą śledzenia 4199 dla programu SQL Server 2008, 2008 R2 i 2012. Jednak ta poprawka jest „włączona” przez domyślnie bez flagi śledzenia w SQL Server 2014 RTM.